Новые системы хранения данных NetApp под управлением ONTAP 9.1
Во время ежегодной конференции для партнёров и заказчиков NetApp Insight было объявлено о выходе новых систем хранения данных, работающих под управлением операционной системы ONTAP. Обновились системы FAS и AFF.
Вместе с выходом нового оборудования будет доступна новая версия ONTAP — 9.1.
Для начала разберёмся, что же нового в железе.
FAS. Всем FlashCache. Первые СХД с 40GbE и 32Gb FC
Начнём с обновления гибридных массивов FAS. Выходит 4 новые модели: FAS2620, FAS2650 — системы начального уровня, FAS8200 — система среднего уровня для корпоративных заказчиков и FAS9000 — high-end система с абсолютно новым (для NetApp) подходом в построении шасси.
Новые системы стали существенно производительнее:
- Используются новые процессоры Intel на архитектуре Broadwell
- Доступно больше кэша и NVRAM
- NVMe FlashCache
- В старших контроллерах доступны интерфейсы 40GbE и 32Gb FC
- Для подключения дисков используется SAS-3 12Gb
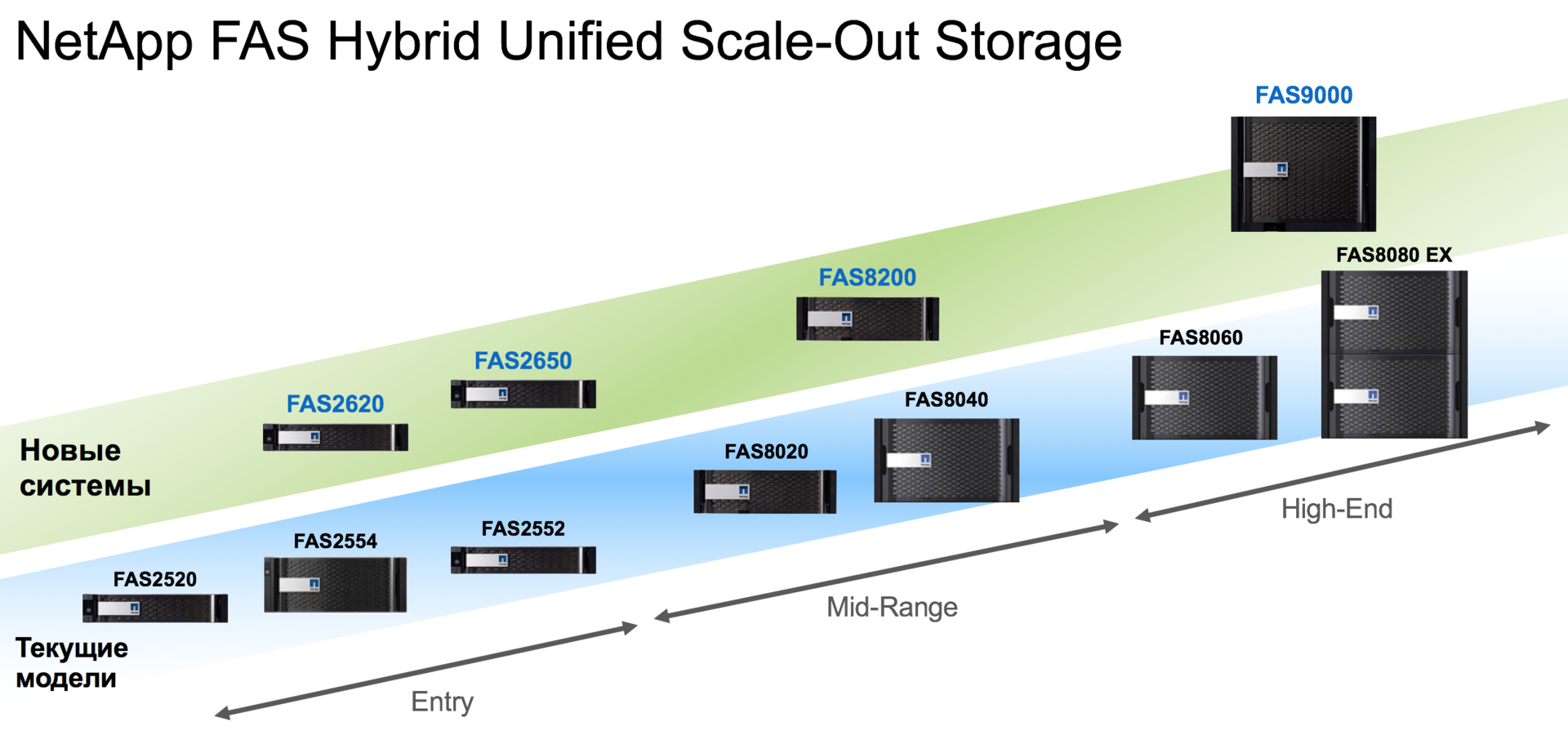
Как видно, моделей стало меньше, что вполне логично при возможности горизонтального масштабирования. Клиенты, которым будет не хватать FAS8200, а FAS9000 покажется слишком производительной, могут брать 4-контроллерные кластеры из FAS8200.
FAS2600

Теперь в младшей линейке две модели. FAS2620 заменяет FAS2554, а FAS2650 — FAS2552. Модели аналогичной урезанной в функциональности FAS2520 теперь нет. И это вполне логично, в моей практике эти модели продавались очень редко.
FAS2620 и FAS2650, как и прошлое поколение, используют одинаковые контроллеры. Отличаются только шасси. В первом случае это шасси на 24 SAS или SSD дисков. А FAS2620 имеет шасси на 12 дисков SATA или SSD.
Обе эти системы конвертируются в дисковые полки для подключения к новым контроллерам в случае апгрейда на старшие модели. Только полки теперь DS224C и DS212C. Это полки с 12Gb SAS интерфейсом. Принцип наименования остался прежний — Disk Shelf, количество юнитов, количество дисков и скорость интерфейса. C — 12 в hex. При желании новые полки можно подключить к текущим контроллерам FAS8000. Надо всего лишь приобрести соответствующий SAS HBA. В новых полках ACP не требует отдельных портов и работает внутри SAS.
Новые системы обещают быть в 3 раза быстрее поколения FAS2500:
- 2 шестиядерных процессора на основе микроархитектуры Intel Broadwell
- 64GB DDR4 памяти
- 8GB NVRAM
- 1TB NVMe M.2 FlashCache
Да-да-да! FlashCache на младших моделях, еще и NVMe, и в базовой конфигурации.
Увеличились максимальные лимиты на общее количество кэша на контроллерах на основе FlashPool и FlashCache до 24TiB.

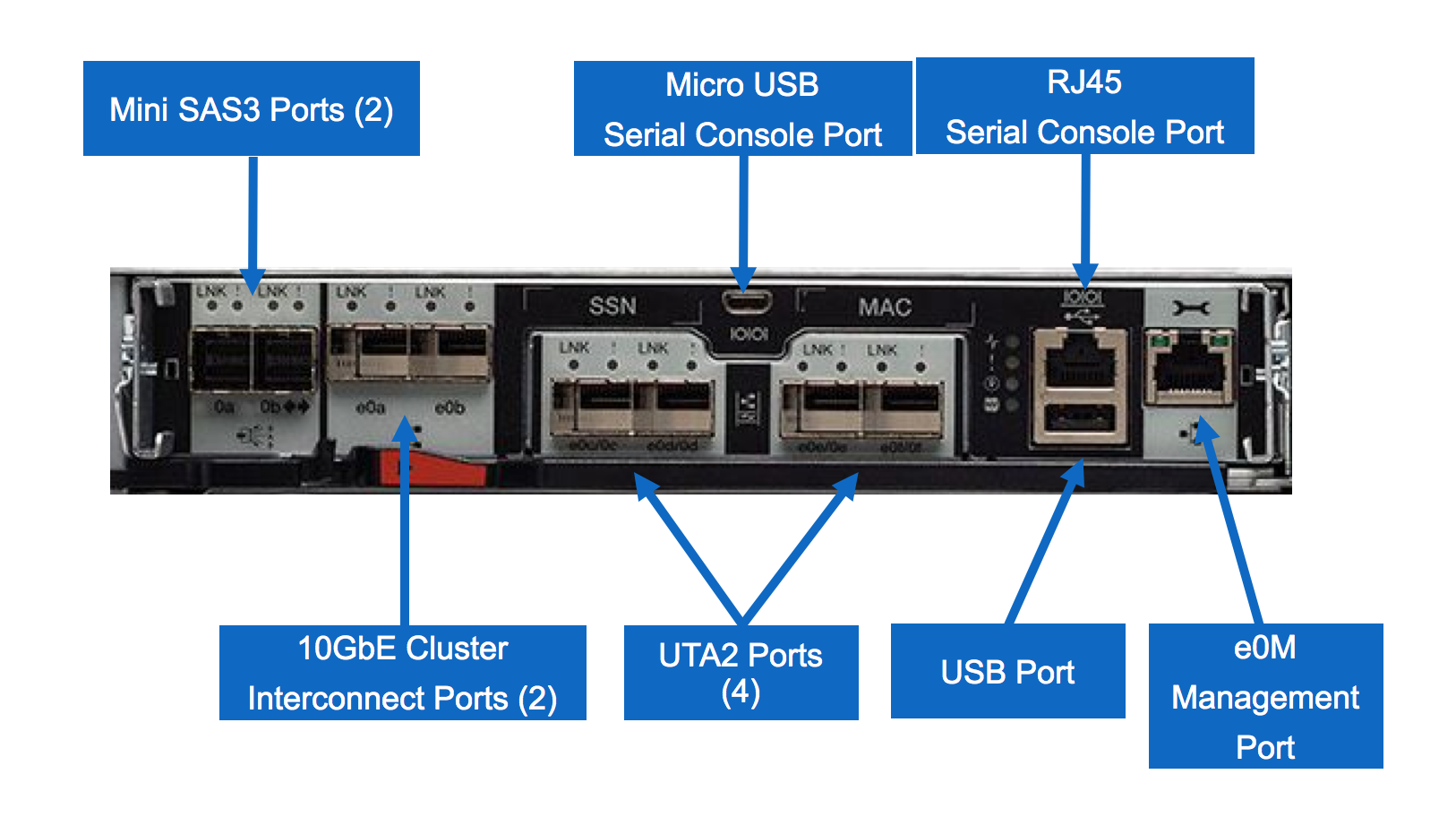
Наконец-то, есть выделенные 10GbE порты для кластерного интерконекта. И нет необходимости чем-то жертвовать для получения конфигурации iSCSI/NFS/CIFS/FCoE + FC.
Теперь содержимое NMRAM в случае потери питания шифруется и записывается на загрузочную флешку.
Из нюансов: FAS2620 не будет доступна в конфигурации all-SSD. Необходимо иметь минимум 8 SATA дисков. FAS2650 таких ограничений не имеет.
FAS8200

FAS8200 пришла на замену сразу двум моделям текущего поколения — FAS8020 и FAS8040. Пара контроллеров FAS8200 находится в одном корпусе и занимает всего 3U. Дисков в этом шасси нет. Обещают прирост производительности по сравнению в FAS8040 около 50%:
- В 2 раза больше ядер
- В 4 раза больше памяти
- 2 TiB NVMe FlashCache в базе с возможностью расширения до 4TiB


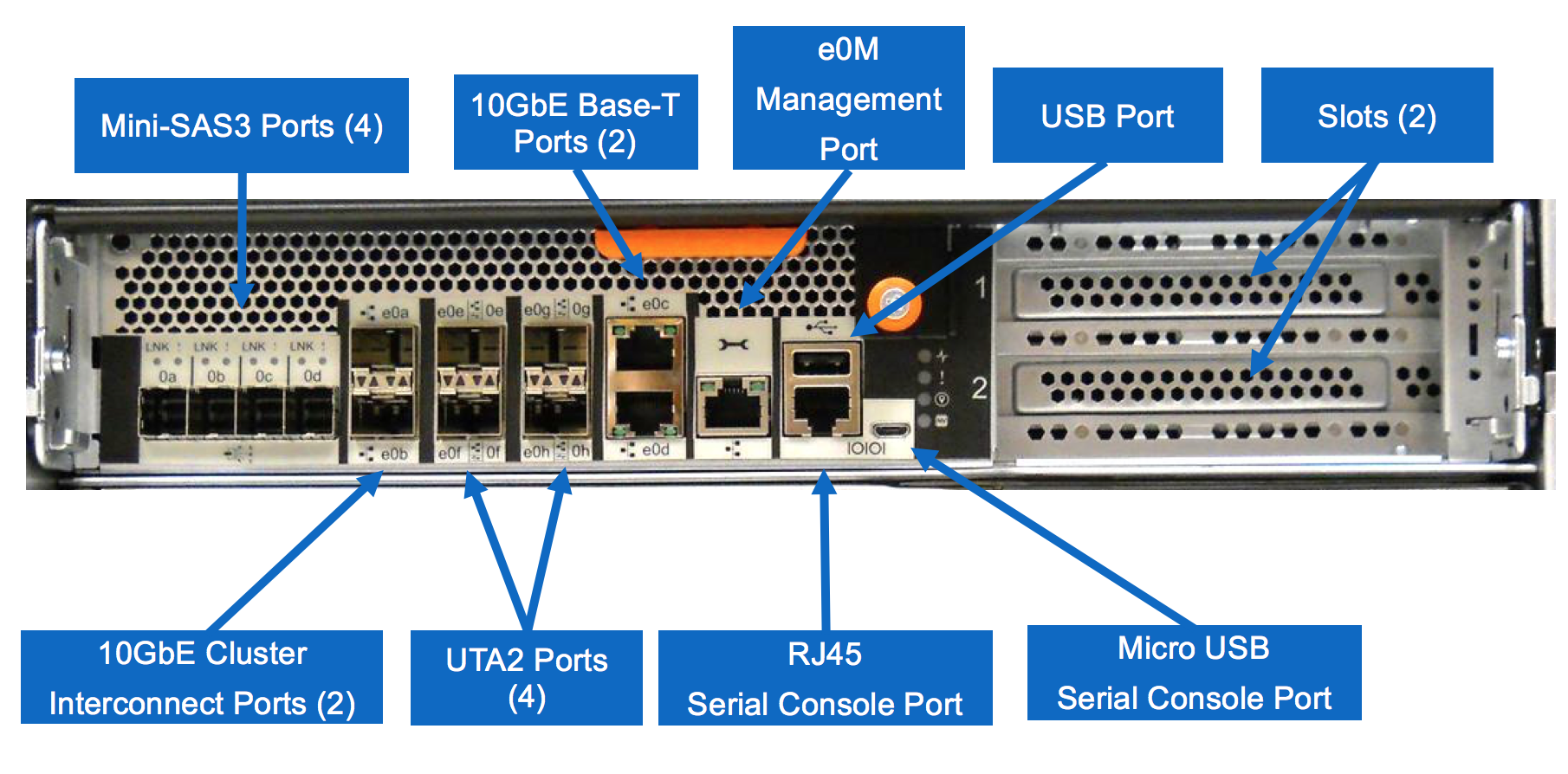
И что же мы имеем? Контроллеры мощнее и занимают меньше места. Но в контроллерах меньше слотов расширения и они поддерживают меньше дисков. Но всё не так плохо.
Разберёмся сначала с дисками.
По статистике более 80% продаж FAS8040 идут с менее чем 150 дисками, то есть реальной необходимости в поддержке 720 дисков у целевой аудитории FAS8200 нет. Если лимит в 480 дисков кого-то беспокоит, то всегда можно добавить в кластер еще пару контроллеров и максимальное количество дисков увеличится до 960.
Что же делать с меньшим количеством слотов расширения? Слоты расширения в 8040 часто используются под FlashCache, который в FAS8200 теперь на материнской плате и слоты под него не нужны. Дополнительные слоты нужны при построении MetroCluster для плат FC-VI, через которые происходит зеркалирование NVRAM на удалённую площадку. Теперь для этих целей можно использовать уже имеющиеся на контроллере порты UTA2. Дисков поддерживается 480, так что нет необходимости занимать слоты SAS HBA картами.
Получается слоты нужны только для портов Ethernet или FC, если базовых портов на контроллере не хватает. И тут мы вспоминаем, что теперь в ONTAP 9.1 NetApp поддерживает использование портов 40GbE и 32Gb FC. Порты 40GbE могут использоваться в качестве 4 по 10GbE. 40GbE порты поддерживаются только в новых контроллерах, а карты 32Gb FC будут доступны и для текущего поколения FAS/AFF.
Порты 10GbE Base-T переехали с контроллеров FAS2520 на FAS8200:) Их можно использовать для кластерного интерконекта и для клиентских подключений. И они поддерживают работу на скорости 1GbE.
FAS9000

Ну, а теперь поговорим про монстра, который пришёл на замену FAS8060 и FAS8080 EX.
В текущем поколении вся линейка FAS80×0 делит одну архитектуру шасси. В FAS9000 применили новый подход, который упрощает обслуживание и расширение.
Но начнём с технических характеристик и сравнения с FAS8080 EX.
Прирост производительности по сравнению с FAS8080 EX 50% за счёт:
- 72 ядер — 4 процессора по 18 ядер
- 1024GB DDR4 памяти — в 4 раза больше
- В два раза больше NVRAM
- 2TiB NVMe FlashCache, расширение до 16TiB
- Зеркалирование NVRAM с пропускной способностью в 80Gb/sec

Ну, а теперь самое интересное — вид сзади:

Новый модульный дизайн. Контроллеры не имеют клиентских портов. Контроллеры и модули расширения поддерживают горячую замену. Благодаря тому, что модули расширения теперь «живут» отдельно от контроллера, при их замене нет необходимости производить failover и нет сложностей с кабелями из других модулей. И самое интересное, что это шасси позволяет в будущем заменить контроллеры FAS9000 на новые.
Несмотря на меньшее количество слотов и отсутствие портов на самих контроллерах, масштабируемость по подключению клиентов не страдает. FlashCache использует отдельные слоты. Поддерживаются порты 40GbE и 32Gb FC. Кстати, для кластерного интерконекта теперь используются 40GbE порты.
AFF A300 и AFF A700
Разобрались с FAS, переходим к all-flash системам. All-flash моделей теперь две и они немного поменяли способ именования.
Самые догадливые конечно поняли, что для AFF систем используется та же самая железная платформа, что и для FAS8200 и FAS9000. Поэтому подробно расписывать технические характеристики я не буду, остановлюсь только на некоторых из них.
- A300 даёт на 50% больше производительности при задержках 1 мс, чем AFF8040
- Поддерживает до 384 SSD
Доступны SSD 15.3TB, 3.8TB и 960GB
- A700 выдаёт в два раза больше производительности, при задержках в два раза ниже, чем AFF8080
- Поддерживает до 480 SSD
- Доступны SSD 15.3TB, 3.8TB и 960GB
Ну и конечно обе модели поддерживают интерфейсы 40GbE, 32Gb FC. А теперь поговорим немного про производительность.
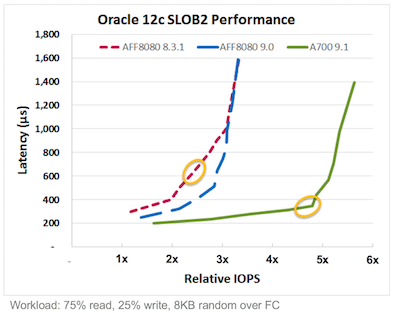
Такого прогресса не достичь простым обновлением железной платформы. С выходом ONTAP 9.1 NetApp первым начал начал поддерживать технологию Multi-Stream Write для SSD. Изначально эту технологию разработали в Sаmsung. В конце 2015 эта технология стала частью стандарта T10 SCSI. Она также будет в стандарте NVMe.
Multi-stream SSD
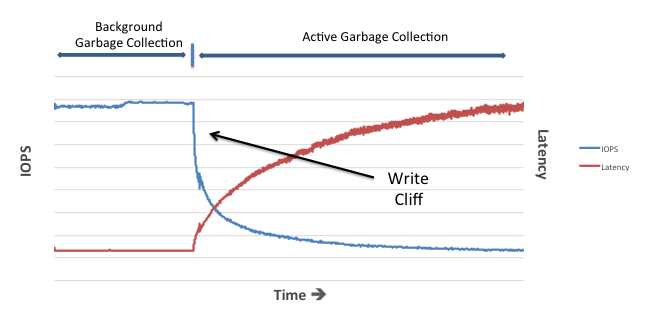
Что это за технология? Для начала немного общеизвестной информации. Всем известно, что запись на SSD сильно отличается от записи на HDD. SSD по сути не имеет такой операции как перезапись. При изменении каких-то данных необходимо стереть старые данные и заново записать измененные данные. Проблема в том, что чтение и запись в пустое место происходит с гранулярностью страницы, а вот при удалении необходимо стирать блок, который состоит из нескольких страниц. Это всем известные P/E циклы (Program/Erase). Всё это ведёт к уменьшению срока службы SSD и снижению производительности на запись при заполнении диска.
Срок службы снижается, так как NAND-ячейки рассчитаны на определенное количество P/E циклов. Что касается производительности, контроллер SSD старается писать изменение данных в пустые страницы. Периодически для очистки блоков с устаревшими данными запускается Garbage Collector, который освобождает блоки. Пока есть свободные страницы для записи новых и измененных данных, GC работает в фоне и особо не влияет на производительность. Но при достижении определенной степени наполненности диска, GC начинает работать более активно, и производительность SSD на запись существенно снижается. SSD приходится производить больше операций, чем на него приходит со стороны хоста. Это называется Write Amplification. На графике производительности SSD виден типичный write cliff.
В Samsung решили классифицировать данные, которые идут со стороны хоста. Данные ассоциируются с определенным потоком. В один поток попадают данные, которые с высокой вероятностью будут одновременно изменяться или удаляться. Данные из разных потоков пишутся в разные блоки на SSD.

Такой подход позволяет увеличить долговечность SSD, повышает производительность и обеспечивает стабильные задержки. По внутренним тестам Samsung технология multi-stream write вполовину снижает write amplification, endurance вырастает до 3 раз, задержки в большинстве случаев снижаются на 50%.
Всё это теперь доступно в AFF системах NetApp c ONTAP 9.1.
Подробнее о Multi-stream SSD можно узнать из следующих презентаций и доклада:
Презентация «The Multi-streamed Solid State Drive» — Jeong-Uk Kang, Jeeseok Hyun, Hyunjoo Maeng, and Sangyeun Cho
Доклад USENIX «The Multi-streamed Solid-State Drive» — Jeong-Uk Kang, Jeeseok Hyun, Hyunjoo Maeng, and Sangyeun Cho
Презентация «Multi-Stream Write SSD Increasing SSD Performance and Lifetime with Multi-Stream Write Technology» — Changho Choi, PhD
ONTAP 9.1
Что еще нового в следующей версии ONTAP? Поддержка FlexGroups. Это масштабируемые файловые контейнеры, которые могут хранить до 20PB и 400 млрд файлов. Одна FlexGroup может располагаться на нескольких контроллерах в кластере, при этом при записи файлов кластер автоматически балансирует нагрузку. Поддерживаются NFS и SMB. Подробнее про FlexGroups.
Поддержка шифрования данных без специальных self-encrypting дисков и внешних менеджеров ключей. NetApp Volume Encryption (NVE). Шифрование происходит на уровне тома. То есть можно выбирать какие тома шифровать, а какие нет. Для каждого тома используется отдельный ключ шифрования. Шифрование происходить в программном модуле встроенном в ONTAP, используются hardware acceleration на уровне процессоров Intel. При этом сохраняется польза от всех технологий эффективности NetApp. WAFL отрабатывает до того как данные будут зашифрованы.
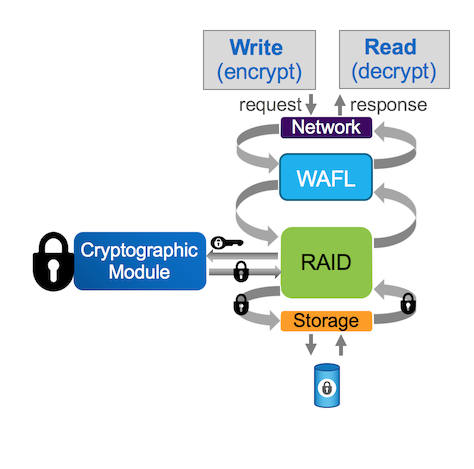
Поддерживается работа в MetroCluster. Есть возможность реплицировать данные из незашифрованных томов на другую систему в шифрованные тома. Поддерживается ONTAP Select. А параноики могут использовать два способа шифрования: NVE и шифрование на уровне NSE дисков. К сожалению, это всё будет недоступно в России. Будет использоваться два разных образа ONTAP — с поддержкой NVE и без.
ONTAP Select теперь поддерживает конфигурации all-flash. А ONTAP Cloud официально заработал в MS Azure.
Ну и самое главное для кластеров с использованием SAN-протоколов увеличен лимит по количеству контроллеров в кластере. Теперь такие кластеры могут состоять из 12 нод или 6 пар контроллеров. Так что все технические характеристики и лимиты контроллеров, про которые я написал, можно умножать на 6 или на 12, если будут использоваться только файловые протоколы.
Комментарии (3)
 navion
navion
28 сентября 2016 в 22:58
0↑
↓
<традиционное брюзжание>Только заказчикам приехали последние акционные железки прошлого поколения, как представили новые кладущие их на лопатки и с Flash Pool в базе скидка в 60% не кажется такой большой.А если серьёзно, то откуда такая огромная разница в NFS? Старые системы совсем дохлые или обычные диски сравнивали с новыми флешпулами?
 Smasher
Smasher
28 сентября 2016 в 23:14
+1↑
↓
Придёт время расширять кластер и туда можно будет добавить уже новые железки.
А если серьёзно, то откуда такая огромная разница в NFS?
Тяжело что-то конкретное ответить. Возможно тестировали pNFS, а он сильно лучше параллелится :)
Как вариант, что старые системы тестировали без FlashCache, а новые в базе идут с NVMe FlashCache. Что даёт очень существенный прирост производительности для файловых нагрузок, при большом объеме работ с метаданными. Метаданные хорошо кэшируются.
Ну и не понятно соотношение чтения/записи. Графики производительности FC странные, так как в многих TR результаты получались выше.
Больше всего конечно порадовал прирост производительности при последовательных операциях.Хотя стоит дождать публикации более серьёзных документов.
 mikkisse
mikkisse
29 сентября 2016 в 08:19
0↑
↓
Спасибо за статью. Очень хороший обзор.
