OllyDbg при смерти — спасение наработок отладочной сессии
Если вы используете OllyDbg не для отладки собственных приложений, для которых у вас есть отладочная информация, а для реверс-инжиниринга или исследования сторонних, типичная ваша деятельность — это вникание в машинный код чужого продукта, осознание сути происходящих вещей и расстановка большого числа меток (labels) и комментариев по всему коду, а также по секциям данных. Вы планомерно разведываете суть процедур/функций и переменных и даёте им имена, отражающие ваше понимание их предназначения.
И вот спустя несколько часов (а то и дней) работы, когда вы разобрались и подписали сотни, а то и тысячи процедур и переменных, OllyDbg внезапно зависает или вылетает, унося в небытие все ваши наработки (в которые могут входить не только labels и comments в большом числе, но и расставленные в нужных местах брекпоинты и модификации). Это потеря времени и чудовищно демотивирующий фактор, от которого опускаются руки и бледнеет лицо.
Эта статья о том, как я в такой экстренной ситуации использовал OllyDbg для того, чтобы оперативно разреверсить OllyDbg (частично), спасти висящие на волоске данные и выработать рецепт действий на случай таких катастроф.
Раз уж вы продолжили читать статью, давайте с самого начала договоримся о некоторых вещах:
- Эта статья относится к OllyDbg 1.xx, но не OllyDbg 2.xx, хотя очень поверхностный взгляд на дизасм кода последней свидетельствует о том, что аспекты организация хранения в ней интересующих нас данных в какой-то мере похожи на то, как это они сделано в линейке версий 1.xx (что и обозревается в этой статье).
- Если у вас прямо сейчас завис OllyDbg или вылетел с ошибкой, и вы не знаете, что делать, т.е. если вы находитесь в «экстренной ситуации» — можете сразу перейти к разделу «Методика спасения данных», пропустив длительное вступление, обзор альтернативных методов и описание процесса анализа исполняемого кода, результатом которого стала предлагаемая методика, снабжённое также размышлениями о найденных в процессе анализа недостатках и багах кода OllyDbg. В ином случае лучше читать статью последовательно, но даже в этом случае будьте осторожны, раскрывая спойлеры — вас может затянуть в кроличью нору.
- Автор прекрасно знает об IDA Pro и других инструментах, но предпочитает OllyDbg для прикладных приложений. Не стоит под статьёй о ремонте Audi писать «а я езжу на BMW» и устраивать холивары. В конце концов лучший инструмент — тот, которым ты владеешь в совершенстве.
- Я некоторое время колебался по поводу того, писать ли эту статью. Она написана «по горячим следам» и на основе личного опыта. Но раз уж на хабре публикуются howto-статьи на тему того, как проксировать трафик через SSH, хотя это абсолютно документированная возможность, то почему методика спасения данных, полагающаяся на нигде не освящённые знания, не заслуживает внимания? Кстати, я вдохновлялся статьёй «Жизнь после BSOD» покойного Криса Касперски — очень интересная статья, если режим ядра для вас не тёмный лес, рекоммендую. Поехали?
Я буду использовать слово «наработки» для того, чтобы обобщённо называть всё то, что вы расставляете в отладчике, перемещаясь по коду, и всё то, что обычно бывает болезненно потерять. А именно:
- Метки (Labels) — OllyDbg даёт вам возможность ставить метки в произвольных местах, например, чтобы подписать безымянную процедуру или переменную.
- Комментарии (Comments) — любому месту в образе исполняемого файла можно присоединить комментарий.
- Точки останова (Breakpoints) — в пояснении не нуждаются.
- Подсказки по анализу (Hints) — можете указать OllyDbg, к примеру, что вот эти 4 байта нужно отображать не как 4 отдельных байта, а как один DWORD.
Больше всего, конечно, меня волнуют именно метки и комментарии, потому что в брекпоинтах кроется не так много уникальной и сложновосполнимой в случае утраты информации. Если вы потеряли десяток важных брекпоинтов, но у вас все процедуры как следует подписаны и код внутри процедур щедро откомментирован, то обычно не составляет труда найти нужные места и установить брекпоинты заново. А вот ориентироваться в бинарнике, в котором не подписано ничего, полагаясь лишь на адреса, сможет только законченный гений и уникум — обычному же человеку крайне важно и полезно иметь человеко-понятные подписи и имена.
Кстати говоря, забегая вперёд, скажу, что подобные сущности, то есть пары {адрес в отлаживаемом процессе → текстовое значение} обобщённо в рамках самого отладчика OllyDbg обозначаются термином names. Набор их типов не ограничивается четырьмя вышеперечисленными.
- NM_LABEL — User-defined label
- NM_EXPORT — Exported (global) name
- NM_IMPORT — Imported name
- NM_LIBRARY — Name extracted from library, object file or debug data
- NM_CONST — User-defined constant (currently not implemented)
- NM_COMMENT — User-defined comment
- NM_LIBCOMM — Automatically generated comment from library or object file
- NM_BREAK — Condition related with breakpoint
- NM_ARG — Arguments decoded by analyser
- NM_ANALYSE — Comment added by analyser
- NM_BREAKEXPR — Expression related with breakpoint
- NM_BREAKEXPL — Explanation related with breakpoint
- NM_ASSUME — Assume function with known arguments
- NM_STRUCT — Code structure decoded by analyzer
- NM_CASE — Case description decoded by analyzer
- NM_PLUGCMD — Plugin commands to execute at breakpoint
- NM_INSPECT — Several last entered inspect expressions
- NM_WATCH — Watch expressions
Все эти сущности при штатном завершении отладчика заботливо сохраняются в специальный файл (с расширением .udd), а при последующем открытии бинарника под отладчиком — загружаются. Поэтому если вы расставили несколько меток, установили сколько-то брекпоинтов и закрыли отладчик, а затем заново открыли под отладчиком то, над чем вы работали, все ваши метки и брекпоинты (как и всё остальное) будут на месте. Каждому модулю, загруженному в адресное пространство отлаживаемого процесса, соответствует свой UDD-файл, так что метки внутри supercool.dll, которую использовал foo.exe, будут видны и при отладке bar.exe, если он тоже использует supercool.dll.
Пути потери данных
К сожалению, при всех своих достоинствах, OllyDbg имеет и большое число недостатков и недоработок (истинный масштаб которых открывается только по мере обретения большого стажа работы с этим отладчиком). К ним относится и склонность OllyDbg терять все те наработки, которые пользователь делает в процессе отладки.
Почему данные теряются, если всё сохраняется в UDD-файлы? Во-первых, часть всех невзгод проистекает из того, что сохранение в UDD-файл происходит только при завершении отладочной сессии, то есть при закрытии отладчика или переход на отладку совершенно другого процесса. Нет никакого автосохранения ваших отладочных данных в UDD с заданной периодичностью. В меню нет никакого пункта «Save everything to UDD». Есть запрятанный подальше пункт «Update .udd file now» — он находится в контекстном меню списка загруженных модулей (EXE/DLL/OCX) и сбрасывает на диск данные только для одного выбранного модуля. Не все знают про этот пункт, и не у всех хватит дисциплины и терпения регулярно заходить в окно Modules и прощёлкивать этот пункт у каждого из модулей, для которых что-то должно быть сохранено. Поэтому при нештатном завершении отладчика всё, что не было сохранено в UDD, будет потеряно. Если вы начали с чистого листа и 20 часов реверсили какой-то бинарник, не сбрасывая результат в UDD принудительно и не закрывая отладчик, вы рискуете потерять абсолютно всё и начинать опять с чистого листа. Во-вторых, есть пара других сценариев развития катастрофы.
Я выделяю 4 основных пути потери данных:
- Нештатное завершение — внешние причины. Сюда относятся BSOD или пропадание электропитания. Эти случаи за рамками рассмотрения данной статьи.
- Нештатное завершение — внезапный вылет. Необработанное исключение, возникшее уже не в отлаживаемом приложении, а в самом отладчике, ведёт к появлению печально известного диалога, в котором вам предлагается выбор между одинаково фатальными «Отправить отчёт» и «Не отправлять отчёт». Но если у вас в системе установлен отладчик (а иначе зачем вы читаете эту статью?), то выбор предстаёт уже между завершением процесса и возможностью присоединиться к умирающему процессу с помощью отладчика и попыткой исправить ситуацию. О перспективах такой возможности будет сказано далее. На самом деле, хоть такое и случается с OllyDbg, но случается сравнительно редко, и виноват в этом чаще всего какой-то плагин, а не сам отладчик.
- Зависание и последующее принудительное завершение. Гораздо чаще OllyDbg любит в некоторый момент просто намертво зависнуть. Здесь нет как такового нештатного завершения, но вы сами убьёте процесс OllyDbg.exe, когда вам надоест ждать. Хотя ждать иногда имеет смысл: мне известен случай, когда OllyDbg самостоятельно «отвис» спустя 27 часов после зависания. С этой ситуацией тоже можно побороться, как и с предыдущей. Кстати, чаще всего в подобных случаях виновником зависания является не сам OllyDbg, а deadlock где-то в ядре Windows, на возникновение которого наличие активно работающего отладчика как-то благотворно влияет (точную причинно-следственную связь я не брался устанавливать). В иных случаях виноват сторонний процесс, например Microsoft-овская утилита Spy++, позволяющая смотреть «внутреннее устройство» окон и обмен оконными сообщениями, для чего Spy++ внедряет во все GUI-процессы собственную DLL, которая и отвечает за перехват оконных сообщений. Если что-то в этом механизме перехвата ломается, зависают все GUI-приложения. Формально они не зависают, а лишь перестают реагировать на оконные сообщения, что для обычного пользователя эквивалентно зависанию. Консольные приложения при этом единственные остаются на плаву.
- Помимо этого OllyDbg любит просто портить UDD-файлы, причём делать это тихо и незаметно. В некоторых случаях при сохранении в UDD-файл происходит сбой, и об этом OllyDbg никак не сигнализирует. Например, на диске может банально кончиться место. При следующем запуске OllyDbg попытается прочитать файл, но не сможет, потому что он окажется битым — в этом случае все данные из файла будут отброшены, отладчик начнёт как бы с чистого листа, при закрытии отладчика будет записан новый UDD-файл, в котором всех ваших наработок уже не будет. В других случаях файл сохраняется нормально, но возникает какая-то проблема при загрузке нормально записанного файла. Всё это происходит молча, OllyDbg не загружает данные из UDD, но при штатном завершении записывает вместо него пустой UDD-файл. Наконец, поскольку UDD-файлы идентифицируются по имени модуля, а не по хешу, возможно, что под отладчиком окажется модуль, чьё имя конфликтует с одноимёнными модулями. Типичный пример — много разных версий одной и той же DLL. В этом случае OllyDbg «подцепит» неподходящий UDD-файл, и либо его контент будет отброшен по причине того, что это откровенно неподходящий UDD-файл, либо прогон анализатора сгенерирует иные сущности, которые наложатся на сущности из неподходящего UDD-файла. Бороться с этим можно только регулярными бэкапами директории для UDD-файлов.
Специальный плагин и способы спасти данные
Прежде чем описать тот способ выхода из положения, которому, собственно, и посвящается эта статья, я хочу опять сделать небольшое отступление и рассказать про специальный плагин, который имеет прямое отношение к вопросу сохранения наработок, и который я нестандартно использовал для спасения данных вплоть до последнего момента, когда мне пришлось найти более прямолинейный и агрессивный способ (т.к. прежний способ не подходил — причины будут описаны далее).
UDD — бинарный формат. Я очень люблю и, как правило, всегда предпочитаю бинарные форматы хранения данных текстовым. Они эффективнее по обработке, они компактнее по хранению и передачи. Но этот случай явно относится к числу исключений.
В данном случае проблема бинарных UDD в двух аспектах:
- Бинарные файлы плохо поддаются версионному контролю. Да, всеми любимый git (которым и я пользуюсь) с лёгкостью может помещать бинарные файлы под версионный контроль (потому что он хранит слепки состояний, а не диффы между состояниями). Но посмотреть diff между двумя ревизиями или найти ревизию, в которой сделано конкретное изменение в случае с бинарными файлами почти что нельзя (да, я знаю о custom diff в git). А уж вести две параллельные ветки работы над объектом, а потом делать merge между результатами этих параллельных разработок в случае с бинарным объектом — невозможно.
- Бинарный файл гораздо сложнее починить вручную, если он сохранился с повреждениями или повредился после сохранения, нежели текстовый. Особенно учитывая то, что формат UDD официально не документирован.
Я уже много лет занимаюсь реверс-инжинирингом и работал в том числе и над довольно большими продуктами, где число процедур измеряется десятками тысяч. Где реверс-инжиниринг целесообразно делать не в одиночку, а командой, в которой каждый член группы начинает распутывать клубок машинного кода каждый со своего конца. В таком случае очень полезно результат реверс-инжиниринга (первичные данные — те самые метки и комментарии, расставляемые в дизассемблере, а также вторичную документацию, которую пишут вручную на основе осмысления разведанного, часто включающую в себя псевдокод, прототипы функций, и т.п.) сохранять в какой-то человеко-читаемый формат и держать под версионным контролем.
При командном реверс-инжиниринге это позволяет использовать VCS типа Git для того, чтобы обмениваться результатами обратной разработки и объединять результаты в единое целое. Типичный пример: один человек начал реверсинг с одной отправной точки (например из процедуры WinMain()), другой — совершенно с другого конца (например из процедуры, сообщающей об ошибке). В процессе работы они неизбежно будут натыкаться на общие процедуры и переменные, но делать это независимо, и каждый из них будет давать одни и тем же процедурам не всегда одинаковые имена. Например, оба будут почти гарантированно натыкаться на статически влинкованные функции стандартной библиотеки (типа memcpy, strncat, qsort в случае стандартной библиотеки Си). Когда результат реверсинга подвергнут версионному контролю, и каждый работает в своей ветке, последующее слияние веток и разрешение закономерно возникающего конфликта слияния (merge conflict), позволит придти к общей терминологии и общему виденью того, как устроен изучаемый бинарник. Частые синхронизации своего репозитория с коллективным позволит меньше и реже «открывать Америку», которую раньше тебя успели разреверсить твои коллеги.
Кроме того, если кто-то в какой-то момент пошёл по неправильному пути и, исходя из неправильных предпосылок, построил частично неправильную картину того, как «устроен мир», при наличии версионного контроля и истории развития репозитория всегда можно вычислить, в какой момент ошибочная теория стала частью «картины мира», и внести исправления. Например, то, что длительное время кто-то принимал за отдельную глобальную переменную, может оказаться на деле полем экземпляра класса, размещённого статически (как глобальная переменная, в противоположность размещению на куче с помощью оператора new).
В общем, использование систем контроля версий при реверс-инжиниринге софта (а особенно больших продуктов) и помещение под версионный контроль документа, содержащего сопоставление адресов исследуемого бинарника и импровизированных названий, присвоенных реверсером тем функциям и переменным, которые он разведал, очень давно казалось мне превосходной идеей.
Кстати, я также на правах хобби занимаюсь сочинением музыки, и идея помещать под версионный контроль музыкальные проекты тоже не даёт мне покоя, но используемый мною DAW сохраняет проекты только в бинарном формате. Типичный случай: исходно-одна композиция существует в виде 5—6 версий, начавшихся от общего предка, но со временем сильно разошедшихся в звучании, концепции, оформлении, стилистике. Было бы здорово сделать merge, взяв от одной ветки наиболее партию баса, получившуюся наиболее удачно именно в этой ветке, а от другой — удачные параметры VST-эффектов на каналах микшера, от третьей — что-то ещё. Или просто выяснить, почему предыдущая версия, хоть и была короче, но звучала лучше, сделав простой git diff, а не перебирая и не сверяя все параметры всех VST-инструментов и VST-эффектов между старой и новой версией файла-проекта.
Но поскольку UDD-файлы не могут служить таким документом из-за того, что это не текстовые файлы, достаточно давно я сделал собственный плагин для OllyDbg, позволяющий экспортировать все наработки (расставленные метки (имена функций, переменных) и комментарии) в текстовый файл (своеобразный дамп), структура и синтаксис которого оптимизированы для работы с системами контроля версий.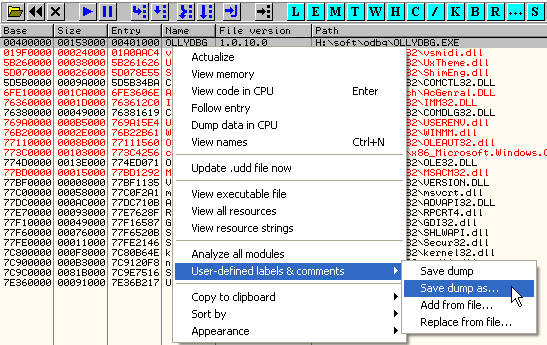
Я назвал этот плагин Markup Dumper, потому что markup — это то, как я традиционно называю расставляемые в процессе реверсинга чужого исполняемого файла метки и коментарии. В рамках данной статьи я употреблял термин «наработки», но наработки — это не только markup, это, к примеру, ещё и брекпоинты.
Дамп разметки модуля OllyDbg, сгенерированный через меню, изображенное на скриншоте выше, выглядит следующим образом. Он состоит из заголовка, позволяющего идентифицировать модуль и случайно не импортировать дамп от какого-то постороннего модуля в качестве разметки для текущего. Заголовок также позволяет во время слияния веток и разрешения конфликта понять, что два файла разметки относятся к разным исполняемым файлам или разным версиям одного и того же бинарника, и пытаться как-то это сливать в одно целое в принципе не имеет смысла.
@ MODULE OLLYDBG
@ VERSION 1.0.10.0
@ BASEADDR 00400000
@ CHECKSUM 17ca77a5
//
// Section: .text
//
LABEL 0040c214 like_ParseStuff
CMT 0040c4c5 colon case
CMT 0040c521 eq case
CMT 0040c575 checking for 1-byte typespec
CMT 0040c578 jump if more than 2 byte spec
CMT 00463f08 checking arg1 (addr) against 0
CMT 00463f0c EDI = arg2 (type of name)
CMT 00463f0f goto error if addr==NULL
CMT 00463f11 checking [addr] against 0
CMT 00463f15 goto error if 0
...
LABEL 004642fb Insertname_EPILOGUE
LABEL 004a3530 like_memcpy
LABEL 004a36d4 like_strlen
LABEL 004a38bc parse_keyword_1
LABEL 004a6c2c like_sprintf
//
// Section: .data
//
LABEL 004eae14 pNamesBlock
LABEL 004eae18 cNameEntriesCur
LABEL 004eae1c cNameEntriesMax
LABEL 004eae30 pNamesStringPool
LABEL 004eae34 cbStringPoolUsed
LABEL 004eae38 cbStringPoolTotal
LABEL 004eae3c xxxWtfNameStringPoolrelatedЗаголовки секций плагин вставляет автоматически. Многоточие поставил я сам, вырезав множество промежуточных строк.
Обратите внимание, что директивы типа CMT вставляются в дамп с двухпробельным отступом от начала строки, а LABEL — нет. Это сделано не просто так. Дело в том, что git diff использует отступы для того, чтобы определить и показать пользователю контекст, в котором находится строка с правкой — причём независимо от языка программирования исходного файла, лишь бы в файле логическая структура выделялась при помощи отступов. Поскольку LABEL в большинстве случаев соответствуют началу очередной процедуры, а CMT появляются, как правило, внутри процедур, такой подход позволяет во время вызова git diff увидеть, к какой процедуре относится добавляемый или изменяемый комментарий (или же метка), что особенно полезно при добавлении чего-то внутрь огромных процедур, не умещающихся целиком на одном экране: 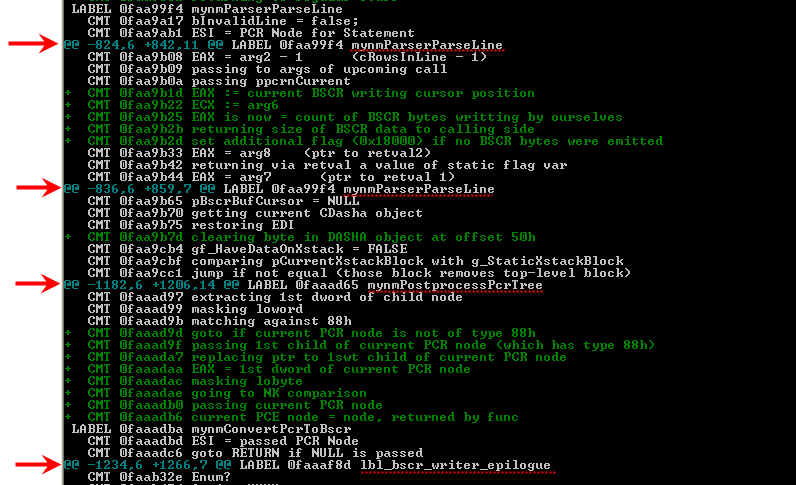
В не меньшей степени это полезно, когда, к примеру, вы разом выгрузили кучу новой разметки в файл, но хотите разобрать её на несколько отдельных коммитов с помощью интерактивного режима (git add --patch).
Этот плагин не является предметом статьи, а нужен лишь для удачной подводки к способу спасения (висящей на волоске от утраты) разметки, который я использовал последние годы, но который не удалось применить в последний раз, из-за чего и пришлось применить более прямолинейный подход.
Хотя надо отметить, что сам по себе плагин, а особенно в комбинации с DVCS отлично решает проблему риска утери данных, описанных выше как пути №1 (BSOD или блэкаут) и №4 (тихая порча UDD).
Но нас интересуют ситуации №2 и №3 (внезапный вылет или зависание). Разберём меры спасения положения в этих ситуациях.
Внезапный вылет
То, что обычные люди называют словами «процесс вылетел», «процесс рухнул», «крешнулся», для нас — необработанное SEH-исключение, которое мы можем попытаться обработать вручную, присоединившись отладчиком, «замяв дело» и продолжив как ни в чём не бывало (если только это не было SEH-исключением с флагом EXCEPTION_NONCONTINUABLE).
Большинство падений OllyDbg с исключением (хотя само по себе это большая редкость) — это исключение типа EXCEPTION_ACCESS_VIOLATION (0xc0000005), и обычно это обращение по нулевому указателю. Это самый простой и легко корректируемый случай, потому что EIP указывает на корректный код, так же как и ESP/EBP содержат корректные значения, стек цел и обычно не повреждён. Почти всегда можно перескочить проблемное место и продолжить, либо перескочить сразу на эпилог процедуры (в которой произошло исключение) и вернуться в вызывающую сторону. В большинстве таких случаев уже в вызывающей процедуре возникнет новое исключение, потому что вызываемая процедура вернула неправильное значение или не подготовила какие-то данные для вызывающей стороны. Поэтому придётся каскадно совершить «принудительный возврат» с раскруткой стека вплоть до тех пор, пока мы не попадём внутрь цикла прокачки оконных сообщений (GetMessage→TranslateMessage→DispatchMessage), откуда брала начала цепочка вызовов, последний элемент которой и спровоцировал возникновения исключения. Так как OllyDbg является GUI-приложением, так или иначе всё берёт начало из подобного цикла, если исключение произошло в процессе фоновой работы, а не в процессе инициализации или завершения отладчика.
Несколько сложнее, если в какой-то процедуре произошло переполнение буфера, размещённого на стеке. Запись за пределы границы буфера имеет высокий риск перезаписать находящиеся там сохранённое значение регистра EBP и адрес возврата. Хакеры используют это для эксплуатации уязвимости и передачи управления на желаемое место, в нашем же случае (не являющемся злонамеренным) подмена адреса возврата на случайное значение приведёт к тому, что после выполнения инструкции retn выполнение (EIP) улетает в тартарары и начинает выполняться неизвестно что.
Как правило, адрес, по которому переходит управление, вообще не является корректным — в виртуальном адресном пространстве (АП) страницы по этому адресу не выделены. Попытка перейти туда и начать выполнение по этому адресу приводит к EXCEPTION_ACCESS_VIOLATION, и именно по этому поводу мы увидим сообщение о необработанном исключении и приглашение воспользоваться отладчиком (для отладки отладчика). Если по ошибочному адресу в АП имеются выделенные страницы, но они имеют атрибуты доступа, не подразумевающие выполнение, а у нас, на счастье, включен DEP, результат будет ровно тем же. Если же нам не повезёт и мы наткнёмся на страницу, выполнение которой разрешено (или DEP не функционирует), этот произвольный и фактически случайный код (или случайные данные, интерпретируемые как код) будет выполняться некоторое время, пока не будет нанесён более серьёзный выстрел себе в ногу. Сложность этого случая в том, что, когда мы подключимся отладчиком к упавшему отладчику, EIP будет указывать скорее всего в никуда, и будет совершенно непонятно, откуда мы сюда прилетели (и куда вернуться, чтобы продолжить всё как было). Стек тоже будет частично нарушен, насколько сильно и глубоко — зависит от случая.
Тем не менее, даже если всё просто, как при случае обращения по нулевому указателю, с тех пор, как у меня появился плагин Markup Dumper, я больше не утруждал себя раскруткой стека вызовов и возвратом в message loop (цикл прокачки оконных сообщений) .
Поскольку внутренности собственного плагина я знал идеально (к нему у меня были отладочные символы), я подключался к умирающему процессу OllyDbg и вместо того, чтобы исправить ситуацию (починить стек, перепрыгнуть проблемное место), я делал нечто совершенно иное.
Я формировал на стеке фрейм с аргументами, которые должны были в норме передаваться при вызове той функции из моего плагина, которая сохраняет дамп, а затем просто насильно менял EIP так, чтобы выполнение продолжилось с этой функции из моего плагина. Естественно, найти адрес этой функции в АП умирающего процесса OllyDbg было наилегчайшей задачей, при условии, что в него был загружен мой плагин (а он был). На выходе из этой функции я ставил ловушку в виде брекпоинта, после чего давал умирающему процессу возможность выполнить мою функцию. Умирающий процесс выполнял процедуру сохранения дампа из моего плагина и сбрасывал дамп в текстовом виде на диск. Дальнейшая судьба умирающего процесса меня не волновала, и я давал ему спокойно умереть: дамп уже был у меня на диске, так что я просто запускал отладчик снова и импортировал дамп, после чего продолжал реверс-инжиниринг как ни в чём не бывало.
Не хочу сделать вид, будто бы в моём плагине есть что-то особенное, что помогает спасти данные в катастрофических обстоятельствах. Он занимает несколько тысяч строк кода, но, если отбросить обработку всех возможных ошибок, защиту от дурака, красивое форматирование выходного файла и прочее, код перечисления и дампинга меток и комментариев можно уместить в пару десятков строк.
Здесь Findname() и Findnextname() — API-функции, которые OllyDbg предоставляет плагинописателям.
void DumpMarkupEx(FILE * fiOutput, int iNameType, char* pszNameType, ulong vaStart, ulong vaLimit)
{
ulong vaCur;
char rgchName[TEXTLEN];
Findname(vaStart-1, iNameType, NULL);
while(vaCur = Findnextname(rgchName) && vaCur= vaStart) fprintf(fiOutput, "%5s %.8x %s\n", pszNameType, vaCur, rgchName);
}
void DumpMarkup(FILE * fiOutput, ulong vaStart, ulong vaLimit)
{
DumpMarkupEx(fiOutput, NM_LABEL, "LABEL", vaStart, vaLimit
DumpMarkupEx(fiOutput, NM_COMMENT, "CMT", vaStart, vaLimit)
} В реальности пользоваться таким кодом не стоит: длина возвращаемого строкового значения ограничена константой TEXTLEN только на бумаге в документации, а фактически же ограничена только объёмом доступной памяти, так что API-функция Findnextname() с радостью переполнит ваш буфер rgchName со всеми вышеперечисленными последствиями. В моём плагине используется более замысловатый подход.
Тем не менее, в экстренных ситуациях даже такой код может быть скомпилирован и инжектирован в умирающий процесс OllyDbg. Точнее мог бы быть, потому что предназначение этой статьи — показать совершенно другой подход к спасению разметки/наработок, нежели вот эту фишку с перенаправлением выполнения в специальный плагин.
Зависание намертво
В этом случае потеря данных происходит потому, что, устав ждать, мы убиваем зависший процесс OllyDbg. Но и тут, как в случае с исключением, мы можем подключиться к зависшему процессу OllyDbg каким-либо отладчиком (например, тем же OllyDbg) и попытаться устранить зависание.
По моей собственной статистике зависания происходят на порядок чаще, чем внезапные вылеты из-за исключения. После подключения к отладчику с помощью другого отладчика можно увидеть, что зависший отладчик застрял и крутится в каком-нибудь бесконечном цикле. Тогда можно попытаться либо прервать этот бесконечный цикл (сфальсифицировав выходное условие для цикла), либо сделать принудительную раскрутку (unwinding) стека, вернув выполнение сразу в message loop. С тех пор, как у меня был мой плагин Markup Dumper, я больше не воевал с бесконечными циклами, а поступал ровно так же, как и в случае с вылетами из-за исключения — насильно менял значение EIP так, чтобы он указывал на сохраняющую функцию из плагина, формировал стековый фрейм и запускал выполнение дальше — код плагина дампил всё, что нужно, в текстовый файл, после чего я спокойно убивал зависший процесс отладчика и запускал новый, импортировав дамп.
Однако лишь в 10—20% случаев зависания в нём виноват сам OllyDbg и возникший в его коде бесконечный цикл. В 80—90% случаев причина зависания была в том, что OllyDbg вызвал какую-нибудь WinAPI-функцию, та дошла до системного вызова, поток перешёл в режим ядра и продолжил выполнение кода ядра, и именно в ядре возник тот самый бесконечный цикл. А если быть точнее, то обычно там был даже не бесконечный цикл, а какой-нибудь вызов NtWaitForSingleObject, сделанный в режиме ядра. В итоге поток просто засыпал в wait-состоянии, ожидал на каком-нибудь объекте синхронизации, который всё никак не удовлетворял это ожидание. Пока не прервётся бесконечный цикл в ядерной части Windows или пока не устранится deadlock, возврата из режима ядра в пользователький режим не произойдёт. Проблема в том, что ждать этого возврата почти не имеет смысла и надежды.
Когда поток перешёл в режим ядра и застрял в ядерном режиме, OllyDbg не имеет никакого контроля над тем, что делает поток. Нет возможности остановить выполнение зависшего потока, нет возможности переместить выполнение на произвольную инструкцию (команда меню New origin here или правка EIP). Ведь что функция New Origin Here, что правка EIP или других регистров процессора — всё это реализуется через обычную WinAPI-функцию SetThreadContext(). Наивно полагать, что Windows позволила бы нам в произвольный момент времени поменять контекст потока, находящегося в привилегированном режиме — это была бы уязвимость галактического масштаба. Настолько же бесполезна отправка зависшему таким образом потоку APC. Чудо не произойдёт и поток не «вынырнет» из режима ядра для обработки нашей APC.
В целом, это скорее проблема Windows, чем проблема OllyDbg, что наличие в системе активного отладчика, присоединённого к процессу, увеличивает вероятность наступления deadlock-а в ядре, но в идеальном отладчике поток, обслуживающий UI отладчика и позволяющий отладчику оставаться живым и интерактивным для пользователя, и поток, который делает обращения к системе для манипулирования отлаживаемым процессом (WaitForDebugEvent, ReadProcessMemory, WriteProcessMemory) — это должны быть разные потоки. И если бы я писал свой идеальный отладчик, то был бы ещё третий watchdog-поток, который в случае зависания GUI-потока создавал бы консольное окно и в нём бы запускал текстовую версию (с использованием псевдографики в том числе) интерфейса отладчика. Как я уже писал выше, устроить коллапс в оконных приложениях тем же сошедшим с ума Spy++ гораздо проще, чем поломать функциональность консольных окон.
Тем не менее, и из такой ситуации, когда главный поток OllyDbg намертво завис в ядре, был очень простой выход. Поскольку OllyDbg — однопоточный по своей природе, при условии, что главный поток усыплён, код самого отладчика и плагина почти во всех случаях можно было запустить в рамках другого потока. Использование глобальных переменных, а не TLS означает, что код, выполняющийся в другом потоке, увидит ровно те же данные, что увидел бы этот же код, выполняйся он в рамках основного потока. Тот факт, что основной поток спит, гарантирует, что синхронного доступа к одним и тем же глобальным объектам, обращения к которым нужно синхронизировать/сериализировать, не произойдёт.
Так что в случае подобных зависаний я формировал где-нибудь в конце секции кода OllyDbg крохотный переходничок, вызывающий спасительную функцию из моего плагина и порождал новый поток с точкой входа на этом переходничке с помощью CreateRemoteThread().
push param1
push param2
push param3
call <адрес_функции_из_моего_плагина>
int3
int3
int3Функция из плагина вызывалась в рамках отдельного потока (только что созданного), сохраняла дамп, после чего новый поток вставал на int3 — в этот момент можно было убивать зависший отладчик и запускать заново, подгрузив дамп из файла (как и в ранее описанных сценариях) и продолжать работу по реверс-инжинирингу.
Это был обзор контрмер, которые помогали спасти наработки отладочной сессии, в случае, когда OllyDbg завис или рухнул. Я пользовался этими трюками последние годы и они выручали, позволяя меньше чем за минуту исправить ситуацию. Но недавно произошёл из ряда вон выходящий случай, когда подобные решения оказались попросту неприемлемыми и неосуществимыми.
Пришлось очень оперативно найти новое решение, которое оказалось универсальным и покрывало не только этот особый случай, но и все описанные до этого.
Особый случай
Формально то, что произошло, может быть отнесено к категории №2 — внезапный вылет из-за необработанного исключения. Но отличие от вышеописанных случаев заключалось в том, какое именно исключение произошло и по поводу чего.
В момент «вылета» появилось следующее сообщение об ошибке: 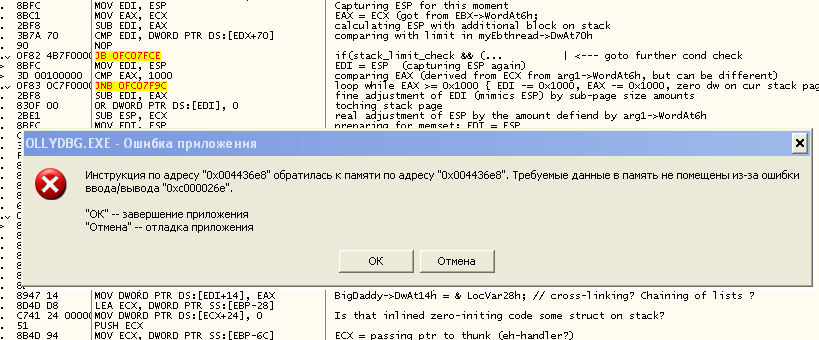
Внимание привлекла к себе необычная формулировка, необычный код исключения 0xC000026E (вовсе не тот привычный 0xC000005 — STATUS_ACCESS_VIOLATION, характерный для доступа по неправильному адресу и/или
