Обзор технологий хранения больших данных. Плюсы, минусы, кому что подойдет
Если вы собираетесь построить или перестроить свое хранилище данных, то столкнетесь с внушительным списком технологий на рынке. Пробовать каждую из них в поисках подходящей именно вам — долго и затратно.
На нашей конференции SmartData ведущий разработчик в Яндексе Максим Стаценко рассказал про плюсы и минусы различных решений для хранения данных: облака или железо, Hadoop, Vertica, ClickHouse, Exasol, Greenplum, Teradata и не только.

Работая в крупных компаниях, Максим попробовал много решений, сравнил их на одинаковых данных и задал вопросы их разработчикам и поставщикам.
Видео и расшифровка доклада — под катом. Далее повествование будет от лица Максима.
Мой доклад ориентирован на людей, которые начинают строить хранилище данных либо задумываются о том, как его переделать, а также на junior-разработчиков, только планирующих стать дата-инженерами. Я сконцентрируюсь на том, как бы я выбирал решения и как хранить данные.
О чем и зачем этот доклад?
Рассказать о технологиях, о которых говорят меньше, чем о хайповых технологиях
Поделиться опытом, полученным в рамках PoC (proof of concept) на большом объеме данных
Поделиться опытом принятия решений, как и где строить хранилище.
Перейдем к тому, что же побудило меня прочитать этот доклад. Кроме работы я преподавал в вузах: МГУ, Бауманке. Так у меня появилось много знакомых, которые любят создавать стартапы или работать в маленьких организациях. Периодически они приходят ко мне и говорят: «Макс, мы хотим создать хранилище или хотим переделать наше хранилище, потому что оно не удовлетворяет нашим требованиям».
Общаясь с ними, я понял, что есть популярные универсальные решения, про которые знают все, а мне хочется рассказать, что есть хорошие большие решения, о которых у нас знают меньше, и поделиться опытом проведения proof of concept в Mail.ru. Мы проводили proof of concept на терабайтах данных кликстрима, и с нами активно работали вендоры различного программного обеспечения.
Разберем план моего доклада. Сначала мы решим, где разворачивать наше хранилище: в облаке или на железе. Потом выберем технологию для хранения данных, затем обсудим то, что не влезло в доклад, и почему я не пытался впихнуть это в презентацию.
Что мы строим?
Мы строим аналитическое хранилище данных. В моем видении аналитическое хранилище данных в первую очередь ориентировано на людей.
Сотрудники должны иметь доступ к данным 24/7. В вашем сервисе может что-то пойти не так в любой момент времени. Аналитики — это люди, которые могут объяснить, почему у вас внезапно просели продажи, почему на сайт перестали приходить люди, почему упала рекламная выручка. Если у вас сработал мониторинг, то аналитик подключится и будет разбираться с проблемой.
Когда вы вырастете (или уже выросли), вам придется разграничивать доступ к данным. Вы не захотите, чтобы junior-разработчик имел доступ к зарплатам сотрудников, затратам и т. д.
Доступ должен быть BI. Я часто привожу пример с мобильным телефоном. Если вы хотите посмотреть, сколько времени в часах осталось работать вашему телефону, вам не нужно писать код на Python, вы просто заходите в меню и смотрите. В бизнесе основные метрики должны быть доступны точно так же, чтобы люди, у которых нет времени и навыков программирования, могли посмотреть ключевые показатели и провести несложную аналитику.
Еще одна важная вещь: аналитическое хранилище данных появляется, когда ваш сервис уже вырос из SMP-системы. Стандартный процесс роста аналитической системы:
Мы живем на той же базе, что и прод.
Аналитики начинают мешать проду по производительности, делают реплику.
Реплика не справляется по производительности.
Начинаем задумываться о переходе на другое решение.
Специфика современности
То, что я сейчас рассказал, было актуально и 30, и 20 лет назад. Но сейчас на дворе 2020 год, и несмотря на коронавирус и прочие проблемы, есть определенные особенности. Дальше я приведу свой чек-лист, на который я смотрю, когда принимаю решения об архитектуре хранилищ.
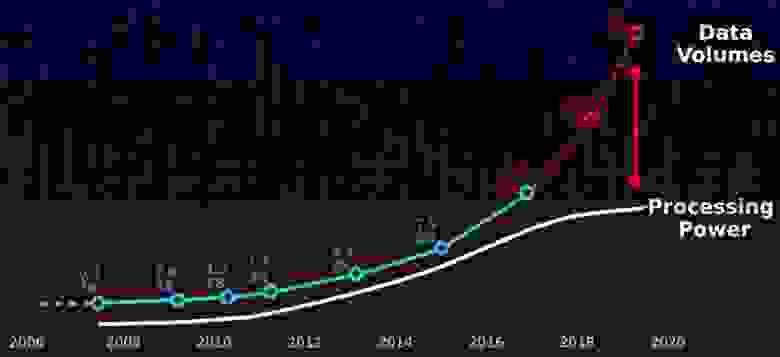
Первое, о чем бы я советовал помнить при построении аналитических хранилищ, — с 2000 года количество данных начало расти гораздо быстрее, чем вычислительные мощности. Как следствие, старые подходы больше не работают. А SMP-системы были придуманы в 70–80е года, и они немного не подходят под эту парадигму.
Второе, о чем не стоит забывать, — это угроза безопасности чувствительных данных. Вы собираете много информации о пользователях, и если эти данные попадут в публичный доступ или в руки мошенников, то будет плохо и вам, и пользователям. В Российской Федерации за это предусмотрена уголовная ответственность.
Третий критерий выбора — сложность найма сотрудников. Де-факто SQL, Python/R — это стандарты доступа к данным. Если для вашей системы нужны будут более специфические навыки, то найти специалистов будет сложнее. Например, если вы захотите нанять C++ разработчика, который будет писать ETL, то будете страдать и предлагать большие деньги. А разработчики будут говорить: «Что? Я буду «прокидывать» поля на C++, обрабатывать логи? Нет, это не интересно». Это мой опыт, и я вам не советую его повторять.
Четвертый фактор, влияющий на принятие решения — это машинное обучение, которое находится на вершине своего хайпа. Это очень популярная технология, на это тоже смотрят и вендоры. Сейчас странно начинать бизнес и не пытаться предсказать вашу выручку, затраты, спрос. Важно следить за тем, чтобы ваше аналитическое хранилище имело возможность предоставлять данные для машинного обучения.
Наконец, нюанс, о котором часто забывают, — проектирование системы. Многие не думают о том, что хороший аналитик сейчас достает не только те данные, которые есть в хранилище. Он может купить данные в других компаниях, скачать их в интернете, пойти к вашему бэкенд-разработчику и попросить достать их из логов. Не важно как, но когда он собрал данные, которые, как ему кажется, решат его задачу, нужно, чтобы эти данные взаимодействовали с данными из хранилища.
Если мы посмотрим старый пайплайн, то для решения этой задачи он попросил бы дата-инженера залить данные в хранилище и разложить их так, чтобы они лежали в третьей нормальной форме и чтобы все могли ими пользоваться. А значит, он поставит задачу в JIRA, которая уходит в бэклог. Дальше аналитик ждет, когда придут данные. Когда у вас много хороших аналитиков, бэклог разрастается, дата-инженеры страдают, а процессы движутся медленно. Кажется, что все было бы лучше, если бы аналитики могли бы сами загружать такие «одноразовые» и абы как структурированные данные.
Сейчас такие возможности есть, благодаря чему упрощается проведение экспериментов, проверка гипотез и выкатка MVP, так как больше не нужно привлекать дата-инженеров, чтобы добавить в хранилище данные, которые, может быть, больше никогда не понадобятся.
Хранение данных в Storage
На слайде ниже я широкими мазками нарисовал схему аналитического хранилища данных. Шина данных — это интерфейс, через который данные поступают в хранилище, а UI и ETL Manager управляют данными и предоставляют к ним доступ.
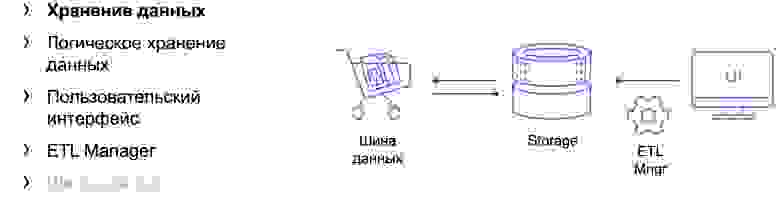 Схема аналитического хранилища данных
Схема аналитического хранилища данных
Мы сфокусируемся на Storage. Схема простая, но если присмотреться, она может оказаться и сложнее.
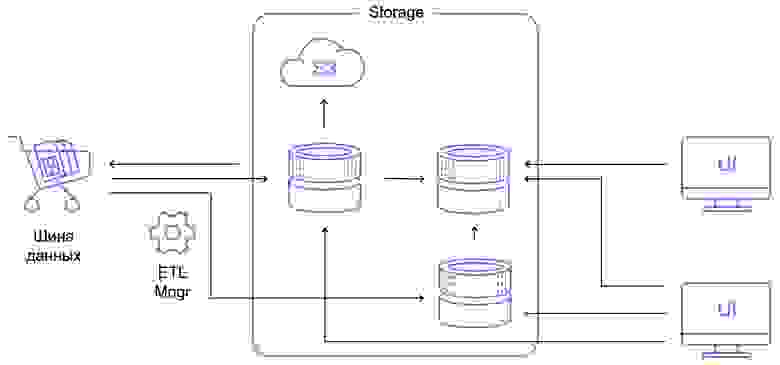
Здесь я нарисовал широкую схему лямбда-хранилища, где у вас есть:
real-time контур;
batch-процессинг;
база данных, в которую вы закидываете предпосчитанные агрегаты;
облако в S3, куда вы помещаете старые данные.
Варианты, где строить
Глобально есть пять вариантов, где строить наше DWH. Первые три варианта я буду объединять в группу «Ваш собственный сервер».
Сервер в кладовке, то есть в собственной серверной
Аренда стойки в дата-центре
Аренда сервера
Аренда виртуальной машины в облаке
Managed Services в облаке.
Последний вариант очень классный. Я открыл его для себя недавно, года два назад. Managed Services появились сейчас и в российских, и в зарубежных облаках. Вы заказываете не сервер, а необходимое программное решение.
Например, вам интересен кластер Hadoop с Zeppelin, Spark и всем прочим. Открываете интерфейс и накликиваете, например, 16 нод Hadoop, в каждой ноде по 1 ТБ данных, определенное количество CPU. Нажимаете на кнопку — и всё появилось.
Так же работает ClickHouse или любой другой сервис, который поддерживает выбранный вами вендор и облако. Таким образом вы получаете систему аналитики данных, по крайней мере, инфраструктуру под нее, точно так же, как вы заказываете еду на своем мобильном телефоне.
Далее у меня будет много консультационных слайдов. Я не буду проходить по всей таблице, но рассмотрю только некоторые пункты. Я пометил знаком доллара в таблице скрытые траты, о которых не стоит забывать, когда вы выбираете, где хранить данные.
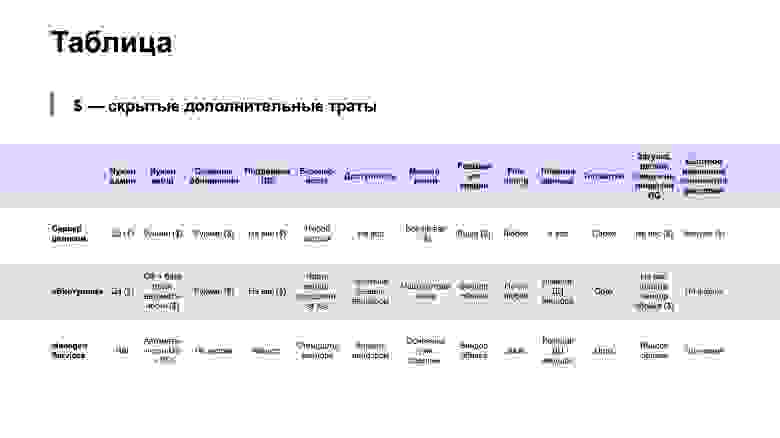
Первая важная вещь: если вы разворачиваете кластерное решение сами, то вам нужен очень хороший админ. Например, есть очень неприятная задача — обновление программного обеспечения кластера. Если вы не хотите допускать даунтайм вашего решения, то вам нужно брать кусок нод, выводить их из ротации. При этом вы должны убедиться, что у вас в ротации осталась хотя бы одна реплика всех данных. Далее вы накатываете новую версию софта, возвращаете в ротацию. Если случится так, что ваша база данных не поедет с новой версией, то откатывать придется точно так же.
Это боль, и ваш админ будет страдать. А если у вас еще опенсорс, то вам нужен разработчик, который будет фиксить баги в бесплатном ПО. Это очень тяжелая работа, мы с ней развлекались весьма долго. Каждый раз обновление Hadoop было эпичной историей, несмотря на то, что мы сначала делали обновление на тестовых базах, потом делали на боевой, но всё равно приходилось откатывать.
Когда вы выбираете решение, не стоит забывать о реакции на аварии и мониторинге.
Во-первых, если у вас собственный сервер, то вам придется подумать о возможности выхода из строя каких-то железных компонентов. Например, у вас может полететь диск, а если у вас большой кластер, то диски будут лететь почти каждый день. У вас может отказать сеть, может пойти что-то не так со свичами.
Чем больше решение завязано на вас, тем больше этих проблем на вас ляжет. Вам нужно будет это решать, предугадывать, закупать заранее диски и свичи, если вы расширяете свои личные дата-центры или даже маленькую серверную. Все эти проблемы нужно решать, и чем больше ответственности вы перекладываете на облако, тем больше рутины будут делать за вас. Это достаточно удобно. Лично я, поскольку вырос из разработчика, не люблю настраивать и реагировать на «железные» аварии, поэтому люблю облака.
Еще одна важная вещь — это мониторинги. Если вы сами сетапите ваш сервер, вам придется самим придумывать систему мониторинга, отслеживать, что у вас максимальная нагрузка на CPU или же легла база данных, или нода Hadoop вышла из ротации, писать об этом сообщения в Telegram, рисовать дашборды. И если вы поднимете виртуалку, то скорее всего, эту работу вам тоже придется делать самим. При использовании managed-сервисов базовые метрики будут сделаны за вас. Появится страница, на которой всегда можно будет посмотреть, что происходит. Самое главное, кто-то отреагирует за вас и скажет: «О, у нас упал кластер Hadoop, давайте срочно его чинить». Вы, скорее всего, даже не заметите этого.
 Мое мнение
Мое мнение
Сразу скажу, это только мое мнение, мой опыт. Возможно, у кого-то из вас другой опыт. Собственное железо дает психологическое спокойствие и спокойствие вашего офицера безопасности. По опыту Mail.ru или Министерства образования я знаю, что адаптировать облачное решение под требования офицера безопасности очень тяжело. В конце концов офицер безопасности говорит: «Я хочу, чтобы доступ на сервер был только через решение Cisco, при этом вы должны авторизоваться через SMS и сессия не должна длиться более 30 минут». Из коробки ни один вендор облака не даст такое решение, и вам придется разговаривать с ним отдельно. На своем сервере вы сможете настроить всё что угодно.
Вторая вещь — это чувствительность данных в вашей инфраструктуре. Я немного параноик и очень переживаю, что данные могут утечь. Когда ты сам отвечаешь за них, то немного спокойнее, потому что можно на ночь отключить провод Ethernet от сервера, и никто не залезет в базу. Доступ к серверу, если он хорошо настроен, есть только у твоих сотрудников. Такие вещи придают спокойствие, но в то же время в облачных решениях давно придумали и применяют современные технологии, которые обеспечивают безопасность на высоком уровне. Но психологически иметь свои чувствительные данные как-то надежнее и приятнее.
Кроме того, когда вы выбираете вендора, лучше спросить, все ли ресурсы ваши. Хоть эта история становится всё менее актуальной, перестраховаться всё же стоит. Раньше вендоры закладывались на то, что вы не сможете занять все забронированные вами ресурсы. Это работает как овербукинг на самолетных рейсах. Вендор продает мощностей больше, чем у его есть на самом деле, надеясь на то, что никто из клиентов не будет использовать свои ресурсы на 100%. И если вам не повезет, то ресурсы достанутся процессам, которых их заняли первыми, а ваши задачи будут работать на остаточных мощностях или вообще будут висеть в очереди. Например, вам предлагают 128 Гб оперативной памяти, когда фактически у вендора всего 64 свободных Гб. Неприятная ситуация, современные вендоры с этим борются. Но стоит обсудить, как они гарантируют квоту и всегда ли вы сможете получить доступ ко всем ресурсам, которые вы купили.
Что касается своего железа, то оно более привычно для пользователей. Но к плюсам виртуалок можно отнести их гибкость и простоту. Приведу два примера.
Допустим, у вас есть большое хранилище, и вы хотите попробовать перевести его на другую технологию, скажем, на ClickHouse. Если у вас свое железо, то вам нужно найти другие серверы. Если их нет, то купить, подождать, пока они приедут, поставить ClickHouse, залить данные. А если ClickHouse вам не понравился, то что делать с купленными серверами? В облаке же вы можете загрузить данные, недельку поиграть, удалить весь этот кластер и быстро разобраться, нужен ли вам ClickHouse.
Второй пример — кейс моих знакомых. Для своей фирмы они наняли специалиста по машинному обучению, которого попросили прогнозировать спрос. Это была сторонняя контора, она начала активно учить свои модели и загрузила аналитическую систему «в потолок» так, что никто кроме них самих не смог работать. Тогда они в облаке просто скопировали свой кластер со спросом и всеми данными и сказали: «Вот вам данные, обучайтесь, туда никто не будет ходить, а аналитика продолжит работать в реальной системе». Когда модель фирмы-подрядчика показала хороший результат, ее начали интегрировать в общую аналитическую систему и увеличивать ресурсы системы под хорошую модель. Так вы получаете гибкость — можно скопировать данные и передать их подрядчику.
И последняя плюшка виртуалки — перевод рутины на других людей. За настройку безопасности и реакцию на аварии будут отвечать специальные сотрудники.
Проблемы облака за пределами РФ
В целом они связаны с законодательством и возможными скрытыми тратами на сеть, если вы загружаете данные из облака или в него.
Согласно постановлению Правительства Российской Федерации № 728 от от 26 июня 2018 года, храним данные пользователей на территории РФ.
Федеральный закон «О персональных данных» от 27 июля 2006 года (№ 152-ФЗ) содержит нормативы, как безопасно хранить данные. Трансграничная передача персональных данных на территории иностранных государств может быть запрещена или ограничена.
Не везде есть русскоязычная поддержка — повышается стоимость специалистов, которые будут работать с облаком.
Валютные риски: стоимость услуг зависит от курса рубля. Стоимость инфраструктуры может удвоиться, как это случилось, когда курс доллара вырос в два раза.
Если надо заливать и выгружать большие объемы данных, то нужен хороший канал. Чем больше точек связности между двумя машинами, тем меньше вероятность, что будет хороший канал.
Стоимость канала до европейского ЦОД может быть равна стоимости ресурсов для проекта DWH в облаках РФ.
Выбор программного продукта
Перейдем к MPP-системам (англ. massive parallel processing). Мне придется немного побыть Капитаном Очевидность, но несколько раз мне лично пришлось доказывать нескольким финансовым директорам, что ценник за продукт — это не вся цена, которую придется заплатить. Я очень люблю Hadoop, но в этом докладе буду его активно хейтить и шеймить. Hadoop можно получить бесплатно, но придется потратить кучу сил, чтобы заставить его нормально работать. Можно купить коробочное решение, за него придется заплатить, но сравнивая с годом-двумя поддержки Hadoop, оно может оказаться намного дешевле.
Еще советую не ориентироваться на тендеры, а проводить proof of concept. Тендеры, отзывы, советы экспертов предвзяты. У вашего бизнеса свои особенности, собственный паттерн использования данных. Поговорите с вендором продукта, попросите его дать вам попробовать продукт. Как правило, можно договориться о триале на месяц или два, вы загрузите туда данные, погоняете на своих запросах и поймете, подходит ли вам это решение или нет.
Может оказаться так, что супернепопулярное решение выстрелит именно в вашем случае. Самый простой пример — автомобиль Лада, который нигде не нужен за пределами РФ, а у нас Лада — популярный продукт, так как его можно починить молотком и кувалдой. Все системы, о которых буду рассказывать дальше, — MPP. На схеме ниже они показаны справа, а слева — более архаичные SMP-системы (англ. symmetric multiprocessing).

Как видите, в MPP-системах мы стараемся хранить данные раздельно. На каждой ноде кусочек данных: от A до F, от G до R, от S до Z. При этом каждая нода старается обрабатывать свой кусочек данных, не заглядывая в чужие. В каких-то кейсах, например, при неудачных джойнах, происходит обмен данными между нодами, и дальше повторяется процесс, где каждая нода пытается обрабатывать только свой кусок. Это хорошо тем, что легко произвести масштабирование в ширину. Это проще и дешевле, чем масштабирование в высоту, поскольку так мы упираемся в некий потолок производительности.
Давайте посмотрим на несколько решений. Для каждого из них я расскажу про его QUERY LANGUAGE, про транзакционность, наличие точки отказа и наличие или отсутствие бесплатной версии. Также я расскажу о том, что отличает это решение от остальных.
Почему эти четыре пункта
SQL — не самое современное решение, но оно же — порог входа. Курсов по SQL очень много, почти все умеют писать на SQL, и вам гораздо проще найти людей. Поверьте, это важно.
Транзакции — это возможность пользователям не мешать друг другу и сохранять целостность данных. Допустим, у вас есть операция по переводу денег со счета на счет. При определенном хранении данных это две операции: списать деньги со счета и записать деньги на другой счет. Если у вас не произойдет одна из операций, то вторую тоже надо отменить. В таком случае операции объединяют в блоки, и такой блок операций называется транзакцией.
Наличие выделенной ноды для меня лично очень важно, поскольку это сигнал, что в системе есть узкое место. Если вы станете большими и у вас будет много пользователей, это место может начать не справляться, и вы с этим ничего не сделаете.
Платное/бесплатное — тут понятно, деньги интересуют всех.
Перед тем как показать табличку, я расскажу про Hadoop. Я очень люблю Hadoop, потому что это комбайн, в нем можно делать все. В нём есть SQL, транзакции, возможность сохранения данных удобным способом, ML из коробки. Можно писать низкоуровнево, сохранять в облаке, в общем, делать всё, что хотите.
Но де-факто Hadoop — это боль.
Первое, что ее вызывает — безопасность. За безопасность в Hadoop отвечает Kerberos (есть и другие решения, но это — самое популярное). Накатывание Kerberos на кластер у всех, кого я знаю, превращается в целый проект, который занимает квартал, полгода, и при этом вы будете решать проблемы, про часть из которых не написано даже на Stack Overflow. В архитектуре Hadoop ваш пользователь записан в переменную окружения. Если вы хотите стать админом, то вы просто пишете в консоли: set HADOOP_USER=«admin» и получаете доступ ко всем данным на кластере. Естественно, ни о какой безопасности тут речи не идет, и нужно устанавливать другие дополнительные системы, например, Kerberos.
Второе — в Hadoop есть платные и бесплатные сборки. Если вы выбрали путь бесплатной сборки, Vanilla Hadoop, то, скорее всего, там будет много багов. Например, мы обновили Hive, и в нем обнаружился баг: если у вас есть JOIN типа поле из одной таблицы равно COALESCE поля из другой таблицы, то оно просто не срабатывало. Это условие не выполнялось, и JOIN работал некорректно. Но мы были крутой командой Java-разработчиков, что нам стоило пофиксить Java-код Hadoop? Мы месяц ковырялись в исходниках Hadoop. В итоге нашли и пофиксили проблему, но это заняло месяц, поскольку делали это впервые. Пока мы этим занимались, наши аналитики нашли еще одну проблему. Когда мы представили, что нам придется еще раз пройти весь этот путь, мы сделали страничку на Wiki, где описали, как делать нельзя. Конечно, кто-то всё равно так делал, получал неправильные результаты, в целом — такое себе решение.
Еще одна боль в Hadoop — разделение ресурсов, оно есть в очень грубом варианте, это очереди YARN или отдельные инстансы Spark. Это не лучшее решение, которое имеет много неприятных нюансов.
Нет BI с быстрым откликом — думаю, все это знают.
Если вы хотите взять данные в Spark или Hive из JDBC-базы и загрузить их в Hadoop и проработать, то, скорее всего, вам нужно будет взять Sqoop или подключать JDBC-коннектор в Spark.
NameNode — узкое место. Я расскажу вам, как джун положил наш Hadoop-кластер. Он много ходил на курсы, разбирался с Hadoop. Там он узнал, что классно складывать данные в отдельные бакеты, кластеризируя их по полю. В рамках запроса он сделал кластеризацию по полю с миллионом уникальных значений так, чтобы каждое уникальное значение помещалось в отдельный файл. Hadoop начал работать очень медленно. У нас не было мониторингов, которые говорили бы, что в Hadoop увеличилось количество файлов. Мы долго разбирались и только в конце дня поняли, что у нас медленно отвечает NameNode, потому как в одной директории появились миллионы файлов размером по 16 Кб. В Hadoop от этого никак не защититься.
Многие считают Hadoop исчадием ада. Наверное, Hadoop — самый простой вариант. Я не знаю систем, которые так же легко запускаются, но я знаю более эффективные. Teradata (о которой речь пойдет ниже) тоже неплохо работает, она может затянуть неструктурированные и неоптимизированные данные из S3 и дальше обработать их за счет адаптивного оптимизатора. И это будет как минимум не медленнее, чем в Hadoop.
В то же время Hadoop и Spark классные. Hadoop — сложный инструмент, который тяжело поддерживать, но открывающий большие возможности. Я бы сравнил Hadoop с языком С, где вы сможете написать любую сложную программу эффективно, но при этом вы с очень высокой вероятностью ошибетесь.
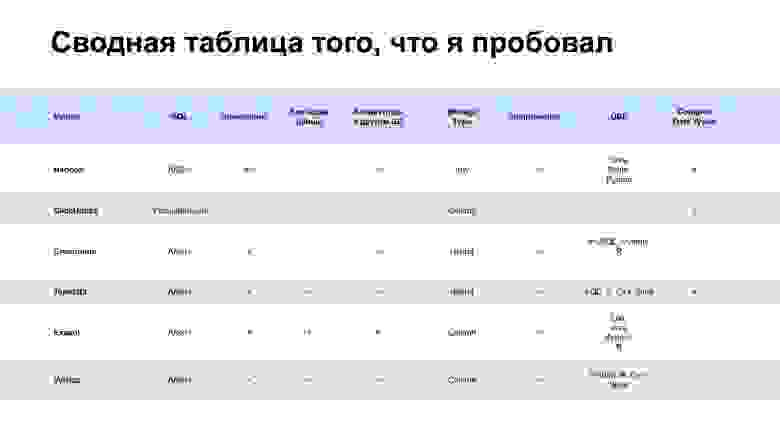
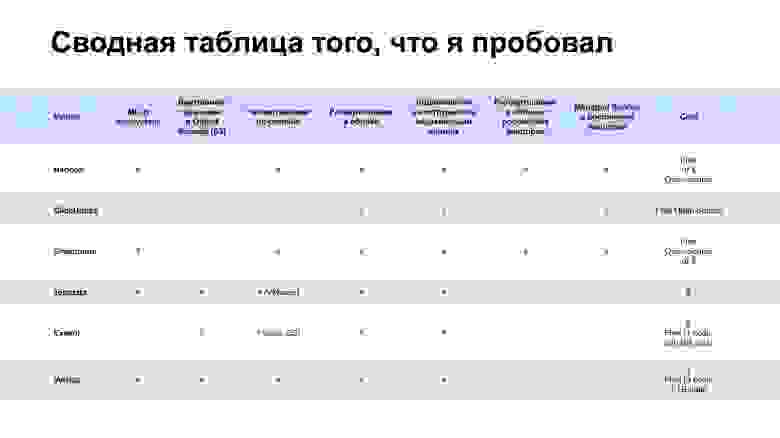
Я работал с Hadoop, ClickHouse, Greenplum, Teradata, Exasol, Vertica. В первой таблице указаны в основном технические характеристики. Остановлюсь на особой важности Storage Type. Есть два Storage Type — колоночное и построчное хранилище. Колоночное хранилище в среднем быстрее дает селект данных и лучше сжимает данные. Для долгого хранения оно подходит больше. При этом ставить данные в колоночное хранилище — это более долгая операция. В случае построчного хранилища вам не нужно проводить сложные операции для вставки данных. Но каждый раз, когда вы прочитали ряд, вам нужно сделать операцию seek, пока вы не дойдете до нужной колонки. Если в колоночном хранилище вы выполняете ее один раз, чтобы дойти до нужной колонки, то в случае построчного вам нужно делать seek для каждой строки.
Еще одна важная вещь — наличие UDF-функций. Тут нужно смотреть, насколько широкие возможности дает тот язык, на котором можно писать собственные функции для хранилища. Многие поддерживают Python, у Greenplum есть PL/SQL, у ClickHouse — расширенный синтаксис SQL. Exasol умеет в Lua, Vertica — в Python, C++ и не только. В последней, если вы написали UDF на C++, то она запускается внутри базы данных, не поднимаются JRE и питоновский исполнитель, а просто происходит нативный процесс.
Дальше я поделюсь моим опытом работы с системами и своим взглядом на них. Информацию о пользователях системы я брал не с официальных сайтов вендоров, а из открытых источников, где сами пользователи рассказывают о своем опыте. Мне кажется, так будет более честно.
ClickHouse
Пользователи:
Яндекс.Метрика
ВКонтакте
Cloudflare
Достаточно новая база, публичная версия вышла в 2016 году. Зародилась она в Яндекс.Метрике, стала дико популярной. Откуда такая популярность?
Человечество тяготело к матрицам и матричным вычислениям, даже когда не было компьютеров. Математики занимались линейной алгеброй. Так у нее появился хороший математический аппарат, и в 60–70е годы ей стали заниматься только появляющиеся программисты. Сейчас машинное обучение любят проводить на GPU-процессорах.
Почему видеокарточка для игрушек подошла для машинного обучения? Дело в том, что визуализация изображения — это тоже матричные операции, и видеокарта хорошо их выполняет. В машинном обучении тоже много матричных операций. Создатели ClickHouse написали на С++ все операции, которые производятся векторизованно. Это позволяет хорошо распараллелить и очень быстро их проводить. Система немного другая логически и иногда позволяет достичь очень крутых результатов.
И еще одна особенность. Синтаксис SQL немного урезан от классического для оптимизации под матричные векторизованные процессы. Взамен вам предлагают много функций, например, лямбда-функции над массивами, которые являются стандартным типом в ClickHouse. Это своеобразная, но очень быстрая система. Как-то раз я встречался с руководителем технического департамента одного банка, он говорил: «Мы тут ClickHouse взяли, но используем его, чтобы парсить JSON, а далее загружаем его в наше хранилище». Потом мы сами стали использовать ClickHouse, когда парсим JSON, так как он написан на С++ и все операции проходят в нем очень быстро.
Greenplum
В опенсорсе с 2015 года; предыдущие версии — с 2005 года.
Пользователи:
Тинькофф Банк
Cбер
Leroy Merlin
Это, наверное, самая логичная по своей эволюции база данных. Представим, что вам не хватает вашей SMP-системы для хранения данных. В Greenplum решили сделать MPP-систему, которая состояла бы из кучи маленьких стоящих рядом SMP-систем. Конкретно в случае GreenPlum в качестве основы использовался PostgreSQL. Фактически Greenplum — это толпа PostgreSQL, которые пытаются обработать ваши запросы, под капотом раскидывая данные и задачи обработки между собой. Почти все, что у вас работает под PostgreSQL, вы можете адаптировать под Greenplum; и для многих внешних систем Greenplum выглядит как большой PostgreSQL. Сложности известны, их решения тоже есть, но отметим один неприятный нюанс: Greenplum часто базируется на старых PostgreSQL, поэтому будьте внимательны.
Exasol
На рынке с 2000 года.
Пользователи:
Ситимобил
Badoo
Exasol — не очень раскрученная БД. Она выросла из SMP базы данных Oracle. Когда Oracle перестало хватать на OLAP-обработку, ребята написали Exasol. Он работает на своей операционке, и это одна из БД, которые пытаются автоматизировать часть работы.
В частности они пытаются автоматизировать работу с индексами. Индексы помогают ускорить работу БД, но они специфичны для каждого запроса. Вы не можете создать всевозможные индексы, так как индекс имеет свою накладную стоимость на вставку данных. Когда вы вставляете данные, вы должны вставить их в каждый из индексов. Индексы иногда надо пересортировывать или балансировать, а это дорогостоящая операция.
Проблема в том, что направления бизнесов меняются. Если вы один раз спроектировали БД, создали индексы под текущие запросы аналитиков, отвечающих на требования бизнеса, то когда через полгода ваш бизнес и запросы аналитиков чуть-чуть поменяются, база будет работать не так эффективно. Вам придется запрашивать администратора БД, чтобы он создал новые индексы.
Exasol делает это автоматически. Он смотрит, какие индексы перестали использоваться, удаляет их. Если видит, что какой-то запрос стал частотным и его можно оптимизировать за счет индексов, он их сам поднимает и создает. В этом плане Exasol очень удобен.
Многие мои коллеги считают, что технология AI DBA немного закрытая, это уникальное торговое предложение коллег из Exasol. Они не раскрывают многие секреты, поэтому это кажется «черным ящиком», примерно как и нейросети. В них вы можете посмотреть, какой нейрон активируется на какое изображение. Однако вы не можете сказать, что понимаете, как думает нейросеть.
Если написать какой-то неправильный запрос в Exasol и запустить его много раз, то пострадает не всё, так как индексы имеют какой-то вес и Exasol старается решать задачу по оптимизации. Но если пользователь написал плохой запрос и будет часто его запускать, то система настроится так, чтобы работать быстро. Что касается монетизации, тарифицироваться будут либо сырые данные, которые загружаются в систему, либо оперативная память.
Vertica
На рынке с 2005 года.
Пользователи:
Avito
СИБУР
Uber
Большая компания, представленная и в РФ, и во всем мире. Для меня в Vertica нет ощущения магии. Она производит впечатление понятного надежного инструмента.
Приведу аналогию с коробками передач машин Формулы-1 и машин 24 часов Ле-Мана. Коробка передач в Формуле-1 очень хитрая, она позволяет переключение без смены оборотов двигателя. Коробка машин 24 часов Ле-Мана — это классическая секвентальная коробка, у которой есть очевидный паттерн работы, куда добавлена автоматика. При этом коробка Формулы-1, хоть и выдает космические скорости, предназначена для коротких гонок.
Коробка машин 24 часов Ле-Мана надежная, быстро чинится и ездит в режиме 24 часов. Vertica можно сравнить как раз с такой коробкой. Ее простота в том, что легко понять, как она оптимизирует вычисления. Методы оптимизации: предподсчет агрегатов, оптимизация под Merge Join (джойн за линейное время) и фильтры Блума, то есть ускоренная фильтрация. Логика понятна, и если что-то пойдет не так, вы легко напишете workaround, который позволит вам дождаться, когда коллеги пофиксят проблему.
Teradata
На рынке MPP-систем с 1984 года.
Пользователи:
ВТБ
Cбер
BMW
Особенность Teradata — отсутствие универсальных хранилищ. Табличные данные хранятся в одном движке, time series — в другом движке, графы — где-то еще. Есть отдельные процессы для обработки ML, графовых данных. Это позволяет хорошо оптимизироваться. Если ваш запрос не самый оптимальный, система будет пытаться оптимизировать его на ходу и обойти ситуативные кейсы. Если кластер Teradata нагружен, и план выполнения запроса не самый оптимальный, она попытается перестроить его под текущие реалии. У Teradata крупные заказчики, поэтому она высоконадежна. Ее экосистема очень удобна: вы можете настроить под Teradata оркестратор или UI, который позволяет ее администрировать.
Мои ассоциации с каждой системой: Exasol — магия, Teradata — надежный инструмент, ClickHouse — хакерский инструмент, Vertica — швейцарские часы, Greenplum — большой PostgreSQL, Hadoop — черная дыра или НЛО.
 Мои ассоциации
Мои ассоциации
Я рассказал только о тех решениях, с которыми работал сам. Есть еще много других: MongoDB, Exadata, SAP HANA, Druid, MemSQL, Tarantool, Qlik.
Важно: если вы выбрали систему, общайтесь с ее представителем. Когда я только начинал общаться с вендорами, мне казалось, что это бесполезно. Как разработчику, выросшему в 90-е, мне казалось, что они предложат купить купоны и продать их коллегам, тогда они дополнительно дадут мне удвоенные купоны.
Но на самом деле модель бизнеса сильно поменялась, и коллеги из вендоров открыто общаются, говорят о слабых и сильных местах системы и даже дают контакты других пользователей, которые могут честно рассказать вам о своем опыте. Например, когда мы тестировали Exasol, нам дали контакты Badoo, мы пообщались и что-то узнали про эту систему.
Общаясь с представителем, вы можете получить скидку или триальную версию для PoC.
Советы
Соблюдайте логику хранения данных
Нельзя взять способ, которым вы хра
