Облака на службе СМИ, или Как Amazon помогает обрабатывать большие объемы видеоконтента
Нашему заказчику, одному из крупнейших мировых издательств, потребовалось увеличить производительность приложения для публикации видео новостей в связи с возросшим объемом трафика. Пользователи приложения — редакторы media-ресурсов. В день через него проходит порядка 200 новостных роликов, средний размер каждого из них ~ 500 мб, итого около 100 Гб свежих новостей в сутки.
Сегодня мы поделимся опытом, как CloudFront и S3 помогли нам построить высоконагруженную и устойчивую систему обработки контента.

Надеемся, наш опыт заинтересует разработчиков/проектировщиков систем по хранению и обработке медиаконтента (видео, аудио, изображения) и технических специалистов, активно использующим сервисы AWS.
Определимся с инструментами и терминологией
Amazon Web Services предлагает набор сервисов для хранения и доставки контента, а их использование становится неотъемлемой частью современных IT платформ.
Предыстория — что мы выяснили?
Для создания видео новости редакторы, используя web интерфейс, загружают исходный видеофайл и заполняют форму с метаданными (описание, ключевые слова, тэги, категории и т. п.). После этого загруженная информация отправляется на обработку (конвертация видео в разные форматы, генерация субтитров и т. д.) в том числе при помощи сторонних сервисов.

Проанализировав архитектуру системы, мы выявили следующие узкие места:
#1 Проблема загрузки большого объема данных из разных точек земного шара
Систему используют редакторы из разных точек земного шара, а оригинальный видеоконтент имеет, как правило, весьма большой объем (сотни Mb для 10 минутного ролика). Процесс передачи данных, а стало быть и время их обработки и публикации, зависит от удаленности редактора от сервера приложений.
#2 Проблема нагрузки сервера
Загружаемое редакторами видео первым шагом попадает на сервер, где развернуто приложение. Далее нам требуется перекодировать это видео в различные форматы, добавить для него субтитры. Для этого мы используем сторонние сервисы обработки видео. Работа с каждым сервисом проходит по следующей схеме:
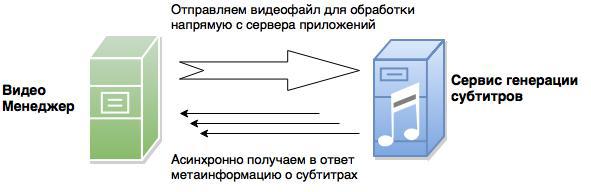
Соответственно, для прохода полного цикла обработки видео (а следовательно и создания видео новости) требуется осуществить несколько итераций передачи видео. Суммарно это выливается в гигабайты трафика и снижает возможность сервера оперативно обрабатывать несколько подобных запросов в силу ограничений по объему передачи данных в единицу времени.
Что мы сделали?
В первую очередь, мы перешли к поиску решения проблемы нагрузки сервера. Для уменьшения объема передаваемой информации решили перенести хранение и раздачу контента на плечи сторонних файловых хранилищ или сервисов.
Мы рассматривали сервисы, которые удовлетворяли бы следующим основным критериям:
возможность стороним системам забирать контент на обработку;
возможность ограничивать доступ до контента как по времени, так и по ссылкам;
Первым основным кандидатом для нас стал AWS S3, который позволяет использовать подписанные урлы (детали → docs.aws.amazon.com/AmazonS3/latest/API/sigv4-post-example.html).
С использованием S3 процесс обработки контента сторонними сервисами меняется. Приложение теперь отправляет только ссылку на контент, сторонняя система забирает его самостоятельно из S3 по подписанной ссылке.

Но в нашем случае такой вариант не подходил, так как не решалась задача ускорения загрузки данных в хранилище.
Следующей альтернативой стал CDN CloudFront. В отличие от других популярных CDN, он позволяет, используя http-методы POST, PUT, DELETE, управлять контентом на S3, т.е. фактически CDN становится полноценной оберткой для своего источника-хранилища. CloudFront шлёт данные по оптимизированным маршрутам, использует постоянные соединения TCP / IP и ускоряет доставку контента (aws.amazon.com/ru/about-aws/whats-new/2013/10/15/amazon-cloudfront-now-supports-put-post-and-other-http-methods).
Как видим, схема работы с сервисами обработки контента остается практически такой же, что и в случае с S3.
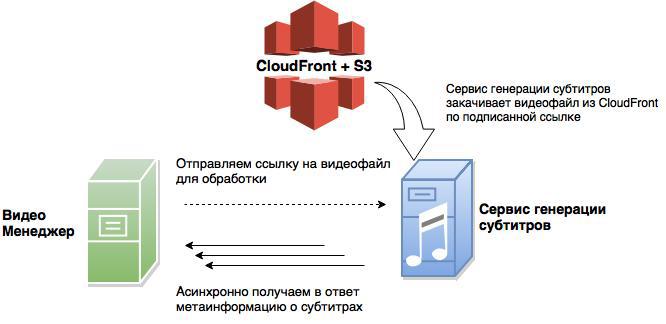
Но для пользователей системы все стало значительно лучше: контент загружается на ближайший CloudFront сервер быстрее, чем напрямую в хранилище S3.

Таким образом, мы убиваем сразу двух зайцев: быстрая загрузка данных и их сохранение напрямую в AWS S3, минуя сервер приложения и файловую систему.
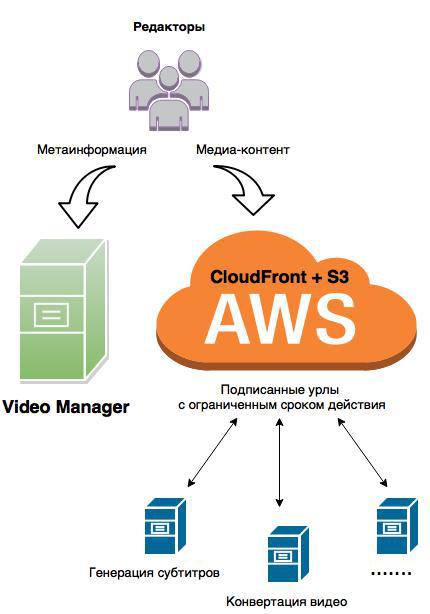
В результате реструктуризации получаем следующую систему:
- приложение видео-менеджер работает непосредственно только с метаданными;
- исходные видеофайлы сохраняются напрямую с пользовательского интерфейса на S3 через CloudFront;
- сторонние сервисы, которым нужен видеоконтент, получают его по подписанным ссылкам
через CloudFront.
Технические детали
Несколько ключевых моментов по конфигурации S3 и CloudFront
Конфигурация S3
Настройка CORS
*
GET
POST
PUT
*
Настройка CloudFront
Настраиваем два distribution CloudFront’a на наш целевой S3-бакет. Первый нужен только для загрузки контента.
Ключевые конфигурации:
Origin Settings
Restrict Bucket Access - Yes;
Allowed Http Methods - GET, HEAD, OPTIONS, PUT, POST, PATCH, DELETE;
Default Cache Behavior Settings
Restrict Viewer Access (Use Signed URLs) - Yes;
Trusted Signer - Self
Второй настраиваем для отдачи:
Origin Settings
Restrict Bucket Access - Yes;
Allowed Http Methods - GET, HEAD;
Default Cache Behavior Settings
Restrict Viewer Access (Use Signed URLs) - Yes;
Trusted Signer - Self
Интеграция с приложением
Работа на стороне пользователя
Для того чтобы новая схема взаимодействия заработала, пришлось решить несколько интеграционных задач.
Популярные загрузчики контента используют multipart/form-data, который не получится использовать с CloudFront, т.к. он не разбирает тело запроса, а сохраняет его как есть. Пришлось немного модифицировать плагин angular-file-upload (на проекте используется в основном AngularJS): для загрузки файла методом PUT использовали xhr.send (Blob) (детали тут → dvcs.w3.org/hg/xhr/raw-file/tip/Overview.html#the-send%28%29-method).
Как выяснилось, загруженные таким образом файлы по умолчанию доступны AWS системе только для псевдо-пользователя cloudfront-identity и не доступны по подписанным урлам. Мы начали искать способ настроить права доступа для загружаемых файлов на AWS. Пришлось штудировать документацию и экспериментировать, т.к. в сети подобной информации крайне мало. В итоге установили, что права при загрузке файлов через CloudFront настраиваются http-заголовками S3 docs.aws.amazon.com/AmazonS3/latest/dev/acl-overview.html.
Пример кода
Мы использовали angular-file-upload для загрузки файлов
Определяем FileUploader:
$scope.videoUploader = new FileUploader({
autoUpload: true,
method: "PUT",
useDirectUpload: true, // а это наша кастомизация для FileUploader - используем html5 XmlHttpRequest загрузка без FormData
headers: {
'x-amz-acl': 'authenticated-read' // тот самый magic header (http://docs.aws.amazon.com/AmazonS3/latest/dev/acl-overview.html)
}
});
Определяем handler для генерации конечной ссылки загрузки на cloudfront:
$scope.videoUploader.onBeforeUploadItem = function(item) {
$.ajax({
url: "base-url.com/file/generateUploadUrl", // генерируем подписанный урл для загрузки на CloudFront
type: 'GET',
data: {fileName: item.file.name, fileSize:item.file.size},
async: false,
success: function(data) {
item.url = data.uploadUrl; // выставляем аплоадеру полученный урл
}
});
};
Определяем handler успешного окончания загрузки
$scope.videoUploader.onSuccessItem = function (item, response, status, headers) {
if (200 <= status && status < 300) {
… // некие действия, например, шлем серверу подтверждение загрузки файла.
}}
На сервере
Чтобы получить подписанную ссылку на скачивание файла, используем стандартный класс из AWS SDK com.amazonaws.services.cloudfront.CloudFrontUrlSigner .
Сгенерированные ссылки мы отдаём пользователям для заливки файлов на s3 или сервисам для их скачивания.
Пример кода
public class CloudFrontConfig {
/**
* for example http://get.example.cf.com/ or http://put.example.cf.com/
*/
private String cloudFrontDomainNameForGet;
private String cloudFrontDomainNameForPut;
private String cloudFrontPrivateKey;
private String cloudFrontKeyPairId;
public String getDownloadUrlForUser(String s3key) throws Exception {
return getSignedURL(cloudFrontDomainNameForGet, s3key);
}
public String getPutUrlForService(String s3key) throws Exception {
return getSignedURL(cloudFrontDomainNameForPut, s3key);
}
private String getSignedURL(String domain, String s3Key) throws Exception {
PrivateKey privateKey = loadPrivateKey(cloudFrontPrivateKey);
Date dateLessThan = getDateLessThan();
String url = CloudFrontUrlSigner.getSignedURLWithCannedPolicy(domain + s3Key,
cloudFrontKeyPairId, privateKey, dateLessThan);
return url;
}
private Date getDateLessThan() {
LocalDateTime dateNow = LocalDateTime.now();
ZonedDateTime zdt = dateNow.plusDays(1).atZone(ZoneId.systemDefault());
return Date.from(zdt.toInstant());
}
private PrivateKey loadPrivateKey(String cloudFrontPrivateKey) {
// конструируем объект PrivateKey с помощью приватного ключа
}
}
Что мы получили в результате?
Редакторы издательства остались довольны обновленной системой: по их словам, она стала работать намного быстрее, что позволило ускорить выпуск новостей.
По статистике от AWS мы получили:
- уменьшение входящего трафика на сервер с 3Tb до 1 Gb в месяц;
- уменьшение исходящего трафика с сервера с 12Tb до 1 Gb в месяц;
- размер используемой файловой системы уменьшился с 500Гб до 2Гб.
В итоге:
- Мы оптимизировали загрузку и управление доступом к контенту посредством использования S3 и CloudFront;
- Снизили сетевую и файловую нагрузку на сервере;
- Написали статью :)
