Obsidian + Dataview: Таблицы

На статью меня вдохновил этот комментарий .
Dataview — это мощный плагин для Obsidian позволяющий отбирать данные (теги, даты, числа и любые другие пользовательские параметры) markdown-заметок, а затем их фильтровать и отбирать как пожелаешь.
Это такой своеобразный аналог Notion-таблиц, где можно создать таблицу с бесконечной вложенностью (таблица, внутри одной ячейки, а внутри еще таблица и еще и еще).
На КДПВ как раз собраны разные кейсы реализации функционала плагина Dataview:
Книги с прогрессом чтения
Проекты со счётчиком выполненных и не выполненных задач
Прогресс года, месяца, дня и всей жизни
Фильмы в виде карточек Разбирать каждый кейс я буду под катом.
Установка Dataview
Данная инструкция написана для версии программы 1.1.9. (Перед всеми нижеописанными действиями надо неплохо было бы обновиться: Меню => О программе => Проверить обновления)
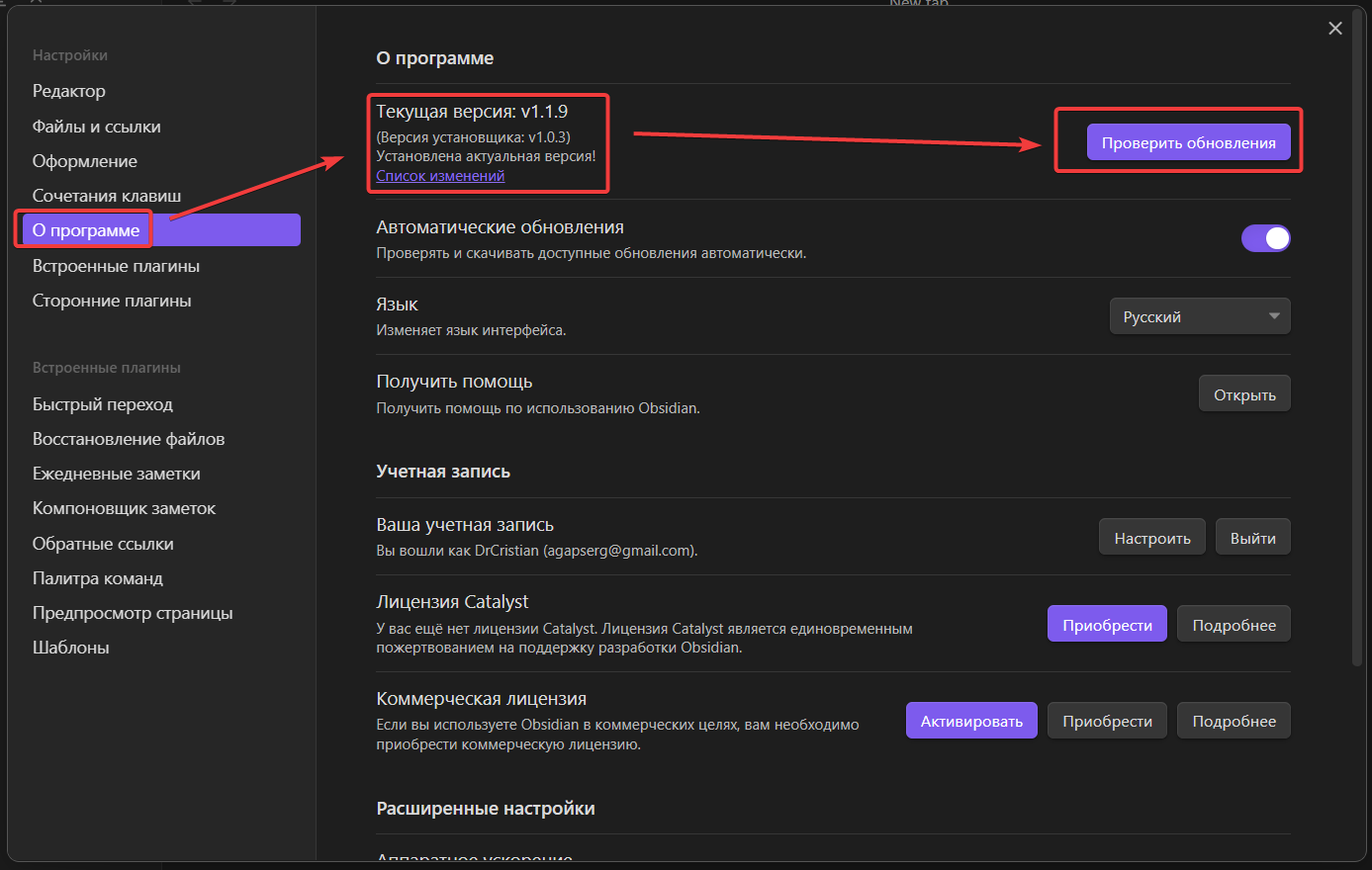
Для начала идём в Меню => Сторонние плагины => Включите плагины сообщества

Затем «Обзор»
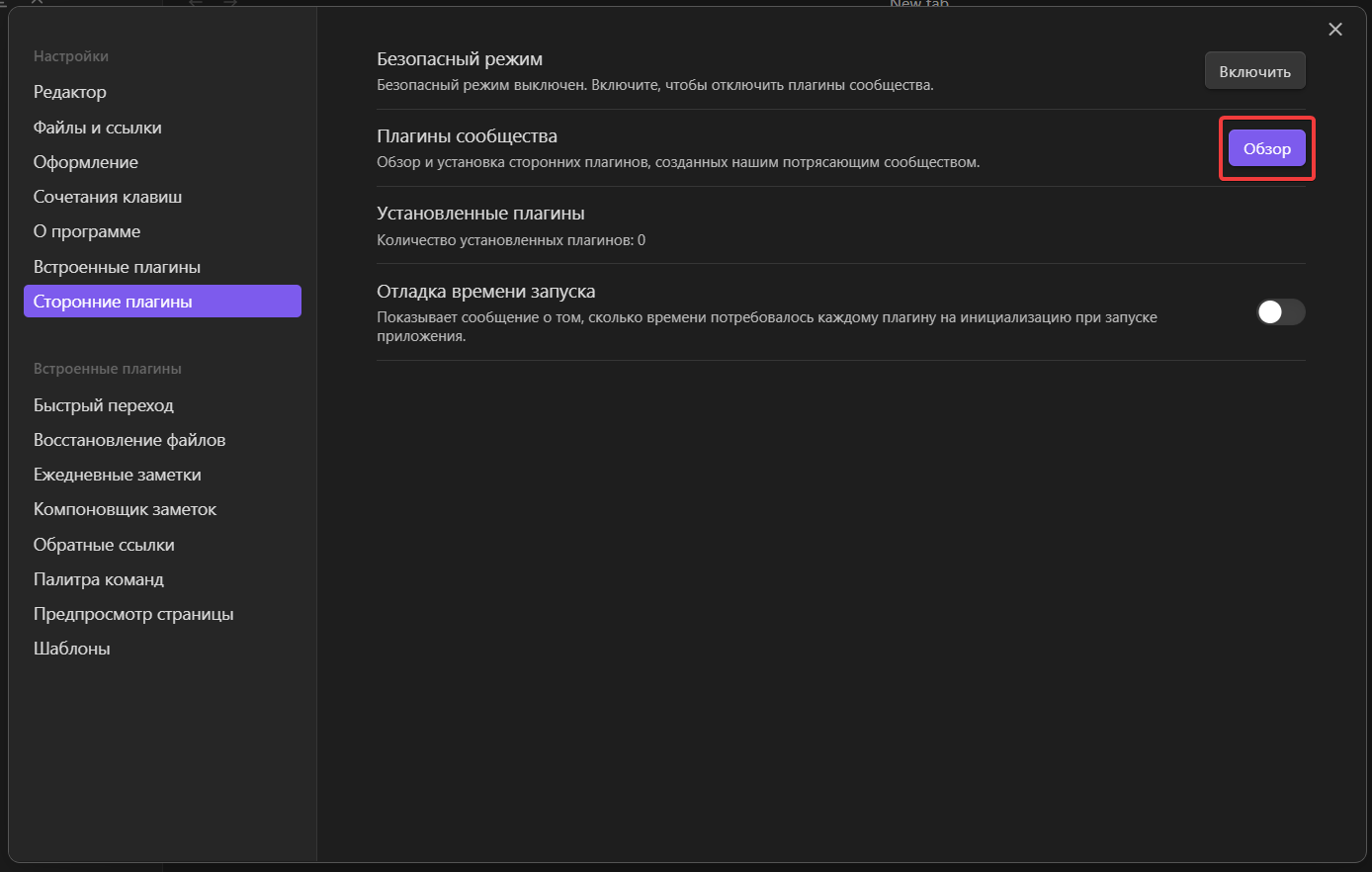
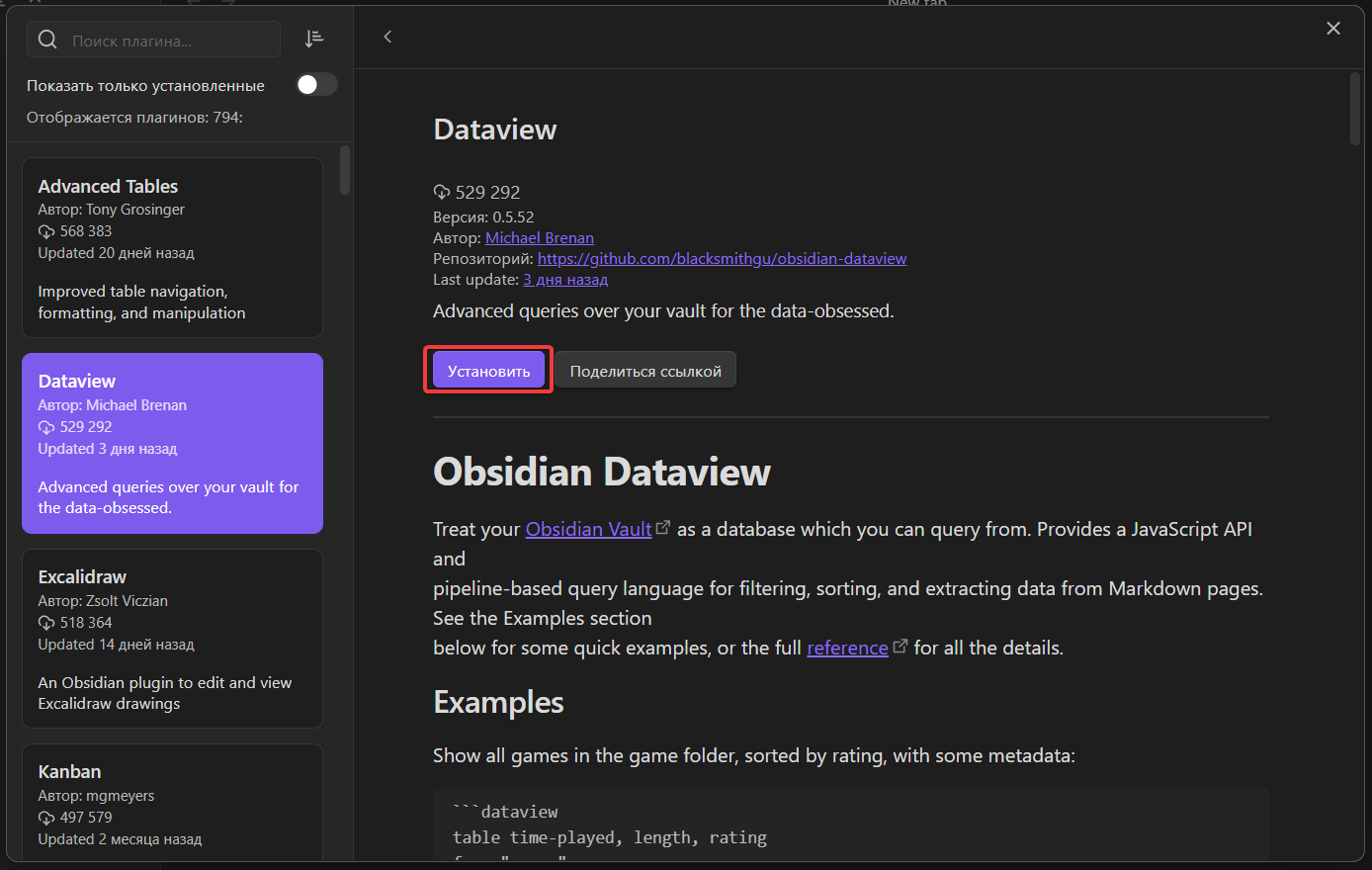
Затем находим в списке Dataview (Можно написать в поиске, а можно не писать, данный плагин находится вторым в списке)

Жмём «Установить», ждём пару секуд пока плагин скачается и установится
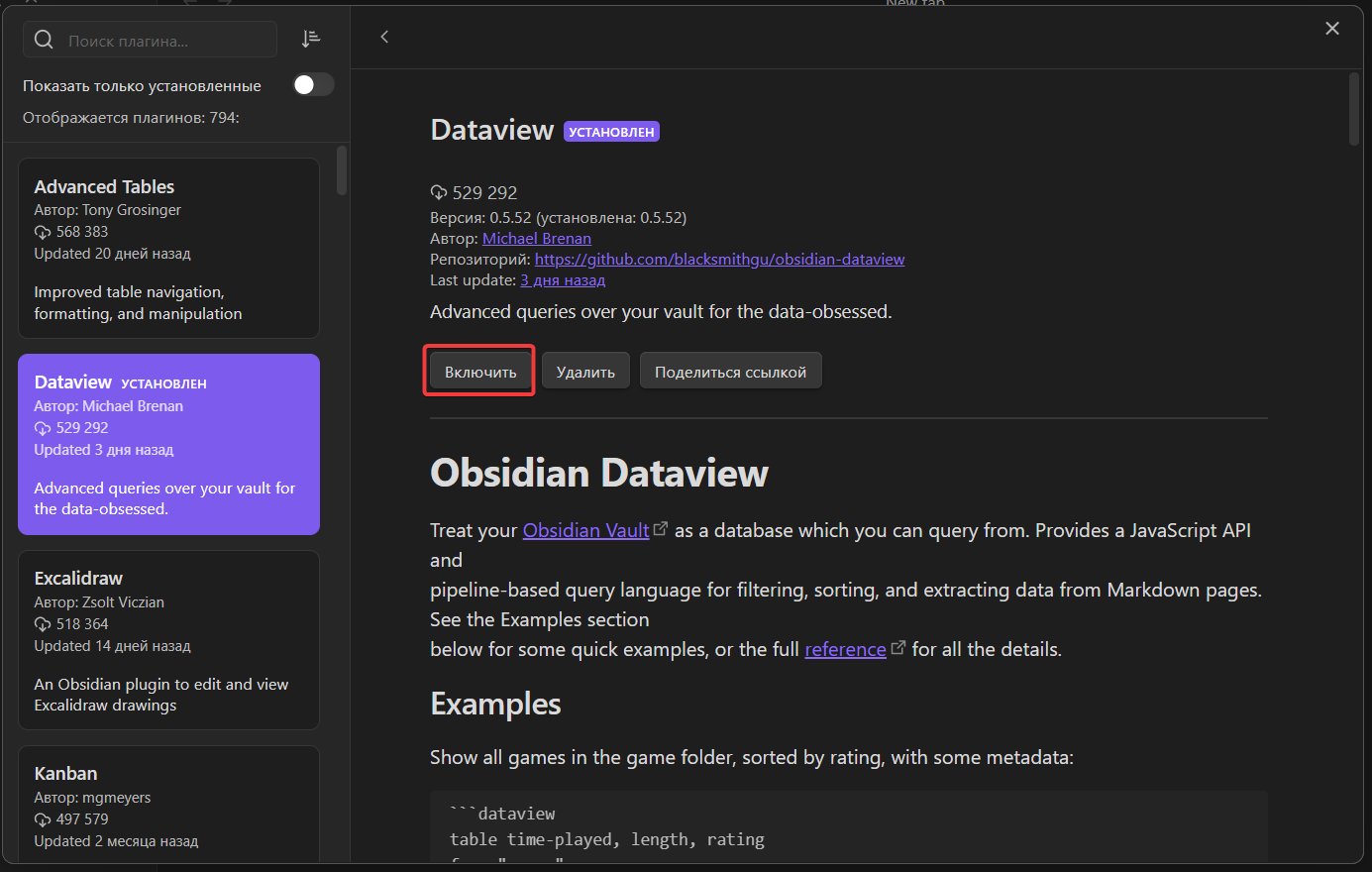
Затем жмём «Включить»
Как всё это работает в двух словах
Dataview работает на встроенном языке запросов
Все запросы должны писаться внутри подобного блока кода:
```dataview TABLE|LIST|TASK <Поле1> [AS "Название столбца"], <Поле2>, ..., <Поле3> FROM <Источник> WHERE <Выражение> SORT <Выражение> [ASC/DESC] ... другие команды ```
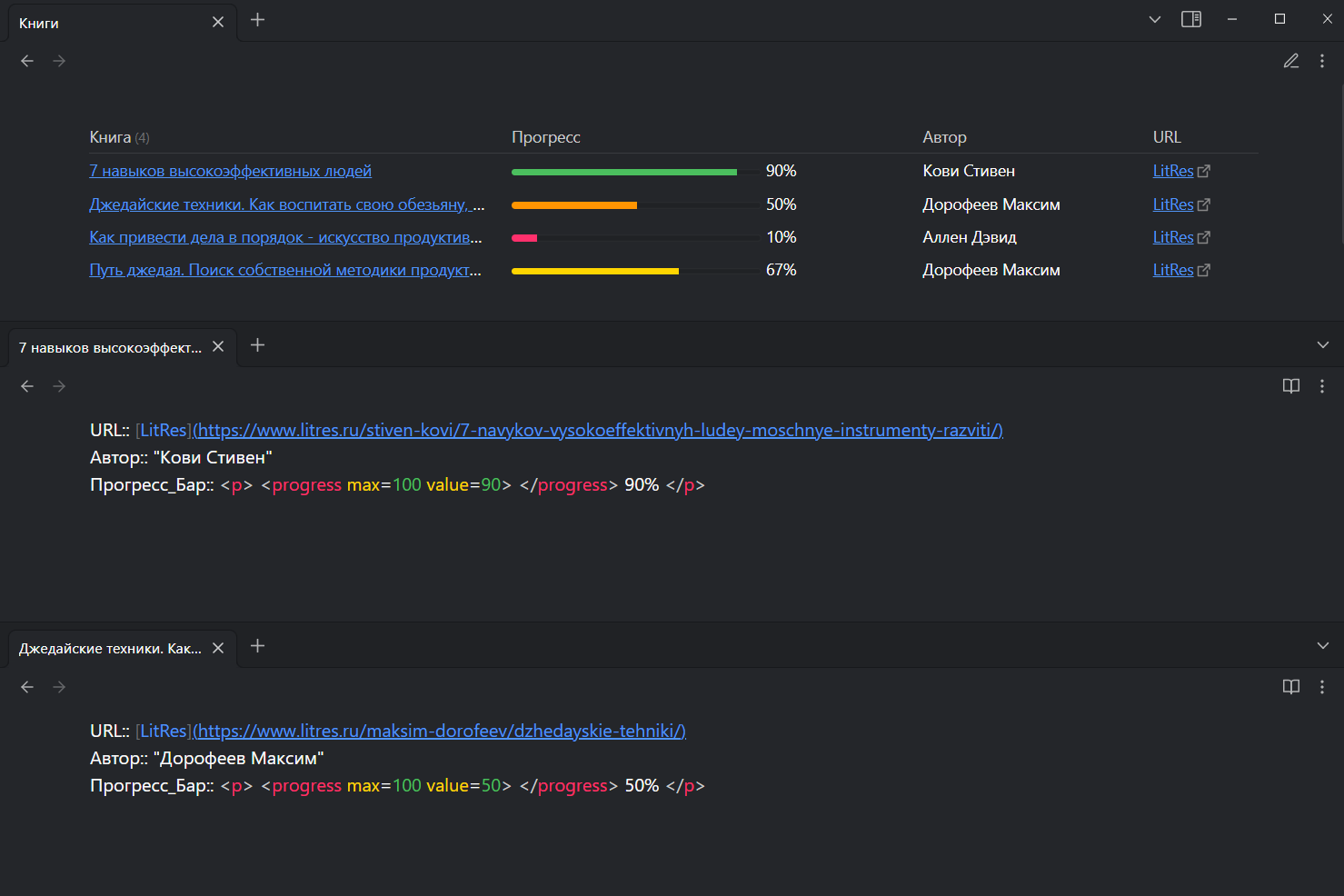
Книги с прогрессом чтения
Данный кейс предназначен для составления своей базы данных книг и отслеживания прогресса чтения
Код запроса выглядит так:
```dataview
TABLE WITHOUT ID
file.link AS "Книга",
Прогресс_Бар AS "Прогресс",
Автор,
URL
FROM "Книги"
```Разбираем код построчно:
TABLE WITHOUT ID — мы указали, что нам нужна таблица
Далее перечисляем столбцы, которые нам нужны, первым столбцом будет ссылка на саму заметку (file.link), а называться этот столбец будет «Книга» (AS Книга)
Затем нам нужен прогресс бар (Прогресс_Бар), а называться этот столбец будет «Прогресс» (AS «Прогресс») — AS … — мы пишем только тогда, когда хотим, чтобы столбец назывался как-то отлично от параметра, который за ним скрывается. Для разнообразия можно использовать эмодзи, они поддерживаются.
Затем Автор
Затем URL
Затем мы указываем откуда будут собираться и обрабатываться заметки из папки «Книги» (FROM «Книги»). Данный способ отбора заметок подходит для тех, кто хочет отобрать заметки из определённой папки => в вашем хранилище заметки должны быть рассортированы по папкам. В дальнейшем при добавленнии в указанную папку новой заметки она так же отобразится в получившейся таблице.
Сами заметки должны лежать в папке «Книги» и содержать следующий набор параметров:
URL:: [LitRes](https://www.litres.ru/stiven-kovi/7-navykov-vysokoeffektivnyh-ludey-moschnye-instrumenty-razviti/)
Автор:: "Кови Стивен"
Прогресс_Бар:: 90%
Разбираем построчно:
Название заметки — Оно отобразится в таблице первым
URL — это ссылка на книгу
Автор — Это автор книги в ковычках, т.к. есть пробел
Прогресс_Бар — Тут мы задаём параметры прогресс бара, максимальное значение (progress max=100), текущее значение (value=90) и текстовое пояснение (90%)
В конечном итоге получается вот такая таблица:
Проекты со счётчиком выполненных и не выполненных задач
Данный кейс предназначен для отслеживания прогресса по проектам
Код запроса выглядит вот так:
```dataview
TABLE WITHOUT ID
file.link AS Проект,
Статус,
(length(filter(file.tasks.completed, (t) => t = true))) / (length(file.tasks.text)) * 100 AS "% Завершено",
(length(file.tasks.text)) AS Всего,
(length(filter(file.tasks.completed, (t) => t = true))) AS Завершённых,
(length(file.tasks.text)) - (length(filter(file.tasks.completed, (t) => t = true))) AS "Незавршенных"
FROM #проекты
```Разбираем код построчно:
TABLE WITHOUT ID — мы указали, что нам нужна таблица
Далее перечисляем столбцы, которые нам нужны, первым столбцом будет ссылка на саму заметку (file.link), а называться этот столбец будет «Проект» (AS Проект)
Статус — это статус наших проектов (В процессе, Готово, Не приступал)
Следующей строчкой мы вычисляем кол-во завершённых задач проекте и кол-во незавершённых задач, делим их друг на друга и получаем процент готовности проекта
Данной строчкой мы считаем кол-во всех задач, т.е. берём размер массива file.tasks.text
Этой строчкой мы считаем кол-во завершённых задач
А этой строчкой мы вычитаем из общего кол-ва задач кол-во завершённых задач и таким образом получаем кол-во незавершённых задач
Затем мы указываем откуда будут собираться и обрабатываться заметки. В данном случае будут отбираться все заметки с тегом #проекты (FROM #проекты). Данный способ отбора заметок подходит для тех, кто хочет отобрать заметки с определённым тего => в вашем хранилище заметкам должны быть присвоены соответствующе теги. В дальнейшем при добавленнии в хранилище новой заметки с указанным тегом она так же отобразится в получившейся таблице.
Сами заметки должны содержать следующий набор параметров:
#проекты
Статус:: "Готово"
---
# ToDo:
- [x] Снять размеры с вытяжки
- [x] Нагуглить вытяжки
- [x] Купить вытяжку
- [x] Съездить за вытяжкой в магазин
- [x] Установить вытяжкуРазбираем построчно:
Тег #проекты — чтобы запрос отбирал нужную нам заметки
Статус — чтобы он отображался в таблице. В дальнейшем этот статус можно будет менять в заметке и он будет меняться в таблице
Затем разделитель (---) — для удобства
И затем список задач — которые будут обрабатываться нашей таблицей
В конечном итоге получаем вот такую таблицу:

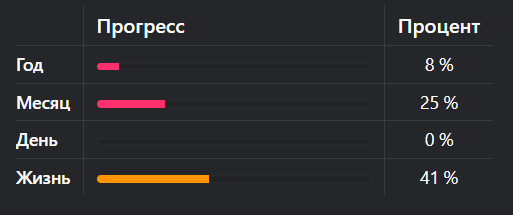
Прогресс года, месяца, дня и всей жизни
Данный кейс предназначен для наглядной визуализации прошедшего года\месяца\дня\жизни. Нужен этот блок для грусти о потерянном времени
Код запроса выглядит побольше, вот так (в данном коде используется уже JavaScript). Отличается он первой строчкой dataview => dataviewjs
```dataviewjs
const today = DateTime.now()
const endOfYear = {
year: today.year,
month: 12,
day: 31
}
const lifespan = { year: 80 }
const birthday = DateTime.fromObject({
year: 1990,
month: 3,
day: 11
});
const deathday = birthday.plus(lifespan)
function progress(type) {
let value;
switch(type) {
case "lifespan":
value = (today.year - birthday.year) / lifespan.year * 100;
break;
case "year":
value = today.month / 12 * 100
break;
case "month":
value = today.day / today.daysInMonth * 100
break;
case "day":
value = today.hour / 24 * 100
break;
}
return ` | ${parseInt(value)} %`
}
dv.span(`
| | Прогресс | Процент |
| --- | --- |:---:|
| **Год** | ${progress("year")}
| **Месяц**| ${progress("month")}
| **День**| ${progress("day")}
| **Жизнь** | ${progress("lifespan")}
`)
```Разбираем код построчно:
В первом блоке мы задаём константы текущего дня и конца года
Во втором блоке мы задаём прогнозируемую продолжительность жизни (80 лет) и дату рождения
Далее описываем функцию расчёта прогресса
И в конце представляем всё это в виде произвольной markdown таблицы
В конечном итоге получаем вот такую таблицу:
Фильмы в виде карточек
Данный кейс предназначен для составлении своей библиотеки просмотренных или наоборот непросмотренных фильмов. Для реализации данного кейса необходимо сделать еще пару приготовительных действий:
Сначала ставим тему Minimal, для этого идём в настройки => Оформление => Настроить
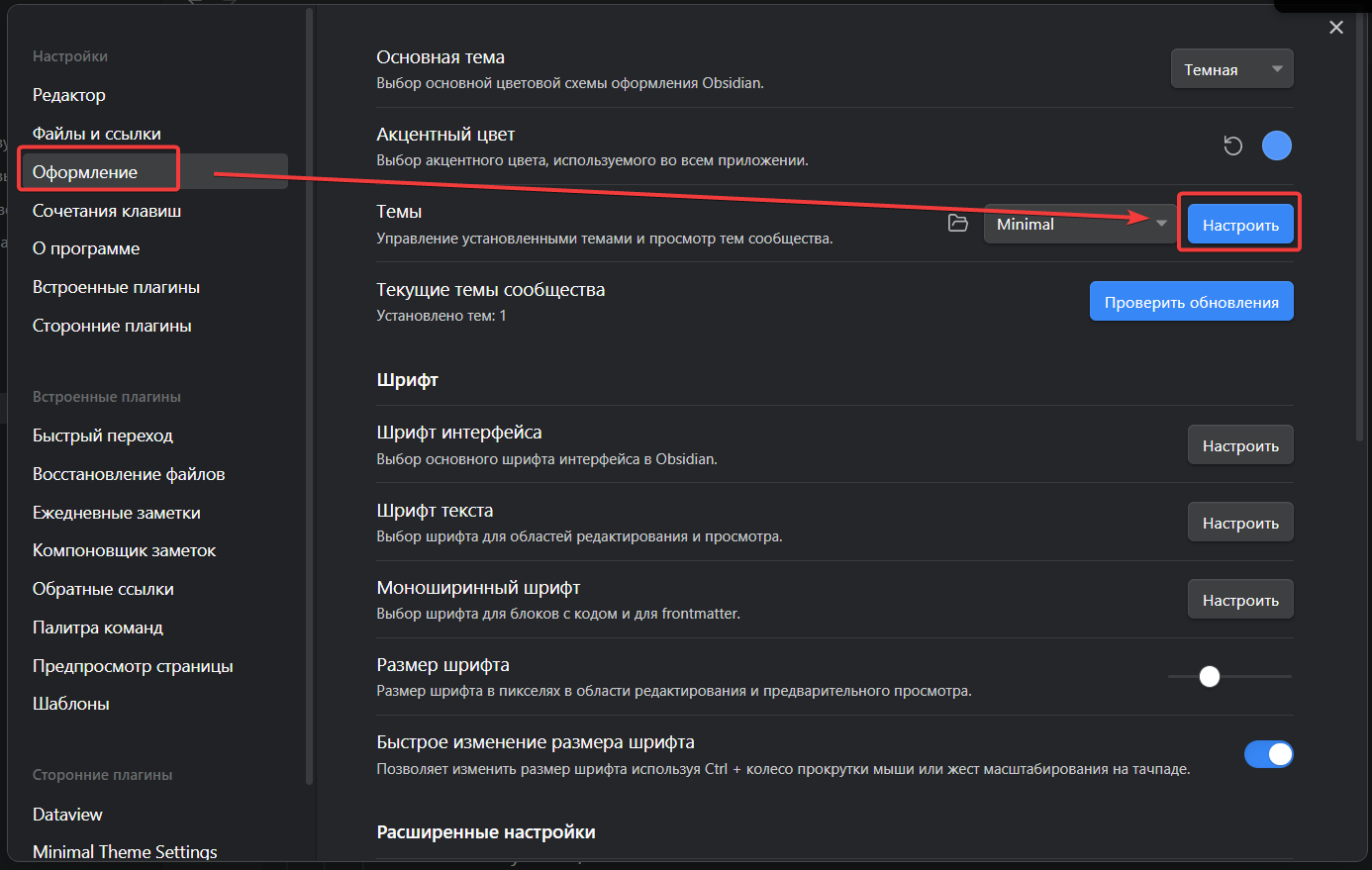
Там выбираем тему Minimal
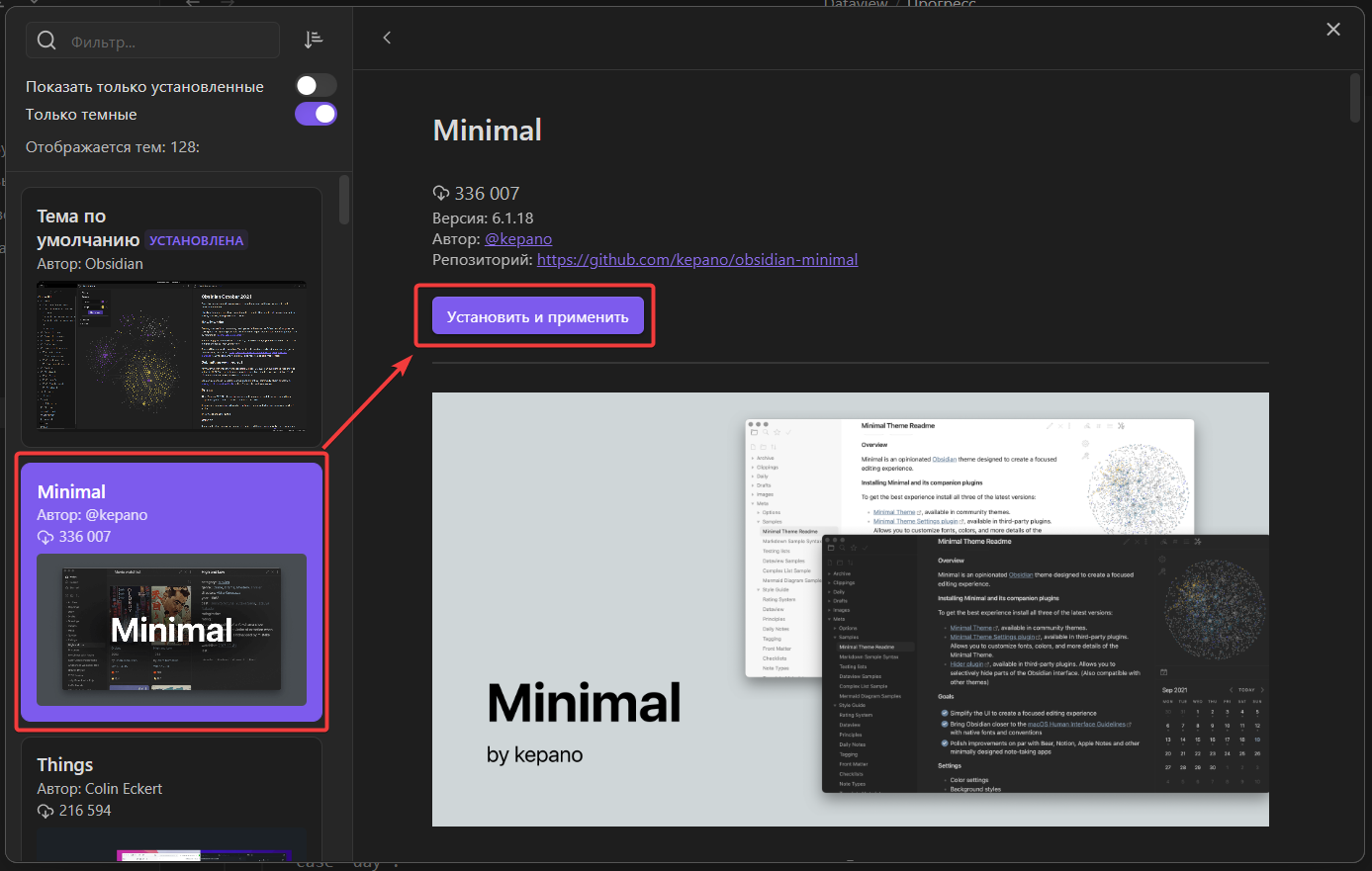
Затем идём в сторонние плагины и устанавливаем и включаем плагин Minimal Theme Settings

А затем так же устанавливаем плагин Sortable
Код запроса выглядит вот так:
---
cssClasses: cards, cards-cover, cards-1-1, table-max, cards-cols-4
---
```dataview
TABLE WITHOUT ID
("") as Постер,
file.link AS Название,
Год,
РейтингКП,
URL
FROM "Фильмы"
```Разбираем построчно:
Сначала мы присваиваем заметке кастомный css-класс, для этого отбиваем его сверху и снизу разделителями (---), а в между ними пишем cards, cards-cover, cards-1–1, table-max, cards-cols-4, это означает, что у нас будет таблица в виде карточек, карточки будут размером 1к1, таблица будет растянута на всю ширину заметки и фиксируем кол-во столбцов = 4
Затем в блоке dataview мы опять задаём, что это будет таблица (TABLE WITHOUT ID)
Затем вот такой строчкой ((»») as Постер) мы говорим обработчику, что хотим выводить сам постер в виде картинки в таблице
Затем опять название заметки
Затем год фильмы
Затем рейтинг кинопоиска
Затем выводим ссылку на кинопоиск
Всё это мы собираем из папки «Фильмы» (FROM «Фильмы»)
Сами заметки должны содержать следующий набор параметров:
Год:: 2003
РейтингКП:: 8.7
URL:: "[Кинопоиск](https://www.kinopoisk.ru/film/3498/)"
Постер:: "https://kinopoisk-ru.clstorage.net/N30iW1384/e515deON/2zI0YN6s508t2KHYsS6u_7YQb9WcfzvbzhmPOPlra6c20ffu3qRaZAQJo-WDAweGjJX5SdfmSPBis5fUXmnHbD_2FBHL6RZb6C10PEDu_jqzJI4VGWvvD0t9zunMvt5VxdN0zEmGOZaGC2Xxt0d2U1kADUiCU8zA4yem43291-vIU5VSn680az8ach9wPy7fZlK7xZ2-Lnivelnaa0qJ5yVh9D6bVHvkpSk0EiVWs5LrI69psdIegdcGtOBfS4VYifM08o7fBpqtOFJNMx2czWVQ-gQPLI5bTeoa6RpoiiVEcYa9yffYJCRZJ8Pnl3KCu6BsmxIzPMFmhOYQfDuH6kkB9lDufrQq7UigbmAeXU2WgRol7twNG-6467j669s1J4MEjBhnutWEaJVQBnVDsctDfQsBAs3AN4b0or9qp9gZ43bQ3M71GV6bYd5ArgwMxoG6lj69fVlvahtJenkoFHchBm3p98pVRml0IaZWIYLLEiwYEwIu0tTGRcGdSoY5yFE2ke7u52uNaoNPAKwNb0cha-YObg147FvZyDlo6vT08xT_OtaJJkfbFSHndNCR-xOfq-Hz3ZCm5abxLcq1ixqD9sLdj9f43iuCTED8jU-XM6v3nw18eax6CLtbSboll7BErsk0OjU2aLYxp1Ugg0rDThngYMzS10RGMJz5FTiJgjcynN6nCf34Uv8xrk8NBFLpJ9x83YotStvJW1lL9zQzlhyYZCqXFFtHkeR2EuCokG1asnH_kfeHxYAvaPb5qcN0oV3v9hnuK4BNcx6NbWTDynYsPi45PvnquMipSvUFYMRt-ffaZ7U7trA2tBMyifOvyIITLMHUVDSyfWmWWogBJrH_3ZTI_8vBjyOcbV_FQytnDo3dW-_LarppaStFNDNFThvmq9SG29RBhQZQINrCjfvR4D0T14WHIC9a9NgbQvXgj76GGv06IkzSnb9f1RF7dE2PDjjtK6s4aKq4NBdC5Y0LZqkmVUpVgNc0cRGJA6_r8rGP0AeGVoHfCWf6SgEH4o5tNlv-iNLcEe5tLpdzaWX9HP1JLWqb2evo-bRUwzZvyGS7F0bpxdBXNXBQe2Fv-oGx70FFVxagLxj1yBmiZGD9jqVJHWpCDNL_3byEEot1rz1eat0KuojJOhpGhuJGTUlUahcUCVax9heCcdlhf4ricg7C1YSmI91K5UnJA4Qh7a7l6S_6MB1g_q4vNnLZlvz-P5r8qCj5Gpm5FMcCRq8YhdqWpjj3k1REEiJ7YG0K4aPu0tf3J_KuypQaidBWgKxshwl_G9Od0R4PLUaS-pcuPf05P9oKSqk5SUcUUDaem_a4xsdqxWAndLIzmbCPC6ITDMBEx7bTH9mXy6sBdtEd7edabXhAbIMvHoy0M3g2Pg7ce30IGQsY2ugXVEJF7qjk-ndlGrUztCcx0vuyr4iB8s6CFGSV8-5bhStqsiYT_o1GyQ26Y56Djv7-dQJLBZ8938ie28vbe8rbhNWyBv97N8qVVrj1IcW2wjGKMB_pUrAfkPTllxJMy2Taq_J0ApzNFyj_udIM876c75fTy9VNLe1Z3GhZCHtbmcSkg4QNeQR6F3To56IWtyCR2DINmQMATnH3dAdRD3qEKZgQReK9nbbpfgpCz2GPHRxmcEinP13uCD6o2mnrucjXlQPkrNtUaacGy6Uj9CbR0xkzvOrh0Y2RJff18P741OhrMDTR_qzG-x1oAhyg_x5u52C4Vn0_34lcyvtJeNnL95dDB9zo5BnkZ_jWcrZG4IK60U9rYCJeUQbVhVGNS7XZGzP10g8_Zjm9KhD8MTxsLbahKlZvjr3L3PmIyKto2lWmQBT-KieploQZVfJUpzDA6DAcy8Mw_aJndGaC3opGG-nA19DPPkVpDUtz7KL-7nzn01g0Tv4euIxqS9jquvlm52PWf_t16zSna1cClydiwvnDraviknzDZTak8l5bdYprA-UBHP1X676LQj6gzYzdpMKpVYyOnKlemkn4OOjLRBRwJ33LJGjlF_kX0PZWMIPY4a8aEyPtMPU2lXMsW2fZenNHUe6uhgqvK5PNUIxOzWfjORbub35IvWmaajnLKYUVcaeuSwQLlZYIx6KGJBHxC7BfyiHQXTAVteVCTNpG6WozpuCuH2UZX2pQ3zLNHu1XEwmVrQyMGd44C4g5iUl05sMlfOpni7aFGSUB93cA0rliTZuT4c8gtZZ2o-5aliirYSaD3g5E6d8aMH7yHO8f5iBLxR5v3etPemvai5n615eiZcx6NguGtxkUIDVVUuPYAE-rsCJuYjbX5PBea6VZiAAUEQ7dVgqOanF-wo3O_7aBmncMr98ZXChImtq5O_bE88WtGgf49Aa61_O1JQPDiUK_moCz3KH3VAYQX9sFaHsDdKCvjYYYvfiR_mId_MylMntmP0yNSW7paMq5KXpmttPXfTomKTSWmceT9tUC89kAHXuxw33C1IQ3cv0K9ipKMCYzHy0War9KkPwyDgxNZXGIR-6cL4mOudvYaxgp9tWzJ9355KpmZlr0MHc3E-FZ4qzYEcPPMJb3J8JNeLbqS_OWoc8vNMvviCFNQ8wevbcBG-b-TD9Z3utLiWhbG-U04aQ-eFb7FSUJNIHGVaPTGdBcOOOyfcN0RlXibRuGKqtD5_KOf9drHRjyLgGt3gzH44l0fh5uWLx5y4kbafp3dINWrxvWCbR0aWVgNXeCIsnA3LuisS5S52Y3gcxZtUmpQAXhb-9WKJ6oAK5jnn-cpJN6p_0-3-veK2nLe1iIdBYCVp_6teqElVtFMhe3MlG7Us8KguINsweG9WMOa-RZe-E0YL-91JscGJF8Yn2uXuRxOUZePs5ZLtiJaOlJ6AUXUya_yfRKBlYq12HkxIHRCQCt-bAwTxFG9rbh_GiGC5tjZdF8PUcqr7phTvI8_z_kgzmULB9tOWyoiZoZycpHd1AGfvlk2mW3SKVgJIYTkNvCLOjTgT1ipvRX0"
В конечном итоге получается вот такая таблица, которую можно на лету сортировать по любому из полей (благодаря плагину Sortable):

Заключение
Надеюсь я смог раскрыть маленькую частичку функционала плагина Dataview.
Возможно разобранные кейсы смогут кого-то вдохновить.
Не успев опубликовать эту статью, уже начал набрасывать статью про задачи в том же плагине Dataview, которые использую активно уже более года и к данному моменту создал уже более 6 тысяч задач себе.
А разбирать каждый кейс будем под катом.
