Оцениваем процессы в команде разработки на основе объективных данных
Разработка софта считается плохо измеримым процессом, и кажется что, чтобы ей эффективно управлять, нужно особое чутье. А если интуиция с эмоциональным интеллектом развиты не очень, то неизбежно будут сдвигаться сроки, проседать качество продукта и падать скорость поставки.
Сергей Семёнов считает, что это происходит в основном по двум причинам.
- Нет инструментов и стандартов для оценки работы программистов. Менеджерам приходится прибегать к субъективной оценке, что в свою очередь приводит к ошибкам.
- Не используются средства автоматического контроля за процессами в команде. Без должного контроля процессы в командах разработки перестают выполнять свои функции, так как начинают исполняться частично или попросту игнорироваться.
И предлагает подход к оценке и контролю процессов на основе объективных данных.
Ниже видео и текстовая версия доклада Сергея, который по результатам зрительского голосования занял второе место на Saint TeamLead Conf.
О спикере: Сергей Семёнов (sss0791) работает в IT 9 лет, был разработчиком, тимлидом, продакт менеджером, сейчас CEO компании GitLean. GitLean — это аналитический продукт для менеджеров, технических директоров и тимлидов, предназначенный для того, чтобы принимать объективные управленческие решения. Большая часть примеров в этом рассказе опирается не только на личный опыт, но и на опыт компаний-клиентов со штатом разработки от 6 до 200 человек.
Про оценку разработчиков мы уже с моим коллегой Александром Киселевым рассказывали в феврале на предыдущей TeamLead Conf. Я не буду на этом подробно останавливаться, а буду ссылаться на статью по некоторым метрикам. Сегодня поговорим о процессах и о том, как их контролировать и измерять.
Источники данных
Если мы говорим об измерениях, хорошо бы понять, откуда брать данные. Прежде всего у нас есть:
- Git с информацией о коде;
- Jira или любой другой task tracker c информацией о задачах;
- GitHub, Bitbucket, Gitlab с информацией о код-ревью.
Кроме того, есть такой крутой механизм, как сбор различных субъективных оценок. Оговорюсь, что его нужно использовать систематически, если мы хотим опираться на эти данные.
Конечно, в данных вас ждет грязь и боль — ничего с этим не поделать, но это еще не так страшно. Самое неприятное, что данных о работе ваших процессов в этих источниках часто может просто не быть. Это может быть потому, что процессы строились так, что никаких артефактов в данных они не оставляют.
Первое правило, которому мы рекомендуем следовать при проектировании и построении процессов, это делать их так, чтобы они оставляли артефакты в данных. Нужно строить не просто Agile, а делать его измеримым (Measurable Agile).
Расскажу страшилку, которую мы встретили у одного из клиентов, который пришел к нам с запросом на улучшение качества продукта. Чтобы вы понимали масштаб — на команду из 15 разработчиков в неделю прилетало примерно 30–40 багов с продакшена. Начали разбираться в причинах, и обнаружили, что 30% задач не попадает в статус «testing». Сначала мы подумали, что это просто ошибка в данных, или тестировщики не обновляют статус задачи. Но оказалось, что действительно 30% задач просто не тестируются. Когда-то была проблема в инфраструктуре, из-за которой 1–2 задачки в итерации не попадали в тестирование. Потом про эту проблему все забыли, тестировщики перестали про неё говорить, и со временем это переросло в 30%. В итоге это привело к более глобальным проблемам.
Поэтому первая важная метрика для любого процесса — это то, что он оставляет данные. За этим обязательно нужно следить.
Иногда ради измеримости приходится жертвовать частью принципов Agile и, например, где-то предпочитать письменную коммуникацию устной.
Очень хорошо себя показала практика Due date, которую мы внедрили в несколько команд ради улучшения прогнозируемости. Суть ее в следующем: когда разработчик берет задачу и перетаскивает ее в «in progress», он должен поставить due date, когда задача будет либо выпущена, либо готова к релизу. Эта практика учит разработчика быть условным микро проджект менеджером своих собственных задач, то есть учитывать внешние зависимости и понимать, что задача готова, только когда клиент может использовать ее результат.
Чтобы происходило обучение, после due date разработчику нужно заходить в Jira и ставить новый due date и оставлять комментарии в специально заданной форме, почему это произошло. Казалось бы, зачем нужна такая бюрократии. Но на самом деле через две недели такой практики мы простым скриптом выгружаем из Jira все такие комментарии и с этой фактурой проводим ретроспективу. Получается куча инсайтов о том, почему срываются сроки. Очень круто работает, рекомендую использовать.
Подход от проблем
В измерении процессов мы исповедуем следующий подход: нужно исходить из проблем. Представляем себе некие идеальные практики и процессы, а дальше креативим, какими способами они могут не работать.
Мониторить нужно нарушение процессов, а не то, как мы следуем какой-то практике. Процессы часто не работают не потому, что люди злонамеренно их нарушают, а потому, что у разработчика и менеджера не хватает контроля и памяти на то, чтобы все их соблюдать. Отслеживая нарушения регламента, мы автоматически можем напоминать людям о том, что нужно делать, и получаем автоматические средства контроля.
Чтобы понять какие процессы и практики нужно внедрять, нужно понимать, зачем это делать в команде разработки, что нужно бизнесу от разработки. Все прекрасно понимают, что нужно не так уж и много:
- чтобы продукт поставлялся за адекватный прогнозируемый срок;
- чтобы продукт был должного качества, не обязательно идеального;
- чтобы всё это было достаточно быстро.
То есть важны прогнозируемость, качество и скорость. Поэтому на все проблемы и метрики мы будем смотреть именно с учетом того, как они влияют на прогнозируемость и качество. Скорость обсуждать почти не будем, потому что из почти 50 команд, с которыми мы так или иначе работали, со скоростью можно было работать только в двух. Для того чтобы повысить скорость, нужно уметь ее измерять, и чтобы она была хоть немного предсказуемой, а это и есть прогнозируемость и качество.
Дополнительно к прогнозируемости и качеству, введем такое направление как дисциплина. Дисциплиной будем называть всё, что обеспечивает базовое функционирование процессов и сбор данных, на основе которых проводится анализ проблем с прогнозируемостью и качеством.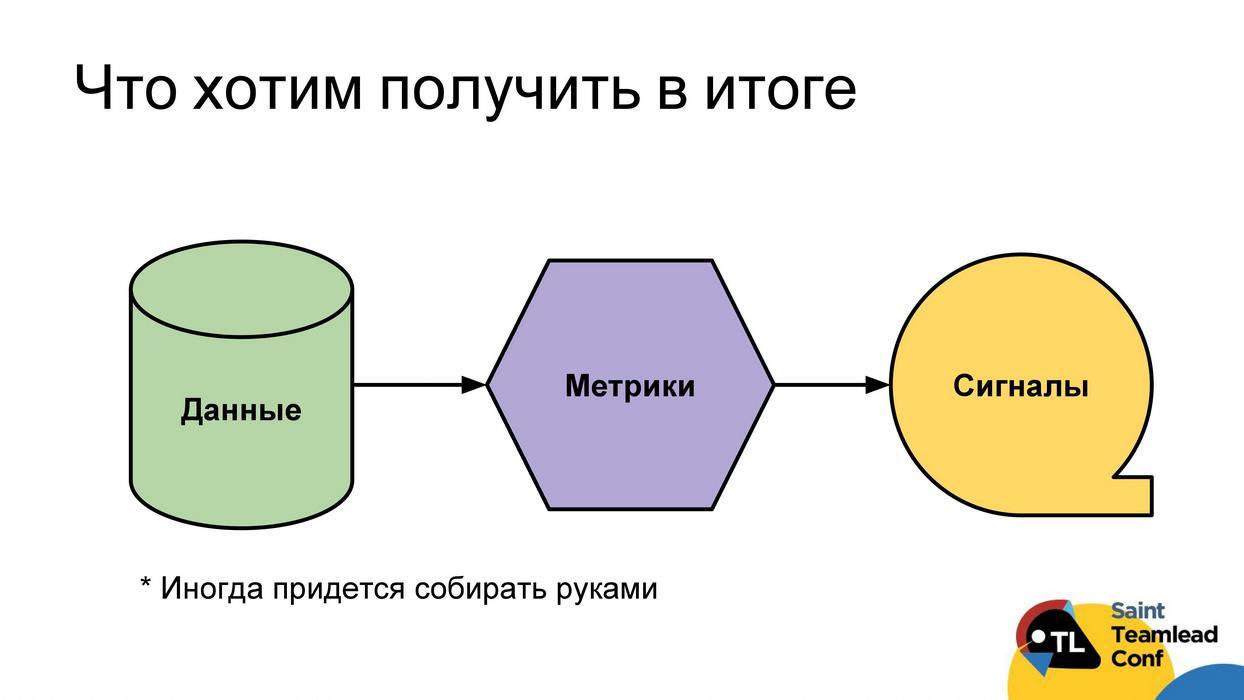
В идеале мы хотим построить следующую схему работы: чтобы у нас был автоматический сбор данных; по этим данным мы могли бы построить метрики; с помощью метрик находить проблемы; сигнализировать о проблемах напрямую разработчику, тимлиду или команде. Тогда все смогут своевременно на них реагировать и справляться с обнаруженными проблемами. Сразу скажу, что дойти до понятных сигналов не всегда получится. Иногда метрики останутся просто метриками, которые придется анализировать, смотреть на значения, тренды и так далее. Даже с данными иногда будет проблема, иногда их нельзя собрать автоматически и приходится делать это руками (буду отдельно уточнять такие случаи).
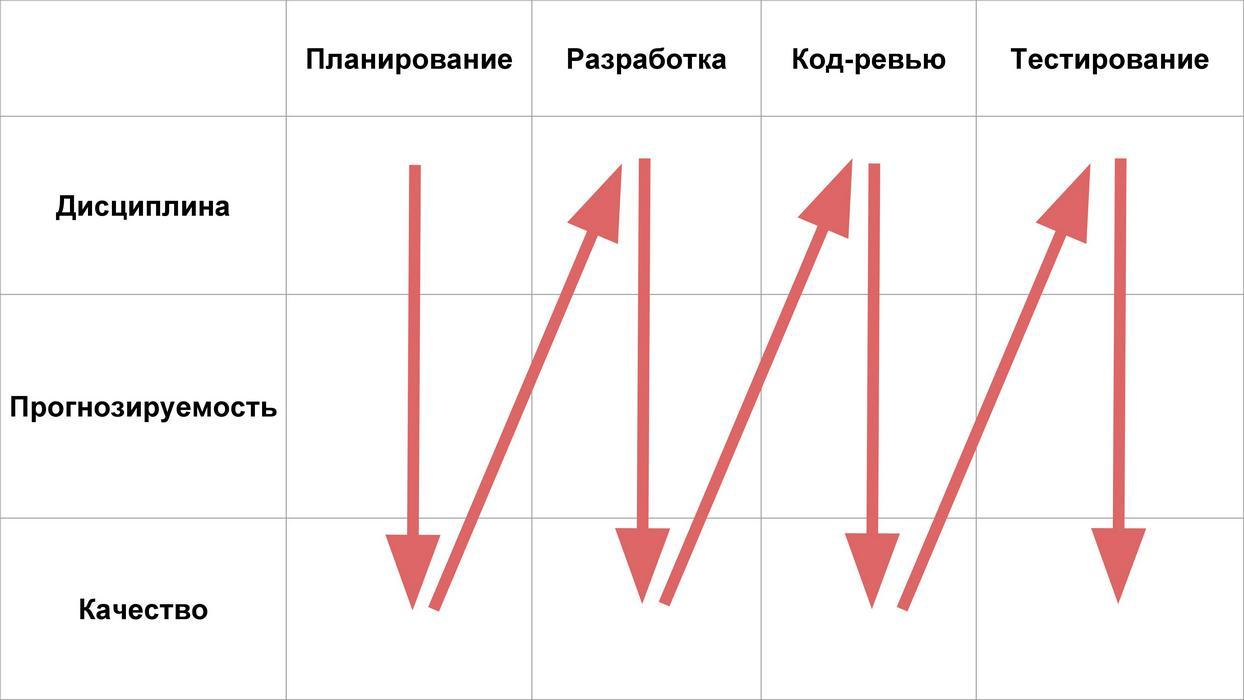
Далее мы рассмотри 4 стадии жизни фичей:
И разберем, какие на каждой из этих стадий могут быть проблемы с дисциплиной, прогнозируемостью и качеством.
Проблемы с дисциплиной на стадии планирования
Информации очень много, но я уделяю внимание самым основным моментам. Они могут показаться достаточно простыми, но с ними сталкивается очень большое количество команд.
Первая проблема, которая часто возникает при планировании, это банально организационная проблема — на митинге планирования присутствуют не все, кто там должен быть.
Пример: команда жалуется, что тестировщик что-то не так тестирует. Выясняется, что тестировщики в этой команде вообще никогда не ходят на планирование. Или вместо того, чтобы сидеть и что-то планировать, команда судорожно ищет место, где присесть, потому что забыла забронировать переговорку.
Метрики и сигналы настраивать не нужно, просто, пожалуйста, убедитесь в том, что у вас нет этих проблем. Митинг отмечен в календаре, на него все приглашены, занято место проведения. Как бы смешно это не звучало, с этим сталкиваются в разных командах.
Теперь обсудим ситуации, в которых сигналы и метрики нужны. На стадии планирования большинство сигналов, о которых я буду говорить, стоит отправлять в команду где-то через час после окончания митинга планирования, чтобы не отвлекать команду в процессе, но чтобы при этом еще сохранялся фокус.
Первая дисциплинарная проблема — у задач нет описания, или они плохо описаны. Это контролируется элементарно. Есть формат, которому должны соответствовать задачи, — проверяем, так ли это. Например, следим, что заданы критерии приемки, или для фронтендовых задач есть ссылка на макет. Еще нужно следить за расставленными компонентами, потому что формат описания часто привязан к компоненту. Для бэкэндовой задачи релевантно одно описание, для фронтендовой — другое.
Следующая частая проблема — приоритеты проговариваются устно или вообще не проговариваются и в данных не отражаются. В результате к концу итерации выясняется, что самые важные задачи так и не были сделаны. Нужно следить за тем, что команда использует приоритеты и использует их адекватно. Если у команды 90% задач в итерации имеют high priority, это всё равно, что приоритетов нет совсем.
Мы стараемся приходить к такому распределению: 20% high priority задач (нельзя не зарелизить); 60% — medium priority; 20% — низкий приоритет (не страшно, если не зарелизим). Навешиваем на всё это сигналы.
Последняя проблема с дисциплиной, которая бывает на стадии планирования — не хватает данных, для последующих метрик в том числе. Базовые из них: у задач нет оценок (следует завести сигнал) или типы задач проставлены неадекватно. То есть баги заводятся как задачи, а задачи технического долга вообще не отследить. К сожалению, автоматически проконтролировать второй тип проблем не получается. Советуем просто раз в пару месяцев, особенно если вы CTO и у вас несколько команд, проглядывать backlog и убеждаться, что люди заводят баги как баги, стори как стори, техдолговые задачи как техдолговые.
Проблемы с прогнозируемостью на стадии планирования
Переходим к проблемам с прогнозируемостью.
Базовая проблема — не попадаем в сроки и оценки, неправильно оцениваем. К сожалению, найти какой-то волшебный сигнал или метрику, которые решат эту проблему, нельзя. Единственный способ — это побуждать команду лучше обучаться, разбирать на примерах причины ошибок с той или иной оценкой. И вот этот процесс обучения можно облегчить при помощи автоматических средств.
Первое, что можно сделать, это разобраться с заведомо проблемными задачами с высокой оценкой времени исполнения. Навешиваем SLA и контролируем, чтобы все задачи были достаточно хорошо декомпозированы. Мы рекомендуем ограничение в максимум два дня на исполнение для начала, а потом можно перейти и к однодневному.
Следующим пунктом можно облегчить сбор артефактов, на которых можно будет проводить обучение и разбирать с командой, почему произошла ошибка с оценкой. Мы рекомендуем для этого использовать практику Due date. Она очень круто себя здесь зарекомендовала.
Еще один способ — это метрика, которая называется Churn кода в рамках задачи. Суть ее в том, что мы смотрим, какой процент кода в рамках задачи был написан, но не дожил до релиза (подробнее в прошлом докладе). Эта метрика показывает, насколько хорошо продумываются задачи. Соответственно, неплохо бы обращать внимание на задачи со скачками Churn и на них разбираться, что мы не учли и почему ошиблись в оценке.
Следующая история стандартная: команда что-то планировала, спринт заполнила, но в итоге делала совсем не то, что запланировала. Настраивать сигналы на вбросы, изменения приоритетов можно, но для большинства команд, с которыми мы так делали, они были нерелевантны. Зачастую это легальные операции со стороны продакт-менеджера что-то вбросить в спринт, изменить приоритет, поэтому будет много ложных срабатываний.
Что тут можно сделать? Посчитать довольно стандартные базовые метрики: закрываемость начального скоупа спринта, количество вбросов в спринт, закрываемость самих вбросов, смены приоритетов, посмотреть структуру вбросов. После этого оценить, сколько у вас обычно вбрасывается задач и багов в итерацию. Далее, с помощью сигнала контролировать то, что вы эту квоту закладываете на этапе планирования.
Проблемы с качеством на этапе планирования
Первая проблема: команда не додумывает функциональность выпускаемых фич. Я буду говорить про качество в общем смысле — проблема с качеством, это если клиент говорит, что она есть. Это могут быть какие-то продуктовые недодумки, а могут быть технические вещи.
Касательно продуктовых недодумок, хорошо работает такая метрика как 3-week churn, выявляющая, что спустя 3 недели после релиза задачи churn выше нормы. Суть простая: задачу зарелизили, а потом в течение трех недель достаточно высокий процент ее кода был удалён. Видимо, задача была не очень хорошо реализована. Такие кейсы мы вылавливаем и разбираем с командой.
Вторая метрика нужна для команд, у которых есть проблемы с багами, крэшами и с качеством. Предлагаем строить график баланса багов и крэшей: сколько багов есть прямо сейчас, сколько прилетело за вчерашний день, сколько за вчерашний день сделали. Можно повесить такой Real Time Monitor прямо перед командой, чтобы она видела его каждый день. Это здорово акцентирует внимание команды на проблемах с качеством. Мы с двумя командами так делали, и они действительно стали лучше продумывать задачи.
Следующая очень стандартная проблема — у команды нет времени на технический долг. Эта история легко мониторится, если вы соблюдаете работу с типами, то есть техдолговые задачи оцениваются и заводятся в Jira как техдолговые. Мы можем посчитать какую квоту распределения времени давали команде на техдолг в течение квартала. Если мы договаривались с бизнесом о том, что это 20%, а потратили только 10%, это можно учесть и в следующем квартале уделить техническому долгу больше времени.
Проблемы с дисциплиной на стадии разработки
Теперь перейдем к стадии разработки. Какие тут могут проблемы с дисциплиной.
К сожалению, бывает так, что разработчики ничего не делают или мы не можем понять, делают ли они хоть что-нибудь. Отследить это легко по двум банальным признакам:
- частота коммитов — хотя бы раз в день;
- хотя бы одна активная задача в Jira.
Если этого нет, то не факт, что надо бить по рукам разработчика, но надо знать об этом.
Вторая проблема, которая может подкосить даже самых сильных людей и мозг даже очень крутого разработчика, это постоянные переработки. Хорошо бы, чтобы вы как тимлид знали о том, что человек перерабатывает: пишет код или делает код-ревью в нерабочее время.
Также могут нарушаться различные правила работы с Git. Первое, чему мы призываем следовать все команды, это указывать в commit messages task-префиксы из трекера, потому что только в этом случае мы можем связать задачу и код к ней. Тут лучше даже не сигналы строить, а прямо настроить git hook. На любые дополнительные git-правила, которые у вас есть, например, нельзя коммитить в master, тоже настраиваем git hooks.
Это же относится и к оговоренным практикам. На этапе разработки бывает много практик, которым должен следовать разработчик. Например, в случае Due date будет три сигнала:
- задачи, у которых due date не проставлен;
- задачи, у которых есть просроченый due date;
- задачи, у которых due date был изменён, но нет комментария.
На всё на это настраиваются сигналы. На любую другую практику тоже можно настроить подобные вещи.
Проблемы с прогнозируемостью на этапе разработки
Много чего может пойти не так в прогнозах на этапе разработки.
Задача может просто долго висеть в разработке. Мы уже попытались решить эту проблему на этапе планирования — декомпозировать задачи достаточно мелко. К сожалению, это не всегда помогает, и бывают задачи, которые зависают. Мы рекомендуем для начала просто настроить SLA на статус «in progress», чтобы был сигнал о том, что этот SLA нарушается. Это не позволит прямо сейчас начать выпускать задачи быстрее, но это позволит опять-таки собирать фактуру, на это реагировать и обсуждать с командой, что произошло, почему задача долго висит.
Прогнозируемость может пострадать, если на одном разработчике слишком много задач. Количество параллельных задач, которые делает разработчик, желательно проверять по коду, а не по Jira, потому что Jira не всегда отражает релевантную информацию. Все мы люди, и если мы делаем много параллельных задач, то риск того, что где-то что-то пойдет не так, увеличивается.
У разработчика могут быть какие-то проблемы, про которые он не говорит, но которые легко выявить на основе данных. Например, вчера у разработчика было мало активности по коду. Это не обязательно означает, что есть проблема, но вы, как тимлид, можете подойти и узнать это. Возможно, он застрял и ему нужна помощь, но он стесняется её попросить.
Другой пример, у разработчика, наоборот, какая-то большая задача, которая всё разрастается и разрастается по коду. Это тоже можно выявить и, возможно, декомпозировать, чтобы в итоге не возникло проблем на код-ревью или стадии тестирования.
Имеет смысл настроить сигнал и на то, что в ходе работы над задачей многократно переписывается код. Возможно, по ней постоянно меняются требования, или разработчик не знает какое архитектурное решение выбрать. На данных это легко обнаружить и обсудить с разработчиком.
Проблемы с качеством на этапе разработки
Разработка напрямую влияет на качество. Вопрос в том, как понять, кто из разработчиков больше всего влияет на снижение качества.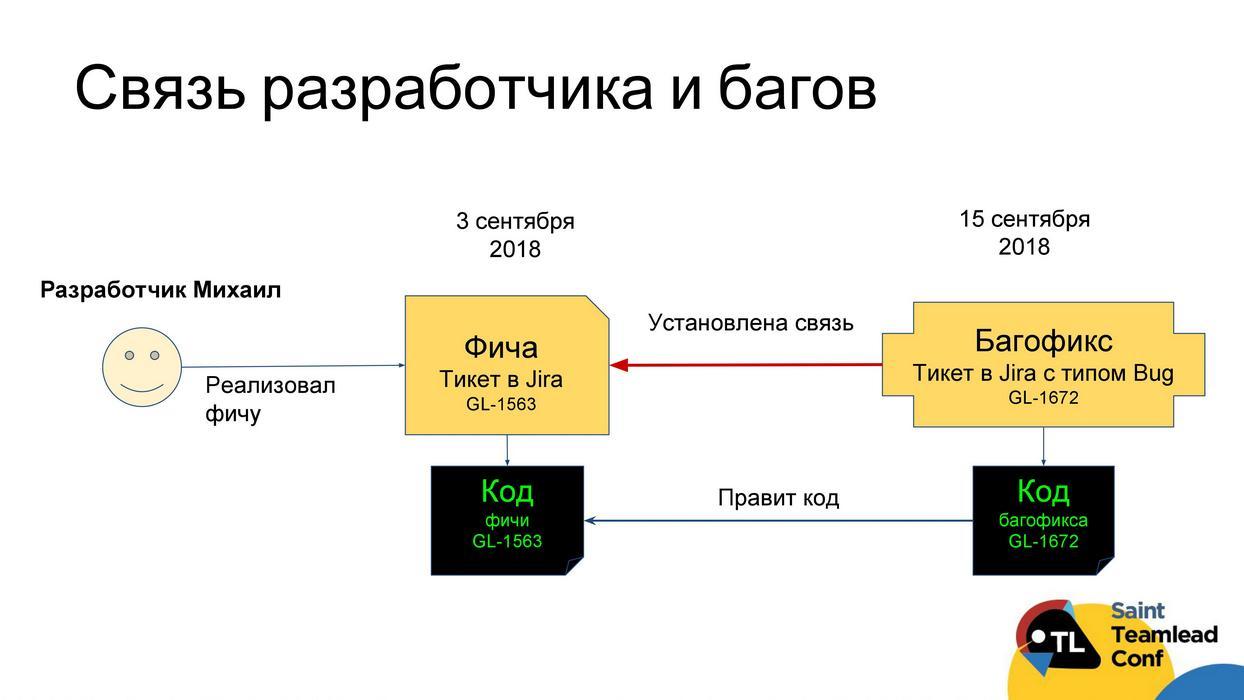
Мы предлагаем делать это следующим образом. Можно рассчитать критерий «бажности» разработчика: берем все задачи, которые были в трекере за три месяца; находим среди всех задач задачи типа «баг»; смотрим код этих задач типа «баг»; смотрим, код каких задач исправлял этот bug fix. Соответственно, можем понять соотношение задач, в которых потом были обнаружены дефекты, ко всем задачам, которые делал разработчик, — это и будет «критерий бажности».
Если дополнить эту историю статистикой по возвратам из тестирования, то есть долю задач разработчика, которые возвращались тестированием на доработки, то получится оценить, у кого из разработчиков больше всего проблем с качеством. В результате поймем, под кого стоит подстроить процессы код-ревью и тестирования, чей код нужно тщательнее ревьюить и чьи задачи желательно отдавать более въедливым тестировщикам.
Следующая проблема, которая может быть с качеством на этапе разработки, это то, что мы пишем сложно поддерживаемый код, такую «слоеную» архитектуру. Не буду здесь останавливаться подробно, я подробно рассказывал об этом в прошлый раз. Есть метрика, которая называется Legacy Refactoring, которая как раз показывает, как много времени тратится на встраивание нового кода в существующий, как много старого кода удаляется и меняется при написании нового.
Наверное, один из самых важных критериев при оценке качества именно на стадии разработки — это контроль SLA для high-priority-багов. Я надеюсь, что вы за этим уже следите. Если нет, то рекомендую начать, потому что это зачастую один из самых важных показателей для бизнеса: high-priority и critical баги команда разработки обязуется закрывать в определенное время.
Последнее, с чем часто приходится сталкиваться — нет автотестов. Во-первых, их нужно писать. Во-вторых, нужно мониторить, что покрытие держится на определенном уровне и не падает ниже порога. Многие пишут автотесты, но забывают следить за покрытием.
Проблемы с дисциплиной на этапе код-ревью
Переходим к стадии Code review. Какие тут могут быть проблемы с дисциплиной? Начнем с, наверное, самых дурацкой причины — забытых pull requests. Во-первых, автор может просто не назначить ревьюера для pull request, который в результате будет забыт. Или, например, тикет забыли передвинуть в статус «in review», а разработчики проверяют, какие задачи нужно ревьюить именно в Jira. Нужно не забывать за этим следить, для чего настраиваем простые сигналы. Если у вас есть практика, что должно быть больше 2–3 ревьюеров на задачу, то это также легко контролируется с помощью простого сигнала.
Следующая история о том, что ревьюер раскрывает задачу, не может быстро понять, к какой задаче относится pull request, ему лень спросить и он ее откладывает. Тут тоже делаем сигнал — убеждаемся, что в pull request всегда есть ссылка на ticket в Jira и ревьюер может легко с ним ознакомиться.
Следующая проблема, которую, к сожалению, не получается исключить. Всегда бывают огромный pull requests, в которых много всего сделано. Соответственно, ревьюер их открывает, смотрит и думает: «Нет, лучше я потом это проверю, что-то тут слишком много». В этом случае автор может помочь ревьюеру с онбордингом, а мы можем этот процесс проконтролировать. Большие pull requests обязательно должны иметь хорошее понятное описание, которое соответствует определенному формату, и этот формат отличается от тикета в Jira.
Второй вид практик для больший pull request, которые тоже можно мониторить, — это, когда автор сам заранее в коде расставляет комментарии в тех местах, где что-то нужно обсудить, где какое-то неочевидное решение, тем самым, как бы приглашая ревьюера в дискуссию. На это тоже легко настраиваются сигналы.
Далее проблема, с которой тоже очень часто сталкиваемся, — автор говорит, что просто не знает, когда ему можно начинать всё исправлять, потому что он не знает, закончено ли ревью. Для этого внедряется элементарная дисциплинарная практика: ревьюер должен в конце ревью обязательно отписаться специальным комментарием о том, что «я закончил, можно фиксить». Соответственно, можно настроить автоматические уведомления об этом автору.
Настройте, пожалуйста, linter. В половине команд, с которыми мы работаем, почему-то не настроен linter, и они сами занимаются таким синтаксическим код-ревью и зачем-то делают работу, с которой машина справится намного лучше.
Проблемы с прогнозируемостью на стадии код-ревью
Если задачи продолжают зависать, рекомендуем настроить SLA на то, что задача либо долго ждет фиксов, либо же долго ждет ревью. Соответственно, обязательно пингуем и автора, и ревьюера.
Если SLA не помогают, рекомендую внедрить в практику утренний »час код-ревью» или вечерний — как удобно. Это время, когда вся команда садится и занимается чисто код-ревью. Внедрение этой метрики очень легко мониторить по смещению времени активности в pull request к нужному часу.
Бывает, что есть люди перегруженные код-ревью, и это тоже не очень хорошо. Например, в одной из команд CTO стоял у самых истоков системы, всю ее написал, и так уж получилось, что всегда был главным ревьюером. Все разработчики постоянно навешивали на него задачи на код-ревью. В какой-то момент всё пришло к тому, что в команде из 6 человек на нём висело больше 50% код-ревью и продолжало копиться и копиться. В результате, как несложно догадаться, итерации у них закрывались на те же самые 50%, потому что CTO не успевал всё проверить. Когда ввели элементарно дисциплинарную практику о том, что на CTO нельзя теперь было навесить больше двух-трех задач в итерацию, в следующую же итерацию команда показала закрытие спринта почти на 100%.
Следующая история, которая легко мониторится с помощью метрик — это то, что в код-ревью начался холивар. Триггеры могут быть такими:
- есть тред, в котором больше двух ответов от каждого из участников;
- большое количество участников в код-ревью;
- нет активности по коммитам, а по комментариям активность есть.
Все это повод проверить, нет ли холивара в этом код-ревью.
Проблемы с качеством на стадии код-ревью
Прежде всего, проблема может быть в просто очень поверхностном код-ревью. Для того чтобы это мониторить, есть две неплохие метрики. Можно измерить активность ревьюера как количество комментариев на каждые 100 строк кода. Кто-то ревьюит каждые 10 строчек кода, а кто-то целые экраны пролистывает и оставляет 1–2 комментария. Конечно, не все комментарии одинаково полезны. Поэтому можно уточнить эту метрику измерив влияние ревьюера — процент комментариев, которые указывали на строку кода, которая потом была изменена в рамках ревью. Тем самым мы понимаем, кто самый въедливый, и самый эффективный в том смысле, что его комментарии чаще всего приводят к изменениям кода.
С теми, кто подходит к ревью очень формально, можно поговорить и мониторить их далее, смотреть, начинают ли они ревьюить более тщательно.
Следующая проблема — автор выносит на ревью очень сырой код и ревью превращается в исправление самых очевидных багов вместо того, чтобы уделить внимание чему-то более сложному, или просто затягивается. Метрика здесь — высокий churn кода после код-ревью, т.е. процент изменения кода в pull request после того, как начался ревью.
Случай, когда ничего непонятно из-за рефакторинга, к сожалению, стоит контролировать руками, автоматически это делать достаточно проблемно. Проверяем, чтобы стилистический рефакторинг был выделен либо в отдельный commit, либо в идеале вообще в отдельную ветку, чтобы не мешать проводить качественный код-ревью.
Качество на код ревью можно еще контролировать с помощью такой практики, как анонимный опрос после код-ревью (когда pull request успешно закрыт), в котором ревьюер и автор оценили бы качество кода и качество код-ревью соответственно. И один из критериев может быть как раз, выделен ли стилистический рефакторинг в отдельный commit, в том числе. Такие субъективные оценки позволяют находить скрытые конфликты, проблемы в команде.
Проблемы с дисциплиной на этапе тестирования
Переходим к этапу тестирования и проблемам с дисциплиной на этом этапе. Самая частая, с которой мы сталкиваемся — нет информации о тестировщиках в Jira. То люди экономят на лицензиях и не добавляют тестировщиков в Jira. То задачи, которые просто не попадают в статус «testing». То мы не можем определить возврат задачи на доработки по task-tracker. Рекомендуем на все это настроить сигналы и смотреть, чтобы данные копились, иначе о тестировщике сказать что-то будет крайне сложно.
Проблемы с прогнозируемостью на стадии тестирования
В части прогнозируемости на стадии тестирования опять рекомендую навешивать SLA на время тестирования и на время ожидания тестирования. А все случаи невыполнения SLA проговаривать с командой, в том числе навесить сигнал на время фикса после возврата задачи из тестирования в разработку.
Как и с код-ревью, в тестировании может быть проблема перегруза тестировщиков, особенно в командах, где тестировщики — это общекомандный ресурс. Рекомендуем просто посмотреть распределение задач по тестировщикам. Даже если у вас тестировщик выполняет задачи от нескольких команд, то нужно по нескольким командам посмотреть распределение задач по тестерам, чтобы понять, кто прямо сейчас является бутылочным горлышком.
Сложный pipeline test-окружения — суперчастая проблема, но, к сожалению, не все на это строят метрики. То время сборки build«а очень большое, то время раскатки системы, то время прогона автотестов — если можете настроить на это метрики, рекомендуем это сделать. Если нет, то хотя бы раз в 1–2 месяца рекомендуем садиться рядом со своим тестировщиком на целый день, чтобы понять, что иногда ему живется очень непросто. Если вы этого ни разу не делали, то вам откроется много инсайтов.
Проблемы с качеством на этапе тестирования
Целевая функция тестирования — не пропускать баги на продакшен. Хорошо бы понять, кто из тестировщиков с этой функцией справляется хорошо. Тут ровно такая же схема, как была с разработчиками, просто теперь мы оцениваем критерий «бажности» тестировщика, как количество задач, которые тестировщик тестировал, а потом в них были исправлены баги, по отношению ко всем задачам, которые тестировал тестировщик.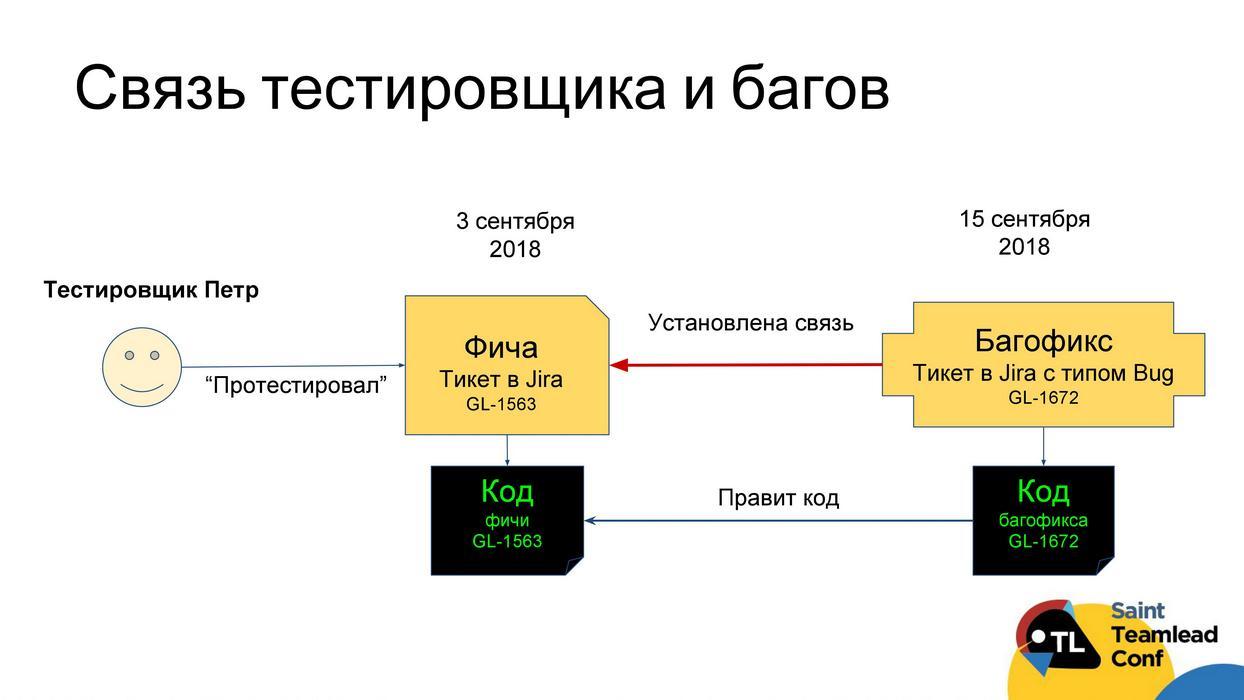
Дальше мы ещё можем посмотреть, сколько всего этот тестировщик тестирует задач, как часто он возвращает задачи, и тем самым построить некий рейтинг тестировщиков. Очень часто на этой стадии нас ждали удивительные открытия. Оказывалось, что тестировщики, которых все любят, потому что они целыми пачками очень быстро тестируют задачи, делают это наименее качественно. А тестировщик, которого прямо недолюбливали, оказался самым въедливым, просто не очень быстрым. Суть здесь очень простая: самым въедливым тестировщикам, которые тестируют качественнее всего, нужно давать самые важные, сложные или потенциально самые рискованные задачи.
Касательно потенциально самых рискованных задач, можно такую же историю с «бажностью» построить для файлов, то есть посмотреть на файлы, в которых находят больше всего багов. Соответственно, задачи, которые эти файлы затрагивают, доверять наиболее ответственному тестировщику.

Еще одна история, которая сказывается на качестве этапа тестирования — это такой постоянный пинг-понг между тестированием и разработкой. Тестировщик просто возвращает задачу разработчику, а тот в свою очередь ничего не меняя, возвращает ее обратно тестировщику. На это можно смотреть либо в качестве метрики, либо настроить сигнал на такие задачи и присматриваться, что там происходит и нет ли проблем.
Методология работы с метриками
Про метрики мы поговорили, и теперь вопрос — как со всем этим работать? Я рассказал только самые базовые вещи, но даже их довольно много. Что со всем этим делать и как это использовать?
Мы рекомендуем по максимуму автоматизировать этот процесс и все сигналы доставлять в команду посредством бота в мессенджерах. Мы пробовали разные каналы коммуникации: и e-mail, и dashboard — не очень хорошо работает. Бот зарекомендовал себя лучше всего. Бота вы можете написать сами, можете взять у кого-нибудь OpenSource, можете купить у нас.
Суть тут очень простая: на сигналы от бота команда реагирует намного спокойнее, чем на менеджера, который указывает на проблемы. Большинство сигналов по возможности доставляйте напрямую сначала разработчику, потом уже в команду, если разработчик не реагирует, например, в течение одного-двух дней.
Не нужно пытаться строить сразу все сигналы. Большинство из них просто не будут работать, потому что у вас не будет данных, из-за банальных проблем с дисциплиной. Поэтому сначала налаживаем дисциплину и настраиваем сигналы на дисциплинарные практики. По опыту команд, с которыми мы общались, на простое выстраивание дисциплины в команде разработки без автоматизации уходило год-полтора. С автоматизацией, с помощью постоянных сигналов команда начинает нормально дисциплинированно работать где-то через пару месяцев, то есть намного быстрее.
Любые сигналы, которые вы делаете публичными, или направляете напрямую разработчику, ни в коем случае нель
