О проблемах нормальной оценки фич и как их решить

Привет. Давайте я расскажу вам о своем опыте в оценке программных продуктов. Я занимаюсь этим без перерывов уже 15 лет, и мне бы хотелось поделиться опытом и эволюцией моих взглядов на оценку. Уверен, что это будет полезно. Начнем с целеполагания. Зачем вообще оценивать? Кому это надо?
Ответ на самом деле очень простой — людям хочется определенности, в частности ответа на вопрос «когда будет готово?». Когда мне можно в отпуск, когда начнутся продажи, когда делать связанную задачу. С другой стороны — мало ли что люди хотят, почему из-за чужих желаний тратить свое время на это занятие?
Но, в конечном счете, нам всем бы хотелось получать зарплату, а зарплата не из воздуха появляется, ее компания берет из выручки, в отдельном случае — из инвестиций. А чтобы эта самая выручка была, нам надо достигать бизнес-цели. А люди, которые формулируют бизнес-цели очень любят всякие финансовые формулы — ROI, LTV и прочая EBITDA. А в этих формулах постоянно фигурируют сроки. Без них крокодил не ловится, не растет кокос.
Есть еще и вторая причина, чуть менее важная: если понятны оценки по фичам, то это влияет на их приоритетность, более простые задачи имеют тенденцию получать более высокий приоритет. Так как в общепринятом аджайл-подходе бэклог регулярно перетряхивается, то входная информация об оценках задач помогает сделать процесс переприоретизации эффективнее.
Как следствие: скорее всего, оценивать все же придется. Смиритесь.
А теперь поговорим о том, как это сделать, чтобы не проклясть все и всех в процессе. Как обычно оценивают люди, которые не умеют оценивать ИТ-шные штуки? Вот так:
- Оцениваем всю работу в человекоднях.
- Добавляем 10% на всякий случай.
- Делим на количество разработчиков.
- Прибавляем получившееся количество дней к текущей дате и получаем итоговую дату.
- Вот и все.
У меня от этого до сих пор перед глазами мелькают вьетнамские флэшбэки из заглавной картинки: слишком много моих нервов погибло на этой войне. И у вас погибнет если вы начнете так оценивать. Проблема в том, что именно такую оценку от вас и ожидают:
«Ты не выделывайся со своими сторипоинтами, ты рукой покажи».
С какими проблемами предстоит столкнуться во время оценки
Начнем с идеальной ситуации:
- У нас есть атомарная (простая, неделимая) задача.
- У нее нет зависимостей от других задач, не надо ничего согласовывать.
- На задачу есть на 100% выделенный человек, который знает, как ее делать.
Даже в таком случае встает вопрос «Кто будет делать оценку?». В этот момент запускается неумолимая машина управления. Сначала менеджер думает: если это будет делать разработчик — что ему помешает указать огромные трудозатраты чтобы повалять дурака? → Поэтому менеджер оценивает задачу сам. → Однако менеджер недостаточно глубоко разбирается в теме и не видит (или не хочет видеть) подводные камни. → Оценка оказывается непоправимо заниженной. → Команда не укладывается в срок. → Смерть и тлен.

Вышеописанная ситуация — это классическая проблема корпоративной культуры недоверия к своим сотрудникам. Однако у большинства разработчиков есть внутренняя мотивация решать интересные задачи, для них это намного привлекательнее, чем валять дурака за компьютером, так что для повального недоверия нет оснований. Вообще, компанию надо строить исходя из презумпции доверия своим сотрудникам, а не корежить нормальные бизнес-процессы под паршивых овец.
Культура недоверия очень часто встречается в связке с корпоративной культурой страха: даже если задачу оценивает разработчик, то что происходит у него в голове во время оценки? Он отвечает на вопрос: «А как в моей компании реагируют на несоответствие планируемых сроков и фактических?». Если за проваленные сроки задач разработчика ругают — он будет их завышать. Если за сделанные раньше срока задачи дальнейшие оценки разработчика будут срезать, то он не будет сдавать задачи заранее.
Новейший пример культуры страха — релиз игры Cyberpunk 2077. Игра вышла в отвратительном качестве на консолях прошлого поколения. СЕО компании в своем заявлении сказал, что «как оказалось, во время тестирования не были обнаружены многие проблемы, с которыми вы столкнулись в игре». Что, разумеется, тотальная ложь. Проблемы были видны невооруженным глазом, тестеры физически не могли такое пропустить. Это типичная ситуация для культуры страха: проблемы замалчиваются. Так информация по пути до верхнего этажа менеджмента превратилась из «игра неиграбельна на базовых консолях» в «давайте релизить».
Если это не ваш случай, то можно оценивать дальше. Если же вам с культурой в компании не повезло — дальше не читайте, ведь вам надо выдавать оценки не для точности, а для минимизации пинков от начальства, а это — совершенно другая задача.
И вот вы дали оценку, например — 1 неделя. Это всего лишь ваше предположение, не более. Оценка определяет запланированный срок завершения задачи, но не может определять время ее фактического завершения. Где конкретно будет фактическое время завершения задачи — описывается нормальным распределением. Пока просто запомним это как аксиому, в конце будет сюжетный поворот.
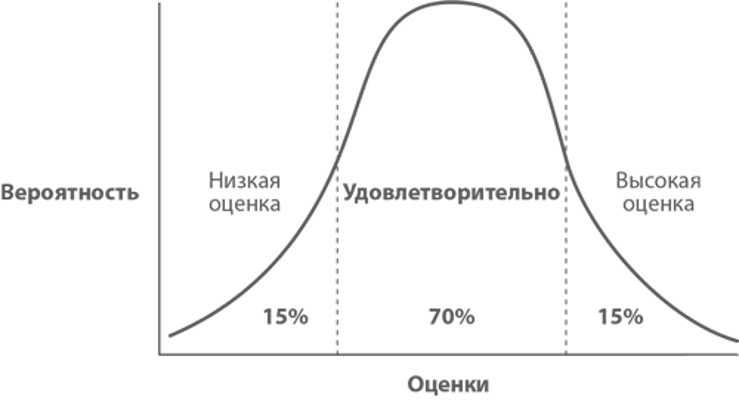
Все дополнительно усложняется тем, что некоторые задачи принципиально не делятся на части, а также бывает так, что их нельзя распараллелить. Еще существуют взаимозависимые задачи, нужно погружаться в контекст задач. Плюс, при разработке команде надо общаться, чтобы синхронизировать свою деятельность.
А еще мы не умеем видеть будущее. Как следствие постоянно возникают задачи, которые мы не предусмотрели, да и не могли предусмотреть. Что это может быть?
- Хотелки клиентов или Product Owner«a.
- Внезапные проблемы, под которые надо что-то доработать.
- Неожиданный legal.
- И тонны всего прочего.
Самое непредсказуемое — проблема разной скорости разработчиков.
У реальных разработчиков одного уровня и с одной зарплатой производительность может отличаться на порядок:
- Кто-то неделю будет пилить и отлаживать код, а кто-то за полдня прикрутит открытую библиотеку.
- Кто-то будет курить Stack overflow, а кто-то уже решал такие задачи и сходу начнет приносить пользу.
В итоге наша гауссиана превращается во что-то такое (так же выглядит оценка, когда задача недостаточно отгрумлена):

В общем, все сложно, мы тут не траншеи роем. Как же сделать хорошую оценку в таких условиях?
Критерии хорошей оценки:
- Высокая скорость оценки — сама по себе оценка не несет какой-либо бизнес-ценности, поэтому логично сделать ее как можно быстрее, чтобы не отвлекаться от разработки.
- Оценка — это ответственность всей команды, есть хороший принцип «ты оценил — ты и делай», который защищает команду от оценок, взятых с потолка.
- Не забываем про все составляющие вывода фичи в прод — аналитику, разработку, юнит-тесты, автотесты, интеграционные тесты, девопс. Все это надо оценивать.
Как видите, я ничего не написал про точность. За те 15 лет, что я занимаюсь оценками, я так и не научился делать их точно, поэтому давайте будем скромнее и попробуем оценивать хотя бы примерно. Весь процесс оценки выглядит так:
- Набираем задачи в бэклог продукта.
- Оцениваем самые высокоприоритетные стори в бэклоге любым методом (методов много, про них ниже расскажу).
- Начинаем работать (например, по скраму — спринтами).
- После нескольких спринтов меряем сколько стори поинтов у нас получается в среднем каждую итерацию. Это наша Velocity — усредненная скорость разработки команды.
- Оцениваем весь бэклог. Теперь у нас появляется достаточно информации чтобы можно было нарисовать burndown chart. Точка пересечения с осью абсцисс в идеальном мире показала бы, когда мы закончим.

Но мир не идеален, поэтому фиксируем, сколько новых фич (тоже оцененных в сторипоинтах) генерит наш Product Owner каждый спринт. Красная линия покажет разрастание бэклога, теперь пересечение красной и синей линии — нужная дата.
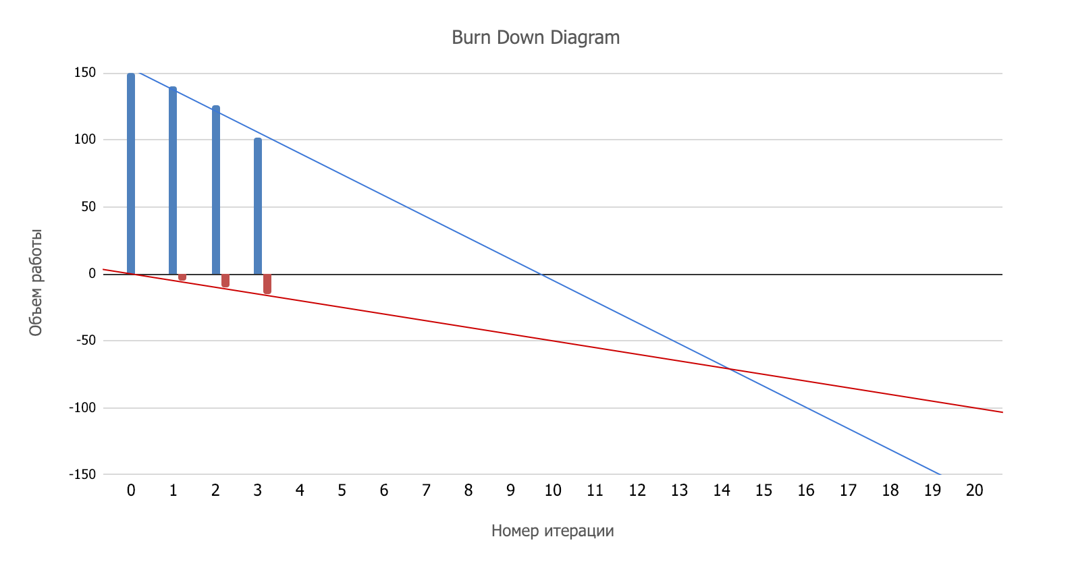
Если Product Owner очень креативый, то может быть даже так:

А теперь вспоминаем, что оценка подчиняется законам нормального распределения, а вот и сюжетный поворот — такие гауссианы отлично складываются. Поэтому получается вот что (это называется enchanced burndown chart):
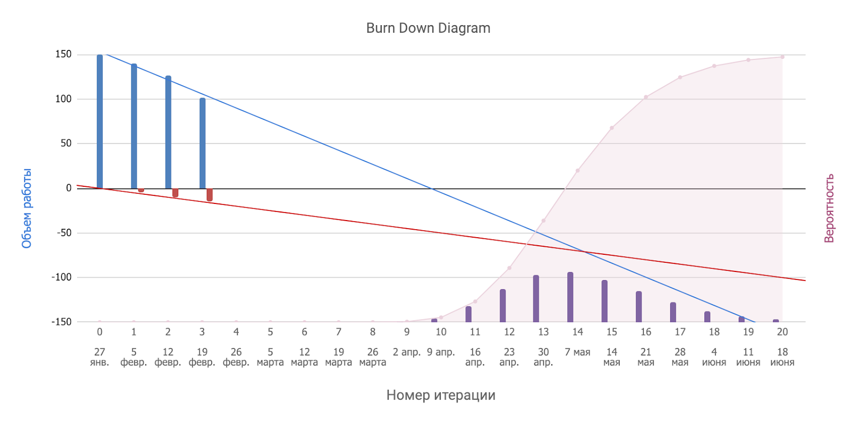
Казалось бы, сбылась мечта юного математика: из кучи хаоса мы получили красивый график и можем с умным видом вещать что «с 50% вероятностью мы закончим в 14 спринте, с 80% вероятностью — в 17-м, с 95% — в 19-м».
Во всем этом процессе есть ряд подводных камней.
Во-первых, сразу скажу про слона в комнате: бэклог большой, в нем куча задач, про которых неизвестно ничего кроме описания в формате user story, поэтому оценка будет очень приблизительная в любом случае. Как на языке математики выглядит приблизительная оценка я уже выше показывал.
Во-вторых, проблема «разработчики работают с разной продуктивностью» никак не решается в принципе. А значит, у нас получается очень пологое нарастание вероятности, которое мало помогает принимать управленческие решения: «с 50% вероятностью мы закончим в 14 спринте, с 80% вероятностью — в 27-м, с 95% — в 39-м» — так на языке математики звучит «пальцем в небо».
Поэтому лично я максимизирую метрику «скорость оценки» и сейчас расскажу вам методы, которые пробовал.
Метод «Покер планирования»
Это одна из самых популярных техник оценки, наверное, потому что самая старая.
- Участники процесса используют специально пронумерованные числами Фибоначчи карты.
- Product Owner делает краткий анонс очередной стори и отвечает на вопросы команды.
- После получения информации участники «покера» выбирают карту с подходящей, по их мнению, оценкой и никому не показывают.
- Потом все вместе вскрываются, и участники с самыми низкими и высокими оценками дают краткие комментарии, объясняя свой выбор оценки.
- В итоге процесса обсуждения команда приходит к единому решению, после чего переходит к следующей стори.
В течение часовой сессии таким способом можно оценить от 4 до 8 историй. Это и самая большая проблема данного метода — он долгий, люди скучают и отвлекаются. Я не зря употребил фразу «все вместе вскрываются».
Метод «выстраивания порядка»
Это тот подход, который мы используем сейчас на работе. Смысл в том, чтобы оценивать задачи друг относительно друга. Так выстраивается последовательность отсортированных по сложности задач. Для этого метода надо предварительно накопить пул оцененных задач и разместить их на шкале.
- Когда наступает время оценки, каждый участник команды по очереди совершает свой ход (как в настолке). Ходы могут быть такими: поставить таск на шкалу, передвинуть таск по шкале, обсудить историю с коллегами, пропустить свой ход.
- В результате, задачи постоянно перемещаются по доске, их оценка друг относительно друга уточняется, пока не получится состояние, удовлетворяющее всю команду.
- Когда все участники пропускают свой ход — готово.
Это быстрая техника. С ее помощью можно оценить 15–20 историй в час, чего обычно вполне достаточно.
Метод «Большой/маленький/непонятный»
Пользовался несколько раз, но не прижилось.
- На доске отмечаются 3 зоны: «большой таск», «малый таск» и «недостаточно информации».
- Команда проводит групповое обсуждение нескольких первых задач, определяясь с терминами «большой/маленький». Я настаиваю на толковании термина «маленькая задача» = «может сделать один человек в спринт».
- После этого все юзерстори индивидуально вешаются на доску в нужные зоны.
У метода огромный плюс — он супербыстрый. Так можно обработать по 50 пользовательских историй в час.
Тут возникает проблема с трансляцией этих оценок в стори поинты, но когда уже известна velocity команды, то мы понимаем сколько сторипоинтов пережует человек за спринт и в Jira и оцениваем маленькие задачи вокруг этой метрики.
Что касается остальных задач. Я отправлял таски из области «недостаточно информации» в аналитику, а задачи из «большой таск» — на декомпозицию, чтобы на следующей сессии оценить их заново.
В итоге у нас в продукте мы просто рисуем роадмап с фичами которые, как нам кажется, мы успеем написать в ближайшее время. Если не успеваем — ну, так бывает. А оценками пользуемся только для ближайших задач, которые мы нормально отгрумили, да и то, не всегда.
Возможно, я занимаюсь тем, что закидываю свою некомпетентность в области оценки наукообразными терминами, но лично для меня сам процесс выглядит довольно стремно, как странный карго-культ, в который мы играем, чтобы сделать вид, что мы такая же стабильная и предсказуемая индустрия, как какая-то другая на самом деле стабильная и предсказуемая индустрия. Я бы с удовольствием почитал про ваш опыт в этой сфере, может, я что-то упускаю.
