NoVerify: линтер для PHP от Команды ВКонтакте теперь в открытом доступе

Расскажу, как нам удалось написать линтер, который получился достаточно быстрым, чтобы проверять изменения во время каждого git push и делать это за 5−10 секунд при кодовой базе в 5 миллионов строк на PHP. Мы назвали его NoVerify.
NoVerify поддерживает базовые вещи вроде перехода к определению и поиску использований и умеет работать в режиме Language Server. В первую очередь наш инструмент ориентирован на поиск потенциальных ошибок, но умеет проверять и стилистику. Сегодня его исходные коды появились в open-source на GitHub. Ищите ссылку в конце статьи.
Зачем нам свой линтер
В середине 2018 года мы решили, что пора внедрять линтер для PHP-кода. Цели было две: уменьшить количество ошибок, которые видят пользователи, и строже следить за соблюдением code style. Основной упор при этом мы сделали на предотвращение типичных ошибок: наличия в коде необъявленных и неиспользуемых переменных, недостижимого кода и других. Также хотелось, чтобы статический анализатор работал максимально быстро на нашей кодовой базе (5−6 миллионов строк кода на PHP на момент написания статьи).
Как вы, вероятно, знаете, исходный код большей части сайта написан на PHP и компилируется с помощью KPHP, поэтому логично было бы добавить эти проверки в компилятор. Но на самом деле не весь код имеет смысл выполнять через KPHP — например, компилятор слабо совместим со сторонними библиотеками, так что для некоторых частей сайта до сих пор используется обычный PHP. Они тоже важны и должны проверяться линтером, поэтому, к сожалению, нет возможности встроить его в KPHP.
Почему NoVerify
Учитывая объем PHP-кода (напомню, это 5−6 миллионов строк), не представляется возможным «исправить» его сразу, чтобы он проходил наши же проверки в линтере. Тем не менее хочется, чтобы меняющийся код постепенно становился чище и строже следовал стандартам кодирования, а также содержал меньше ошибок. Поэтому мы решили, что линтер должен уметь проверять изменения, которые разработчик собирается запушить, и не ругаться на остальное.
Чтобы это сделать, линтеру нужно проиндексировать весь проект, полностью проанализировать файлы до изменений и после и посчитать разницу между сгенерированными предупреждениями. Новые предупреждения показываются разработчику, и мы требуем их исправить перед тем, как можно будет сделать push.
Но бывают ситуации, когда такое поведение нежелательно, и тогда разработчики могут выполнить push без локальных хуков — с помощью команды git push --no-verify. Опция --no-verify и дала название линтеру :)
Какие были альтернативы
Кодовая база в VK мало использует ООП и в основном состоит из функций и классов со статическими методами. Если классы в PHP поддерживают autoload, то функции — нет. Поэтому мы не можем без существенных модификаций использовать статические анализаторы, которые основывают свою работу на том, что autoload загрузит весь недостающий код. К таким линтерам относится, например, psalm от компании Vimeo.
Мы рассмотрели следующие инструменты статического анализа:
- PHPStan — однопоточный, требует autoload, анализ кодовой базы дошел до 30% за полчаса;
- Phan — даже в quick-режиме с 20 процессами анализ застопорился на 5% через 20 минут;
- Psalm — требует autoload, анализ занял 10 минут (всё равно хотелось бы намного быстрее);
- PHPCS — проверяет стиль, но не логику;
- phpcf — проверяет только форматирование.
Как можно догадаться из заголовка статьи, ни один из этих инструментов не удовлетворяет нашим требованиям, поэтому мы написали свой.
Как создавался прототип
Сначала мы решили построить небольшой прототип, чтобы понять, стоит ли вообще пытаться сделать полноценный линтер. Поскольку одно из важных требований к линтеру — это скорость его работы, вместо PHP мы выбрали Go. «Быстро» — это давать фидбэк разработчику как можно оперативнее, желательно не более чем за 10−20 секунд. В противном случае цикл «поправить код, прогнать линтер ещё раз» начинает существенно замедлять разработку и портить настроение людям :)
Поскольку для прототипа выбран Go, нужен парсер PHP. Таких существует несколько, но наиболее зрелым нам показался проект php-parser. Этот парсер не идеален и всё ещё дорабатывается, но для наших целей он вполне подошёл.
Для прототипа было решено попробовать реализовать одну из самых простых, на первый взгляд, инспекций: обращение к неопределённой переменной.
Основная идея для реализации такой инспекции выглядит просто: для каждого ветвления (например, для if) создаём отдельную вложенную область видимости и объединяем типы переменных на выходе из неё. Пример:
Выглядит просто, не так ли? В случае обычных условных операторов всё работает хорошо. Но мы должны обрабатывать, например, switch без break;
По коду не сразу понятно, что $c будет на самом деле определена всегда. Конкретно этот пример — выдуманный, но он хорошо иллюстрирует, какие бывают сложные моменты для линтера (и для человека в данном случае тоже).
Рассмотрим более сложный пример:
Не зная сигнатуру функции exec, нельзя сказать, будут ли определены $out и $retval. Сигнатуры встроенных функций можно взять из репозитория github.com/JetBrains/phpstorm-stubs. Но те же проблемы будут при вызове пользовательских функций, а их сигнатуру можно узнать, только проиндексировав весь проект. Функция exec принимает второй и третий аргументы по ссылке, а значит переменные $out и $retval могут быть определены. Здесь обращение к этим переменным — не обязательно ошибка, и линтер не должен ругаться на такой код.
Аналогичные проблемы с неявной передачей по ссылке возникают с методами, но заодно добавляется необходимость выводить типы переменных:
some_method($b);
echo $b;
Мы должны знать, какие типы возвращают функции some_func () и other_func (), чтобы потом найти метод под названием some_method в этих классах. Только тогда сможем сказать, будет переменная $b определена или нет. Ситуацию осложняет то, что зачастую у простых функций и методов нет phpdoc-аннотаций, поэтому нужно ещё уметь вычислять типы функций и методов, исходя из их реализации.
При разработке прототипа пришлось реализовать примерно половину всей функциональности, чтобы простейшая инспекция заработала как надо.
Работа в качестве language server
Чтобы было легче отлаживать логику линтера и проще видеть предупреждения, которые он выдаёт, мы решили добавить режим работы в качестве language server для PHP. В режиме интеграции с Visual Studio Code это выглядит примерно так:
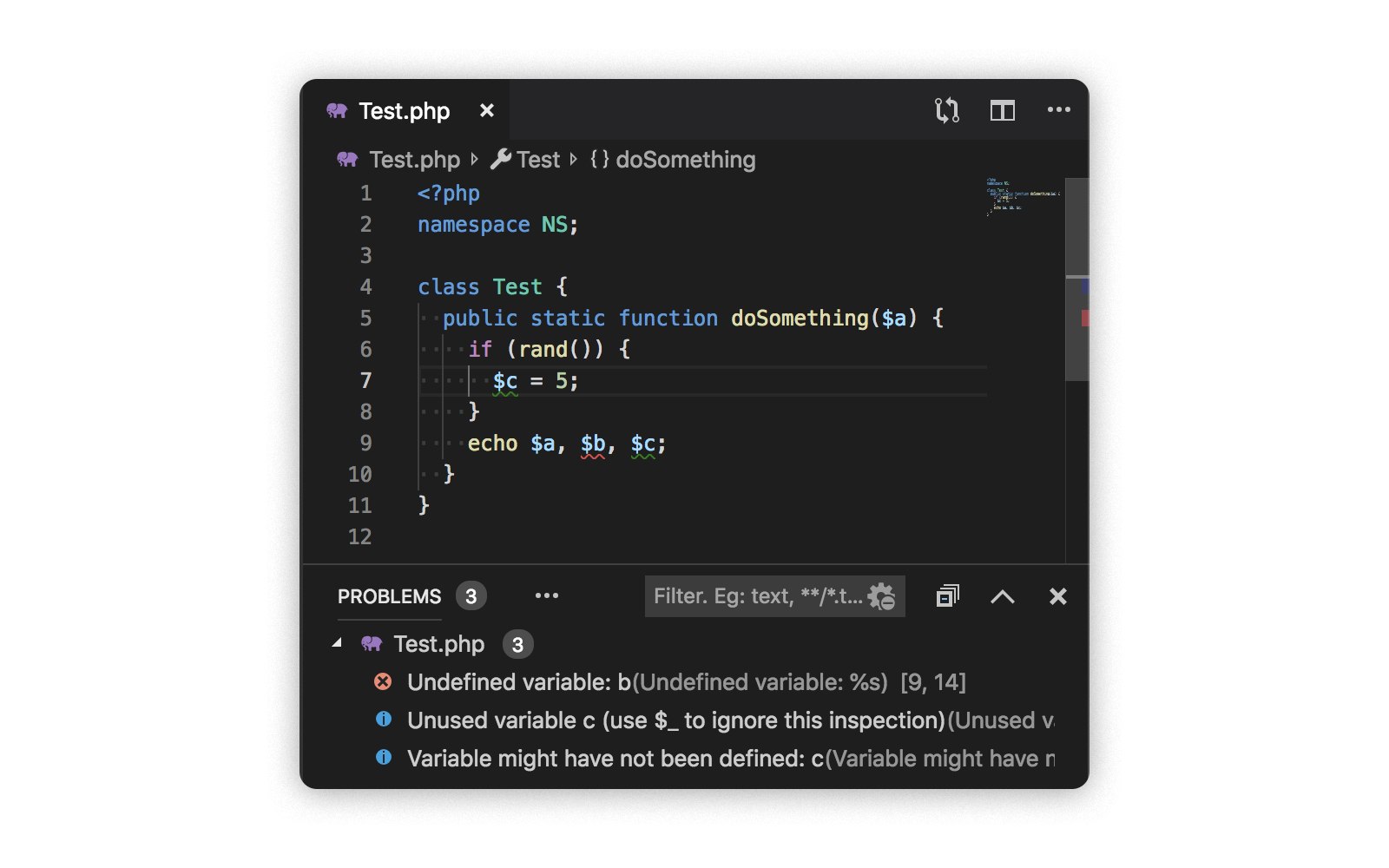
В таком режиме удобно тестировать гипотезы и проверять сложные случаи (после этого надо написать тесты, конечно). Также хорошо тестировать производительность: даже на больших файлах php-parser на Go показывает неплохую скорость работы.
Поддержка language server далека от идеала, поскольку её основное предназначение — отладка правил линтера. Тем не менее в этом режиме есть несколько дополнительных возможностей:
- Подсказки для имён переменных, констант, функций, свойств и методов.
- Подсветка выведенных типов переменных.
- Переход к определению.
- Поиск использований.
«Ленивый» вывод типов
В режиме language server требуется, чтобы работало следующее: вы меняете код в одном файле, и потом, когда переключаетесь на другой, должны работать с уже обновлённой информацией о том, какие типы возвращаются в функциях или методах. Представьте, что файлы редактируются в такой последовательности:
prop;
}
}
// Файл C.php, не меняется
$c = B::something();
// $c имеет тип int
// Файл A.php, версия 2
class A {
/** @var string <--- теперь тут string */
public $prop;
}
// Файл C.php, не меняется
$c = B::something();
// $c это теперь string, хотя ни B.php, ни C.php не менялись
Учитывая, что мы не заставляем разработчиков всегда писать PHPDoc (особенно в таких простых случаях), нужен способ хранить информацию о том, какой тип возвращает функция B: something (). Чтобы, когда изменится файл A.php, в файле C.php информация о типах сразу была актуальной.
Одно из возможных решений — хранить «ленивые типы». Например, тип возвращаемого значения у метода B: something () на самом деле представляет собой тип выражения (new A)→prop. В таком виде линтер и хранит информацию о типе, и благодаря этому можно закешировать всю метаинформацию по каждому файлу и обновлять её, только когда этот файл изменится. Делать это нужно осторожно, чтобы нигде случайно не просочилась слишком конкретная информация о типах. Ещё необходимо изменять версию кеша, когда меняется логика вывода типов. Тем не менее такой кеш ускоряет фазу индексации (о которой расскажу позже) в 5−10 раз по сравнению с повторным парсингом всех файлов.
Две фазы работы: индексация и анализ
Как мы помним, даже для простейшего анализа кода требуется информация как минимум обо всех функциях и методах в проекте. Это означает, что нельзя проанализировать только один файл отдельно от проекта. И ещё — что это невозможно сделать за один проход: например, PHP позволяет обращаться к функциям, которые объявлены дальше в файле.
Из-за этих ограничений работа линтера состоит из двух фаз: первичная индексация и последующий анализ только нужных файлов. Теперь подробнее об этих двух фазах.
Фаза индексации
В этой фазе парсятся все файлы и делается локальный анализ кода методов и функций, а также кода на верхнем уровне (например, для определения типов глобальных переменных). Собирается информация об объявленных глобальных переменных, константах, функциях, классах и их методах и записывается в кеш. Для каждого файла в проекте кеш представляет собой отдельный файл на диске.
Из отдельных кусочков составляется глобальный словарь всей метаинформации о проекте, которая в дальнейшем уже не меняется*.
*Кроме режима работы в качестве language server, когда на каждую правку проводится индексация и анализ измененного файла.
Фаза анализа
В этой фазе мы можем пользоваться метаинформацией (о функциях, классах…) и уже непосредственно анализировать код. Вот список того, что по умолчанию умеет проверять NoVerify:
- недостижимый код;
- обращение к объектам, как к массиву;
- недостаточное количество аргументов при вызове функции;
- вызов неопределенного метода/функции;
- доступ к отсутствующему свойству класса/константе;
- отсутствие класса;
- неверный PHPDoc;
- обращение к неопределённой переменной;
- обращение к переменной, которая не всегда определена;
- отсутствие «break;» после case в конструкциях switch/case;
- ошибка синтаксиса;
- неиспользуемая переменная.
Список довольно короткий, но можно добавлять проверки, специфичные для вашего проекта.
В процессе эксплуатации линтера оказалось, что самая полезная инспекция как раз последняя (неиспользуемая переменная). Такое часто бывает, когда вы рефакторили код (или писали новый) и опечатались в названии переменной: этот код является валидным с точки зрения PHP, но ошибочным по логике.
Скорость работы
Сколько времени проверяются изменения, которые мы хотим запушить? Всё зависит от количества файлов. С NoVerify процесс может занимать до минуты (так было, когда я изменил 1400 файлов в репозитории), но если правок было немного, то обычно все проверки проходят за 4−5 секунд. За это время происходит полная индексация проекта, парсинг новых файлов, а также их анализ. У нас вполне получилось создать линтер для PHP, который работает быстро даже с нашей большой кодовой базой.
Что же в итоге?
Поскольку решение написано на Go, то требуется использовать репозиторий github.com/JetBrains/phpstorm-stubs, чтобы иметь определения всех встроенных в PHP функций и классов. Взамен мы получили высокую скорость работы (индексация 1 миллиона строк в секунду, анализ 100 тысяч строк в секунду) и смогли добавить проверки линтером в качестве одного из первых шагов в хуках для git push.
Была разработана удобная база для создания новых инспекций и достигнут уровень понимания кода, близкий к PHPStorm. Благодаря тому, что из коробки поддерживается режим работы с подсчётом диффа, есть возможность постепенно улучшать код, не допуская новых потенциально проблемных конструкций в новом коде.
Подсчет диффа не идеален: например, если один большой файл был разнесен на несколько мелких, то git, а следовательно и NoVerify, не смогут определить, что код был перемещен, и линтер будет требовать исправления всех найденных проблем. В этом плане подсчет диффа мешает проводить крупный рефакторинг, поэтому в таких случаях его зачастую отключают.
Написание линтера на Go имеет ещё одно преимущество: не только AST-парсер работает быстрее и потребляет меньше памяти, чем на PHP, но и последующий анализ тоже очень шустрый по сравнению с чем угодно, что можно было бы сделать на PHP. Это значит, что наш линтер может проводить более сложный и глубокий анализ кода, сохраняя при этом высокую производительность (например, фича «ленивые типы» требует выполнения довольно большого количества вычислений в процессе работы).
Open-source
NoVerify доступен в open-source на GitHub
Приятного использования в вашем проекте!
Юрий Насретдинов, разработчик отдела инфраструктуры ВКонтакте
