Ограничение скорости передачи трафика. Policer или shaper, что использовать в сети?

Когда речь заходит об ограничении полосы пропускания на сетевом оборудовании, в первую очередь в голову приходят две технологи: policer и shaper. Policer ограничивает скорость за счёт отбрасывания «лишних» пакетов, которые приводят к превышению заданной скорости. Shaper пытается сгладить скорость до нужного значения путём буферизации пакетов. Данную статью я решил написать после прочтения заметки в блоге Ивана Пепельняка (Ivan Pepelnjak). В ней в очередной раз поднимался вопрос: что лучше — policer или shaper. И как часто бывает с такими вопросами, ответ на него: всё зависит от ситуации, так как у каждой из технологий есть свои плюсы и минусы. Я решил разобраться с этим чуточку подробнее, путём проведения нехитрых экспериментов. Полученные результаты подкатом.
И так, начнём с общей картинки разницы между policer и shaper.
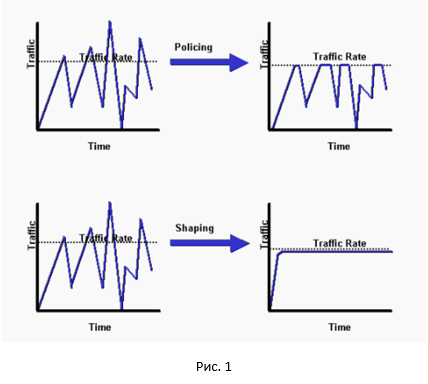
Как видно, policer срезает все пики, shaper же делает сглаживание нашего трафика. Достаточно неплохое сравнение между policer и shaper можно найти здесь.
Обе технологии в своей основе используют механизм токенов (token). В этом механизме присутвует виртуальное ограниченное по размеру ведро (token bucket), в которое с некой регулярностью поступают токены. Токен, как проездной, расходуется для передачи пакетов. Если токенов в ведре нет, то пакет отбрасывается (могут выполняться и другие действия). Таким образом, мы получаем постоянную скорость передачи трафика, так как токены поступают в ведро в соответствии с заданной скоростью.
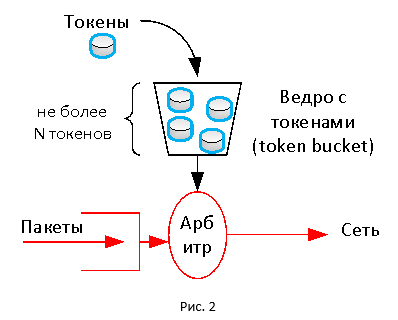
Механизм токенов позволяет обеспечить гибкость в настройке ограничения скорости. Размер ведра влияет на то, как мы будем усреднять нашу скорость. Если ведро большое (т.е. токенов там может скопиться много), мы позволим трафику сильнее «выпрыгивать» за отведенные ограничения в определённые моменты времени (эквивалент усреднения на большем промежутке времени). Если размер ведра маленький, то трафик будет более равномерный, крайне редко превышая заданный порог (эквивалент усреднения на маленьком промежутке времени).
В случае policer«а наполнение ведра происходит каждый раз, когда приходит новый пакет. Количество токенов, которые загружаются в ведро, зависит от заданной скорости policer«а и времени, прошедшего с момента поступления последнего пакета. Если токенов в ведре нет, policer может отбросить пакеты или, например, перемаркировать их (назначить новые значения DSCP или IPP). В случае shaper«а наполнение ведра происходит через равные промежутки времени независимо от прихода пакетов. Если токенов не хватает, пакеты попадают в специальную очередь, где ждут появления токенов. За счёт этого имеем сглаживание. Но если пакетов приходит слишком много, очередь shaper«а в конечном счёте переполняется и пакеты начинают отбрасываться. Стоит отметить, что приведённое описание является упрощённым, так как и policer и shaper имеют вариации (детальный разбор данных технологий займёт объём отдельной статьи).
Эксперимент
А как это выглядит на практике? Для этого соберём тестовый стенд и проведём следующий эксперимент. Наш стенд будет включать устройство, которое поддерживает технологии policer и shaper (в моём случае — это Cisco ISR 4000; подойдёт устройство любого вендора аппаратное или программное, которое поддерживает данные технологии), генератор трафика iPerf и анализатор трафика Wireshark.
Сначала посмотрим на работу policer. Настроим ограничение скорости равным 20 Мбит/с.
policy-map Policer_20
class class-default
police 20000000
interface GigabitEthernet0/0/1
service-policy output Policer_20В iPerf запускаем генерацию трафика в рамках четырёх потоков, используя протокол TCP.
C:\Users\user>iperf3.exe -c 192.168.115.2 -t 20 -i 20 -P 4
Connecting to host 192.168.115.2, port 5201
[ 4] local 192.168.20.8 port 55542 connected to 192.168.115.2 port 5201
[ 6] local 192.168.20.8 port 55543 connected to 192.168.115.2 port 5201
[ 8] local 192.168.20.8 port 55544 connected to 192.168.115.2 port 5201
[ 10] local 192.168.20.8 port 55545 connected to 192.168.115.2 port 5201
[ ID] Interval Transfer Bandwidth
[ 4] 0.00-20.01 sec 10.2 MBytes 4.28 Mbits/sec
[ 6] 0.00-20.01 sec 10.6 MBytes 4.44 Mbits/sec
[ 8] 0.00-20.01 sec 8.98 MBytes 3.77 Mbits/sec
[ 10] 0.00-20.01 sec 11.1 MBytes 4.64 Mbits/sec
[SUM] 0.00-20.01 sec 40.9 MBytes 17.1 Mbits/sec
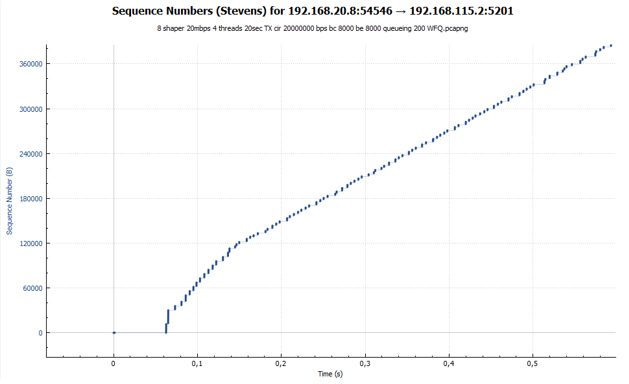
Средняя скорость составила 17.1 Мбит/с. Каждая сессия получила разную полосу пропускания. Обусловлено это тем, что настроенный в нашем случае policer не различает потоки и отбрасывает любые пакеты, которые превышают заданное значение скорости.
С помощью Wireshark собираем дамп трафика и строим график передачи данных, полученный на стороне отправителя.
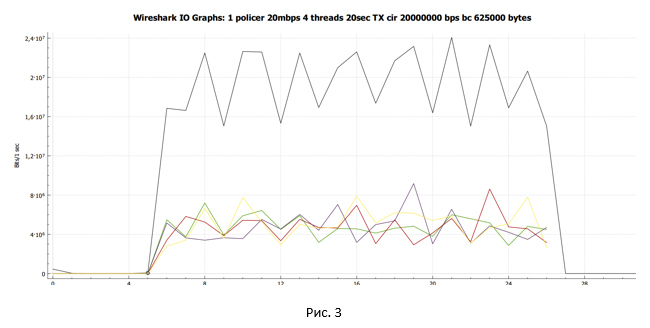
Чёрная линия показывают суммарный трафик. Разноцветные линии — трафик каждого потока TCP. Прежде чем делать какие-то выводы и углубляться в вопрос, давайте посмотрим, что у нас получится, если policer заменить на shaper.
Настроим shaper на ограничение скорости 20 Мбит/с.
policy-map Shaper_20
class class-default
shape average 20000000
queue-limit 200 packets
interface GigabitEthernet0/0/1
service-policy output Shaper_20При настройке используем автоматическое выставляемое значение размера ведра токенов BC и BE равное 8000. Но меняем размер очереди с 83 (по умолчанию в версии IOS XE 15.6(1)S2) на 200. Сделано это сознательно, чтобы получить более чёткую картину, характерную для shaper«а. На этом вопросе мы остановимся более подробно в подкате «Влияет ли глубина очереди на нашу сессию?».
cbs-rtr-4000#sh policy-map interface gigabitEthernet 0/0/1
Service-policy output: Shaper_20
Class-map: class-default (match-all)
34525 packets, 50387212 bytes
5 minute offered rate 1103000 bps, drop rate 0000 bps
Match: any
Queueing
queue limit 200 packets
(queue depth/total drops/no-buffer drops) 0/0/0
(pkts output/bytes output) 34525/50387212
shape (average) cir 20000000, bc 80000, be 80000
target shape rate 20000000
В iPerf запускаем генерацию трафика в рамках четырёх потоков, используя протокол TCP.
C:\Users\user>iperf3.exe -c 192.168.115.2 -t 20 -i 20 -P 4
Connecting to host 192.168.115.2, port 5201
[ 4] local 192.168.20.8 port 62104 connected to 192.168.115.2 port 5201
[ 6] local 192.168.20.8 port 62105 connected to 192.168.115.2 port 5201
[ 8] local 192.168.20.8 port 62106 connected to 192.168.115.2 port 5201
[ 10] local 192.168.20.8 port 62107 connected to 192.168.115.2 port 5201
[ ID] Interval Transfer Bandwidth
[ 4] 0.00-20.00 sec 11.6 MBytes 4.85 Mbits/sec
[ 6] 0.00-20.00 sec 11.5 MBytes 4.83 Mbits/sec
[ 8] 0.00-20.00 sec 11.5 MBytes 4.83 Mbits/sec
[ 10] 0.00-20.00 sec 11.5 MBytes 4.83 Mbits/sec
[SUM] 0.00-20.00 sec 46.1 MBytes 19.3 Mbits/sec
Средняя скорость составила 19.3 Мбит/с. При этом каждый поток TCP получил примерно одинаковую полосу пропускания.
С помощью Wireshark собираем дамп трафика и строим график передачи данных, полученный на стороне отправителя.
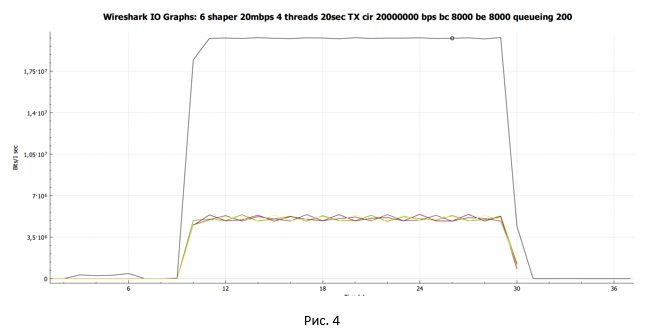
Чёрная линия показывают суммарный трафик. Разноцветные линии — трафик каждого потока TCP.
Сделаем первые промежуточные выводы:
- В случае policer полезная пропускная способность составила 17.1 Мбит/с. Каждый поток в разные моменты времени имел разную полосу пропускания.
- В случае shaper полезная пропускная способность составила 19.3 Мбит/с. Все потоки имели примерно одинаковую полосу пропускания.
Посмотрим более детально на поведение TCP сессии в случае работы policer и shaper. Благо, в Wireshark достаточно инструментов, чтобы сделать такой анализ.
Начнём c графиков, на которых отображаются пакеты с привязкой ко времени их передачи. Первый график — policer«а, второй — shaper«а.
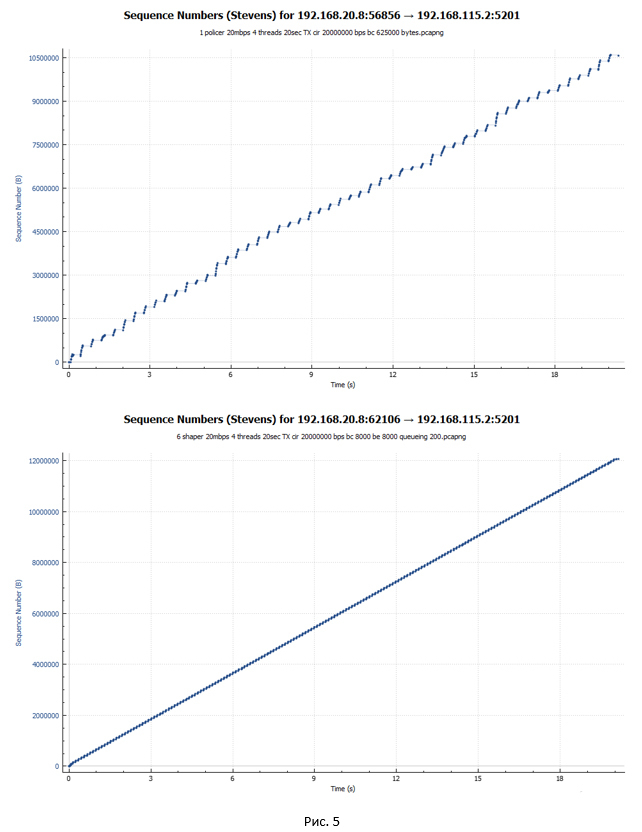
Из графиков видно, что пакеты в случае shaper передаются более равномерно по времени. При этом в случае policer видны скачкообразные разгоны сессии и периоды пауз.
Анализ TCP сессии при работе policer
Посмотрим поближе на сессию TCP. Будем рассматривать случай policer«а.
Протокол TCP в своей работе опирается на достаточно большой набор алгоритмов. Среди них для нас наиболее интересными являются алгоритмы, отвечающие за управление перегрузками (congestion control). Именно они отвечают за скорость передачи данных в рамках сессии. ПК, на котором запускался iPerf, работает под управлением Windows 10. В Windows 10 в качестве такого алгоритма используется Compound TCP (CTCP). CTCP в своей работе позаимствовал достаточно многое из алгоритма TCP Reno. Поэтому при анализе TCP сессии достаточно удобно посматривать на картинку с состояниями сессии при работе алгоритма TCP Reno.
На следующей картинке представлен начальный сегмент передачи данных.
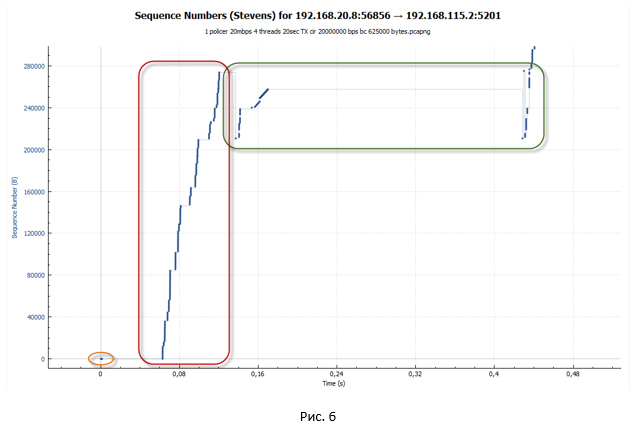
- На первом этапе у нас устанавливается TCP сессия (происходит тройное рукопожатие).
- Далее начинается разгон TCP сессии. Работает алгоритм TCP slow-start. По умолчанию значение окна перегрузки (congestion window — cwnd) для TCP-сессии в Windows 10 равно 10. Это означает, что данный ПК может отправить сразу 10 пакетов, не дожидаясь получения подтверждения на них в виде ACK. В качестве начального значения порога прекращения работы алгоритма slow-start (ssthresh) и перехода в режим избегания перегрузки (congestion avoidence) берётся значение максимального окна, которое предоставил получатель (advertised window — awnd). В нашем случае ssthresh=awnd=64K. Awnd — максимальное значение данных, которые получатель готов принять себе в буфер.Где посмотреть начальные данные сессии?Чтобы посмотреть параметры TCP, можно воспользоваться PowerShell.
Смотрим, какой глобальный шаблон TCP используется в нашей системе по умолчанию.

Далее выполняем запрос «Get-NetTCPSetting Internet» и ищем значение величины InitialCongestionWindow (MSS).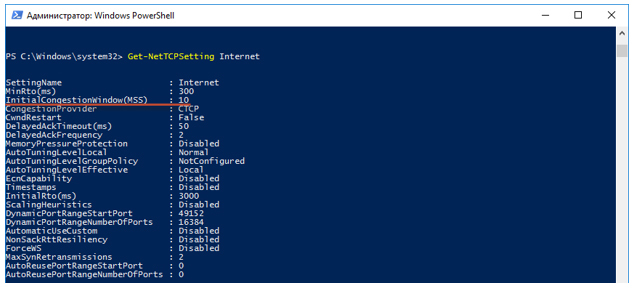
Значение awnd можно найти в пакетах ACK, пришедших от получателя: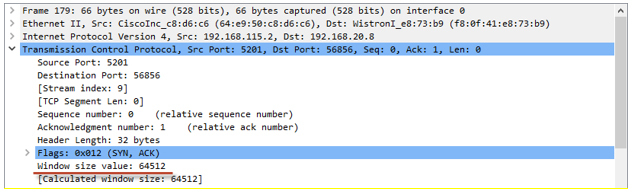
В режиме TCP slow-start размер окна (cwnd) увеличивается каждый раз при получении ACK. При этом оно не может превысить значение awnd. За счёт такого поведения, мы имеем практически экспоненциальный рост количества передаваемых пакетов. Наша TCP сессия разгоняется достаточно агрессивно.Передача пакетов в режиме TCP slow-start- ПК устанавливает TCP-соединение (№1–3).
- Отправляет 10 пакетов (№4–13), не дожидаясь подтверждения (ACK), так как cwnd=10.
- Получает ACK (№14), который подтверждает сразу два пакета (№4–5).
- Увеличивает размер окна Cwnd=10+2=12.
- Отправляет дополнительно три пакета (№15–17). По идее ПК должен был отправить четыре пакета: два, так как он получил подтверждение на два пакета, которые были переданы ранее; плюс два пакета из-за увеличения окна. Но в реальности на самом первом этапе система шлёт (2N-1) пакетов. Найти ответ на этот вопрос мне не удалось. Если кто-то подскажет, буду благодарен.
- Получает два ACK (№18–19). Первое ACK подтверждает получение удалённой стороной четырёх пакетов (№6–9). Второе — трёх (№10–12).
- Увеличивает размер окна Cwnd=12+7=17.
- Отправляет 14 пакетов (№20–33): семь новых пакетов, так как получили ACK на семь ранее переданных пакетов, и ещё семь новых пакетов, так как увеличилось окно.
- И так далее.
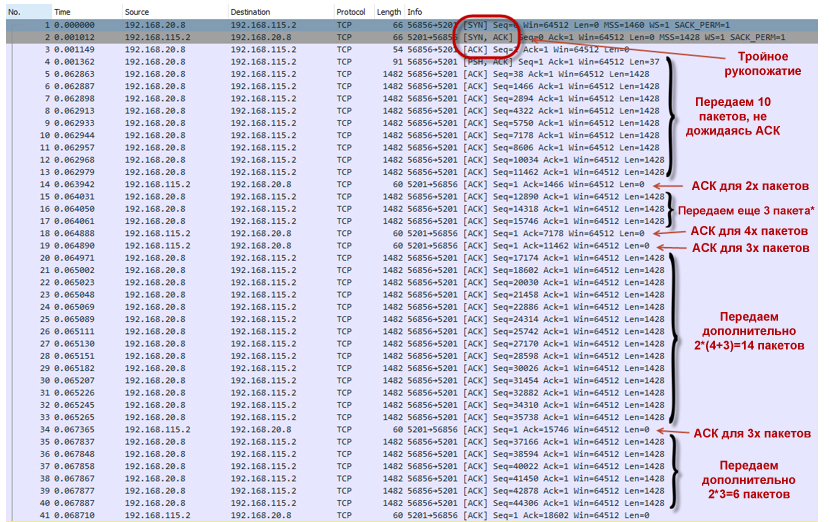
- Policer никак не препятствует разгону сессии. Токенов в ведре много (при инициализации policer«а ведро заполнено токенами полностью). Для скорости 20 Мбит/с размер ведра по умолчанию выставляется равным 625000 байт. Таким образом, сессия разгоняется в момент времени практически до 18 Мбит/с (а мы помним, что у нас таких сессий четыре). Размер окна cwnd достигает максимального значения и становится равным awnd, а значит, cwnd = ssthersh. cwnd = ssthershКогда cwnd = ssthersh точного ответа, произойдёт ли смена алгоритма с slow-start на алгоритм congestion avoidance, я найти не смог. RFC точного ответа не даёт. С практической точки зрения это не очень важно, так как размер окна дальше расти не может.
- Так как наша сессия разогналась достаточно сильно, токены очень быстро тратятся и в конечном итоге заканчиваются. Ведро не успевает наполнятся (наполнение токенами идёт для скорости 20 Мбит/с, при этом суммарная утилизация всеми четырьмя сессиями в моменте времени приближается к 80 Мбит/с). Policer начинает отбрасывать пакеты. А значит, до удалённой стороны они не доходят. Получатель шлёт Duplicate ACK (Dup ACK), которые сигнализируют отправителю, что произошла потеря пакетов и нужно передать их заново.
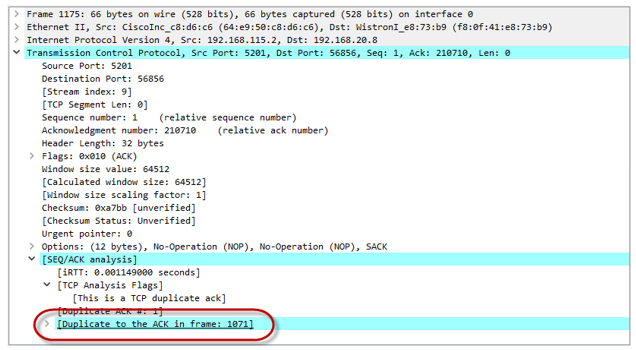
После получения трёх Dup ACK наша TCP сессия переходит в фазу восстановления после потери (loss recovery, включающую алгоритмы Fast Retransmit/Fast Recovery). Отправитель устанавливает новое значение ssthresh = cwnd/2 (32K) и делает окно cwnd = ssthresh+3.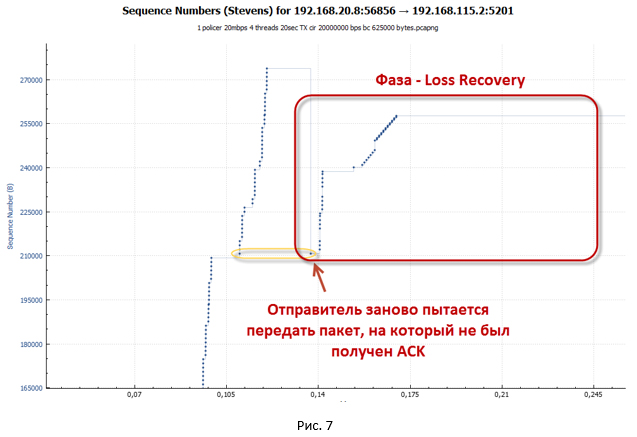
- Отправитель пытается сразу же начать заново передать потерянные пакеты (работает алгоритм TCP Fast Retransmission). При этом продолжают приходить Dup ACK, назначение которых — искусственно увеличить окно cwnd. Это нужно, чтобы как можно быстрее восстановить скорость сессии из-за потери пакетов. За счёт Dup ACK окно cwnd вырастает до максимального значения (awnd).
Как только было отправлено количество пакетов, укладывающихся в окно cwnd, система останавливается. Для продолжения передачи данных ей нужны новые ACK (не Dup ACK). Но ACK не приходят. Все повторные пакеты отбрасываются policer«ом, так в ведре закончились токены, а времени, чтобы их восполнить, прошло слишком мало. - В таком состоянии система ждёт, пока не сработает таймаут на получение нового ACK от удалённой стороны (Retransmission timeout — RTO). С этим как раз и связаны наши большие паузы, которые видны на графиках.
- После срабатывания таймера RTO система переходит в режим slow-start и устанавливает ssthresh = FlightSize/2 (где FlightSize — количество не подтверждённых данных), а окно cwnd = 1. Далее снова делается попытка передать потерянные пакеты. Правда, теперь отправляется всего один пакет, так как cwnd = 1.
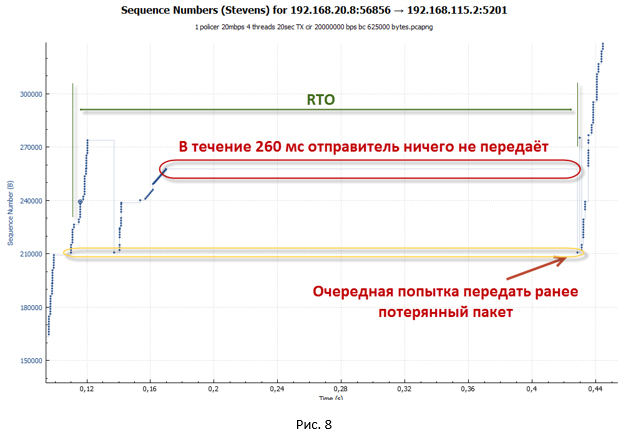
- Так как в течение некоторого времени система ничего не передавала, в нашем ведре успели накопиться токены. Поэтому в конечном итоге пакет доходит до получателя. А значит, мы получим новое ACK. С этого момента система начинает передать потерянные ранее пакеты в режиме slow-start. Происходит разгон сессии. Как только размер окна cwnd превышает значение ssthresh, сессия переходит в режим congestion avoidance.
В алгоритме Compound TCP для регулирования скорости передачи используется окно отправителя (sending window — wnd), которое зависит от двух взвешенных величин: окна перегрузки (cwnd) и окна задержки (delay window — dwnd). Cwnd, как и раньше, зависит от полученных ACK, dwnd зависит от величины задержки RTT (round trip time). Окно wnd растёт только один раз за период времени RTT. Как мы помним, в случае slow-start окно cwnd росло при получении каждого ACK. Поэтому в режиме congestion avoidance сессия разгоняется не так быстро. - Как только сессия разгоняется достаточно сильно (когда пакетов передаётся больше, чем есть токенов в ведре), опять срабатывает policer. Начинают отбрасываться пакеты. Далее следует фаза loss recovery. Т.е. весь процесс повторяется заново. И так продолжается, пока у нас не завершится передача всех данных.
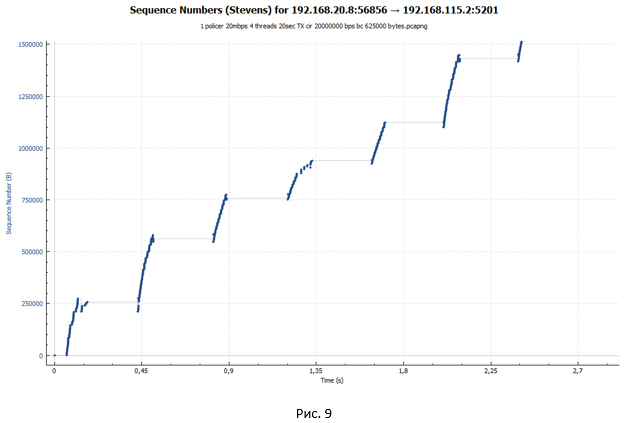
TCP сессия при работе policer выглядит как лестница (идёт фаза передачи, за которой следует пауза).
Анализ TCP сессии при работе shaper
Теперь давайте посмотрим поближе на сегмент передачи данных для случая shaper. Для наглядности возьмём аналогичный масштаб, как и для графика policer на Рис. 6.
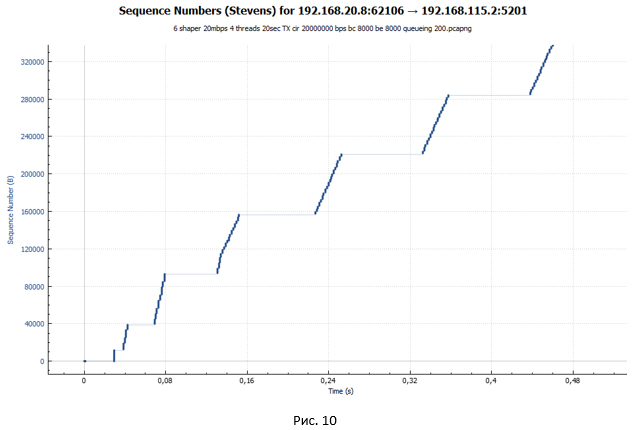
Из графика мы видим всё ту же лесенку. Но размер ступенек стал существенно меньше. Однако если приглядеться к графику на Рис. 10, мы не увидим небольших «волн» на конце каждой ступеньки, как это было на Рис. 9. Такие «волны» были следствием потери пакетов и попыток их передачи заново.
Рассмотрим начальный сегмент передачи данных для случая shaper.
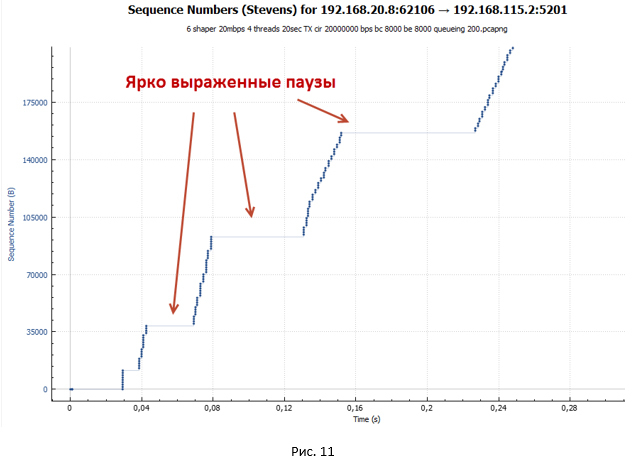
Происходит установление сессии. Далее начинается разгон в режиме TCP slow-start. Но этот разгон более пологий и имеет ярко выраженные паузы, которые увеличиваются в размере. Более пологий разгон обусловлен тем, что размер ведра по умолчанию для shaper всего (BC+BE) = 20 000 байт. В то время как для policer размер ведра — 625 000 байт. Поэтому shaper срабатывает существенно раньше. Пакеты начинают попадать в очередь. Растёт задержка от отправителя к получателю, и ACK приходят позже, чем это было в случае policer. Окно растёт существенно медленнее. Получается, что чем больше система передаёт пакетов, тем больше их накапливается в очереди, а значит, тем больше задержка в получении ACK. Имеем процесс саморегуляции.
Через некоторое время окно cwnd достигает значения awnd. Но к этому моменту у нас накапливается достаточно ощутимая задержка из-за наличия очереди. В конечном итоге при достижении определённого значения RTT наступает равновесное состояние, когда скорость сессии больше не меняется и достигает максимального значения для данного RTT. В моём примере среднее RTT равно 107 мс, awnd=64512 байт, следовательно, максимальная скорость сессии будет соответствовать awnd/RTT= 4.82 Мбит/с. Примерно такое значение нам и выдал iPerf при измерениях.
Но откуда берутся ярко выраженные паузы в передаче? Давайте посмотрим на график передачи пакетов через устройство с shaper в случае, если у нас всего одна TCP сессия (Рис. 12). Напомню, что в нашем эксперименте передача данных происходит в рамках четырёх TCP сессий.
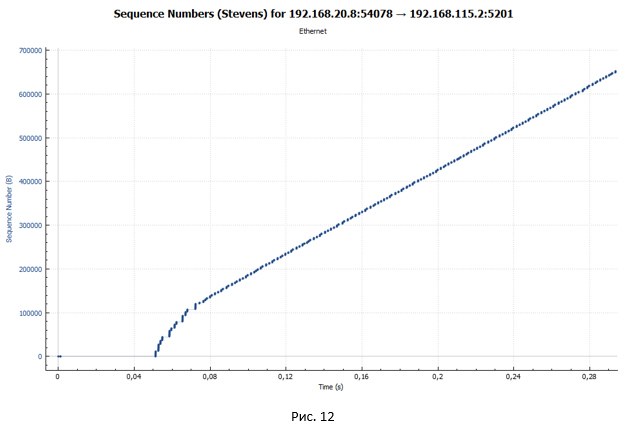
На этом графике очень хорошо видно, что нет никаких пауз. Из этого можно сделать вывод, что паузы на Рис. 10 и 11 обусловлены тем, что у нас одновременно передаётся четыре потока, а очередь в shaper одна (тип очереди FIFO).
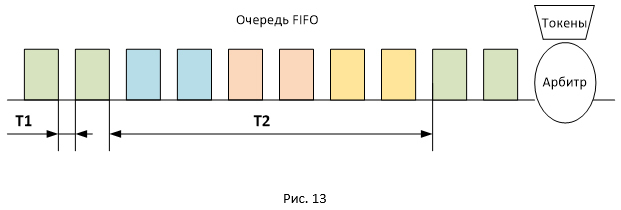
На Рис. 13 представлено расположение пакетов разных сессий в очереди FIFO. Так как пакеты передаются пачками, они будут располагаться в очереди таким же образом. В связи с этим задержка между поступлением пакетов на приёмной стороне будет двух типов: T1 и T2 (где T2 существенно превосходит T1). Общее значение RTT для всех пакетов будет одинаковым, но пакеты будут приходить пачками, разнесёнными по времени на значение T2. Вот и получаются паузы, так как в момент времени T2 никакие ACK к отправителю не приходят, при этом окно сессии остаётся неизменным (имеет максимальное значение равное awnd).
policy-map Shaper
class shaper_class
shape average 20000000
queue-limit 200 packets
fair-queue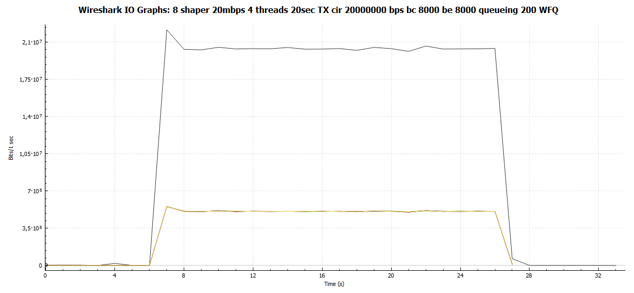
Из общего графика мы сразу видим, что графики всех четырёх TCP сессий идентичны. Т.е. все они получили одинаковую полосу пропускания.
А вот и наш график распределения пакетов по времени передачи ровно в том же масштабе, что и на Рис. 11. Никаких пауз нет.
Стоит отметить, что очередь типа WFQ позволит нам получить не только более равномерное распределение полосы пропускания, но и предотвратить «забивание» одного типа трафика другим. Мы всё время говорили про TCP, но в сети также присутствует и UDP трафик. UDP не имеет механизмов подстройки скорости передачи (flow control, congestion control). Из-за этого UDP трафик может с лёгкостью забить нашу общую очередь FIFO в shaper«е, что драматически повлияет на передачу TCP. Напомню, что, когда очередь FIFO полностью заполнена пакетами, по умолчанию начинает работать механизм tail-drop, при котором отбрасываются все вновь пришедшие пакеты. Если у нас настроена очередь WFQ, каждая сессия пережидает момент буферизации в своей очереди, а значит, сессии TCP будут отделены от сессий UDP.
Самый главный вывод, который можно сделать после анализов графиков передачи пакетов при работе shaper«а — у нас нет потерянных пакетов. Из-за увеличения RTT скорость сессии адаптируется к скорости shaper«а.
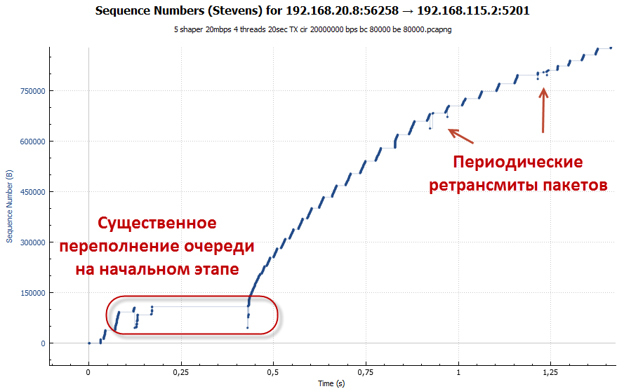
При глубине в 83 пакета очередь переполняется быстрее, нежели достигается нужное значение RTT. Пакеты отбрасываются. Особенно ярко это проявляется на начальном этапе, когда у нас работает механизм TCP slow-start (сессия разгоняется максимально агрессивно). Стоит отметить, что количество отброшенных пакетов несравнимо меньше, чем в случае с policer, так как увеличение RTT приводит к тому, что скорость сессии растёт более плавно. Как мы помним, в алгоритме CTCP размер окна в том числе зависит от значения RTT.
Графики утилизации пропускной способности и задержки при работе policer и shaper
В заключение нашего небольшого исследования построим ещё несколько общих графиков, после чего перейдём к анализу полученных данных.
График утилизации пропускной способности:
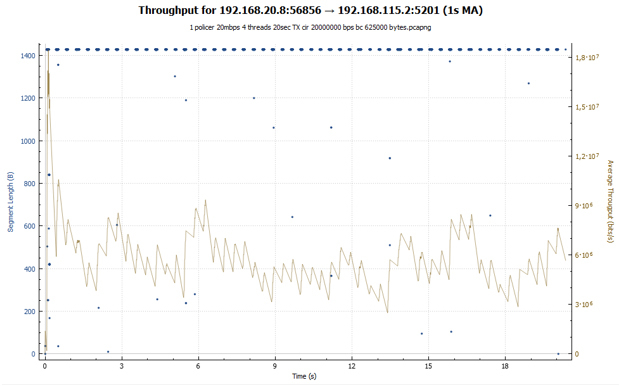
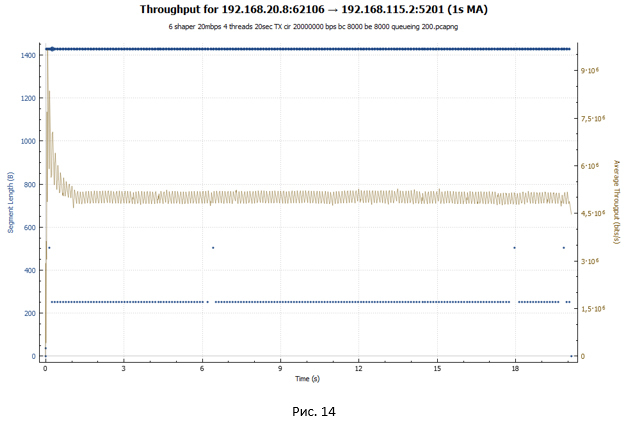
В случае policer мы видим скачкообразный график: сессия разгоняется, потом наступают потери, и её скорость падает. После чего всё повторяется снова. В случае shaper наша сессия получает примерно одинаковую пропускную способность на протяжении всей передачи. Скорость сессии регулируется за счёт увеличения значения RTT. На обоих графиках вначале можно наблюдать взрывной рост. Он обусловлен тем, что наши вёдра изначально полностью заполнены токенами и TCP-сессия, ничем не сдерживаемая, разгоняется до относительно больших значений (в случае shaper это значение на 2 раза меньше).
График задержки RTT для policer и shaper (по-хорошему, это первое о чём мы вспоминаем, когда говорим про shaper):
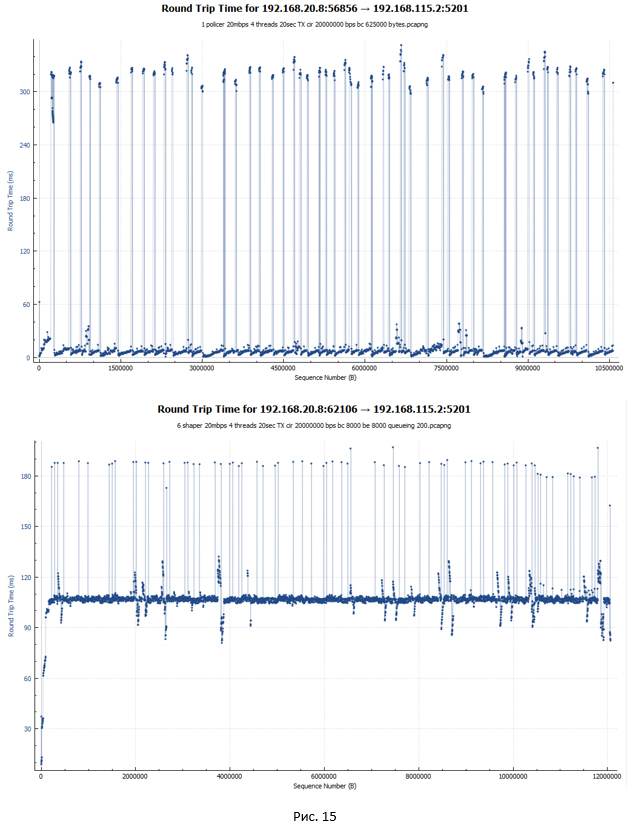
В случае policer (первый график) задержка RTT для большинства пакетов минимальна, порядка 5 мс. На графике также присутствуют существенные скачки (до 340 мс). Это как раз моменты, когда пакеты отбрасывались и передавались заново. Тут стоит отметить, как Wireshark считает RTT для TCP трафика. RTT — это время между отправкой оригинального пакета и получением на него ACK. В связи с этим, если оригинальный пакет был потерян и система передавала пакет повторно, значение RTT растёт, так как точкой отсчёта является в любом случае момент отправки оригинального пакета.
В случае shaper задержка RTT для большинства пакетов составила 107 мс, так как они все задерживаются в очереди. Есть пики до 190 мс.
Выводы
Итак, какие итоговые выводы можно сделать. Кто-то может заметить, что это и так понятно. Но наша цель была капнуть чуточку глубже.
- Shaper предоставляет нам на 13% больше полезной пропускной способности, чем policer (19.3 против 17.1 Мбит/с) при заданном ограничении в 20 Мбит/с.
- В случае shaper полоса пропускания распределяется более равномерно между сессиями. Наилучший показатель может быть получен при включении очереди WFQ. При работе policer«а присутствуют существенные пики и падения скорости для каждой сессии.
- В случае shaper потерь пакетов практически нет (конечно, это зависит от ситуации и глубины очереди). При работе policer«а мы имеем существенные потери пакетов — 12.7%.
Если policer настроен ближе к получателю, наша сеть фактически занимается прокачкой бесполезного трафика, который будет в итоге отброшен policer«ом. Например, в разрезе глобальной сети интернет это может является проблемой, так как трафик режется зачастую ближе к получателю. - В случае shaper у нас появляется задержка (в нашем эксперименте — это дополнительные 102 мс). Если трафик примерно одинаков, без существенных всплесков, очередь shaper«а находится в относительно стабильном состоянии и больших вариаций в задержке (jitter) не будет. Если трафик будет иметь взрывной характер, мы можем получить повышенное значение jitter. Вообще наличие очереди может достаточно негативно сказываться на работе приложений — так называемый эффект излишней сетевой буферизации (Bufferbloat). Поэтому с глубиной очереди надо быть аккуратными.
- Policer и shaper подвержены ситуации, когда UDP трафик может «забить» TCP. При настройке этих технологий необходимо учитывать данный факт.
- Работа shaper создаёт бОльшую нагрузку на сетевое устройство, чем работа policer. Как минимум требуется память под очередь.
Можно отметить ещё один факт, хоть и не относящийся непосредственно к задаче ограничения скорости. Shaper позволяет нам настраивать различные типы очередей (FIFO, WFQ и пр.), обеспечивая тем самым разнообразные уровни приоритезации трафика на любых скоростях. Это очень удобно в случаях, если фактическая скорость передачи трафика отличается от канальной (например, так часто бывает с выходом в интернет или WAN каналами).
Для борьбы с негативным эффектом работы policer«а предлагаются следующие меры в зависимости от точки их применения.
Для интернет-провайдеров:
- В policer«е уменьшить размер ведра (burst size). Это приведёт к тому, что TCP сессия не сможет слишком сильно разогнаться, пока есть свободные токены, и быстрее начнёт адаптацию под реальную пропускную способность.
- Вместо policer«а использовать shaper (с небольшой глубиной очереди).
- Использовать и shaper, и policer одновременно. В этом случае shaper располагается чуть раньше, чем policer. Shaper задерживает пакеты, сглаживая колебания. Из-за такой задержки policer успевает аккумулировать достаточное количество токенов, чтобы передавать трафик. Потери в таком случае минимизируются.
Однозначных рекомендаций по поводу конфигурации shaper в документе не даётся. Shaper может обеспечивать положительный эффект как при большом, так и при маленьком значении размера ведра (даже если BC = 8 000 байт). Также нет однозначной рекомендации по поводу глубины очереди. Маленькая глубина приводит к лишним потерям, большая может негативно сказаться на задержках в сети. Во всех случаях есть свои плюсы и минусы.
Для контент-провайдеров предлагается ограничивать скорость отправки трафика на сервере, чтобы избегать включения policer«а. Но на практике оценить реальную скорость канала не всегда просто. Второй метод — избегать взрывной передачи трафика за счёт модификации алгоритмов TCP: использовать TCP Pacing (отправлять пакеты с привязкой к RTT, а не к моменту получения ACK) и изменить схему работы фазы loss recovery (на каждый полученный ACK слать только один новый пакет).
Таким образом, нет однозначного ответа на вопрос, что лучше использовать: shaper или policer. Каждая технология имеет свои плюсы и минусы. Для кого-то дополнительная задержка и нагрузка на оборудование не так критична, как для другого. А значит выбор делается в сторону shaper. Кому-то важно минимизировать сетевую буферизацию для борьбы с джиттером — значит наша технология policer. В ряде случаев вообще можно использовать одновременно обе эти технологии. Поэтому выбор технологии зависит от каждой конкретной ситуации в сети.
