Обработка миллионов событий в сутки при помощи каскадов очередей
Под капотом нашего продукта крутятся сотни, тысячи, а в некоторых сервисах и миллионы очередей, через которые проходит огромное количество данных. Все это нужно каким-то магическим образом обрабатывать и не застрелиться. В данном посте я расскажу, какие архитектурные подходы мы используем у себя, имея достаточно скромный стэк технологий и не имея маленького дата-центра у себя в «кладовке».

Что имеем?
Итак, с одной стороны у нас есть всем известный стэк технологий: Nginx, PHP, PostgreSQL, Redis. С другой стороны, у нас в системе ежеминутно происходят десятки тысяч, а в пике может достигать и сотен тысяч событий. Для того, чтобы было понятно что это за события, и как мы должны на них реагировать, сделаю небольшое продуктовое отступление, после которого я расскажу, как мы разрабатывали Event-based систему автоматизации.
ManyChat — платформа для маркетинговой автоматизации. Владелец страницы на Facebook может подключить ее к нашей платформе и настроить автоматизацию взаимодействия со своими подписчиками (проще говоря, создать чат-бота). Автоматизация обычно состоит из множества цепочек взаимодействий, которые могут быть не связаны между собой. В рамках этих цепочек автоматизаций, могут происходить определенные действия с подписчиком, например присваивание определенного тэга в системе, или присваивание/изменение значение поля в карточке подписчика. Эти данные в дальнейшем позволяют сегментировать аудиторию и выстраивать более релевантное взаимодействие с подписчиками страницы.
Наши клиенты очень хотели Event-based автоматизацию — возможность настраивать выполнение действия при срабатывании определенного события в рамках подписчика (например присваивание тега).
Так как триггерное событие может сработать из разных цепочек автоматизации, важно, чтобы была единая точка настройки всех Event-based действий со стороны клиента, а со стороны нашего процессинга должна быть единая шина, обрабатывающая изменение контекста подписчика из разных точек автоматизации.
В нашей системе существует общая шина, через которую проходят все события, происходящие с подписчиками. В сутки это более 500 миллионов событий. Их обработка достаточно тонкая — это запись в хранилище данных, для того, чтобы у владельца страницы была возможность просмотреть исторически все, что происходило с его подписчиками.
Казалось бы, для того, чтобы реализовать Event-based систему у нас уже все есть, и нам достаточно встроить нашу бизнес-логику в обработку общей событийной шины. Но у нас есть определенные требования к нашей новой системе:
- Мы не хотим получить деградацию производительности в обработке основной событийной шины
- Нам важно сохранить порядок обработки сообщений в новой системе, так как на это может быть завязана бизнес-логика клиента, который настраивает автоматизацию
- Избежать эффекта шумных соседей, когда активные страницы с большим количеством подписчиков забивают очередь и блокируют обработку событий «маленьких» страниц
Если встроить процессинг нашей логики в обработку общей шины событий, то мы получим серьезную деградацию в производительности, так как нам придется проверять каждый ивент на соответствие настроенной автоматизации. В рамках настройки автоматизации могут быть наложены определенные фильтры (например, запускать автоматизацию при срабатывании события только для клиентов женского пола, старше 30 лет). То есть, при обработке событий в основной шине будет обрабатываться огромное количество лишних запросов к бд, а также запускаться достаточно тяжеловесная логика сравнения текущего контекста подписчика с настройками автоматизации. Такой вариант нам не подходит, поэтому мы пошли думать дальше.
Организация каскада очередей
Так как наша бизнес логика, связанная с event-based системой, очень хорошо отделима от логики обработки событий из основной шины, мы решаем вынести нужные нам типы событий из общей шины в отдельную очередь, для дальнейшей обработки в отдельном потоке данных. Тем самым, мы убираем проблему, связанную с деградацией производительности в обработке основной событийной шины.
На этом же этапе мы решаем, что было бы круто при перекладывании событий в следующую по каскаду очередь, класть эти события в отдельные для каждого бота очереди. Тем самым, изолировав активность каждого бота рамками своей очереди, что позволяет нам решить проблему, связанную с эффектом шумных соседей.
Наша схема потока данных теперь выглядит следующим образом: 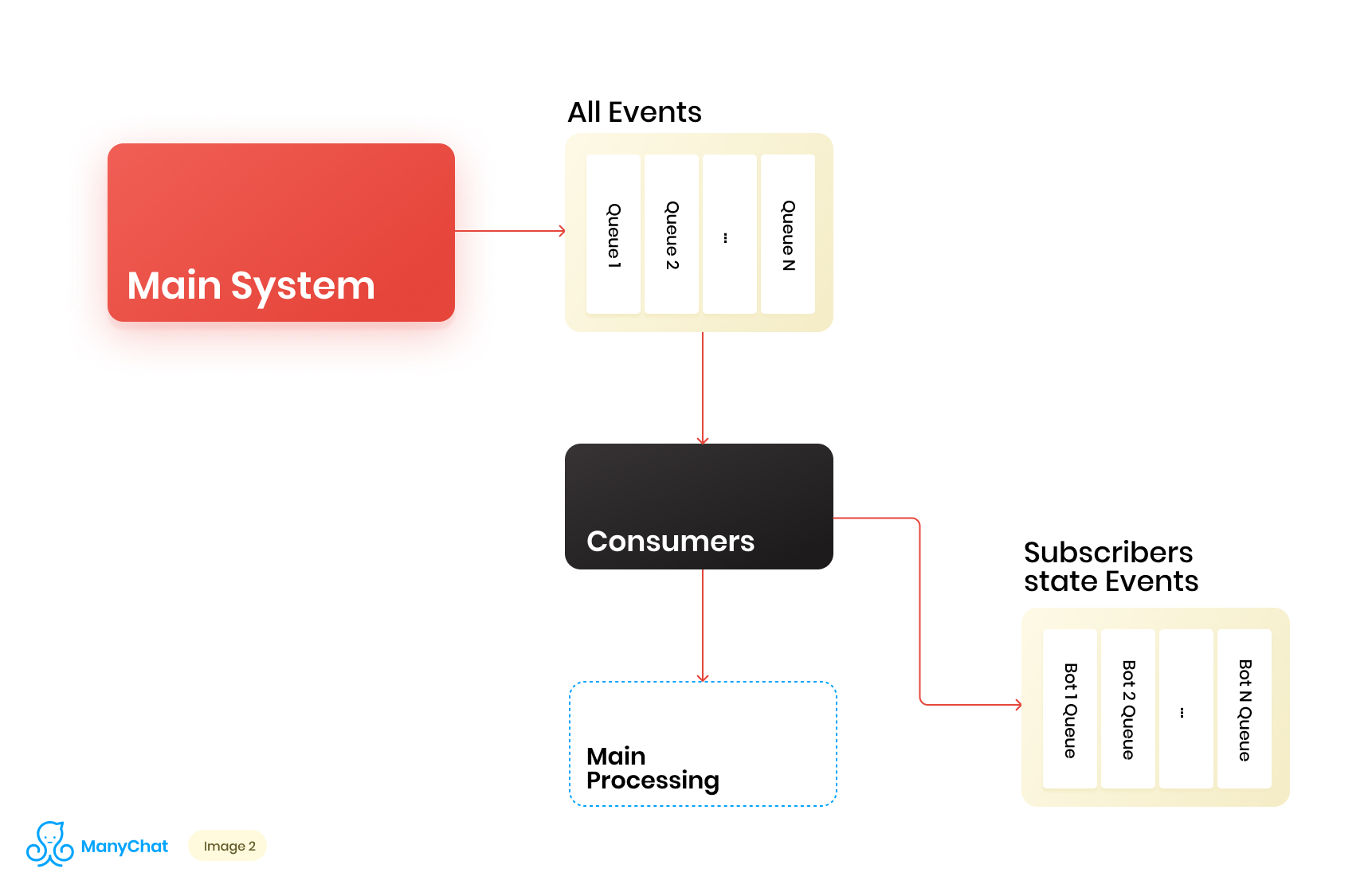
Однако для того, чтобы эта схема заработала, нам нужно решить вопрос с обработкой новых очередей.
На нашей платформе больше 1 миллиона подключенных страниц (ботов), а это значит, что потенциально мы можем получить в нашей схеме ~1 миллион очередей, только на уровне event-based слоя. С технической точки зрения для нас это не страшно. В качестве сервера очередей мы используем Redis с его стандартными типами данных, таких как LIST, SORTED SET, и другие. Это значит, кто каждая очередь является стандартной для Redis структурой данных в оперативной памяти, которая может быть создана или удалена на лету, что позволяет нам легко и гибко оперировать огромным количеством очередей у нас в системе. Более глубоко об использовании Redis в качестве сервера очередей с техническими деталями я расскажу в отдельном посте, а пока вернемся к нашей архитектуре.
Понятно, что у каждого бота разная активность, и что вероятность получить 1 миллион очередей в состоянии «нужно обработать сейчас» крайне мала. Но в один момент времени вполне возможна ситуация, когда у нас будет пара десятков тысяч активных очередей, которые требуют обработки. Количество этих очередей постоянно меняется. Сами эти очереди тоже меняются, какие-то из них вычитываются полностью и удаляются, какие-то из них динамически создаются и наполняются событиями на обработку. Соответственно нам нужно придумать эффективный способ их обработки.
Обрабатываем огромный пул очередей
Итак, у нас есть куча очередей. В каждый момент времени их может быть рандомное количество. Важное условие для обработки каждой очереди, которое упоминал в начале своего поста — события в рамках каждой страницы должны обрабатываться строго последовательно. А это значит, что в один момент времени каждую очередь не может обрабатывать больше одного воркера, чтобы избежать проблем связанных с конкурентностью.
Но и сделать соотношение очередей к обработчикам 1:1 — сомнительная задача. Количество очередей постоянно меняется, как в большую, так и в меньшую сторону. Количество запущенных обработчиков тоже не бесконечное, как минимум, мы имеем ограничение со стороны операционной системы и железа, да и не хотелось бы, чтобы воркеры простаивали на пустых очередях. Для решения проблемы взаимодействия между обработчиками и очередями, мы реализовали систему round robin для обработки нашего пула очередей.
И здесь на помощь нам пришла контрольная очередь.

В момент переадресации события из общей шины в event-based очередь конкретного бота, мы также кладем идентификатор этой ботовой очереди в контрольную очередь. Контрольная очередь хранит в себе только идентификаторы очередей, которые находятся в пуле и нуждаются в обработке. В контрольной очереди хранятся только уникальные значения, то есть один и тот же идентификатор ботовой очереди будет храниться в контрольной только один раз, вне зависимости от того, сколько раз он будет туда записан. На Redis это реализуется при помощи структуры данных SORTED SET.
Дальше мы можем выделить некоторое количество воркеров, каждый из которых будет получать из контрольной очереди свой идентификатор ботовой очереди на обработку. Тем самым каждый воркер будет независимо от остальных обрабатывать чанк из присвоенной ему очереди, после обработки чанка, возвращать идентификатор обработанной очереди в контрольную, тем самым возвращая его в наш round robin. Главное не забыть снабдить все это дело блокировками, для того, что бы два воркера не могли в параллель обрабатывать одну и ту же ботовую очередь. Такая ситуация возможна, если в контрольную очередь попадет идентификатор ботовой, в момент когда она уже находится в обработке воркером. Для блокировок мы так же используем Redis, как key: value хранилище с TTL.
При взятии задачи с идентификатором ботовой очереди из контрольной, мы ставим блокировку с TTL на взятую очередь, и начинаем ее обработку. В случае если другим консьюмером будет взята из контрольной очереди задача с уже обрабатываемой очередью, он не сможет поставить блокировку, вернет задачу в контрольную очередь и получит следующую задачу. После обработки консьюмером ботовой очереди, он снимает блокировку и идет за следующей задачей в контрольную очередь.
Итоговая схема выглядит следующим образом: 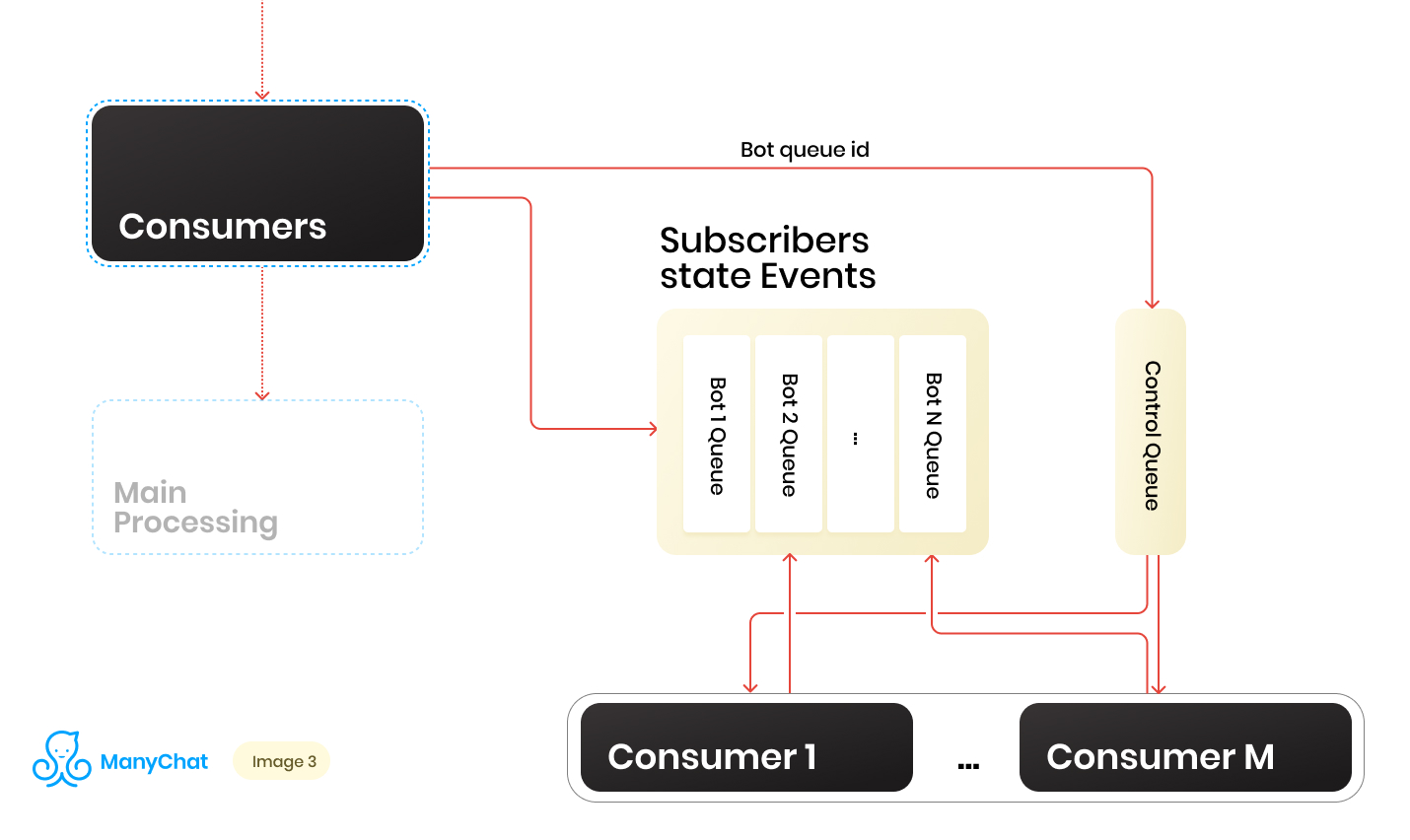
В итоге, при текущей схеме мы решили основные обозначенные проблемы:
- Деградация производительности в основной событийной шине
- Нарушение порядка обработки событий
- Эффект шумных соседей
А как бороться с динамической нагрузкой?
Схема рабочая, но в ней мы имеем фиксированное количество консьюмеров на динамическое количество очередей. Очевидно, что при таком подходе, мы будем проседать в обработке очередей каждый раз, когда их количество будет резко увеличиваться. Кажется, что было бы неплохо, чтобы наши воркеры динамически запускались или тушились, когда это нужно. А еще было бы неплохо, чтобы это сильно не усложняло процесс выкатки нового кода. В такие моменты руки очень чешутся пойти и написать свой process manager. В дальнейшем мы так и сделали, но эта история про другое.
Подумав, мы решили, а почему бы нам в очередной раз не использовать всем знакомые и привычные инструменты. Так у нас появилась наше внутреннее API, которое работало на стандартной связке NGINX + PHP-FPM. В итоге мы можем заменить наш фиксированный пул воркеров на API, и пускай NGINX + PHP-FPM сам разруливает и управляет воркерами, а нам достаточно иметь между контрольной очередью и нашим внутренним API всего один контрольный консьюмер, который будет отправлять в нашу API идентификаторы очередей на обработку, а сама очередь будет обрабатываться в воркере, поднятом PHP-FPM.
Новая схема выглядела следующим образом: 
Выглядит красиво, однако наш контрольный консьюмер работает в одном потоке, и наше API работает синхронно. Это означает, что консьюмер будет каждый раз висеть в ожидании, пока PHP-FPM перемалывает какую-то очередь. Это нам не подходит.
Делаем наше API асинхронным
А что если бы мы могли отправить задачу на наш API, и пусть он там молотит бизнес логику, а наш контрольный консьюмер пойдет за следующей таской в контрольную очередь, после чего запульнет ее опять в API, и так далее. Сказано — сделано.
Реализация занимает пару строчек кода, а Proof of Concept выглядит следующим образом:
class Api {
public function actionDoSomething()
{
$data = $_POST;
$this->dropFPMSession();
//после того, как ответили клиенту и разорвали с ним связь, можем запустить любую тяжелую логику
//Этот код будет выполнен в постпроцессинге
}
protected function dropFPMSession()
{
ignore_user_abort(true);
// говорим что скрипт не должен прерываться если отвалился клиент
ob_end_flush(); //сбрасываем вывод буфера
flush(); //сбрасываем системный буфер
@session_write_close(); //закрываем сессию
fastcgi_finish_request();
//говорим клиенту что его запрос выполнен и рвем с ним соединение
}
}В методе dropFPMSession () мы рвем соединение с клиентом, отдавая ему ответ 200, после чего мы можем выполнять любую тяжелую логику в постпроцессинге. Клиентом в нашем случае является контрольный консьюмер. Для него важно быстро раскидать задачи из контрольной очереди в обработку на API и знать, что задача до API дошла.
Применив такой подход, мы сняли с себя кучу головной боли, связанной с динамическим управлением консьюмерами и их автоматическим масштабированием.
Масштабируемся дальше
По итогу, архитектура нашей подсистемы, стала состоять из трех слоев: Data Layer, Processes и Internal API. При этом через все потоки данных у нас проходит информация о том, к какому именно боту принадлежит обрабатываемое событие/задача. Очевидно, что мы можем использовать наш ключ/идентификатор бота для шардирования, продолжая горизонтально масштабировать нашу систему.
Если представить нашу архитектуру в виде цельного юнита, выглядеть она будет следующим образом: 
Увеличив количество таких юнитов, мы можем поставить тонкий баласировщик перед ними, который будет раскидывать наши события/задачки в нужные юниты, в зависимости от ключа шардирования. 
Тем самым мы получаем большой запас по горизонтальному масштабированию нашей системы.
При реализации бизнес-логики стоит не забывать про концепцию thread safety, иначе можно получить неожиданные результаты.
Такая схема с каскадами очередей и выносом тяжелой бизнес-логики в асинхронный процессинг у нас применяется в нескольких частях системы больше двух лет. Нагрузка за это время на каждую из подсистем выросла в десятки раз, а предложенная реализация позволяет нам легко и быстро масштабироваться. При этом мы продолжаем работать на своем основном стеке, не расширяя его новыми инструментами/языками и не увеличивая, тем самым накладные расходы на внедрение и поддержку новых инструментов.
