Обзор алгоритмов аудиоаналитики
 Разработки Синезис не ограничиваются одной лишь видеоаналитикой. Мы занимаемся и аудиоаналитикой. Вот о ней-то мы и хотели сегодня вам рассказать. Из этой статьи вы узнаете о наиболее известных аудиоаналитических системах, а также алгоритмах и их специфике. В конце материала — традиционно — список источников и полезных ссылок, в том числе аудиобиблиотек.Осторожно: статья может долго грузиться — много картинок.Автор: Михаил Антоненко.В то время как видеоанализ стал стандартной функцией многих охранных видеокамер, встроенная аудиоаналитика продолжает оставаться довольно редким явлением, несмотря на наличие как самого аудиоканала в устройствах, так и доступных вычислительных мощностей для обработки аудиоданных [1]. Тем не менее, аудиоаналитика обладает некоторыми преимуществами по сравнению с видеоаналитикой: стоимость микрофонов и их обслуживание значительно дешевле, чем видеокамер; при работе системы в режиме реального времени поток данных аудиоинформации значительно меньше по объему, чем поток данных с видеокамер, что предъявляет более лояльные требования к пропускной способности канала передачи данных. Системы аудиоаналитики могут быть особенно востребованы для городского наблюдения, где можно автоматически начать транслировать живое видео на полицейский пульт с места взрыва и стрельбы. Технологии аудиоаналитики также могут использоваться при изучении видеозаписи и определении событий. С ростом осведомленности о возможностях данных систем применение аудиоаналитики будет только расширяться. Давайте же начнем с основ:
Разработки Синезис не ограничиваются одной лишь видеоаналитикой. Мы занимаемся и аудиоаналитикой. Вот о ней-то мы и хотели сегодня вам рассказать. Из этой статьи вы узнаете о наиболее известных аудиоаналитических системах, а также алгоритмах и их специфике. В конце материала — традиционно — список источников и полезных ссылок, в том числе аудиобиблиотек.Осторожно: статья может долго грузиться — много картинок.Автор: Михаил Антоненко.В то время как видеоанализ стал стандартной функцией многих охранных видеокамер, встроенная аудиоаналитика продолжает оставаться довольно редким явлением, несмотря на наличие как самого аудиоканала в устройствах, так и доступных вычислительных мощностей для обработки аудиоданных [1]. Тем не менее, аудиоаналитика обладает некоторыми преимуществами по сравнению с видеоаналитикой: стоимость микрофонов и их обслуживание значительно дешевле, чем видеокамер; при работе системы в режиме реального времени поток данных аудиоинформации значительно меньше по объему, чем поток данных с видеокамер, что предъявляет более лояльные требования к пропускной способности канала передачи данных. Системы аудиоаналитики могут быть особенно востребованы для городского наблюдения, где можно автоматически начать транслировать живое видео на полицейский пульт с места взрыва и стрельбы. Технологии аудиоаналитики также могут использоваться при изучении видеозаписи и определении событий. С ростом осведомленности о возможностях данных систем применение аудиоаналитики будет только расширяться. Давайте же начнем с основ:
Существующие решения в области аудиоаналитикиПожалуй, самой известной системой является ShotSpotter [2], лидер в США при детектировании выстрелов из огнестрельного оружия в городских условиях. В наиболее опасных районах установлены направленные микрофоны (на столбах, домах, других высокий сооружениях), улавливающие звуки городского фона. В случае положительной идентификации выстрела, информация с GPS-координатами конкретного микрофона передается на центральный компьютер, где проводится дополнительный анализ звука, чтобы отсеять возможные ложные срабатывания, вроде пролетающего вертолета или, например, взорвавшейся петарды. Если выстрел подтверждается, патруль выезжает на место. Система, установленная в Вашингтоне еще в 2006 году, за прошедшие годы локализовала 39000 выстрелов из огнестрельного оружия, и полиция смогла быстро отреагировать в каждом конкретном случае. [3]
Среди поставщиков услуг аудиоаналитики в РФ можно выделить «SistemaSarov» [4]. Система акустического мониторинга позволяет в автоматическом режиме выделять в звуковом потоке акустические артефакты, выполнять их предварительную классификацию (по типу тревожного события), а в случае оснащения терминального устройства приемником GPS/ГЛОНАСС сигнала, определять координаты произошедшего события и сохранять события в архив. [5]
Проект «AudioAnalytics» [6], базирующийся в Великобритании, предоставляет сразу несколько решений для различных вариантов использования. Архитектура предлагаемых решений имеет следующий вид: программа CoreLogger, работающая на устройстве конечного пользователя, позволяет принимать и отображать/сохранять тревожные события. Работает в связке с другой частью общей системы — Sound Packs — которая представляет не что иное как набор различных модулей аудиоаналитики. Основные возможности данных модулей представляют собой детектирование следующих аудиособытий:
агрессия (разговор на повышенных тонах, крик);
сигнализация автомобилей;
разбивающееся стекло;
поиск ключевых слов («милиция», «помогите» и т. д.);
выстрелы;
крик/плач ребенка.
Дополнительно предоставляется часть системы под названием Core Trainer, которая на основании поданного ей на вход набора аудиосигналов, выделит наиболее отличающиеся (выделяющиеся) части и сформирует новый паттерн для SoundPacks.Методы и подходы к детектированию и распознаванию аудиособытий различных типов (выстрел, разбитое стекло, крик)
В качестве примера исходных данных представлены спектрограммы трех различных типов аудиособытий:1. Набор выстрелов. 2. Разбитое стекло
2. Разбитое стекло
3.Крик
Соответствующие аудиозаписи скачаны из базы аудиоданных [7]. Среди других источников исходных аудиоданных можно отметить базы данных [8] [9] [10] [11].Задача распознавания различных тревожных аудиособытий подразделяется на 2 подзадачи [12]:
детектирование (выделение) резких импульсных сигналов из фонового шума в потоке аудио данных;
классификация (распознавание) детектированного сигнала к одному из типов аудио событий.
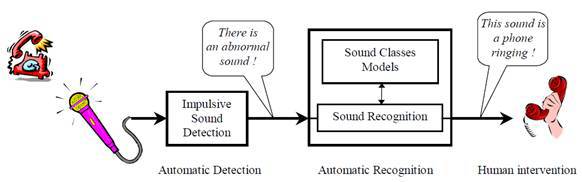 Детектирование импульсных выделяющихся аудиособытий
Большинство методов основаны на определении мощности для набора последовательных неперекрывающихся блоков аудио сигнала [13]. Мощность для k-го блока сигнала, состоящего из для N отсчетов, определяется как
Детектирование импульсных выделяющихся аудиособытий
Большинство методов основаны на определении мощности для набора последовательных неперекрывающихся блоков аудио сигнала [13]. Мощность для k-го блока сигнала, состоящего из для N отсчетов, определяется как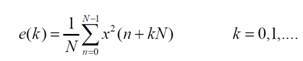
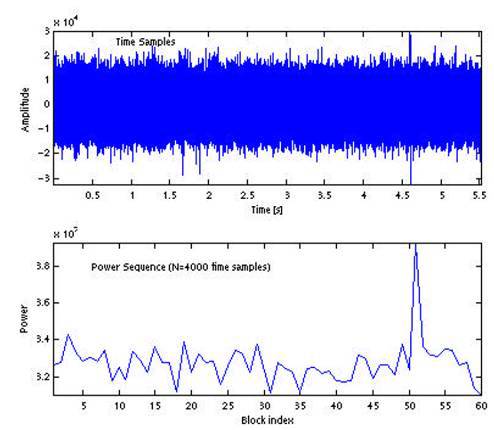
В качестве примера приведен аудиосигнал с выстрелом, произошедшем на отметке 4.6 с, а также набор значений мощностей для блоков из N=4000 отсчетов, что соответствует продолжительности каждого блока около 90 мс.Различные методы отличаются способом автоматического детектирования блока, соответствующего резкому импульсному звуку: на основе стандартного отклонения нормированных значений мощностей блоков; на основе применения медианного фильтра для значений мощностей блоков; по динамическому порогу для значений мощностей блоков.Давайте рассмотрим их чуть подробнее:
Метод на основе стандартного отклонения нормированных значений мощностей блоков
Ключевым аспектом данного метода является нормировка рассматриваемого набора значений блоков мощности к диапазону [0, 1]:
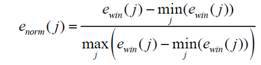
Далее вычисляется стандартное отклонение (дисперсия) полученного набора значений:

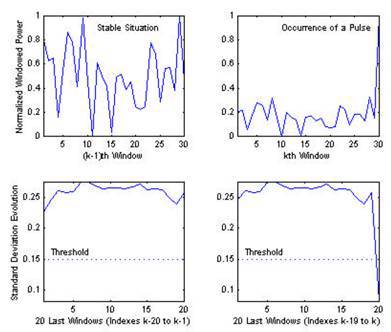
В случае фонового шума, значения блоков мощности будут примерно равномерно распределены в диапазоне [0–1] (видно на рисунке слева). Так как при поступлении нового значения мощности для блока аудиосигнала, происходит перенормировка значений к указанному диапазону, то при наступлении блока со значительно более высоким уровнем мощности, значение стандартного отклонения существенно уменьшится по сравнению с аналогичным значением для набора предыдущих фоновых блоков мощности. По снижению стандартного отклонения ниже порогового значения, можно автоматически детектировать блок с импульсным сигналом.
Преимуществом данного метода является его устойчивость к изменению уровня шума, а также возможность детектирования медленно меняющегося сигнала, анализируя среднее значение нормированных блоков мощности.
Метод на основе использования медианного фильтра
Основные этапы автоматического детектирования импульсных выделяющихся сигналов с использованием медианного фильтра представлены ниже. Пример применения медианного фильтра порядка k к набору значений блоков мощностей представлен на рисунке ниже
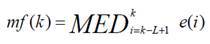
Для детектирования блока с импульсным событием применяется условный медианный фильтр (conditional median filtering), который оставляет исходное значение сигнала в случае, если разница между исходным отсчетом и медианным значением меньше порогового значения, и медианное значение в противном случае.
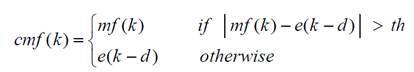
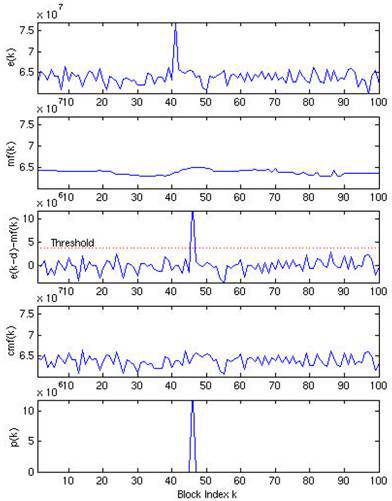
Вычислив разницу между сигналом после применения conditional median filter и смещенным исходным сигналом, можно автоматически выделить блок с произошедшим импульсным событием.
Метод на основе динамического порога для значений мощностей блоков
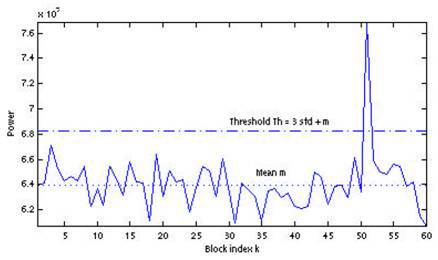
В этом методе предлагается детектировать импульсный сигнал используя среднее значение набора мощностей блоков и среднеквадратичное отклонение в качестве динамического порога. Автоматическое детектирование происходит при превышении мощности очередного блока порогового значения, определяемого как
th=par*std+m
Где par — параметр, определяющий чувствительность алгоритма. Пример применения данного метода при значении параметра par=3 представлен на следующем рисунке:
Распознавание аудиособытий
Общая схема распознавания аудиособытий включает следующие этапы: 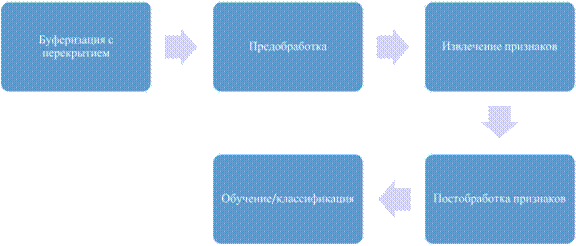
Буферизация с перекрытием
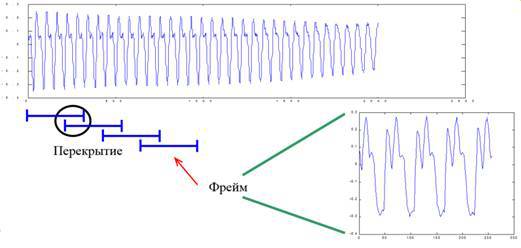
На первом этапе происходит преобразование исходного аудио сигнала в набор фреймов с перекрытием:
Стадия предобработки
Стадия предобработки включает в себя, как правило, pre-emphasis фильтрацию и оконное взвешивание. Pre-emphasis обработка осуществляется за счет применения КИХ-фильтра H (z)=1− a / Z. Это необходимо для спектрального сглаживания сигнала [14]. В таком случае сигнал становится менее восприимчивым к различным шумам, возникающим в процессе обработки.
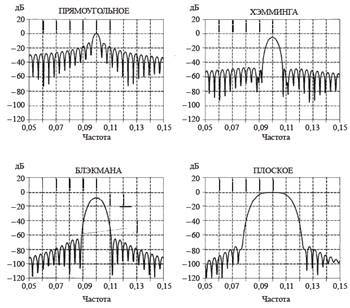
Оконное взвешивание необходимо применять в связи с тем, что аудиофрейм ограничен во времени, поэтому при переходе в частотную область будет происходить эффект просачивания спектра боковых лепестков, связанное с формой спектра функции прямоугольного окна (он имеет вид sin (x) / x). Поэтому, чтобы уменьшить влияние этого эффекта, применяется взвешивание исходного сигнала различного вида окнами, с формой, отличной от прямоугольной. Отсчеты входной последовательности умножаются на соответствующую функцию окна, что влечет за собой обнуление значений сигнала на краях выборки. В качестве взвешенных функций чаще всего выступают окна Хэмминга, Блэкмэна, плоское, Кайзеля-Бесселя, Дольфа-Чебышева [15]. Спектральные характеристики некоторых приведены ниже:
Извлечение признаков
Существует несколько подходов к извлечению дескрипторов (признаков) из аудиосигнала. Все они задаются общей целью уменьшить избыточность сигнала и выделить наиболее релевантную информацию, и, в то же время, отбросить нерелевантную. Как правило, признаки, описывающие аудиосигнал с разных точек зрения, комбинируются в один вектор признаков, на основе которого происходит процесс обучения и затем классификации с использованием выбранной обученной модели. Далее будут представлены наиболее популярные признаки, выделяемые из аудиосигнала.1. Статистика во временной области (Time-domain statistics)
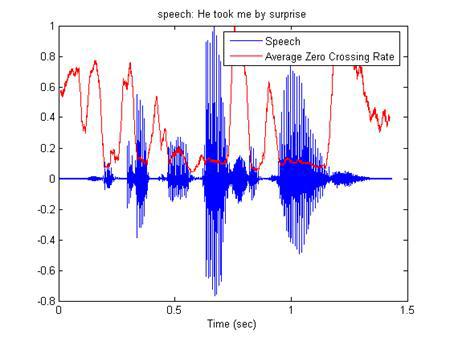
ZCR (Zero crossing rate) — количество пересечений оси времени аудио сигналом [16].
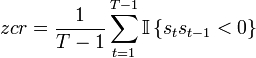
 Short-time energy [17]– среднее значение энергии для аудио фрейма
Short-time energy [17]– среднее значение энергии для аудио фрейма
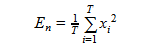 Entropy of energy [18]
Разделив каждый фрейм на набор под-фреймов, вычисляется набор энергий для каждого подфрейма. Далее, нормируя энергию каждого из подфреймов на энергию всего фрейма, можно рассматривать набор энергий как набор вероятностей и вычислить информационную энтропию по формуле:
Entropy of energy [18]
Разделив каждый фрейм на набор под-фреймов, вычисляется набор энергий для каждого подфрейма. Далее, нормируя энергию каждого из подфреймов на энергию всего фрейма, можно рассматривать набор энергий как набор вероятностей и вычислить информационную энтропию по формуле: 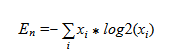
2. Статистика в частотной области (Frequency-domain statistic)
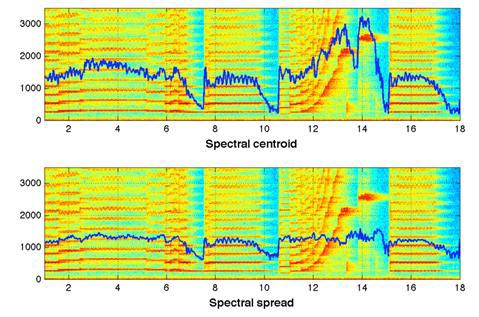
Spectral centroid [17]Представляет собой интерпретацию «центра масс» спектра. Вычисляется как сумма частот, взвешенных соответствующими амплитудами спектра, деленная на сумму амплитуд:

Где F[k] — амплитуда спектра, соответствующая k-му значению частоты в спектре ДПФ.
Затем полученное значение удобно отнормировать на максимальное значение частоты (Fs/2), в результате диапазон возможных «центр масс» спектра будет лежать в диапазоне [0–1].
Spectrum spread [17] (также называемый мгновенной шириной спектра/полосой пропускания).
Определяется как второй центральный момент: 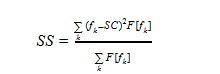
Где fk — значения частот в DFT, F[fk] — значения амплитуд, SC — значение Spectral centroid
Audio Spectrum Flatness (ASF) [19]
Отражает отклонение мощности спектра сигнала от пологой формы. С точки зрения человеческого восприятия, характеризует степень тональности звукового сигнала.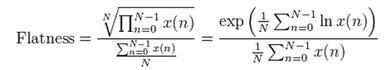
Energy-band spectrum [20]
Пространство частот разделяется на N полос, после чего вычисляется энергия спектра в каждой полосе. Полученные значения берутся в качестве признаков. По сути признаки в таком случае представляют собой значение энергии спектра в «низком разрешении».Cepstral coefficients
Получаются на основе предыдущих признаков путем перевода их в кепстральное пространство. Кепстр представляет собой не что иное как «спектр логарифма спектра», вместо преобразования Фурье применяют дискретное косинусное преобразование (DCT): 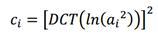
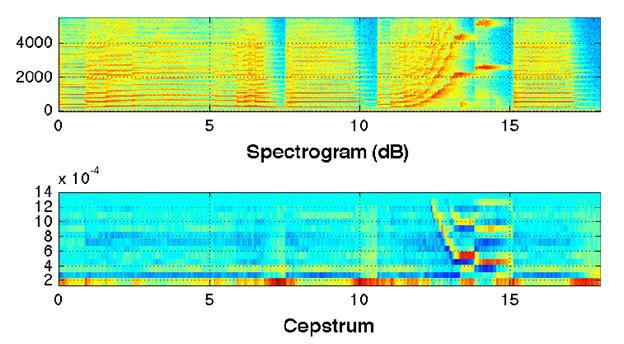
Spectral Entropy Энтропия спектра для заданного фрейма вычисляется аналогичным образом с энтропией энергии во временной области: частотная область спектра разделяется на N частотных подобластей, для каждой из которых рассчитывается часть всей энергии спектра, приходящаяся на данную подобласть, а затем вычисляется информационная энтропия по аналогии с временной областью.Spectral flux [21] Поток спектра — отражает, насколько быстро изменяется энергия спектра, вычисляется на основе спектра на текущем и предыдущем фреймах. Определяется как вторая норма (Евклидово расстояние) между двумя нормализованными спектрами: windowFFT = windowFFT / sum (windowFFT); F = sum ((windowFFT — windowFFTPrev).^2);
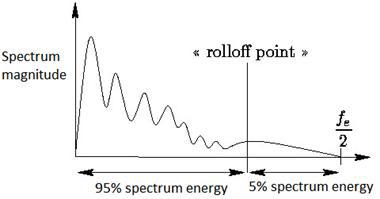
Spectral rolloff («завал» энергии) [22] Определяется как относительная частота, в пределах которой которой сосредоточена определенная часть всей энергии спектра (задается в качестве параметра с): countFFT → c*totalEnergySR = countFFT/lengthFFT
Схематично представлено значение Spectral rolloff при с=0.95:
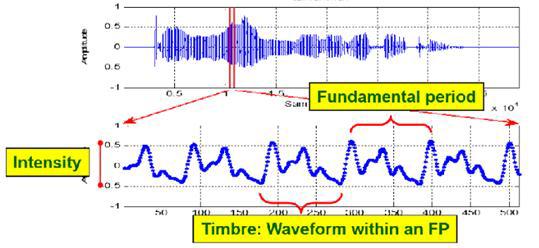
Признаки, отражающие гармоничность аудиосигнала (harmonic ration, fundamental frequency) :
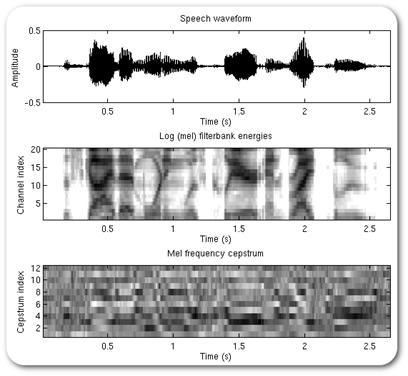
 3. MFCC — Mel-frequency cepstral coefficients. (Хабраисточник [23])Общая схема получения мел-частотных кепстральных коэффициентов представлена на следующей схеме [24].
3. MFCC — Mel-frequency cepstral coefficients. (Хабраисточник [23])Общая схема получения мел-частотных кепстральных коэффициентов представлена на следующей схеме [24].
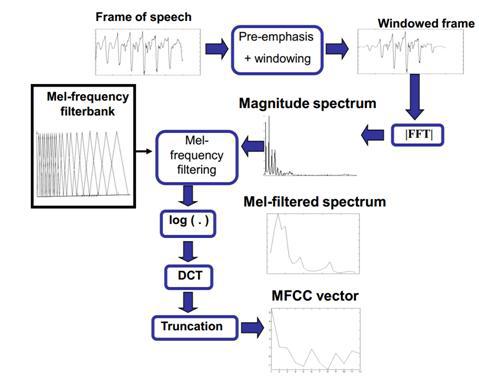
Как было указано ранее, аудиосигнал разделяется на фреймы, производится pre-emphasis фильтрация и оконное взвешивание, выполняется быстрое преобразование Фурье, далее спектр пропускается через набор треугольных фильтров, расположенных равномерно на мел-шкале. Это приводит к большей плотности фильтров в области низких частот и меньшей плотности в области высоких частот, что отражает чувствительность восприятия звуковых сигналов человеческим ухом. Таким образом, основная информация «снимается» из аудио сигнала в области низких частот, что является наиболее релевантным признаком звуковых сигналов (в особенности, речевых). Далее отсчеты переводятся в кепстральное пространство с помощью дискретного косинусного преобразования (DCT).
Математическое описание:
Применяем к сигналу преобразование Фурье
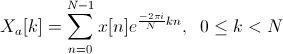
Составляем гребенку фильтров, используя оконную функцию
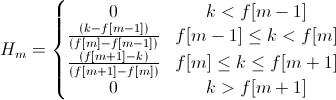
Для которой частоты f[m] получаем из равенства
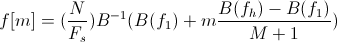
B (b) — преобразование значения частоты в мел-шкалу, соответственно,
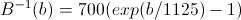
Вычисляем энергию для каждого окна
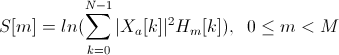
Применяем ДКП
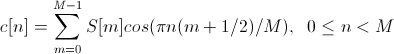
4. LPC (Linear prediction coefficients)
В качестве признаков выступают коэффициенты, предсказывающие сигнал на основе линейной комбинации предыдущих отсчетов. [25] По сути являются коэффициентами КИХ-фильтра соответствующего порядка:
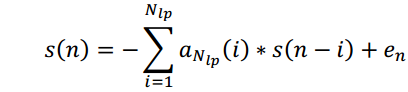
Используются также при кодировании речи (Linear Prediction Coding), так как показано, что хорошо аппроксимируют характеристики речевых сигналов.
В различных статьях исследуется влияние тех или иных компонент вектора признаков на качество распознавания аудиособытий.
Постобработка признаков
После извлечения необходимых признаков сигнала для их дальнейшего использования производится нормализация признаков так, чтобы каждый компонент вектора признаков имел среднее значение 0 и стандартное отклонение 1: 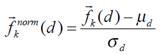
Часто применяется технику mid-term analysis [26], когда производится усреднение признаков по набору последовательных фреймов. Как правило, в качестве интервала для усреднения выбирается 1–10 секунд.

Как правило, размерность вектора признаков получается довольно большой, что существенно влияет в дальнейшем на производительность процесса обучения. Вот почему в этом случае применяются хорошо известные и теоретически изученные методы сокращения размерности вектора признаков (LDA, PCA и др.) [27].
Одним из преимуществ использования методов сокращения размерности является способность существенно увеличить скорость процесса обучения за счет уменьшения количества признаков. Более того, выбрав признаки, обладающие наилучшими дискриминационными способностями в отдельный набор, возможно убрать лишнюю нерелевантную информацию, что повысит точность работы алгоритмов машинного обучения (таких как SVM и др.) [28]
Данные методы были затронуты в материале про распознавание лиц. Различие PCA и LDA методов заключается в том, что метод PCA позволяет сократить размерность вектора признаков за счет выделения независимых компонент, максимальным образом покрывающий разброс по всем событиям.
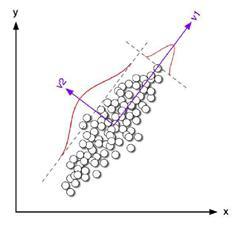
В то время как LDA выделяет компоненты, показывающие наилучшие дискриминационные способности среди набора классов.
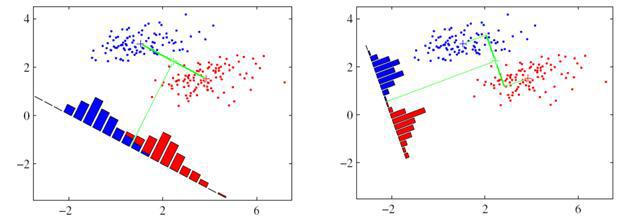
Как в PCA, так и в LDA, на этапе обучения рассчитывается матрица W, определяющая линейное преобразование исходного вектора признаков в новое пространство сокращенной размерности Y = WTX
Выбор классификатора Наконец, последним этапом является выбор классификатора (обучающей модели). Некоторые исследования в области аудионалитики при детектировании интересующих аудиосигналов посвящены сравнению точности распознавания при использовании различных моделей классификаторов при различных типах аудиособытий. Отмечается, что использование иерархических классификаторов существенно увеличивает точность распознавания в сравнении с использованием мультиклассовых классификаторов. [29] [19]Наиболее простым вариантом модели распознавания является Байесовский классификатор, который основан на вычислении функции правдоподобия для каждого из классов, и на этапе распознавания событие относится к тому классу, апостериорная вероятность которого максимальна среди всех классов. На следующем рисунке показан пример классификации для вектора признаков размерности 2. Эллипсы отцентрированы относительно средних значений, соответствующих каждому из классов, красные границы представляют собой набор значений признаков, где классы эквивалентны.
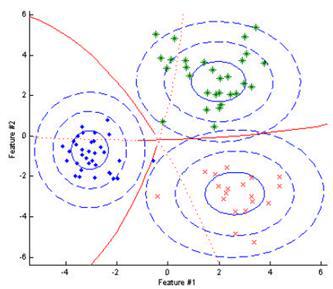
В случае выбора признаков, показывающих хорошие дискриминационные свойства, высокий результат распознавания может быть достигнут и с использованием байесовских классификаторов.
В отличие от классического Байесовского классификатора, где для аппроксимации каждого класса выступали параметры гауссовского распределения, в качестве функции плотности распределения вероятности в GMM (Gaussian Mixture Model) модели выступает «смесь» из нескольких гауссиан [19], параметры которых для каждого класса подбираются на этапе обучения с использованием EM (Expectation Maximization) алгоритма. Как видно из рисунка, представляющего результат классификации трех классов, область пространства, соответствующая каждому классу, представляет собой более сложную форму, чем эллипс, модель распознавания стала более точной, соответственно, улучшится результат распознавания.
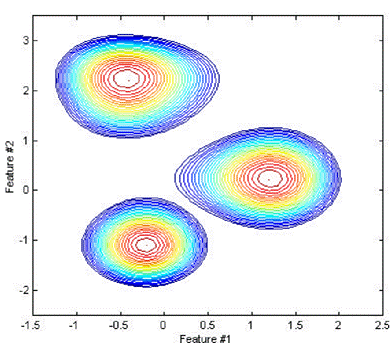
Среди недостатков данной модели можно отметить высокую чувствительность к вариациям в обучающей выборке данных при выборе большого числа гауссовских распределений, что может приводить к процессу переобучения.
В качестве еще одного способа классификации признаков, выделенных из аудиосигнала, является SVM (Support Vector Machine) классификатор [30], который переводит исходные вектора признаков в пространство с большей размерностью и находит максимально отстоящую от распознаваемых классов разделяющую гиперплоскость. В качестве ядра могут выступать не только линейная функция, но и полиномиальная, а также RBF (radial-basis function) [31].
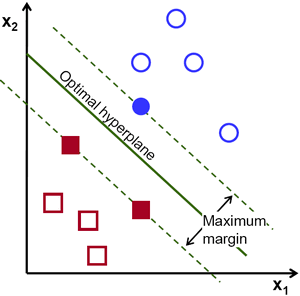
Преимуществом данного классификатора в том, что на этапе обучения метод находит полосу максимальной ширина, что на этапе распознавания позволит осуществить более точную классификацию Среди недостатков можно выделить чувствительность к стандартизации данных и шумам.
Применение HMM (Hidden Markov Model) [32] и нейронных сетей [27] в качестве классификатора было рассмотрено в нашем предыдущем обзоре алгоритмов распознавания лиц (Хабраисточник [33]).
Список литературы
[1] «http://www.secuteck.ru/articles2/videonabl/10-trendov-videonablyudeniya-2014po-versii-kompanii-ihs/,» [В Интернете].[2] «http://www.shotspotter.com/,» [В Интернете].[3] «http://habrahabr.ru/post/200850/,» [В Интернете].[4] «http://sarov-itc.ru/,» [В Интернете].[5] «http://sarov-itc.ru/docs/acoustic_monitoring_description.pdf,» [В Интернете].[6] «http://www.audioanalytic.com/,» [В Интернете].[7] «http://www.freesound.org/,» [В Интернете].[8] «http://sounds.bl.uk/,» [В Интернете].[9] «http://www.pdsounds.org/,» [В Интернете].[10] «http://macaulaylibrary.org/,» [В Интернете].[11] «http://www.audiomicro.com/,» [В Интернете].[12] A. Dufaux, «Automatic Sound Detection And Recognition For Noisy Environment.».[13] I.L. Freire, «Gunshot detection in noisy environments».[14] F. Capman, «Abnormal audio event detection».[15] Микулович, «Цифровая обработка сигналов,» [В Интернете].[16] L. Gerosa, «SCREAM AND GUNSHOT DETECTION IN NOISY ENVIRONMENTS».[17] C. Clavel, «EVENTS DETECTION FOR AN AUDIO-BASED SURVEILLANCE SYSTEM».[18] A. Pikrakis, «GUNSHOT DETECTION IN AUDIO STREAMS FROM MOVIES BY MEANS OF DYNAMIC PROGRAMMING AND BAYESIAN NETWORKS».[19] S. Ntalampiras, «ON ACOUSTIC SURVEILLANCE OF HAZARDOUS SITUATIONS».[20] M.F. McKinney, «AUTOMATIC SURVEILLANCE OF THE ACOUSTIC ACTIVITY IN OUR LIVING».[21] D. Conte, «An ensemble of rejecting classifiers for anomaly detection of audio events».[22] G. Valenzise, «Scream and Gunshot Detection and Localization for Audio-Surveillance Systems».[23] «http://habrahabr.ru/post/140828/,» [В Интернете].[24] I. Paraskevas, «Feature Extraction for Audio Classification of Gunshots Using the Hartley Transform».[25] W. Choi, «Selective Background Adaptation Based Abnormal Acoustic Event Recognition for Audio Surveillance».[26] T. Giannakopoulos, «Realtime depression estimation using mid-term audio features,» [В Интернете].[27] J. Portˆelo, «NON-SPEECH AUDIO EVENT DETECTION».[28] B. Uzkent, «NON-SPEECH ENVIRONMENTAL SOUND CLASSIFICATION USING SVMS WITH A NEW SET OF FEATURES».[29] P.K. Atrey, «AUDIO BASED EVENT DETECTION FOR MULTIMEDIA SURVEILLANCE».[30] A. Kumar, «AUDIO EVENT DETECTION FROM ACOUSTIC UNIT OCCURRENCE PATTERNS».[31] T. Ahmed, «IMPROVING EFFICIENCY AND RELIABILITY OF GUNSHOT DETECTION SYSTEMS».[32] M. Pleva, «Automatic detection of audio events indicating threats».[33] «http://habrahabr.ru/company/synesis/blog/238129/,» [В Интернете].
