Обучение модели токсификации текстов с помощью TorchTune, подробное руководство
Приветствую, хабровчане!
Сегодня пятница, поэтому предлагаю немного пошалить и поговорить о слегка необычном, но весьма забавном проекте обучения нейросетевой модели на базе LLaMA 2 7B, которая умеет превращать невинные предложения на русском языке в чуть более «токсичные» их версии.

Так по мнению DALL-E выглядит an artificial intelligence that transforms non-toxic elements into toxic substances
Но обучать модель мы будем не абы как, а при помощи недавно вышедшего в свет проекта под названием TorchTune, так как надо ведь пробовать новые инструменты, иными словами, предлагаю соединить тему интересную с темой полезной.
Так что пристегнитесь, будет весело и слегка токсично!
Мотивация
Недавно для одного хобби-проекта потребовалось реализовать вспомогательную модель детоксификации текста. Поэтому я отправился на arXiv в поисках публикаций по данной теме, и вот некоторые любопытные работы которые мне удалось найти:
На самом деле это далеко не всё — подобных публикаций мне довелось прочесть больше десятка и начитавшись вдоволь, я стал искать похожие решения, оптимизированные под русский язык, но из более-менее серьёзного смог найти лишь:
Иными словами, сделать нечто подобное и при этом оптимизированное под русский язык вполне реально. Но где взять подходящий русскоязычный датасет? При помощи гугления и общения с участниками сообщества «better data community» удалось найти два таких датасета:
russe_detox_2022 (в нём содержится примерно 6 тысяч образцов текста, разбитых на три сплита: dev, train и test)
textdetox/multilingual_paradetox (в сплите ru содержится 400 образцов)
Однако, этих примеров может быть недостаточно для создания комплексных моделей, способных выполнять детоксификацию. В таком случае придётся выполнять сбор данных из «токсичных» источников, после чего задействовать человека для творческой очистки… что, на мой скромный взгляд, будет слишком долго, да и людей жалко.
И тут мне пришла идея:, а что, если создать модель, которая будет принимать на вход нормальные предложения и возвращать токсичные их версии учитывая особенности Великого и Могучего? Это гипотетически позволит создавать датасеты для детоксификации любого объёма и сложности из любого источника на русском языке…
И кстати, забавный факт: мне не удалось найти русскоязычных моделей-токсификаторов. Странно, что столь любопытную тему обходят стороной. А тут ещё и разработчики проекта Torch 16 го апреля опубликовали TorchTune, поэтому я решил и новый инструмент попробовать и полезную нейросеть обучить.
Подготовка рабочего пространства
Для обучения модели нам понадобится станция с видеокартой от Nvidia на 16Гб+ VRAM, желательно, чтобы ОС была на базе ядра Linux, необходимо, чтобы драйверы видеокарты и драйверы CUDA были установлены и настроены, а ещё понадобится Python 3.11 и библиотека Python Virtual Environment. Подробно про это я рассказывал у себя в блоге в публикации под названием «Как подготовить Linux к запуску и обучению нейросетей? (+ Docker)», поэтому задерживаться не буду.
Создаём директорию, скажем toxicator-ru, далее зайдём в неё, после чего инициализируем и активируем виртуальное окружение:
mkdir toxicator-ru
cd toxicator-ru
python3 -m venv venv
source venv/bin/activateТеперь нам понадобится установить несколько пакетов:
pip install torch~=2.2.2 torchtune~=0.1.1 bitsandbytes~=0.43.1 numpy~=1.26.4 datasets~=2.19.0 wandb~=0.16.6 transformers~=4.40.1После чего мы можем переходить к шагу создания датасета.
Создание датасета токсификации
Теперь самое интересное, а именно подготовка данных для обучения. Чуть выше я уже упоминал датасет russe_detox_2022, он файлы из данного проектам использовались участниками соревнования «RUSSE 2022 Russian Text Detoxification Based on Parallel Corpora».
Данный проект содержит CSV-файлы dev.tsv и train.tsv .
Содержимое папки data/input проекта russe_detox_2022
Указанные файлы имеют следующий вид:
toxic_comment | neutral_comment1 | neutral_comment2 | neutral_comment3 |
токсичный комментарий | первая нейтральная версия | вторая нейтральная версия | третья нейтральная версия |
… | … | … | … |
Есть ещё файл test.tsv, но в нём лишь колонка toxic_comment.
Но для обучения модели не нужно иметь три нейтральных варианта, нужен лишь один, который наиболее похож на изначальный токсичный комментарий. Существует множество алгоритмов, которые позволяют оценивать похожесть текста, но мой наиболее любимый — это расстояние Левенштейна. Кстати, на Хабре была отличная публикация «Расстояние Левенштейна для чайников», рекомендую ознакомиться, если интересуют детали.
Так вот, для вычисления похожести двух образцов текста я набросал следующего вида функцию на языке Python:
def levenshtein_distance(s1, s2):
if len(s1) < len(s2):
return levenshtein_distance(s2, s1)
if len(s2) == 0:
return len(s1)
previous_row = range(len(s2) + 1)
for i, c1 in enumerate(s1):
current_row = [i + 1]
for j, c2 in enumerate(s2):
insertions = previous_row[j + 1] + 1
deletions = current_row[j] + 1
substitutions = previous_row[j] + (c1 != c2)
current_row.append(min(insertions, deletions, substitutions))
previous_row = current_row
return previous_row[-1]А вот так происходит её вызов:
def similarity_coefficient(text1, text2):
distance = levenshtein_distance(text1, text2)
max_length = max(len(text1), len(text2))
similarity = 1 - distance / max_length
return similarityВ результате работы функции similarity_coefficient мы получим на выходе float, обозначающий, насколько второй образец текста отличается от первого. После этого мы сможем отсортировать нейтральные образцы по их «дистанции» от токсичного и выбрать ближайшие:
def get_similar_field(sample):
distances = []
for comment in ['neutral_comment1', 'neutral_comment2', 'neutral_comment3']:
if isinstance(sample[comment], float):
continue
distance = levenshtein_distance(sample[comment], sample['toxic_comment'])
distances.append((distance, comment))
distances.sort(key=lambda x: x[0]) # Сортируем по дистации
return distances[0][1] # Выбираем образец с минимальной дистанциейДальше дело техники: скачиваем все упомянутые ранее CSV-файлы, выполняем анализ каждого из них, оформим образцы текста в формате датасетов типа Alpaca Instruct, указанный формат предполагает, что итоговом датасете будет как минимум три колонки:
instruction | input | output |
что надо сделать | что передаётся на входе | что ожидается на выходе |
… | … | … |
В колонке instruction для всех строк мы добавим фразу:
Перефразируй нетоксичный текст так, чтобы он стал токсичным, сохраняя при этом исходный смысл, орфографию и пунктуацию.
В input будут находиться нейтральные фразы, а в колонке output — «токсичные».
Далее преобразуем массивы словарей в объекты типа Dataset (что из пакета datasets), после чего соберём объект типа DatasetDict (тоже из пакета datasets) и опубликуем результат на HuggingFace.
Полный код юпитерианского блокнота вы сможете найти тут.
По итогу получился датасет на HuggingFace доступный по адресу evilfreelancer/toxicator-ru.
Генерация и настройка конфигурации TorchTune
Напоминаю, что мы всё ещё находится в контексте директории toxicator-ru.
Обучать я планирую модель LLaMA 2 7B HuggingFace, по нескольким причинам:
с ней мне уже привычно работать;
проект TorchTune из коробки её прекрасно поддерживает;
мне ещё на открыли доступ к репозиторию на HuggingFace с LLaMA 3;)
Для начала скачаем веса модели локально:
tune download meta-llama/Llama-2-7b-hf --output-dir ./Llama-2-7b-hfДалее скопируем конфигурационный файл для обучения модели в режиме full:
tune cp llama2/7B_full_low_memory ./toxicator.train.yamlПомимо режима обучения full доступны ещё lora и qlora, на больших и малых объёмах памяти, на множестве видеокарт и на одной, плюс можно обучать не только LLaMA 2, но и некоторые другие модели.
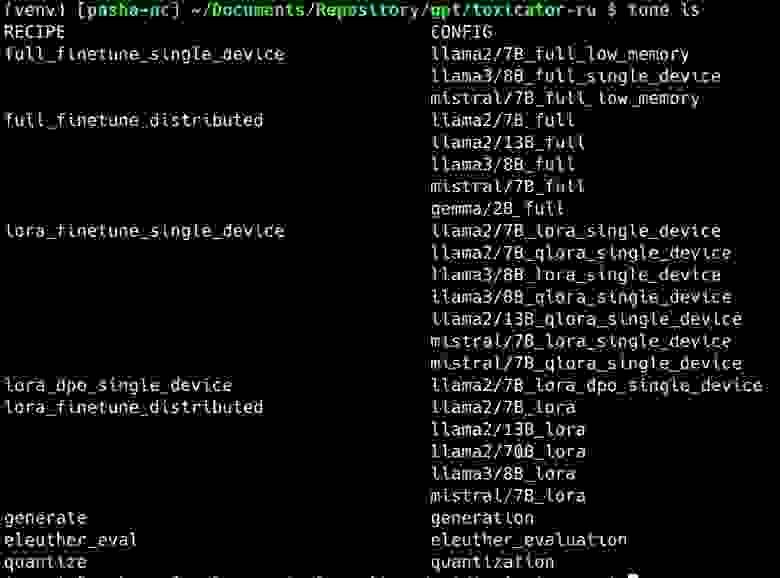
Все доступные на текущий момент рецепты и конфигурации моделей
Подправим YAML-конфигурацию, заменим в ней директорию /tmp на ./:
sed -r 's#/tmp/#./#g' -i ./toxicator.train.yamlДалее откроем в редакторе файл ./toxicator.train.yaml и заменим секцию dataset на следующего вида код:
# Dataset
dataset:
_component_: torchtune.datasets.instruct_dataset
source: evilfreelancer/toxicator-ru
template: AlpacaInstructTemplate
split: train
train_on_input: True
seed: null
shuffle: TrueТут видно, что мы указали, что хотим получить модель типа instruct, при этом обучать её мы будем на датасете evilfreelancer/toxicator-ru используя сплит train.
Далее заменим секцию metric_logger, по умолчанию в ней содержатся настройки логирования в папку, но мне удобнее использовать проект wandb.ai, должно получиться что-то вроде этого:
# Logging to the built-in WandBLogger
metric_logger:
_component_: torchtune.utils.metric_logging.WandBLogger
project: toxicator-ru
output_dir: ./llama2-finetune
log_every_n_steps: 1Ну и не забудем поднять batch_size до 10, а epoch до 3.
# Fine-tuning arguments
batch_size: 10
epochs: 3Полный пример конфигурационного файла тут.
Запуск процедуры обучения
На данном шаге у нас имеется готовый датасет, скачанная модель и подготовленная конфигурация для обучения.
Если предпочитаете использовать wandb для логирования, то не забудьте залогиниться:
wandb loginПосле чего запустим команду обучения модели:
tune run full_finetune_single_device --config toxicator.train.yamlДалее побегут сообщения отладки и запустится обучение.

Вывод консоли если всё хорошо
Полное обучение на датасете в почти 6 тысяч пар прошло на моей RTX 4090 примерно за 3 часа, что не такой уж и большой промежуток времени.
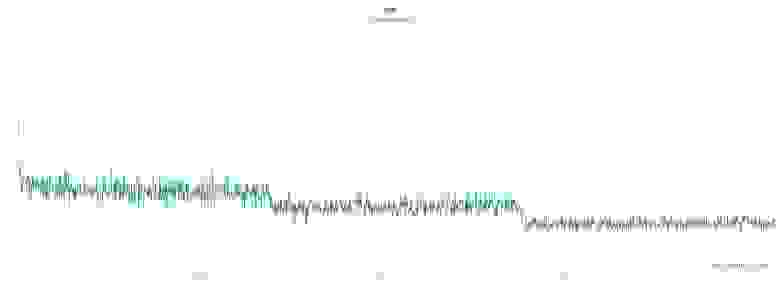
График loss функции
Вот тут можно посмотреть полный отчёт wandb.
В результате в директории ./Llama-2-7b-hf у нас появятся новые файлы, в частности это будут:
hf_model_0001_0.pt
hf_model_0001_1.pt
hf_model_0001_2.pt
hf_model_0002_0.pt
hf_model_0002_1.pt
hf_model_0002_2.pt
Где 0001 и 0002 это порядковый номер чекпоинта из оригинального репозитория LLaMA 2 7B, а числа от 0 до 2 в конце — номер эпохи обучения.
Генерация текста
Для того чтоб выполнять задачи инференса у указанной модели потребуется описать конфигурацию, скопируем заготовку из примера:
tune cp generation ./toxicator.gen.yamlДалее снова заменим /tmp на ./:
sed -r 's#/tmp/#./#g' -i ./toxicator.gen.yamlДалее в нём потребуется подкорректировать секцию checkpointer:
checkpointer:
_component_: torchtune.utils.FullModelHFCheckpointer
checkpoint_dir: ./Llama-2-7b-hf/
checkpoint_files: [
hf_model_0001_2.pt,
hf_model_0002_2.pt,
]
output_dir: ./Llama-2-7b-hf/
model_type: LLAMA2Для работы с моделью рекомендую использовать промт в формате Alpaca Instruct следующего вида:
### Instruction:
Перефразируй нетоксичный текст так, чтобы он стал токсичным, сохраняя при этом исходный смысл, орфографию и пунктуацию.
### Input:
Великолепный полёт мысли, сразу видно, что Вы очень талантливы.
### Response:
Пропишем его в конфигурации:
prompt: "### Instruction:\nПерефразируй нетоксичный текст так, чтобы он стал токсичным, сохраняя при этом исходный смысл, орфографию и пунктуацию.\n\n### Input:\nВеликолепный полёт мысли, сразу видно, что Вы очень талантливы.\n\n### Response:\n"Теперь попробуем запустить свежеобученную модель с предложенным выше промтом:
tune run generate --config ./toxicator.gen.yamlВ ответе будет что-то типа:
*** полёт мысли, сразу видно что вы *** талантливый ***.Пришлось немного заретушировать, так как ну уж очень хороший результат получился :)
И так с большинством примеров которые приходят на вход модели, хотя иногда модель отказывается выполнять подобные преобразования и возвращает в Response ту же фразу, что была в Input.
Публикация весов на HuggingFace
Одна из особенностей TorchTune заключается в том, что данная утилита сохраняет веса обученной модели в ту же папку, в которую мы через вызов tune download скачали веса оригинальной модели. Поэтому прежде чем опубликовать свежеобученную модель на HuggingFace необходимо перенести веса и всё необходимое в отдельную директорию.
В частности на понадобятся следующие файлы:
config.json (конфигурация модели, тут мы разве что заменим _name_or_path)
generation_config.json (параметры по умолчанию для генератора)
hf_model_0001_2.pt → (переименуем) → pytorch_model-00001-of-00002.bin
hf_model_0002_2.pt → (переименуем) → pytorch_model-00002-of-00002.bin
pytorch_model.bin.index.json (индекс весов)
special_tokens_map.json
tokenizer.json
tokenizer.model
tokenizer_config.json
src="./Llama-2-7b-hf"
dst="./toxicator-ru-hf"
mkdir -pv toxicator-ru-hf
cp -v $src/hf_model_0001_2.pt $dst/pytorch_model-00001-of-00002.bin
cp -v $src/hf_model_0002_2.pt $dst/pytorch_model-00002-of-00002.bin
cp -v $src/pytorch_model.bin.index.json $dst/
cp -v $src/config.json $dst/
sed -r 's#meta-llama/Llama-2-7b-hf#evilfreelancer/llama2-7b-toxicator-ru#g' -i $dst/config.json
cp -v $src/generation_config.json $dst/
cp -v $src/special_tokens_map.json $dst/
cp -v $src/tokenizer.json $dst/
cp -v $src/tokenizer.model $dst/
cp -v $src/tokenizer_config.json $dst/Проверим работоспособность модели следующим скриптом для инференса:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
#MODEL_NAME = "evilfreelancer/llama2-7b-toxicator-ru"
MODEL_NAME = "./toxicator-ru-hf"
DEFAULT_INSTRUCTION = "Перефразируй нетоксичный текст так, чтобы он стал токсичным, сохраняя при этом исходный смысл, орфографию и пунктуацию."
DEFAULT_TEMPLATE = "### Instruction:\n{instruction}\n\n### Input:\n{input}\n\n### Response:\n"
# Init model and tokenizer
generation_config = GenerationConfig.from_pretrained(MODEL_NAME)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, torch_dtype=torch.float16, device_map="auto")
model.eval()
# Build instruct prompt
user_message = "Великолепный полёт мысли, сразу видно, что Вы очень талантливы."
prompt = DEFAULT_TEMPLATE.format(**{"instruction": DEFAULT_INSTRUCTION, "input": user_message})
# Run model
data = tokenizer(prompt, return_tensors="pt")
data = {k: v.to(model.device) for k, v in data.items()}
output_ids = model.generate(**data, max_length=256, generation_config=generation_config)[0]
output = tokenizer.decode(output_ids, skip_special_tokens=True)
print(output)Запустим и посмотрим что получилось:

Пример работы тестового скрипта для токсификации
Тут будет чуть более продвинутая версия скрипта выше, работающая в режиме интерактивного чата.
Пару слов про TorchTune
Мы завершили основную часть, поэтому хочу поделиться некоторыми наблюдениями о работе с утилитой TorchTune.
Во время работы я оценил её удобство и простоту, но также столкнулся с рядом ограничений. Одно из них — невозможность одновременно использовать несколько датасетов при обучении. Если в будущем потребуется обучать модель уровня Saiga (rulm), придётся заранее объединять все датасеты в один, что снижает гибкость. Ожидаю, что эту возможность добавят в обновлениях.
Кроме того, TorchTune пока не поддерживает самописные классы моделей и датасетов, так как конфигурации по умолчанию ориентированы на встроенные пути внутри директории пакета torchtune. В идеале, хотелось бы видеть функцию интеграции пользовательских датасетов и классов.
Также разочаровало ограниченное количество поддерживаемых моделей. Я ожидал более гибкую систему настройки, подобно AutoModel и AutoTokenizer из пакета transformers, которые могли бы автоматически адаптировать настройки.
На данный момент квантизация доступна только через пакет bitsandbytes, хотя было бы удобно иметь возможность выполнять квантизацию и через другие инструменты, например, llama.cpp.
Несмотря на текущие ограничения, которые, вероятно, будут устранены, TorchTune представляет большой интерес. Этот инструмент имеет потенциал стать стандартом в обучении моделей, благодаря своей простоте и универсальности. Поэтому я рекомендую испытать его в работе, чтобы оценить все преимущества на собственном опыте.
Заключение
Вот и подошел к концу наше пятничное путешествие по захватывающему миру токсификации текстов. Мы начали с подготовки рабочего пространства, перешли к созданию датасета и завершили наш проект публикацией результатов на HuggingFace. Теперь у нас есть модель Toxicator RU, которая позволяет генерировать синтетические датасеты с токсичными предложениями, используя лишь обычные тексты.
Что касается проекта TorchTune, несмотря на его относительную молодость и некоторые ограничения, он предлагает мощные инструменты для обучения и тестирования моделей, делая этот процесс более доступным и удобным.
Надеюсь, что данная публикация вдохновит вас на собственные эксперименты и исследования в области искусственного интеллекта и машинного обучения. Не бойтесь пробовать новое и экспериментировать.
Спасибо за внимание и хороших выходных!
Полезные ссылки
PS. А ссылку на мой Телеграм-канал, уж простите, не дам, это секретная информация ;)
