Оцените шансы хакнуть криптообменник и получить книжку с кабанчиком в подарок
Тогда вам стоит почитать книгу «с кабанчиком» Мартина Клеппмана и оценить, какие ваши шансы хакнуть криптообменник с помощью теста (лучший получит от меня книгу в подарок с доставкой в любое место, куда доставляет Озон).
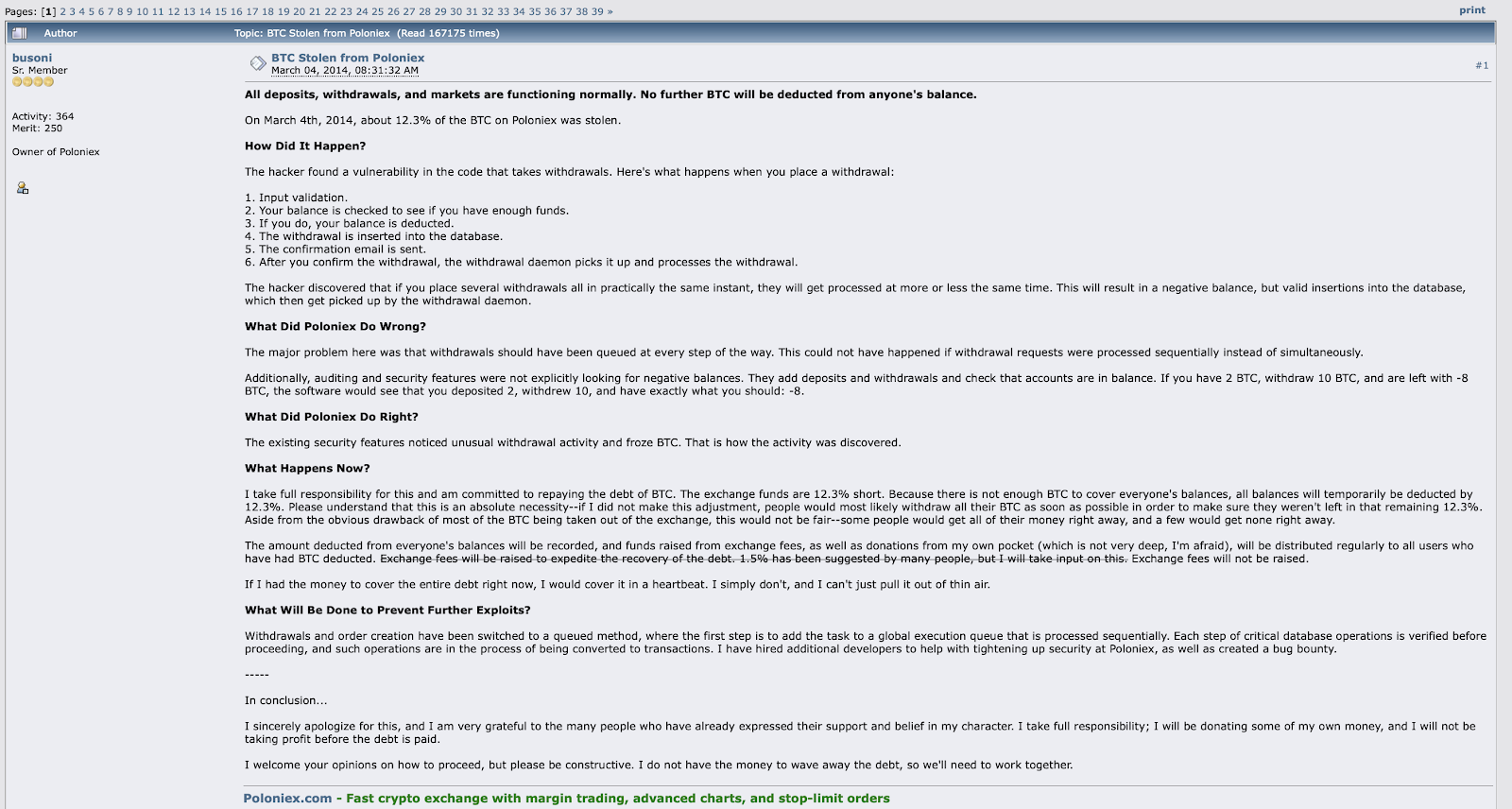
Итак, в 2014 году из криптообменника Poloniex были украдены 12,3% BTC. Хакер нашел уязвимость в коде, реализующем снятие денег со счета…

Код был реализован так, что при попытке снять BTC выполнялись:
- валидация запроса,
- проверка баланса на достаточность средств,
- если средств достаточно, то баланс уменьшался на требуемую сумму,
- и т.д. (см. сообщение на рисунке ниже).
Оказалось, что если зарегистрировать одновременно несколько корректных запросов на снятие средств с одного счета, то они будут обработаны одновременно и успешно пройдут проверку достаточности средств на шаге 2, даже если общая запрашиваемая сумма будет превосходить размер имеющихся средств. Конкретики у меня нет, но код мог быть реализован примерно следующим образом:
BEGIN TRANSACTION
-- проверяем баланс счета списания
SELECT balance INTO $t_balance FROM accounts WHERE account_id=$account_id;
-- если сумма на счете больше или равна сумме списания,
-- то уменьшается баланс и выполняются другие действия
IF $t_balance-$sum>=0 THEN
UPDATE accounts SET balance=$t_balance-$sum WHERE account_id=$account_id;
-- выполнялись дальнейшие действия по снятию средств в той же транзакции
-- ...
ENDIF;
COMMIT;Если в БД используется уровень изоляции SNAPSHOT_ISOLATION или слабее, то возможна следующая ситуация. Например, баланс вашего счета 10 BTC, вы создаете две транзакции со списаниями по 10 BTC, которые одновременно прочитают положительное значение баланса и будут авторизованы криптообменником. В результате баланс счета станет -10 BTC, а вы сможете списать с вашего счета больше средств, чем у вас было.
Прочитав книгу, начинаешь понимать, что конкурентный доступ и транзакции — это не просто теоретические вопросы для гиков. Подобные проблемы «вызывали немалые денежные потери, приводили к расследованиям финансовых аудиторов и становились причиной порчи пользовательских данных». В книге приводится масса интересных ссылок и примеров. Раньше я думал, что не надо заморачиваться нюансами конкурентного доступа и всякими аномалиями. Просто нужно использовать ACID-базу данных, и все само собой образуется. Однако, как оказалось, за примерами проблем, которые могут в таком случае возникнуть, далеко ходить не надо. Подобные вопросы возникают, если нужно предотвратить двойное бронирование конференц-зала; в многопользовательской игре — обеспечить, чтобы два пользователя не поставили фигуру на одно и тоже поле; в криптообменнике — обеспечить невозможность двойного списания средств и так далее. Камон! Моя команда в ЛАНИТ как раз сейчас реализует функциональность записи на прием в госорганизацию.
Очень часто можно услышать мнение, что если вы не Google и не Amazon, то не надо ничего усложнять — просто используйте реляционную БД, и все будет нормально. С другой стороны, довольно часто встречаются ситуации, когда команды применяют какое-то модное решение просто потому, что о нем последнее время много говорят. Я лично на собеседованиях кандидатов часто слышу странные обоснования, например: «Мы решили перейти на Apache Kafka, т.к. его все используют, и это, похоже, уже стандарт». Обе эти крайности могут привести как минимум к неэффективным решениям, а, возможно, и к проблемам.
Действительно, технологии постоянно меняются. Сейчас мы уже хотим хостить наши приложения в облаках, использовать микросервисную архитектуру, разрабатывать с использованием непрерывной поставки и прочее. А это все очень серьезно меняет предпосылки, исходя из которых разрабатывались и использовались те или иные технологии.
В главе 9 автор, например, обращает внимание на то, что при использовании двухфазной фиксации критически важным звеном является координатор транзакций. Если координатор транзакций окажется недоступен, то это может повлечь значительную недоступность системы. Часто координатор является частью сервера приложений (например, WildFly с Narayana), поэтому если вы переносите сервер приложений с координатором в облако, то журналы координатора становятся критически важной частью системы, и эти узлы больше нельзя считать узлами без состояния (stateless). Это существенным образом влияет на схему развертывания. Таких тонкостей масса, и если не понимать, что там у технологий «под капотом», то можно серьезно опростоволоситься.
Книга полна интересных исторических справок. Оказывается, термин «согласованность» (consistency) в аббревиатуре ACID на самом деле был добавлен авторами терминов для красоты, и согласованность вообще не считалась чем-то существенным.
«Атомарность, изоляция и сохраняемость — свойства базы данных, в то время как согласованность в смысле ACID — свойство приложения. Оно может полагаться на свойства атомарности и изоляции базы данных, чтобы обеспечить согласованность, но не на одну только базу».
Для меня эта книга стала настольной. Я не могу ее охватить за один присест и уже перечитываю третий раз с упором на разные темы. Обычно я делаю выжимки из книг, когда их читаю, однако в данном случае — это просто бессмысленно. Поэтому я решил, что будет полезно сделать тесты, чтобы я сам (так как все забывается!) и мои коллеги могли попрактиковаться и оценить свои знания.
Информации так много, что я решил сократить тест до пары десятков вопросов и ограничил его несколькими темами: надежность, масштабируемость, легкость развития (глава 1), модели данных (глава 2), подсистемы хранения и извлечения данных (глава 3), кодирование и эволюция (глава 4), транзакции (глава 7).
Оцените ваши знания в области проектирования высоконагруженных систем по версии книги «с кабанчиком» тут (лучший получит от меня книгу в подарок с доставкой в любое место, куда доставляет Озон, ответы принимаются в течение 1 недели после публикации поста).
Было жутко интересно и полезно придумывать вопросы по книге. Понимание материала улучшается значительно. Мне лично всегда не хватает практических задач или тестов после прочтения книги, просто так прочитать — не достаточно. Если у вас есть интересные вопросы по затронутым здесь темам, напишите в комментариях. Было бы здорово поломать голову.
Если вам хочется присоединиться к «высокотехнологичной» команде, которая работает по схеме DevOps/непрерывная поставка с использованием современных технологий и микросервисной архитектуры, то пишите мне в личку, сюда или сюда.
