Нужно больше датасетов. Музыка, IT-скилы и котики

Привет, Хабр! Совсем недавно мы писали про открытый датасет, собранный командой студентов магистратуры «Наука о данных» НИТУ МИСиС и Zavtra.Online (подразделение SkillFactory по работе с университетами) в рамках первого учебного Дататона. А сегодня представим вам целых 3 датасета от команд, которые также вышли в финал.
Все они разные: кто-то исследовал музыкальный рынок, кто-то — рынок труда IT-специалистов, а кто-то и вовсе домашних кошек. Каждый из этих проектов актуален в своей сфере и может быть использован для того, чтобы что-то усовершенствовать в привычном ходе работы. Датасет с котиками, например, поможет судьям на выставках. Датасеты, которые необходимо было собрать студентам, должны были представлять собой MVP (таблица, json или структура каталогов), данные должны быть очищены и проанализированы. Посмотрим же, что у них получилось.
Датасет 1: Скользим по музыкальным волнам с «Data Surfers»
Состав команды:
- Плотников Кирилл — project manager, разработка, документация.
- Тарасов Дмитрий — разработка, сбор данных, документация.
- Шадрин Ярослав — разработка, сбор данных.
- Мерзликин Артём — product manager, презентация.
- Колесниченко Ксения — предварительный анализ данных.
В рамках участия в хакатоне участниками команды было предложено несколько различных интересных идей, но мы решили остановиться на сборе данных о российских музыкальных исполнителях и их лучших треках с ресурсов Spotify и MusicBrainz.
Spotify — музыкальная платформа, пришедшая в Россию не так давно, но уже активно захватывающая популярность на рынке. Кроме того, с точки зрения анализа данных, Spotify предоставляет очень удобное API с возможностью запроса большого количества данных, в том числе их собственных метрик, например таких, как «danceability» — показатель от 0 до 1, описывающий, насколько трек подходит для танцев.
MusicBrainz — это музыкальная энциклопедия, содержащая максимально полную информацию о существующих и существовавших музыкальных коллективах. Своего рода «музыкальная википедия». Данные с этого ресурса нам были необходимы для того, чтобы получить список всех исполнителей из России.
Сбор данных об артистах
Мы собрали целую таблицу, содержащую 14363 уникальных записи о различных исполнителях. Чтобы в ней было удобно ориентироваться — под спойлером описание полей таблицы.
musicbrainz_id — уникальный идентификатор артиста в музыкальной базе данных Musicbrainz;
spotify_id — уникальный идентификатор артиста в стриминговом сервисе Spotify, если он там представлен;
type — тип исполнителя, может принимать значения Person, Group, Other, Orchestra, Choir или Character;
followers — количество подписчиков артиста на Spotify;
genres — музыкальные жанры артиста;
popularity — индекс популярности артиста на Spotify от 0 до 100, который рассчитывается на основе популярности всех треков артиста.

Пример записи
Поля artist, musicbrainz_id и type извлекаем из музыкальной базы данных Musicbrainz, так как там есть возможность получить список артистов, связанных с одной страной. Извлечь эти данные можно двумя способами:
- Постранично парсить раздел Artists на странице с информацией о России.
- Достать данные через API.
Документация MusicBrainz API
Документация MusicBrainz API Search
Пример запроса GET на musicbrainz.org
В ходе работы выяснилось, что API MusicBrainz не совсем корректно отвечает на запрос с параметром Area: Russia, скрывая от нас тех исполнителей, у кого в поле Area указано, например, Izhevsk или Moskva. Поэтому данные с MusicBrainz были взяты парсером непосредственно с сайта. Ниже пример страницы, откуда парсились данные.
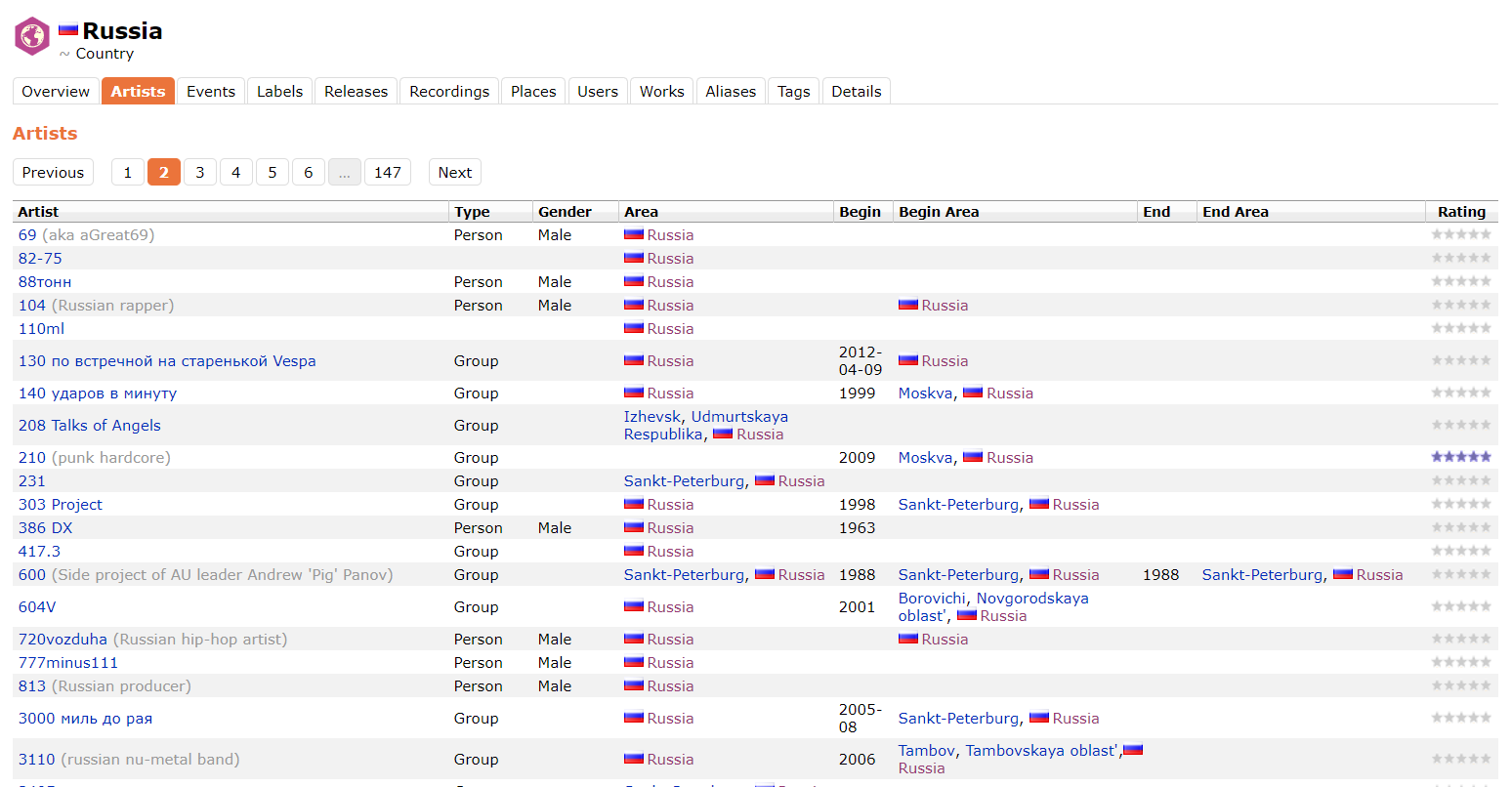
Полученные данные об артистах из Musicbrainz.
Остальные поля получаем в результате GET запросов к эндпоинту. При отправке запроса в значении параметра q указываем имя артиста, а в значении параметра type указываем artist.
Сбор данных о популярных треках
Таблица содержит 44473 записи о самых популярных треках российских артистов, представленных в таблице выше. Под спойлером описание полей таблицы.
artist_spotify_id — уникальный идентификатор артиста в стриминговом сервисе Spotify (по нему можно будет джойнить таблицы, так как это spotify_id из таблицы с артистами);
name — название трека;
spotify_id — уникальный идентификатор трека в стриминговом сервисе Spotify;
duration_ms — длительность трека в миллисекундах;
explicit — содержит ли текст трека нецензурные выражения, может принимать значения true или false;
popularity — индекс популярности трека на Spotify *;
album_type — тип альбома, может принимать значения album, single или compilation;
album_name — название альбома;
album_spotify_id — уникальный идентификатор альбома в стриминговом сервисе Spotify;
release_date — дата выхода альбома;
album_popularity — индекс популярности альбома на Spotify.
mode — указывает модальность трека, мажор — 1, минор — 0;
time_signature — предполагаемый общий тактовый размер композиции;
acousticness — мера достоверности от 0,0 до 1,0 того, является ли трек акустическим;
danceability — описывает, насколько трек подходит для танцев от 0,0 до 1,0;
energy — представляет собой перцептивную меру интенсивности и активности от 0,0 до 1,0;
instrumentalness — определяет, содержит ли трек вокал, принимает значения от 0,0 до 1.0;
liveness — определяет присутствие аудитории при записи, принимает значения от 0,0 до 1,0;
loudness — общая громкость трека в децибелах, типичный диапазон значений от -60 до 0 дБ;
speechiness — определяет наличие произнесённых слов в треке, принимает значения от 0,0 до 1,0;
valence — описывает музыкальную «позитивность», передаваемую треком, принимает значения от 0,0 до 1,0;
tempo — предполагаемый общий темп трека в ударах в минуту.
Подробно о каждом параметре можно прочитать здесь.

Пример записи
Поля name, spotify_id, duration_ms, explicit, popularity, album_type, album_name, album_spotify_id, release_date получаем с помощью GET запроса на https://api.spotify.com/v1//v1/artists/{id}/top-tracks , указывая в качестве значения параметра id Spotify ID артиста, который мы получили ранее, а в значении параметра market указываем RU. Документация.
Поле album_popularity можно получить, сделав GET запрос на https://api.spotify.com/v1/albums/{id}, указав album_spotify_id, полученный ранее, в качестве значения для параметра id. Документация.
В результате получаем данные о лучших треках артистов из Spotify. Теперь задача — получить особенности аудио. Сделать это можно двумя способами:
- Для получения данных об одном треке нужно сделать GET-запрос на
https://api.spotify.com/v1/audio-features/{id}, указав его Spotify ID как значение параметра id. Документация. - Чтобы получить данные о нескольких треках сразу, следует отправить GET запрос на
https://api.spotify.com/v1/audio-features, передавая Spotify ID этих треков через запятую как значение для параметра ids. Документация.
Все скрипты находятся в репозитории по этой ссылке.
После сбора данных мы провели предварительный анализ, визуализация которого представлена ниже.
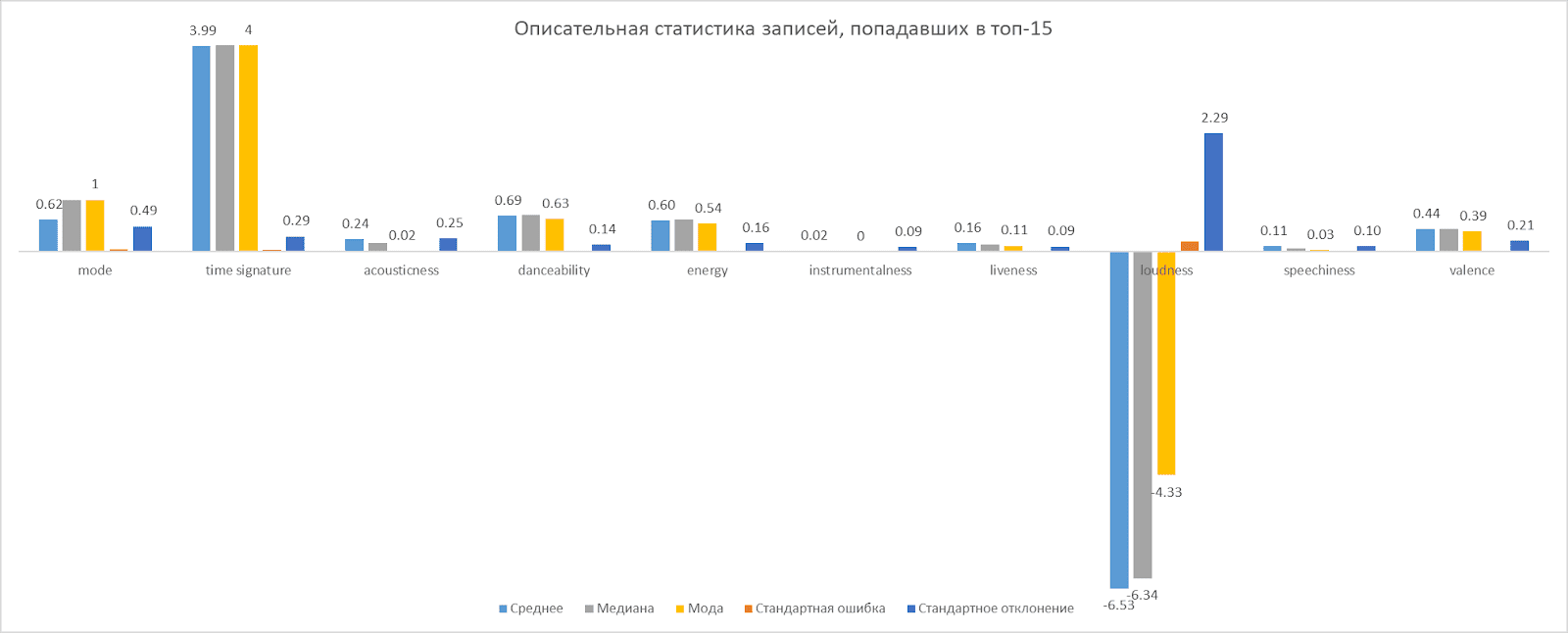
Итоги
В результате у нас получилось собрать данные по 14363 артистам и 44473 трекам. Объединив данные из MusicBrainz и Spotify, мы получили наиболее полный на текущий момент набор данных о всех российских музыкальных исполнителях, представленных на платформе Spotify.
Такой датасет позволит создавать B2B и B2C продукты в музыкальной сфере. Например, системы рекомендаций промоутерам исполнителей, концерт которых можно организовать, или системы помощи молодым исполнителям в написании треков, которые с большей вероятностью станут популярными. Также при регулярном пополнении датасета свежими данными можно анализировать различные тенденции в музыкальной индустрии, такие как формирование и рост популярности определённых трендов в музыке, либо проводить анализ отдельных исполнителей. Сам датасет можно посмотреть на GitHub.
Датасет 2: Исследуем рынок вакансий и выявляем ключевые навыки с «Ежу понятно»
Состав команды:
- Пшеничный Андрей — сбор и обработка данных, написание аналитической записки о датасете.
- Кондратёнок Павел — Product Manager, сбор данных и описание его процесса, GitHub.
- Щербакова Светлана — сбор и обработка данных.
- Евсеева Оксана — подготовка итоговой презентации проекта.
- Елфимова Анна — Project Manager.
Для своего датасета мы выбрали идею сбора данных о вакансиях в России из сферы «IT и Телеком» с сайта hh.ru за октябрь 2020 года.
Сбор данных о скилах
Самым важным показателем для всех категорий пользователей являются ключевые навыки. Однако при их анализе у нас возникли трудности: эйчары при заполнении данных о вакансии выбирают ключевые навыки из списка, а также могут вносить их вручную, а следовательно, в наш датасет попало большое количество дублирующих навыков и некорректных навыков (например, мы столкнулись с названием ключевого навыка »0,4 Кb»). Есть ещё одна трудность, которая доставила проблем при анализе получившегося датасета, — только около половины вакансий содержат данные о заработной плате, но мы можем использовать средние показатели о заработной плате с другого ресурса (например, с ресурсов Мой круг или Хабр.Карьера).
Начали с получения данных и их глубинного анализа. Далее мы произвели выборку данных, то есть отобрали признаки (features или, иначе, предикторы) и объекты с учетом их релевантности для целей Data Mining, качества и технических ограничений (объема и типа).
Здесь нам помог анализ частоты упоминания навыков в тегах требуемых навыков в описании вакансии, какие характеристики вакансии влияют на предлагаемое вознаграждение. При этом было выявлено 8915 ключевых навыков. Ниже представлена диаграмма с 10 наиболее популярными ключевыми навыками и частотой их упоминания.
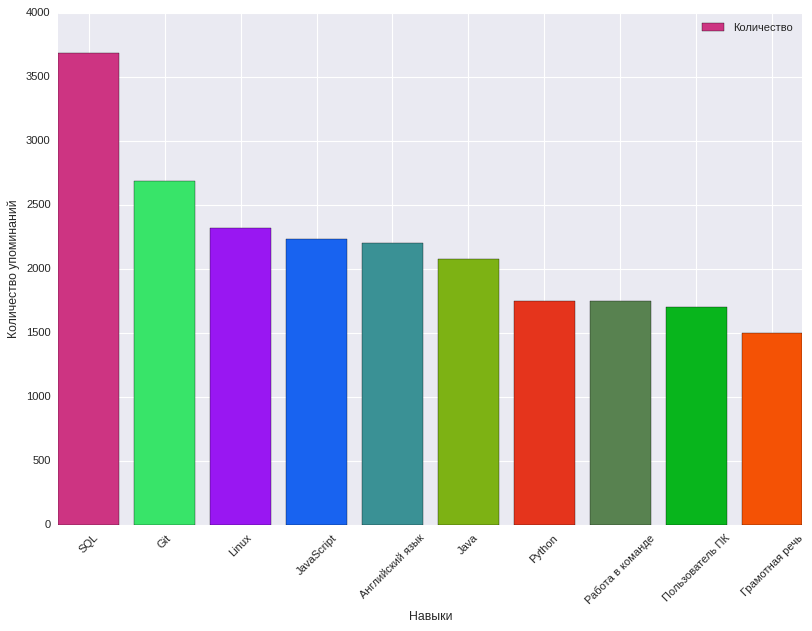
Наиболее часто встречающиеся ключевые навыки в вакансиях из сферы IT, Телеком
Данные получили с сайта hh.ru с помощью их API. Код для выгрузки данных можно найти тут. Вручную выбрали признаки, которые нам необходимы для датасета. Структуру и тип собираемых данных можно увидеть в описании документации к датасету.
После этих манипуляций мы получили Dataset размером 34 513 строк. Образец собранных данных вы можете увидеть ниже, а также найти по ссылке.

Образец собранных данных
Итоги
В результате получился датасет, с помощью которого можно узнать, какие навыки являются самыми востребованными среди IT специалистов по разным направлениям, и он может быть полезен для соискателей (как для начинающих, так и для опытных), работодателей, hr-специалистов, образовательных организаций и организаторов конференций. В процессе сбора данных были и трудности: слишком много признаков и они написаны на низкоформализируемом языке (описание навыков для кандидата), половина вакансий не имеет открытых данных о заработной плате. Сам датасет можно глянуть на GitHub.
Датасет 3: Наслаждаемся многообразием котиков с «Команда AA»
Состав команды:
- Евгений Иванов — разработка веб-скрапера.
- Сергей Гурылёв — product manager, описание процесса разработки, GitHub.
- Юлия Черганова — подготовка презентации проекта, анализ данных.
- Елена Терещенко — подготовка данных, анализ данных.
- Юрий Котеленко — project manager, документация, презентация проекта.
Датасет, посвящённый котам? Да почему бы и нет, подумали мы. Наш котосет содержит образцы изображений, на которых сфотографированы кошки различных пород.
Сбор данных о котиках
Изначально для сбора данных мы выбрали сайт catfishes.ru, он обладает всеми нужными нам преимуществами: это свободный источник с простой структурой HTML и качественными изображениями. Несмотря на преимущества этого сайта, он имел существенный недостаток — малое количество фотографий в целом (около 500 по всем породам) и малое количество изображений каждой породы. Поэтому мы выбрали другой сайт — lapkins.ru.

Из-за чуть более сложной структуры HTML скрапить второй сайт было несколько сложнее первого, но разобраться в структуре HTML было легко. В итоге нам удалось собрать со второго сайта уже 2600 фотографий всех пород.
Нам не потребовалось даже фильтровать данные, так как фотографии кошек на сайте хорошего качества и соответствуют породам.
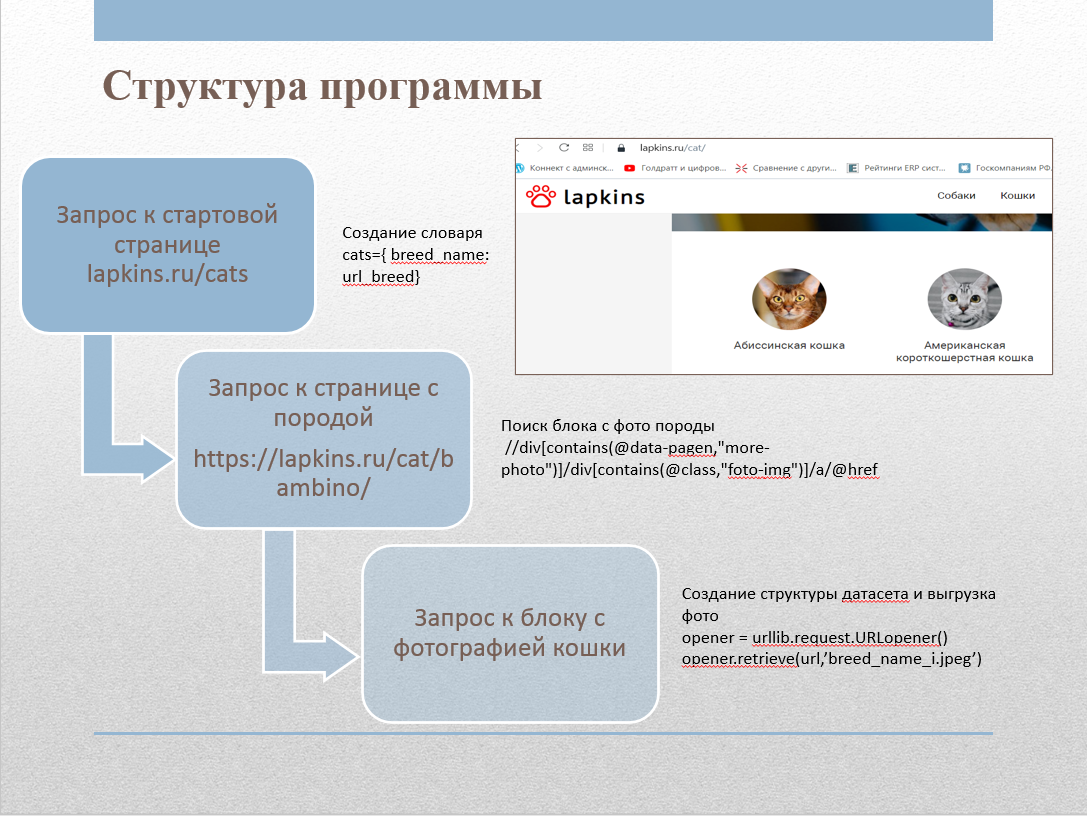
Для сбора изображений с сайта нами был написан веб-скрапер. Сайт содержит страницу lapkins.ru/cat со списком всех пород. Сделав парсинг этой страницы, мы получили названия всех пород и ссылки на страницу каждой породы. Итеративно пройдя в цикле по каждой из пород, мы получили все изображения и сложили их в соответствующие папки. Код скрапера был реализован на Python с использованием следующих библиотек:
- urllib: функции для работы с URL;
- html: функции для обработки XML и HTML;
- Shutil: функции высокого уровня для обработки файлов, групп файлов и папок;
- OS: функции для работы с операционной системой.
Для работы с тегами мы использовали XPath.
Каталог Cats_lapkins содержит папки, названия которых соответствуют названиям пород кошек. Репозиторий содержит 64 каталога для каждой породы. Всего в датасете содержатся 2600 изображений. Все изображения представлены в формате .jpg. Формат названия файлов: например «Абиссинская кошка 2.jpg», вначале идёт название породы, затем число — порядковый номер образца.

Итоги
Такой датасет может, например, использоваться для обучения моделей, классифицирующих домашних кошек по породам. Собранные данные могут быть использованы для следующих целей: определение особенностей по уходу за котом, подбор подходящего рациона для кошек определённых пород, а также оптимизация первичной идентификации породы на выставках и при судействе. Также котосет может использоваться и бизнесом — ветеринарными клиниками и производителями кормов. Сам котосет находится в свободном доступе на GitHub.
Послесловие
По итогам дататона наши студенты получили первый кейс в своё портфолио дата-сайентиста и обратную связь по работе от менторов из таких компаний, как Huawei, Лаборатория Касперского, Align Technology, Auriga, Intellivision, Wrike, Мерлин АИ. Дататон был полезен ещё и тем, что прокачал сразу и профильные хард- и софт-скилы, которые понадобятся будущим дата-сайентистам, когда они будут работать уже в реальных командах. Также это хорошая возможность для взаимного «обмена знаниями», так как у каждого студента разный бэкграунд и, соответственно, свой взгляд на задачу и её возможное решение. Можно с уверенностью сказать, что без подобных практических работ, похожих на какие-то уже существующие бизнес-задачи, подготовка специалистов в современном мире просто немыслима.
Узнать больше про нашу магистратуру можно на сайте data.misis.ru и в Telegram канале.
Ну, и, конечно, не магистратурой единой! Хотите узнать больше про Data Science, машинное и глубокое обучение — заглядывайте к нам на соответствующие курсы, будет непросто, но увлекательно. А промокод HABR поможет в стремлении освоить новое, добавив 10% к скидке на баннере.

КУРСЫ
