Обзор операторов PostgreSQL для Kubernetes. Часть 3: CloudNativePG
Статья продолжает наш обзорный цикл о PostgreSQL-операторах для Kubernetes. В первой части мы рассматривали операторы Stolon, Crunchy Data и Zalando. Во второй — KubeDB и StackGres, а также объединили все пять операторов в сравнительную таблицу. В этот раз разбираем решение CloudNativePG, его возможности и особенности, а заодно актуализируем таблицу.

В конце апреля 2022 года компания EnterpriseDB под лицензией Apache License 2.0 выпустила CloudNativePG — Open Source-оператор PostgreSQL для Kubernetes. Этот оператор хорошо документирован, гибок и удобен в использовании, с широким набором функций.
Начало работы
Для установки CloudNativePG в Kubernetes загрузите актуальный манифест YAML и примените к нему kubectl apply. После установки будут определены объекты CustomResourceDefinition: Cluster, Pooler, Backup и ScheduledBackup — о них расскажем ниже.
Оператор работает со всеми поддерживаемыми версиями PostgreSQL. Помимо официальных Docker-образов PostgreSQL можно использовать кастомные, которые удовлетворяют требованиям в разделе Container Image Requirements документации.
Варианты развертывания кластера описаны в секции spec.bootstrap ресурса Cluster:
можно создать новый кластер —
initdb;восстановить из бэкапа —
recovery(в том числе PITR, илиpoint-in-time recovery— восстановление на указанный момент времени);скопировать данные из действующего PostgreSQL —
pg_basebackup(вариант может быть полезным при миграции существующей базы данных).
Приведем типовой манифест с описанием кластера grafana-pg из трёх инстансов с хранением данных в локальном хранилище:
---
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: grafana-pg # Название кластера.
spec:
instances: 3
primaryUpdateStrategy: unsupervised
storage:
storageClass: local
size: 1Gi
bootstrap:
initdb: # Развертывание нового кластера.
database: grafana
owner: grafana
secret:
name: grafana-pg-user
---
apiVersion: v1
kind: Secret # Secret с доступами к БД.
metadata:
name: grafana-pg-user
data:
username: {{ .Values.postgres.user | b64enc }}
password: {{ .Values.postgres.password | b64enc }}
type: kubernetes.io/basic-authСогласно концепции Cloud Native, каждую пользовательскую базу данных лучше обслуживать отдельным кластером PostgreSQL. Поэтому при создании кластера методом initdb в манифесте можно указать только одну базу. У такого подхода много плюсов; подробнее о них можно почитать в разделе Frequently Asked Questions (FAQ) документации.
Дополнительные базы и пользователей можно создать вручную под суперпользователем postgres. Либо выполнить соответствующие запросы после инициализации кластера, передав их в секции spec.bootstrap.initdb.postInitSQL.
Архитектура, репликация, отказоустойчивость
Одна из особенностей оператора — отказ от использования внешних инструментов для согласования кластера, таких как Patroni или Stolon. Вместо этого в каждый Pod помещается исполняемый файл /controller/manager, называемый Instance Manager, который напрямую взаимодействует с Kubernetes API.
Если один из резервных инстансов PostgreSQL не проходит проверки (probes) доступности, он помечается неисправным, отключается от сервисов -ro и -r и перезапускается. Затем данные синхронизируются с master«ом, и при корректно пройденных проверках инстанс вводится в эксплуатацию. При возникновении проблем с основным инстансом оператор назначает роль master«а резервному с минимальной задержкой репликации.
Примечательно, что оператор создает непосредственно Pod«ы с инстансами БД, а не ReplicaSet или StatefulSet. Поэтому для бесперебойной работы кластера рекомендуем запустить несколько Pod«ов с оператором, увеличив число реплик вdeployment cnpg-controller-manager.
Оператор поддерживает асинхронный (по умолчанию) и синхронный (на основе кворума) типы потоковой репликации инстансов. Число синхронных реплик регулируется параметрами minSyncReplicas и maxSyncReplicas.
Интересен подход к использованию local storage на K8s-узлах. При запуске Pod«а с PostgreSQL оператор проверяет наличие на узле PVC с содержимым PGDATA и пытается использовать его, применив недостающие WAL. Если это невозможно, только тогда новый узел PostgreSQL будет развернут путём копирования данных с master-инстанса. Таким образом снижается нагрузка на сеть и сокращается время развертывания новых узлов кластера.
Для подключения к PostgreSQL оператор в выбранном окружении создает для каждого кластера отдельный (по имени кластера) набор Service«ов для разных режимов доступа. Например, список Service«ов для кластера grafana-pg:
grafana-pg-rw — чтение/запись с master-инстанса;
grafana-pg-ro — чтение только с реплик;
grafana-pg-r — чтение с любого инстанса.
Отдельно стоит отметить сервис grafana-pg-any — он служебный и использоваться для подключения не должен.
Гибкие настройки для планировщика Kubernetes
Оператор позволяет задать для Pod«ов необходимые affinity/anti-affinity, nodeSelector и tolerations. Разработчики подумали за пользователя и сделали anti-affinity включенным по умолчанию, чтобы можно было разносить инстансы одного кластера PostgreSQL на разные узлы кластера Kubernetes:
affinity:
enablePodAntiAffinity: true # Default value.
topologyKey: kubernetes.io/hostname # Default value.
podAntiAffinityType: preferred # Default value.Для большей гибкости можно передать список пользовательских правил affinity/anti-affinity через additionalPodAntiAffinity и additionalPodAffinity:
additionalPodAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: postgresql
operator: Exists
values: []
topologyKey: "kubernetes.io/hostname"Резервное копирование и восстановление
Бэкапы в CloudNativePG реализованы на основе Barman — мощного Open Source-инструмента для резервного копирования и восстановления PostgreSQL.
В качестве хранилища данных могут быть использованы облачные сервисы AWS S3, Microsoft Azure Blob Storage и Google Cloud Storage, а также S3-совместимые сервисы, например, MinIO и Linode. Поддерживается несколько алгоритмов сжатия (gzip, bzip2, snappy) и шифрование.
Бэкапы настраиваются в секции spec.backup ресурса Cluster. Приведём рабочий пример с описанием резервного копирования в S3-совместимое хранилище:
backup:
retentionPolicy: "30d" # Cрок хранения архива.
barmanObjectStore:
destinationPath: "s3://grafana-backup/backups" # Путь к каталогу.
endpointURL: "https://s3.storage.foo.bar" # Сервис S3.
s3Credentials: # Данные для доступа к bucket’у.
accessKeyId:
name: s3-creds
key: accessKeyId
secretAccessKey:
name: s3-creds
key: secretAccessKey
wal:
compression: gzip # Включено сжатие WAL.Архивирование журналов предзаписи WAL с интервалом в 5 минут начнётся сразу после подключения хранилища. Для ручного создания полной резервной копии необходим ресурс Backup. Также можно настроить бэкап по расписанию с помощью ScheduledBackup:
---
apiVersion: postgresql.cnpg.io/v1
kind: ScheduledBackup
metadata:
name: grafana-pg-backup
spec:
immediate: true # Старт резервной копии после создания ScheduledBackup.
schedule: "0 0 0 * * *"
cluster:
name: grafana-pgОтметим, что формат записи spec.schedule отличается от стандартного cron, имеет 6 полей и включает в себя секунды.
Рекомендуем настроить резервное копирование по расписанию, чтобы актуальные архивы всегда были в хранилище. Во-первых, при восстановлении к свежему бэкапу быстрее применятся WAL. Во-вторых, не возникнет ситуация, при которой единственная «ручная» копия будет стерта из хранилища по достижении указанного директивой retentionPolicy срока, и восстановить данные будет невозможно.
Хотелось бы рассказать о граблях, на которые мы наступили при настройке бэкапов.
После включения резервного копирования для теста были сделаны несколько полных архивов. Ожидаемые файлы в хранилище появились, но оператор показывал, что бэкап всё ещё выполняется:
kubectl -n grafana get backups.postgresql.cnpg.io grafana-pg-backup-1655737200 -o yaml
---
apiVersion: postgresql.cnpg.io/v1
kind: Backup
[...]
status:
phase: runningСтали разбираться и поняли, что status.phase неверно отображается из-за того, что Barman не получает список объектов в bucket S3. Причина оказалась в значениях endpointURL и destinationPath. Эти директивы определяют ссылку на S3-сервис и путь к каталогу, их можно задавать в Virtual-hosted-style- и Path-style-форматах. В документации к оператору не нашлось четкого указания, какой из форматов использовать, поэтому изначально с легкой руки были указаны:
backup:
barmanObjectStore:
destinationPath: "s3://backups/"
endpointURL: "https://grafana-backup.s3.storage.foo.bar"После приведения endpointURL к формату Path-style, а destinationPath к виду s3://BUCKET_NAME/path/to/folder, хранилище корректно подключилось и значение status.phase стало отображаться правильно:
backup:
barmanObjectStore:
destinationPath: "s3://grafana-backup/backups" # Путь к каталогу.
endpointURL: "https://s3.storage.foo.bar" # Сервис S3.
kubectl -n grafana get backups.postgresql.cnpg.io grafana-pg-backup-1655737200 -o yaml
---
apiVersion: postgresql.cnpg.io/v1
kind: Backup
[...]
status:
phase: completedВосстановление
Для восстановления требуется хотя бы одна полная резервная копия в хранилище. Выполнить восстановление в текущий кластер нельзя: необходимо определить новый ресурс Cluster с другим названием в секции metadata.name.
При восстановлении в окружение с исходным кластером PostgreSQL источником данных в spec.bootstrap.recovery можно указать существующий ресурс Backup:
kubectl -n grafana get backups.postgresql.cnpg.io # Выбираем бэкап из списка доступных.
NAME AGE CLUSTER PHASE ERROR
[...]
grafana-pg-backup-1657497600 5h28m grafana-pg completed
---
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: grafana-pg-restore
spec:
[...]
bootstrap:
recovery:
backup:
name: grafana-pg-backup-1657497600Восстановление в другие окружения или Kubernetes-кластер выполняем из хранилища:
---
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: grafana-pg-restore # Название нового кластера.
spec:
[...]
bootstrap:
recovery: # Кластер будет создан из резервной копии.
source: grafana-pg
recoveryTarget:
targetTime: "2022-07-01 15:22:00.00000+00" # Метка времени.
externalClusters: # Определяем кластер с данными для восстановления.
- name: grafana-pg # Название исходного кластера.
barmanObjectStore: # Данные для подключения к хранилищу.
destinationPath: "s3://grafana-backup/backups"
endpointURL: "https://s3.storage.foo.bar"
s3Credentials:
accessKeyId:
name: s3-creds
key: accessKeyId
secretAccessKey:
name: s3-creds
key: secretAccessKeyОбратите внимание: значение секции name в разделе spec.externalClusters должно соответствовать названию исходного кластера: по этому названию оператор ищет архивы с резервными копиями в хранилище. Также нельзя допускать, чтобы резервное копирование нескольких кластеров выполнялось в один каталог в хранилище — данные в этом случае будут непригодны для восстановления.
В примере выше выполняется восстановление PITR, метка времени определена параметром bootstrap.recovery.recoveryTarget.targetTime. Если раздел bootstrap.recovery.recoveryTarget не определен, данные будут восстановлены до последнего доступного архива WAL.
Мониторинг состояния и алерты
Для управления кластером в Kubernetes имеется kubectl-плагин. С его помощью можно посмотреть текущий статус кластера, управлять ролями инстансов и сертификатами, выполнять операции reload и restart оператора, включать maintenance-режим, выгружать отчеты. Вот так плагин показывает текущее состояние кластера:

Отображается информация о состоянии репликации, инстансов, ролях, сертификатах, резервном копировании. При запуске плагина с ключами --verbose или -v вывод будет дополнен конфигурацией PostgreSQL.
В каждом инстансе кластера имеется отдельный экспортер метрик, доступный по имени /metrics через порт 9187. Для представления метрик подготовлен дашборд Grafana:
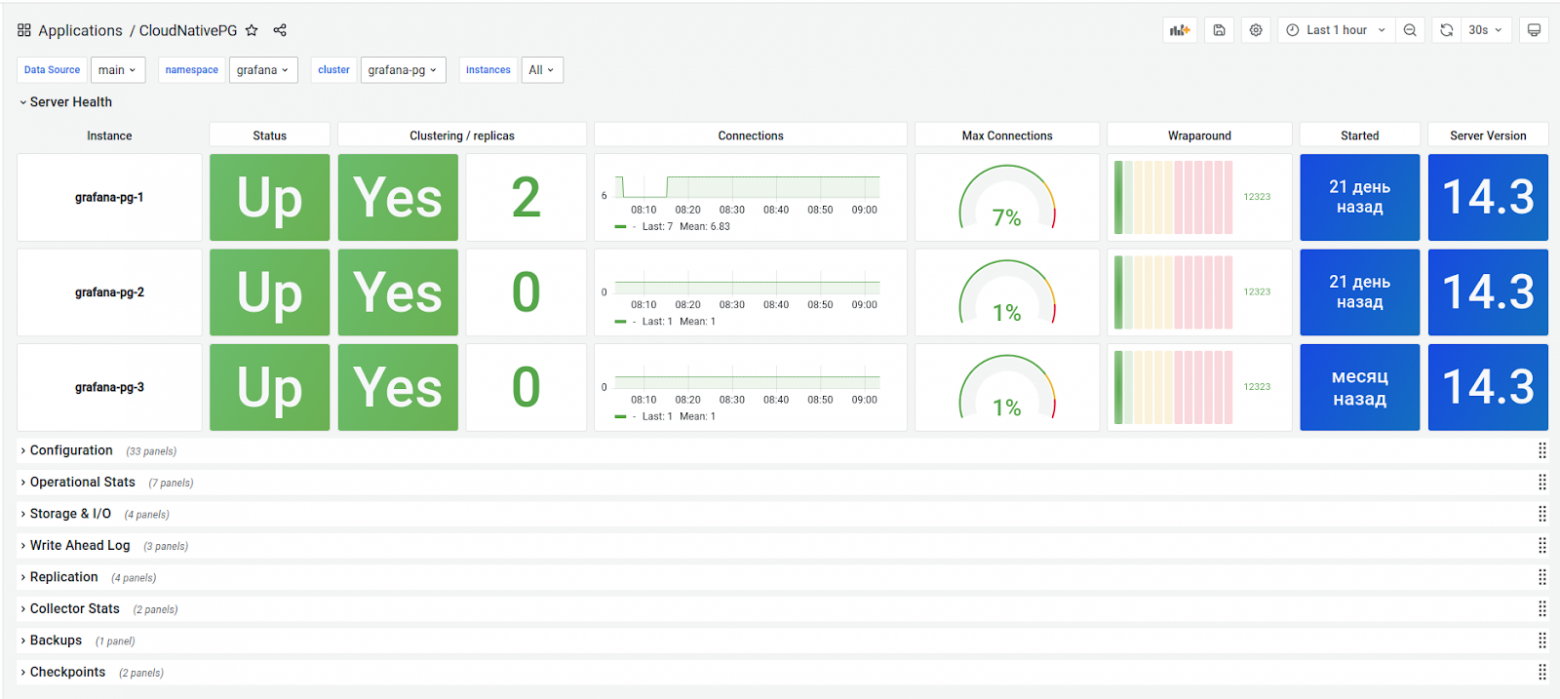
На основании метрик можно настроить алерты для Alertmanager’а — см. примеры в репозитории GitHub.
Сравнение с другими операторами
Мы актуализировали и дополнили сводную таблицу для Postgres-операторов в Kubernetes из предыдущей части:
Stolon | Crunchy Data | Zalando | KubeDB | StackGres | CloudNativePG | |
Текущая версия | 0.17.0 | 5.1.2 | 1.8.0 | 0.17 | 1.2.0 | 1.16.0 |
Версии PostgreSQL | 9.6–14 | 10–14 | 9.6–14 | 9.6–14 | 12, 13 | 10–14 |
Общие возможности | ||||||
Кластеры PgSQL | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
Теплый и горячий резерв | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
Синхронная репликация | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
Потоковая репликация | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
Автоматический failover | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
Непрерывное архивирование | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
Инициализация: из WAL-архива | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
Бэкапы: мгновенные, по расписанию | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ |
Бэкапы: управляемость из кластера | ✗ | ✗ | ✗ | ✓ | ✓ | ✓ |
Инициализация из снапшота | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
Специализированные возможности | ||||||
Встроенная поддержка Prometheus | ✗ | ✓ | ✗ | ✓ | ✓ | ✓ |
Кастомная конфигурация | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
Кастомный Docker-образ | ✓ | ✗ | ✓ | ✓ | ✗ | ✓ |
Внешние CLI-утилиты | ✓ | ✓ | ✗ | ✓ (kubectl-плагин) | ✗ | ✓ (kubectl-плагин) |
Конфигурация через CRD | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ |
Кастомизация Pod’ов | ✓ | ✗ | ✓ | ✓ | ✗ | ✓ через PodTemplateSpec |
NodeSelector и NodeAffinity | ✓ | ✓ | ✓ (через патчи) | ✓ | ✓ | ✓ |
Tolerations | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
Pod anti-affinity | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
Выводы
Оператор оставил приятное впечатление. Даже те функции, что мы попробовали, покрывают большую часть потребностей. Новый кластер легко запустить, отказоустойчивость работает из коробки. Радуют многообразие сценариев развертывания кластера, гибкие параметры для планировщика Kubernetes, наличие предустановленных метрик с экспортерами, возможность определять пользовательские метрики. Бэкапы получились функциональными, но простыми в настройке и управлении.
Статья не раскрывает все возможности оператора, за бортом осталось немало интересного. Например, можно изменять ряд настроек оператора и делать тюнинг PostgreSQL. Встроена поддержка PgBouncer для управления пулами соединений, его можно включить и настроить через кастомный ресурс Pooler. Поддерживается создание кластера как реплики другого кластера и многое другое. Оператор получился интересный и продуманный. Рекомендуем!
P.S.
Читайте также в нашем блоге:
