Обзор и сравнительное тестирование ПЭВМ «Эльбрус 401‑PC». Часть четвёртая — бенчмарки
Заключительная часть статьи посвящена сравнению производительности нового российского компьютера с зарубежными конкурентами и собственными предшественниками.

Осторожно: много букв и картинок!
Напоминаем содержание предыдущих частей:
- обзор аппаратного обеспечения:
- процесс приобретения;
- аппаратное обеспечение;
- обзор программного обеспечения:
- запуск операционной системы;
- штатное программное обеспечение;
- обзор средств разработки:
- особенности архитектуры;
- машинный язык;
- средства разработки;
- сравнительное тестирование производительности:
Приятного чтения!
Автор долгое время находился в глубоком заблуждении, полагая, что данный компьютер приобретается фирмой для собственных нужд — в дополнение к эксплуатируемой технике более раннего поколения. И только в момент получения выяснилось, что новинка предназначена для дальнейшей поставки в составе комплекса. Поэтому, вместо запланированного изначально вдумчивого чтения документации, практического ознакомления со всеми тонкостями, тщательного подбора средств тестирования и прочей медитативной деятельности, пришлось действовать быстро, если не сказать хаотично. Градус неадекватности дополнительно повысился благодаря пред‑ и посленовогоднему авралу, в посильном устранении которого автор параллельно участвовал.
«Сделать правильное тестирование можно только одним способом. Сделать неправильное тестирование можно бесконечным числом разных способов. И сами угадайте, что чаще всего случается». (nutanix)
Достичь какого‑то «истинно правильного» результата, прицельно раскрывающего уникальные достоинства или недостатки той или иной платформы, мы перед собой не ставили. Хотелось просто получить обиходное представление о вычислительных мощностях нового «Эльбруса» на фоне ранее известных образцов отечественной и западной электроники, — с позиции рядового пользователя, использующего готовые программы в собранном виде или компилирующего их из исходных кодов без применения эзотерических знаний по оптимизации и портированию. Поэтому в статье не будет сенсаций вида «Эльбрус порвал Xeon при шифровании по алгоритму ГОСТ» или «Эльбрус в режиме эмуляции x86 работает даже быстрее, чем исполняя нативный код» (что можно тут и там прочитать в Интернете, и всегда почему‑то без раскрытия подробностей). Впрочем, истины и интриги ради, стоит заметить, что в одной серии тестов главный герой данного обзора действительно продемонстрировал в несколько раз более высокие результаты, чем аналогичный компьютер на базе Core i7.
Поскольку абсолютные значения полученных в бенчмарках результатов обычно представляют собой весьма абстрактные величины, даже когда алгоритмы тестирования основаны на программном коде реальных приложений, было решено провести серию одинаковых измерений на целом ряде компьютерных платформ, максимально отличающихся друг от друга и в то же время покрывающих почти весь спектр актуальной техники схожего назначения.
Компьютер архитектуры x86‑64 на базе Intel Atom

Пожалуй, идеальным соперником для «Эльбруса» был бы какой-нибудь современный Intel Celeron или Atom с четырьмя ядрами и низкой частотой, либо аналог под маркой AMD;, но из того, что имелось в закромах, нашёлся только двухъядерный Atom D2500, распаянный на материнской плате Intel D2500CC формата mini‑ITX. Конфигурация этого компактного и заведомо не слишком резвого компьютера, наверное, не нуждается в дополнительных пояснениях; у неё был только один нетипичный компонент — 3,5‑дюймовый жёсткий диск (правда, начальной серии), но, так как производительность ввода-вывода не находилась в фокусе исследования, этим фактом можно пренебречь. Для обеспечения максимальной схожести в программном плане, в качестве операционной системы был выбран дистрибутив Debian 7.9.0 для архитектуры x86‑64 с ядром Linux 3.2.0 (тем более, что установка и обновление более старых версий Debian — квест не для слабых духом).
Компьютер архитектуры x86‑64 на базе Intel Core i7


Вторым естественным участником стал компьютер с противоположного полюса функций и быстродействия — настольная мини-башня Dell OptiPlex 990 с процессором Core i7‑2600 и оригинальной материнской платой на базе чипсета Q67. Система работала в своём повседневном режиме — с отключённой функцией разгона (Turbo Boost), но с включённой технологией многопоточности (Hyper-Threading), под управлением openSUSE 13.2 для архитектуры x86‑64 с ядром Linux 3.16.7.
Компьютер «Эльбрус‑90 микро» на базе МЦСТ R500


Однако было бы некорректным проводить сравнение только с мейнстримом, так как новый «Эльбрус‑4С» — это в первую очередь замена старым представителям продуктовой линейки «Эльбрус», включающей в себя не только компьютеры архитектуры E2K, но также SPARC. К сожалению, наша фирма не располагает техникой современной архитектуры SPARC V9, такой как МЦСТ R1000, зато «имеем счастье» возиться с целым выводком R500 — из поколения SPARC V8, которое ещё 32-битное. Первым представителем старой гвардии стал компьютер «Эльбрус‑90 микро» в формате обычной мини-башни с двумя распаянными процессорами R500, дискретной видеокартой собственной разработки, обычным жёстким диском и оптическим приводом. Операционной системой этого компьютера является МСВС 3.0 для архитектуры SPARC с ядром Linux 2.4.25, компилятором GCC 3.3.6 и библиотекой GNU LibC 2.2.5.
Другой компьютер архитектуры SPARC V8 на базе R500 (примерный вид, фото с сайта МЦСТ)

Другой компьютер тоже оснащён парой процессоров R500, но выполнен в модульном конструктиве «Евромеханика 6U», имеет всего 512 Мбайт оперативной памяти и флэш-карту промышленного уровня в качестве основного накопителя (модель Meltron P7 гордо именуется «SSD», но фактическая производительность в составе данного компьютера скорее ближе к старым, медленным флэшкам). Принципиальное отличие от предыдущего участника — в том, что здесь установлена операционная система «Эльбрус» (ОС 311‑03), датированная началом 2011 года, с ядром Linux 2.6.16, компилятором LCC 1.16.12 (заявлена совместимость с GCC 3.4.6) и библиотекой GNU LibC 2.16.0. Как будет видно далее, эти программные отличия от МСВС иногда приводят к существенной разнице в быстродействии, причём чаша весов склоняется то в одну сторону, то в другую. Поэтому ниже приведены обе серии результатов, обозначенные соответственно «R500/E» для компьютера с системой «Эльбрус» и «R500/M» для компьютера с системой МСВС.
Как уже вкратце упоминалось, в состав программного обеспечения входит довольно обширная коллекция тестовых утилит для проверки корректности функционирования аппаратуры и системных библиотек, а также для измерения производительности. Часть этих утилит является собственной разработкой фирмы МЦСТ, часть — известные программы сторонних авторов. Среди последних также встречаются версии, адаптированные специально для «Эльбруса»: например, CoreMark требует для каждой платформы реализовать свой интерфейс, учитывающий особенности компилятора и библиотек, системных вызовов и структур данных, многопоточности, средств измерения времени. Никаких скрытых преимуществ это портирование не даёт, впрочем, тем более что результаты основного прогона затем перепроверяются с использованием профилировщика.
Тест CoreMark создан Консорциумом по измерению производительности встраиваемых микропроцессоров (EEMBC) и состоит из нескольких синтетических задач, включающих обработку матриц и связанных списков, переключение состояний конечного автомата, вычисление контрольной суммы. Видимо, по той причине, что для скачивания исходных кодов и публикации полученных результатов требуется регистрация, этот тест не снискал большой популярности: всего в базе на данный момент 406 записей.
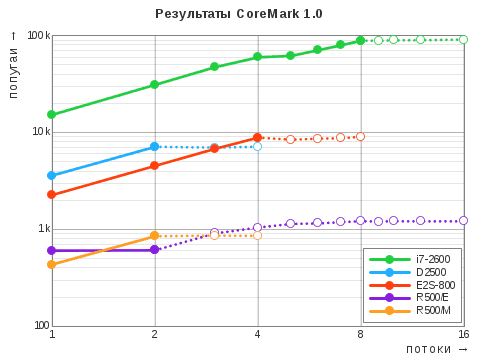
| Режим | i7‑2600 | D2500 | E2S-800 | R500/E | R500/M |
|---|---|---|---|---|---|
| одно ядро | 15'218 | 3'595 | 2'260 | 602 | 434 |
| все ядра | 88'570 | 7'108 | 8'850 | 1'214 | 850 |
Результат, достигнутый процессором «Эльбрус‑4С» в однопоточном режиме, находится чуть выше старого AMD Athlon XP‑M с той же тактовой частотой, а при задействовании всех четырёх ядер — близок к двухъядерным Athlon 64×2 QL‑65, Intel Atom 330, D525, D2500, Core 2 Duo E4300, у которых частота минимум вдвое выше.
Странное поведение продемонстрировал R500 с операционной системой «Эльбрус»: при использовании двух потоков или двух процессов, оба они делили одно ядро поровну, и только третий и последующие потоки или процессы распределялись и на второе ядро тоже, а насыщение происходило только при степени параллелизма, равной 8. Поэтому на диаграмме пунктиром также нанесены дополнительные результаты при количестве потоков, превышающих количество ядер того или иного компьютера: как можно видеть, у всех прочих участников тестирования эти пунктиры складываются в горизонтальную линию — так и должно быть, когда каждый поток поглощает все доступные ему ресурсы. Причины аномалии выяснить не удалось: возможно, таковы особенности настройки планировщика задач в системе «Эльбрус» на том компьютере.
Идея включить в программу испытаний встроенный тест архиватора созрела после прочтения обзора на CNews 2014 года, где так же сравнивалась производительность Core i7‑2600 (без Hyper-Threading, но с Turbo Boost, видимо) и «Эльбрус‑4С», правда, на частоте 700 МГц, а также «Эльбрус‑2С+», у которого всего два ядра и частота 500 МГц, зато есть ещё четыре ядра сигнальной обработки ElCore9 DSP фирмы «Элвис» (впрочем, они никак не были задействованы в том тестировании). Судя по приведённым там значениям, автор запускал »7z b» и делил результат на количество ядер. Мы публикуем результаты в первозданном виде, причём на диаграмме в качестве меры быстродействия выбрано оценочное количество целочисленных операций на всех ядрах за единицу времени (MIPS), а в таблице указана абсолютная скорость обработки данных и относительный рейтинг одного ядра, учитывающий фактическую загруженность процессора в том или ином режиме работы.
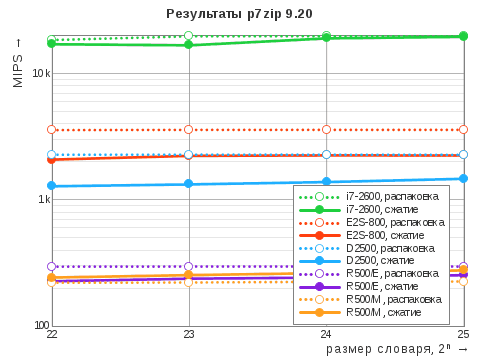
| Показатель | i7‑2600 | D2500 | E2S-800 | R500/E | R500/M |
|---|---|---|---|---|---|
| сжатие, Мбайт/с | 17'200 | 1'300 | 2'144 | 228 | 247 |
| распаковка, Мбайт/с | 211'282 | 24'738 | 38'894 | 3'227 | 2'430 |
| рейтинг, MIPS | 18'781 | 1'823 | 2'920 | 269 | 241 |
| рейтинг ядра | 2'662 | 1'000 | 843 | 263 | 243 |
Здесь мы можем наблюдать, как новый «Эльбрус» почти не отстаёт от Atom даже в однопоточном режиме, а суммарная производительность всех ядер превосходит показатели оного уже существенно — в полтора раза.
Нежелание масштабироваться при двух потоках на этот раз показали оба компьютера на базе R500. Более того, 7‑Zip в системе МСВС почему‑то не мог определить степень загруженности ядер при распаковке, — пришлось принять её равной 99% по аналогии со сжатием и вычислять рейтинг вручную.
Аналогично предыдущему тесту, решение погонять OpenSSL естественным образом пришло после неоднократного столкновения с тезисами типа «Отечественные процессоры очень эффективны в криптографии, особенно на алгоритмах ГОСТ» (какие реализации алгоритмов при этом используются, увы, не уточняется). Поиски файлов, содержащих слово »gost» в своём имени, увенчались довольно скромным результатом:
/usr/include/nettle/gosthash94.h /usr/include/php/ext/hash/php_hash_gost.h
Поставляемый вместе с системой самый обычный OpenSSL 0.9.8zc также не мог ничем похвастаться. Поэтому для тестов были выбраны более популярные алгоритмы хеширования, симметричного шифрования и вычисления цифровой подписи.
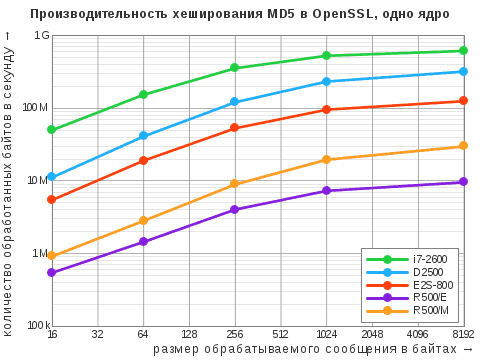
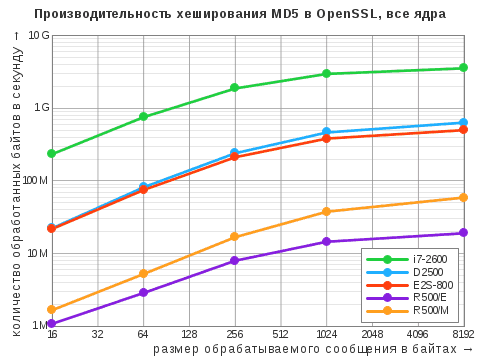
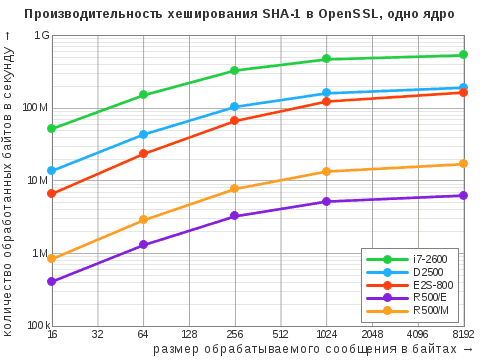
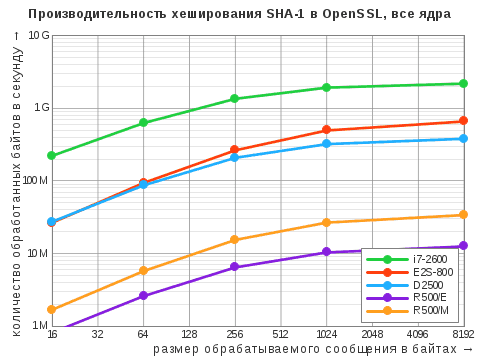
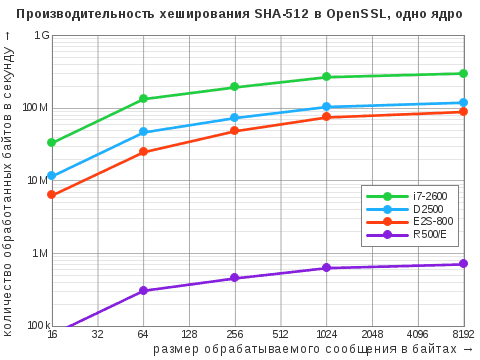
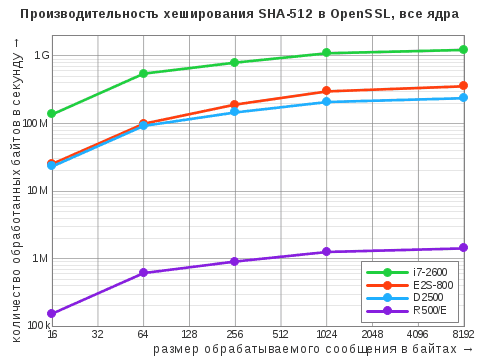
| Алгоритм | i7‑2600 | D2500 | E2S-800 | R500/E | R500/M |
|---|---|---|---|---|---|
| MD5 | 615 / 3546 | 320 / 635 | 125 / 500 | 10 / 19 | 30 / 59 |
| SHA-1 | 534 / 2181 | 192 / 381 | 165 / 658 | 6,3 / 13 | 17 / 34 |
| SHA-512 | 301 / 1227 | 119 / 237 | 89 / 355 | 0,7 / 1,4 | – |
Здесь и ниже приведены максимальные показатели, выраженные в «десятичных» мегабайтах в секунду. Через дробь указаны результаты при задействовании одного ядра и всех ядер. Прочерк означает, что данный алгоритм не поддерживается в штатной версии OpenSSL: у старой системы «Эльбрус» это 0.9.8b, у МСВС — 0.9.7b (да, мы не уязвимы к Heartbleed!).
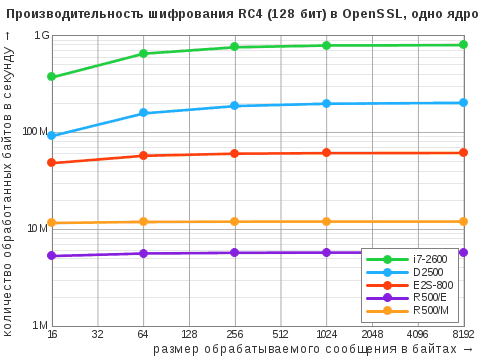
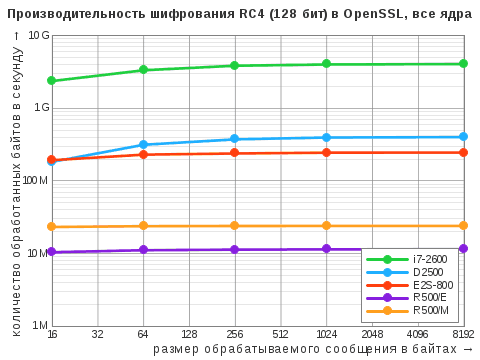
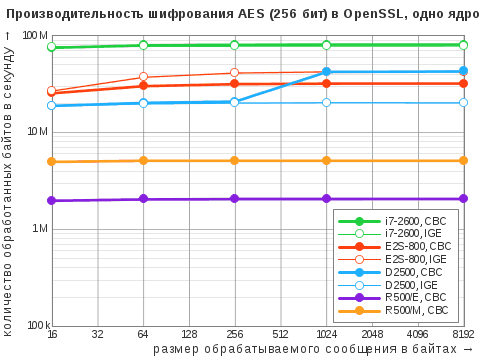
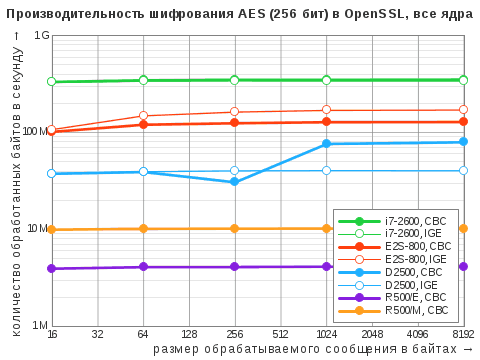
| Алгоритм | i7‑2600 | D2500 | E2S-800 | R500/E | R500/M |
|---|---|---|---|---|---|
| RC4 | 797 / 4060 | 202 / 401 | 61 / 246 | 5,8 / 12 | 12 / 24 |
| AES-CBC | 81 / 351 | 43 / 79 | 32 / 128 | 2,1 / 4,1 | 5,1 / 10 |
| AES-IGE | 78 / 341 | 20 / 40 | 43 / 170 | – | – |
Тогда как симметричная криптография обычно занимает одинаковое время при зашифровании и расшифровании сообщений равного объёма (за исключением, быть может, затрат на выработку начального состояния), асимметричные алгоритмы имеют дело с данными фиксированного размера, но требуют выполнения разного набора или количества действий для формирования и проверки цифровой подписи. Поэтому далее результаты приводятся раздельно и выражены в количестве операций в секунду.
| Алгоритм | i7‑2600 | D2500 | E2S-800 | R500/E | R500/M |
|---|---|---|---|---|---|
| RSA-4096, подпись | 105 / 477 | 11 / 22 | 6,6 / 27 | 0,8 / 1,7 | 0,8 / 1,5 |
| RSA-4096, проверка | 6496 / 30'176 | 700 / 1400 | 453 / 1790 | 56 / 126 | 49 / 98 |
| DSA-2048, подпись | 2396 / 11'200 | 267 / 534 | 157 / 634 | 20 / 40 | 18 / 37 |
| DSA-2048, проверка | 2052 / 9531 | 220 / 440 | 136 / 534 | 17 / 34 | 15 / 29 |
| ECDSA-p384, подпись | 4896 / 22'480 | 782 / 1560 | 273 / 1085 | 55 / 108 | – |
| ECDSA-p384, проверка | 1135 / 4994 | 157 / 312 | 49 / 198 | 10 / 21 | – |
| ECDH-p384, обмен | 1367 / 6014 | 187 / 374 | 58 / 233 | 12 / 25 | – |
Суммарная производительность «Эльбрус‑4С» в этих тестах тоже находится на уровне Atom D2500, демонстрируя то преимущество, то отставание от алгоритма к алгоритму. Результаты R500 с операционной системой «Эльбрус» приведены для 4-х потоков, — именно в таком режиме он выходил на максимум, при этом всё равно сильно проигрывая своему же собрату под управлением МСВС на хешировании и шифровании, но слегка реабилитируясь на задачах асимметричной криптографии.
Этот набор синтетических тестов, затрагивающих самые разные аспекты работы компьютера, — от элементарных арифметических действий до системных вызовов и дисковых операций, — впервые был разработан в начале 80‑х годов и, постепенно эволюционируя, дожил до наших дней, не растеряв популярность как кроссплатформенное средство интегральной оценки производительности системы в целом и отдельных компонент в частности.
| Тест | i7‑2600 | D2500 | E2S-800 | R500/E | R500/M |
|---|---|---|---|---|---|
| Dhrystone 2 | 3240 / 13'735 | 595 / 1190 | 185 / 738 | 67 / 132 | 59 / 118 |
| Whetstone | 820 / 5344 | 171 / 382 | 126 / 505 | 27 / 52 | 23 / 46 |
| Execl | 886 / 5630 | 257 / 524 | 82 / 314 | 47 / 85 | 88 / 136 |
| File, 1024/2000 | 3040 / 2994 | 451 / 683 | 287 / 373 | 44 / 47 | 37 / 32 |
| File, 256/500 | 1983 / 1890 | 307 / 479 | 185 / 232 | 34 / 34 | 30 / 23 |
| File, 4096/8000 | 4273 / 5664 | 807 / 1112 | 618 / 904 | 55 / 57 | 38 / 42 |
| Pipe | 1747 / 8922 | 419 / 851 | 209 / 824 | 59 / 115 | 107 / 181 |
| Context | 585 / 4865 | 214 / 428 | 175 / 688 | 51 / 99 | 62 / 116 |
| Fork | 1260 / 4537 | 264 / 570 | 63 / 222 | 78 / 85 | 83 / 120 |
| Shell, 1 | 1968 / 6990 | 458 / 703 | 210 / 551 | 45 / 65 | 123 / 183 |
| Shell, 8 | 5465 / 7113 | 670 / 684 | 490 / 562 | 68 / 68 | 166 / 166 |
| SysCall | 2978 / 6584 | 781 / 1183 | 333 / 1082 | 79 / 152 | 133 / 223 |
| итого | 1920 / 5550 | 403 / 682 | 203 / 519 | 52 / 76 | 66 / 92 |
Следует заметить, что в комплекте программного обеспечения «Эльбрус 401‑PC» имелась версия UnixBench 5.1.2, но для единообразия везде использовалась актуальная версия 5.1.3, тем более что штатный вариант демонстрировал те же показатели (в рамках погрешности измерения).
Трудно было пройти мимо статьи об ускорении Postgresql на IBM Power8, где описывался процесс оптимизации программного кода для этой архитектуры в частности и была дана положительная оценка развития проекта в целом, не заразившись желанием проверить, насколько далека более скромная техника от приведённых там фантастически высоких показателей производительности. Другое дело, что выбранные для тестирования персональные компьютеры не претендуют на роль серьёзного сервера баз данных не только потому, что имеют гораздо меньше процессорных ядер и потоков исполнения, но и меньше кэша, оперативной памяти, «никакую» дисковую систему. Однако объём тестовой базы (менее 0,5 Гбайт) вполне укладывается в рамки личного хранилища данных, уместного на личном компьютере и, более того, полностью умещается в оперативной памяти большинства выбранных машин. Поэтому данный тест можно считать комплексным мерилом быстродействия всего компьютера в целом, которое, в отличие от UnixBench, имеет реалистичный, хотя и однобокий, характер нагрузки.
Операционная система компьютера «Эльбрус 401‑PC» имеет в своём составе Postgresql 9.2.3, и данную версию решено было сделать точкой отсчёта для всех остальных участников, не забыв при этом о более актуальных версиях. Скопировав репозиторий разработчиков по состоянию на 3 декабря 2015 года, мы попытались самостоятельно собрать текущую версию, далее обозначаемую »9.6devel», но ещё на этапе конфигурирования выяснилось, что для каждой архитектуры требуется платформенно-зависимая реализация спинлоков (о том, что это такое, и чем отличается от остальных видов блокировок, используемых Postgresql, рассказывается в упомянутой выше статье), и для E2K в мейнлайне её нет, конечно же. В качестве запасного варианта можно использовать режим »‑‑disable-spinlocks», однако, как и предупреждает документация, ценой ощутимого — хотя и не катастрофического — падения производительности. Причём, если самостоятельно собранная версия 9.6devel оказалась медленнее штатной 9.2.3, то собранная затем также из публичных исходных текстов версия 9.2.3 оказалась ещё медленнее, чем 9.6devel. А повторный запуск штатной версии 9.2.3 после окончания всех прочих тестов подтвердил, что падение производительности нельзя объяснить одними только особенностями SSD-накопителя (хотя и без них тоже не обошлось в комбинированном тесте на чтение и запись). Отсюда напрашивается вывод, что программисты МЦСТ внесли в штатную версию необходимые поправки, то есть выполнили полноценное портирование, и потому мы будем обозначать эту версию суффиксом »e2k», а самосборный вариант без спинлоков — суффиксом »ds».
Напротив, никаких проблем при сборке версии 9.2.3 из публичных исходных текстов не возникло на платформе SPARC, так как она поддерживается официально. Однако попытка закрепить успех с версией 9.6devel потерпела неудачу на этапе компиляции, так как memory barriers (механизм обеспечения строгого порядка операций с памятью на процессорах с внеочередным исполнением инструкций) теперь поддерживаются только на SPARC V9. Та же ошибка возникала при сборке версии 9.4.5 (основной стабильной ветки на тот момент), хотя в документации и поныне заявлена поддержка старой архитектуры.
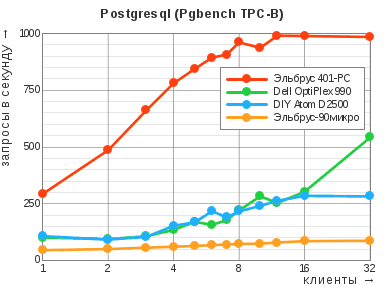
Методика тестирования была максимально прямолинейной: СУБД запускалась с настройками по умолчанию сразу после инициализации хранилища, там создавалась тестовая база данных, которая заполнялась утилитой Pgbench в расчёте на 32 параллельных потока, и затем проводилась серия запусков Pgbench по 60 секунд каждый с меняющимся количеством имитируемых клиентов, каждый из которых работал в своём потоке (так результаты получались выше, чем когда несколько клиентов делило один поток). Количество запросов, переданных в рамках каждого сеанса, оставалось по умолчанию (10 запросов на одно соединение), а поскольку клиенты функционировали на той же машине, что и сервер, затраты времени на установление соединений не учитывались.
Основной нагрузочный сценарий Pgbench подражает набору тестов TPC‑B, разработанному Советом по производительности обработки данных ещё в 90‑х годах, и состоит из различных запросов на выборку и изменение данных. Очевидно, что узким местом в данном случае становится дисковая подсистема, что для нас не показательно. Поэтому мы также провели тесты только на чтение (SELECT-only), — как уже говорилось, вся база данных при этом целиком умещается в оперативной памяти; к тому же, именно этот сценарий использовался авторами патчей для Power8 и их предшественниками из стана x86‑64 при демонстрации своих улучшений.
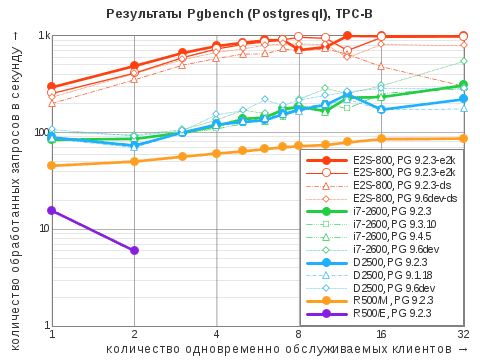
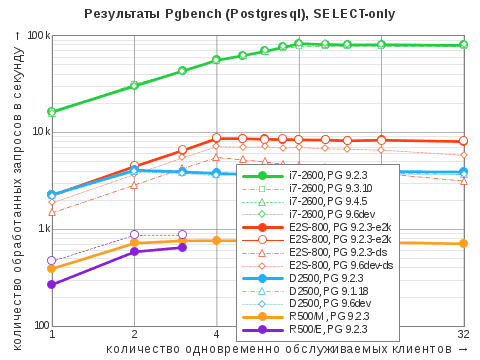
| Сценарий | i7‑2600 | D2500 | E2S-800 | R500/E | R500/M |
|---|---|---|---|---|---|
| TPC-B | 307 / 542 | 248 / 285 | 991 / 991 | 16 / 16 | 87 / 87 |
| SELECT | 82'304 / 83'280 | 4076 / 4076 | 8732 / 8732 | 650 / 650 | 766 / 766 |
Таблица результатов содержит максимально достигнутые показатели, выраженные в количестве обработанных запросов в секунду: через дробь указаны значения, полученные с помощью версии 9.2.3 и во всех протестированных версиях вообще. Этот максимум обычно соответствует количеству параллельно обслуживаемых клиентов, равному числу ядер процессора, когда дело ограничивается только чтением данных; когда также производится запись данных на диск, то максимум достигается при большем параллелизме, видимо, за счёт переупорядочения команд диском (или системным кэшем, если тест такое позволяет).
Соотношение результатов первых трёх участников — вполне ожидаемое: «Эльбрус 401‑PC» опередил всех в смешанном режиме благодаря своему шустрому SSD, и это лишний раз напомнило о том, что центральный процессор не является единственно важным для отзывчивости компьютера. Картина при выборке данных совсем иная, но и тут нельзя не заметить, что процессор «Эльбрус‑4С» выступает на равных с Atom D2500 даже при количестве потоков в рамках числа ядер последнего, — несмотря на более чем двойное преимущество оного по частоте; видимо, играет свою роль разница в объёме кэш-памяти второго уровня (8 Мбайт против 1 Мбайт). Не вчера придуманная формула успеха «Много памяти и быстрый накопитель» не теряет своей актуальности!
Отдельного пояснения требуют обрывочные результаты компьютера на базе R500 с операционной системой «Эльбрус». То ли по причине нехватки оперативной памяти, то ли в силу иных обстоятельств, утилита Pgbench просто переставала подавать признаки жизни после прогона в 2-поточном режиме на запись или 3-поточном на чтение. Причём ситуация не исправлялась даже при понижении объёма тестовой базы (за счёт уменьшения параметра scaling factor; результат обозначен пунктиром на диаграмме) и, соответственно, появлении достаточного количества свободной памяти. Что характерно, однако, стек вызовов «уснувшей» программы выглядел следующим образом:
#0 0x00.... in __lll_lock_wait_private () from /lib/libc.so.6
#1 0x00.... in __lll_lock () from /lib/libc.so.6
#2 0x00.... in free () from /lib/libc.so.6
#3 0x00.... in doCustom ()
#4 0x00.... in main ()
Что до плачевных показателей в тестах этого компьютера на запись, то ожидать от флэш-карты высокой производительности было бы наивно.
Комментируя результаты в целом, можно отметить, что такой революционной разницы в производительности между протестированными версиями Postgresql, какая была показана в упомянутой ранее статье, в нашем эксперименте заметить не удалось: не считая самостоятельно собранной в неоптимальном виде версии для E2K, расхождения были в рамках погрешности измерения, — в том числе при смешанной нагрузке, когда скорость работы жёсткого диска была статистически плохо предсказуемой при выбранной длительности проведения теста.
Также в планах было протестировать родную для МСВС, хотя и не входящую в штатный набор программного обеспечения, СУБД «Линтер ВС» (не путать с «Линтер»), версия 707.3.4 которой основана на Postgresql 8.4.3 с оригинальными расширениями для поддержки мандатного управления доступом. Однако опциональная утилита Pgbench в комплект поставки этого продукта не входит, а самостоятельно собранный вариант из публичных исходных кодов оказался несовместимым с используемой моделью прав и привилегий.
Сборка Postgresql оказалась неплохим бенчмарком сама по себе: это не слишком мелкий проект, чтобы настройка и компиляция промелькнули на экране в мгновение ока, и в то же время не слишком большой, чтобы процесс растянулся надолго или завершился с ошибкой из‑за отсутствующих зависимостей либо платформенной несовместимости. Единственный недостаток с точки зрения всестороннего тестирования состоит в том, что Postgresql написан целиком на языке Си — нет ни одного модуля на C++.
Измерению подвергалось полное время компиляции версии 9.2.3 в многопоточном режиме с различными уровнями оптимизации: приведённые в таблице результаты выражены в часах, минутах и секундах по астрономическому времени, а также в скобках указаны суммарные затраты процессорного времени пользователя во всех потоках (системные затраты сравнительно малы и связаны, скорее всего, с файловым вводом-выводом, который нам не очень интересен в данном контексте). Время на конфигурирование сборки не учитывалось: хотя оно может быть существенным и даже сопоставимым с длительностью компиляции, всё же конфигурирование обычно выполняется однократно на том или ином этапе работы над проектом, тогда как компилятор вызывается часто при внесении правок. Кроме того, следует иметь в виду, что при сборке стабильной версии с настройками по умолчанию не выполняется компилирование опциональных утилит, таких как Pgbench, — в отличие от сборки текущей версии из репозитория.
| Режим | i7‑2600 | D2500 | E2S-800 | R500/E | R500/M |
|---|---|---|---|---|---|
| -O0 | 0:00:17 (0:01:15) | 0:03:00 (0:05:08) | 0:02:00 (0:06:17) | 0:25:51 (0:42:09) | 0:14:18 (0:23:53) |
| -O1 | 0:00:24 (0:02:12) | 0:04:31 (0:07:56) | 0:05:25 (0:15:18) | 1:33:35 (2:02:02) | 0:19:14 (0:33:10) |
| -O2 | 0:00:32 (0:03:01) | 0:06:02 (0:10:47) | 0:13:12 (0:34:50) | 1:38:30 (2:46:51) | 0:27:31 (0:46:57) |
| -O3 | 0:00:38 (0:03:37) | 0:07:02 (0:12:41) | 0:33:04 (1:22:04) | 2:17:38 (4:05:42) | 0:30:20 (0:51:40) |
Данные результаты демонстрируют только то, как быстро будет выполнена компиляция конкретной версии конкретного проекта с настройками по умолчанию — конкретной версией штатного компилятора на той или иной платформе. Представители архитектуры x86‑64 использовали компилятор GCC 4.8.3 и 4.7.2 соответственно, компьютер под управлением МСВС использовал GCC 3.3.6 для архитектуры SPARC, а участники с операционной системой «Эльбрус» имели в распоряжении LCC 1.16.12 и 1.19.18 соответственно, причём оптимизирующий компилятор LCC для архитектуры SPARC и для архитектуры E2K — это два совершенно разных компилятора, которые проделывают разный объём работы и выдают разный по эффективности код. Поэтому прямое сравнение тут невозможно, и никаких выводов о быстродействии аппаратуры на основании результатов данного теста делать нельзя. Другое дело, что хорошо было бы исследовать эффективность оптимизаций, но для этого нужна недюжинная квалификация, — чтобы не получилось, что мы измеряем скорость инкремента и делаем на основании этого космического масштаба выводы.
Имея весьма смутное представление о Java, автор решил просто пробовать все результаты гуглинга по порядку, и первым делом остановил взгляд на этом проекте, который оказался довольно компактным и простым в запуске. В нём реализованы базовые оценки быстродействия процессора и жёсткого диска, которые также комбинируются в сценариях «Desktop» и «Server»: первый создаёт нагрузку в большей степени последовательно, а второй старается взяться за много задач одновременно.
| Сценарий | i7‑2600 | D2500 | E2S-800 |
|---|---|---|---|
| CPU, млн. | 3927 | 196 | 356 |
| Disk | 2546 | 164 | 126 |
| Desktop | 3238 | 181 | 241 |
| Server | 7568 | 378 | 405 |
Если не обращать внимание на оценку дисковой производительности, результаты кажутся правдоподобными, — приблизительное соотношение 10:1 между Core i7 и «Эльбрус‑4С», наблюдаемое в других тестах (с нативными приложениями), здесь также просматривается, а большее различие в сценарии «Server» можно было бы объяснить особенностями нагрузки или объективными свойствами испытуемых платформ. Однако такое же соотношение скорости файловых операций, — при том, что компьютер «Эльбрус 401‑PC» оснащён быстрым SSD, а в остальных компьютерах установлены обычные диски начального уровня, — заставляет усомниться в адекватности самого теста или формулы вычисления рейтинга. И действительно, заглянув в подробный журнал сценария «Disk», можно видеть, что скорость чтения жёсткого диска Seagate Barracuda 7200.9 якобы составляет 325 Мбайт/с в каждом из двух потоков на Atom D2500, а скорость чтения WD Caviar Blue — вообще, страшно сказать, — 1650 Мбайт/с в каждом из восьми потоков на Core i7. Такие показатели превышают скорость интерфейса SATA‑2, по которому подключены диски, а потому не могут отражать даже скорость обращения к буферу диска, — ну разве что к системному кэшу.
Дальнейшие тесты покажут, что и оценка производительности процессора в Java Micro Benchmark, видимо, реализована некорректно. Этот случай в очередной раз напоминает нам, что писать правильные бенчмарки не так‑то просто, и слепо верить первому встречному, не сверяясь с другими источниками, будет ошибкой.
Корпорация стандартизованной оценки производительности (SPEC), — разработчик ставших эталонными тестов SPEC CPU и многих других, — в представлении, пожалуй, не нуждается, и профессионализм её программистов сомнению не подлежит. Обычно их продукты стоят больших денег, но для SPECjvm98 и SPECjvm2008 они сделали исключение и распространяют совершенно бесплатно, — грех было не воспользоваться.
| Тест | i7‑2600 | D2500 | E2S-800 |
|---|---|---|---|
| compiler | 533,11 | 34,24 | 4,54 |
| compress | 292,94 | 21,48 | 2,74 |
| crypto | 269,87 | 19,14 | 3,10 |
| derby | 427,77 | 24,85 | 5,00 |
| mpegaudio | 184,79 | 12,48 | 2,29 |
| scimark.large | 45,88 | 5,46 | 1,13 |
| scimark.small | 414,42 | 20,43 | 4,02 |
| serial | 207,05 | 13,86 | 1,45 |
| startup | 32,31 | 5,19 | 0,69 |
| sunflow | 110,51 | 6,85 | 0,89 |
| xml | 621,66 | 36,76 | 5,25 |
| итого | 206,50 | 15,03 | 2,30 |
Теперь соотношение между Core i7 и «Эльбрус‑4С» — порядка 100:1, причём во всех тестах единогласно, без исключения. Да что уж, 4‑ядерный «Эльбрус» здесь безнадёжно отстал даже от 2‑ядерного Atom! Учитывая предыдущий неудачный опыт Java-бенчмаркинга, в этот результат было сложно поверить: вроде нагрузка идёт только на процессор и память, а картина столь разительно отличается от нативных программ.
Гипотеза о том, что Core i7 получает преимущество за счёт использования более новой версии Java — 1.7.0, тогда как «Эльбрус» имеет в своём распоряжении только 1.6.0, — была опровергнута тестированием той же версии 1.6.0 на Atom; правда, JVM в последнем случае была версии 23.25 против 20.0 (автор не в курсе, насколько это существенно). Также было проверено предположение, что слишком большой объём выделенной памяти для Java — так же плохо, как и слишком малый: в точном соответствии с документацией, было выделено по 512 Мбайт на ядро, но результат лишь осциллировал в рамках погрешности по сравнению с тем, когда выделялось вдвое больше, и когда вчетверо.
