Обзор конференции Highload fwdays’17

14 октября в Киеве прошла конференция Highload fwdays, посвященная высоконагруженным проектам, работе с базами данных и архитектурой, в частности, микросервисами, машинному обучению и Big Data. DataArt был спонсором конференции. А наши коллеги Игорь Мастерной (лидер Java-сообщества DataArt Киев) и Анна Колот (.NET, SharePoint Developer) рассказали о докладах, на которых они побывали.
Детально с программой конференции можете ознакомиться тут.
Начнем обзор с доклада Дмитрия Охонько из Facebook про Log Device. «Yet another log storage», — подумаете вы. Вы бы были правы, но этот Log Storage на общем фоне выделяется своими создателями. Заявленная пропускная способность у Facebook — 1TB/s. И узнать, как они справляются с обработкой такого объема данных, было интересно.
LogDevice

Для чего нужен Log Device? На презентации были представлены следующие юзкейсы:
- Reliable communication between services.
- Write ahead logging.
- State replication.
- Journaling.
- Maintaining secondary indexes on a big distributed data store.
Система призвана быстро надежно доступно и на века записать огромное количество append only-логов, которые выступают наименьшими адресуемыми единицами. Кроме того, система должна гарантировать порядок записи лога и возможность достать его при необходимости. Посмотрим на ее архитектуру.

Рис. 1 Архитектура LogDevice.
Данные, которые пишутся в LogDevice, для начала поступают на так называемые sequencer-ноды (на рисунке это красный и зеленый ромбы). У каждого лога свой sequencer, который генерирует номер, состоящий из двух чисел: номера эпохи и порядкового номера записи. Такая комбинация идентификаторов необходима, чтобы гарантировать отказоустойчивость самого секвенсора. Если sequencer-нода умирает, новая должна продолжить запись логов, идентификаторы которых будут больше ранее записанных. Для этого новая нода увеличивает номер эпохи. Метаданные о логах, идентификаторы эпох логов хранятся в zookeeper.
Далее лог с полученным идентификатором записывается в определенное количество storage nodes. Докладчик объяснил, что внутри storage-ноды крутится key-value база данных Rocks DB. Каждый лог в ней представляет собой запись вида:
{LOG_ID, LSN, COPYSET, DATE, Payload}
- LOG_ID — тип лога;
- LSN — идентификатор записи;
- COPYSET — список идентификаторов нод, которые содержат запись;
- Payload — тело лога.
Как работает чтение записей? Как видно на рисунке, каждый Reader client подключается ко всем нодам, которые содержат записи нужных ему логов. Каждая нода выдает записи начиная с указанного идентификатора, либо даты. Задача Reader client — убрать дубликаты и отсортировать полученные записи.
Детальнее про LogDevice вы можете прочитать на Facebook. Запланированный выход в open source — конец 2017 года.
ML доклады

По соседству с выступлениями о Highload и Big Data можно было глубже познакомиться с модным направлением Machine Learning. Нам удалось послушать доклады Сергея Ващилина (PayMaxi) «Семантический анализ текста и поиск плагиата» и Александа Заричкового (Ring Ukraine) «Faster than real-time face detection».
Семантический анализ текста
Докладчик прошелся по базовым алгоритмам в области, однако тема машинного обучения осталась не раскрытой. В докладе были представлены алгоритмы SVD, tf-idf для поиска ключевых слов документа, shingles algorithm и применение архиватора lzm для сравнения похожести двух документов. Описанная автором система представляет собой относительно недорогой способ проверки документов на совпадения.
На входе системе подается документ, в котором с помощью SVD находят ключевые слова, по этим словам производится поиск похожих документов в интернете. В качестве кэша, для ускорения поиска используется Apache Lucene, который позволяет локально сохранять и индексировать документы. Найденные документы обрабатываются с помощью алгоритма шинглов и сравниваются с входящим документом.
Достоинства системы — в ее простоте и дешевизне разработки в сравнении с аналогами. Недостаток системы — отсутствие настоящего семантического анализа текста и более интеллектуального поиска ключевых слов.
Faster than real-time face detection
В докладе был представлен обзор методов машинного обучение для распознования объектов на картинках и определения их местоположения на них (как на рисунке 2). Докладчик рассказал историю методов распознавания начиная от детектора Виолы-Джонса и до современных (2015) сверточных нейронных сетей типа YOLO, SSD.

Рис. 2 Распознование объектов и их расположения.
Этот доклад особенно заинтересовал тем, что его представлял украинский стартап Ring Ukraine, который работает над созданием устройства «умного дверного звонка». Насколько понятно из выступления, описанные нейронные сети широко используются для определения лица человека, звонящего в вашу дверь. Основной сложностью, со слов докладчика, остается определение звонящего в реальном времени, для чего необходима высокая скорость самого распознавания. Современные нейронные сети YOLO или SSD обладают такими характеристиками, ниже сравнительная таблица архитектур различных нейронных сетей.
Таблица 1. Сравнение архитектур нейронных сетей
| Model | Train | mAP | FLOPS | FPS |
|---|---|---|---|---|
| YOLO | BVOC 2007+2012 | 40.19 | 40.19 | 45 |
| SSD300 | VOC 2007+2012 | 63.4 | - | 46 |
| SSD500 | VOC 2007+2012 | 74.3 | - | 19 |
| YOLOv2 | VOC 2007+2012 | 76.8 | 34.90 | 67 |
| YOLOv2 544×544 | VOC 2007+2012 | 76.8 | 59.68 | 40 |
| Tiny YOLO | VOC 2007+2012 | 57.1 | 6.97 | 207 |
Как мы можем увидеть в Таблице 1, нейронные сети отличаются характеристиками скорости (FPS — frames per second) и точности (mAP — mean average precision) распознавания, что позволяет выбрать нейронную сеть под конкретную задачу.
New features in Elastic 6

Доклад Филиппа Кренна из Elastic начался с приведенной ниже таблицы с сайта db-engines.com, отслеживающего популярность поисковых систем. Elastic опережает ближайшего конкурента Solr в два раза. Его используют такие организации, как CERN, Goldman Sachs и Sprint.
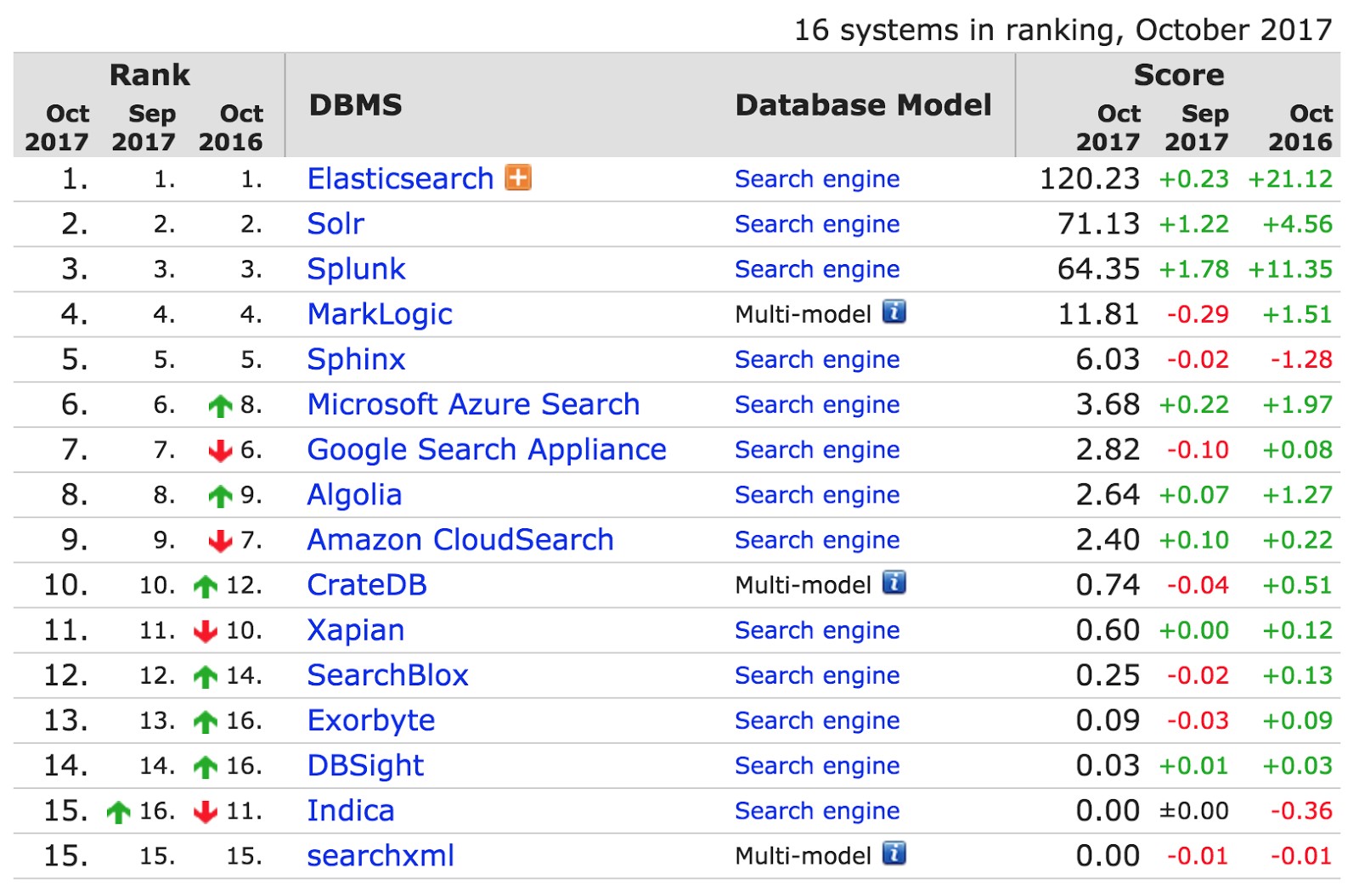
Что же такого классного в новом Elastic 6, beta-версия которого вышла в августе? В докладе были представлены следующие новинки.
Cross cluster search
Позволяет искать данные в нескольких Elastic-кластерах. Такая возможность уже существовала, но реализована она была неоптимально — с помощью Tribe-ноды. Tribe хранила merged state обоих кластеров, принимая любой апдейт состояния каждого подконтрольного Elastic-кластера. Плюс ко всему Tribe-нода, которая получила request, самостоятельно определяла, какие индексы, шарды и ноды необходимо опросить и какие top-N документов должны быть загружены.
Сross cluster search не требует отдельной выделенной ноды и merged state обоих кластеров. Любая нода может принимать cross-cluster запросы. Cross cluster-запрос обрабатывается координационной нодой, которая общается с тремя сконфигурированными seed nodes другого кластера. Также можно настроить gateway-ноду, которая непосредственно принимает подключение от координатора и выступает в роли прокси. Для координации с точки зрения API нет никакой разницы в поисковых запросах индексов на другом кластере — результаты будут помечены префиксом с именем второго кластера. Cross cluster search унифицирует поисковый API и убирает некоторые ограничения по сравнению с Tribe-нодой (поиск по индексам с одинаковыми именами на локальном и связанных кластерах). Подробнее можно прочитать здесь и здесь.
Как же мигрировать существующий Elastic 5 кластер на Elastic 6? Начиная с шестой версии вы сможете обновлять версию при помощи Rolling Upgrades, не останавливая Elastic-кластер (валидно для перехода с Elastic 5.6 → Elastic 6).
Sequence numbers
Sequence numbers еще одна из важных новых фич Elastic 6. Каждой операции update, delete, put будет присваивается последовательный идентификатор, для того чтобы отстающая secondary реплика смогла восстановить ход операций из Transaction-лога начиная с i-й, не копируя при этом файлы. Пользователям предоставляется возможность конфигурировать время хранения transaction-лога.
Типы
Ранее Elasticsearch представлял типы (Mapping types) как таблицы в базе данных (индексе). Хотя аналогия не совсем точная. Колонки в базах данных с одинаковым именем могут не зависеть друг от друга, но в Elastic поля двух разных Mapping types должны иметь одинаковый Field type. Нельзя полю deleted date одного типа присвоить boolean в другом типе. Это связано с тем, как именно Elastic реализует типы. Apache Lucene под капотом Elastic хранит поля разных типов в одном и том же поле. Теперь Elastic решил постепенно отказаться от типов в индексах. В Elastic 6 каждый индекс может содержать только один тип и может не быть указан при индексации. В следующих версиях поддержка типов будет и вовсе прекращена.
Топ-10 архитектурных фейлов на реальном highload проекте
По подаче понравился доклад Дмитрия Меньшикова «Топ-10 архитектурных фейлов на реальном highload проекте». Дмитрий — прирожденный оратор, владеет словом, удачно добавляет в выступление юмор и поддерживает интерес аудитории. Докладчик показал десять кейсов, рассказал, что привело к проблемам, и как ситуацию смогли разрешить.
К примеру:
- Как ошибка выбора идентификатора пользователя UUID в формате date+time+MAC address и длиной 128 бит, обнаруженная после запуска проекта в эксплуатацию, привела к замедленной работе и чуть не стоила двух лет разработки. И как простое решение увеличить длину индекса до 4 байт спасло положение. Как известно, timestamp — величина 60-битная, и для UUID версии 1 представлена как счет 100-наносекундных интервалов по UTC, начиная с 00:00:00.00 15 октября. Проблема заключалась в том, что не было учтено возможное попадание секундной фракции в начало и отсутствие равномерного распределения из-за особенностей генерации идентификаторов.

- Как новый разработчик решил поправить давно падающий тест, добавил проверку на существование ключа и порядка 2 млн пользовательских писем, которые не имели ключа, были утеряны.
На наш взгляд, доклад не был насыщен сложными производственными деталями. Но вывод неизменен: внедряемые решения необходимо проверять на практике и думать, как изменение затронет систему.
Ловушки микросервисной архитектуры
Никита Галкин, системный архитектор из GlobalLogic, представил доклад «Ловушки микросервисной архитектуры». Основные проблемы при внедрении микросервисов, по мнению Никиты, состоят в разработке без использования шаблонных подходов — когда в одном случае файл с настройками называется config, в другом — settings и т. п.; отказе от ежедневного обновления документации в процессе разработки; применении микросервисов там, где задачу можно решить коробочными средствами уже внедренных продуктов.
High[Page]load
Интересным оказался доклад «High[Page]load» Дмитрия Волошина, сооснователя Preply.com, сайта для поиска репетиторов по всему миру. Дмитрий рассказал об истории развития сайта, как возникла необходимость измерять и улучшать длительность загрузки страницы с увеличением числа пользователей с трех человек до миллиона и с выходом сайта на межконтинентальный рынок.
Основная идея доклада — необходимость постоянного мониторинга факторов, влияющих на скорость загрузки страницы; необходимость работ по улучшению показателей, так как успешность бизнеса прямо зависит от скорости загрузки страницы.

Средства, применяемые в Preply для повышения скорости загрузки страницы:
- базовые: caching, orm optimizations;
- более продвинутые: replicas, load-balancing;
- текущие: CDN, microservices.

