Newbie Guide: разбираемся с MVCC на простых примерах
Изоляция транзакций в СУБД — важный механизм, который позволяет пользователю получить согласованное состояние данных и работать с ними, не допуская конфликтов и снижения производительности. Организовать изоляцию нужного уровня можно несколькими способами, один из которых — MVCC (Multiversion Concurrency Control, многоверсионное управление конкурентным доступом).
Я Александр Ляпунов, руководитель группы разработки Tarantool, VK. В статье расскажу, что такое MVCC и как работает механизм в дисковых и in-memory базах данных (БД).
Статья написана по моему выступлению на HighLoad++ 2022. Вы можете посмотреть его здесь.
Что такое и зачем нужен MVCC
MVCC — механизм СУБД, который позволяет организовывать параллельный доступ к базам данных. Метод подразумевает, что каждый пользователь получает персональный снапшот, то есть копию данных. Изменения в снапшоте не видны другим пользователям до подтверждения транзакции. То есть MVCC не позволяет пишущим транзакциям заблокировать читающие, и наоборот.
Чтобы понять, как работает MVCC и зачем нужна подобная изоляция, начнем с простого бытового примера. Например, жена просит мужа сходить в магазин купить батон и, если будут яйца, взять десяток: муж покупает 10 батонов, потому что яйца в магазине были. То есть любое задание (в том числе «купи батон») можно рассматривать в качестве элементарной программы (в нашем случае составитель программы — жена, исполнитель — муж). Таких программ может быть множество, в том числе более сложных:
- если будет белый хлеб, возьми, если нет, купи половину черного;
- если будет молоко, яйца и мука — возьми (будем блины печь), но, если не будет хотя бы чего-то из списка, не бери ничего (не сможем печь блины);
- если будут чипсы со скидкой, возьми три пакета, но один — в любом случае.
Но человек — разумный исполнитель, который может решать конфликты, исходя из меняющихся обстоятельств. Например, даже если два покупателя в магазине одновременно подойдут к полке с хлебом и обнаружат, что батон всего один, один из покупателей уйдет с хлебом, а второй — с пустыми руками. В случае с программой такие ситуации критичны: она выполняет строго то, что написано в коде. Если действия на каждый сценарий в нем не прописаны подробно и заранее, операция даст сбой. По аналогии с упомянутым примером: если две программы захотят одновременно изменить один блок данных, неудачей завершатся сразу обе, а то и вообще программа перейдет в невозможное состояние.
Чтобы исключить такие ситуации, в реальном мире можно изолировать покупателей. Например, впускать в магазин, к отдельной полке или товару только по одному. Решение рабочее, но у него есть три недостатка:
- покупателей может интересовать разный товар — неоправданно ставить их в одну очередь;
- покупателей могут интересовать несколько товаров — время ожидания каждого клиента кратно увеличивается;
- появляются большие очереди на вход.
Аналогичный подход можно реализовать при работе с базами данных. Такой метод называется блокировкой: объект остается недоступным для других, пока с ним кто-то работает. Блокировать можно всю БД, таблицу, запись или их диапазон. Недостатки аналогичны магазину: риск взаимных блокировок и потенциально высокие очереди на вход. Чем больше запросов к БД, тем больше проявляются недостатки, поэтому блокировки используют ограниченно. Одним из способов разрешить эту ситуацию и является MVCC.
Как работает MVCC
MVCC нельзя реализовать в жизни, но представить можно. Очереди в магазин нет, но при входе каждый покупатель получает персональную копию магазина. Как результат, каждый может делать внутри что угодно и при этом не мешает остальным.

Ключевым звеном при таком подходе является кассир — менеджер транзакций. На выходе он проверяет, что делал покупатель, и повторяет эти действия в реально существующем магазине. Например, в реальном магазине одна бутылка молока, но в своих изолированных средах ее независимо взял и первый, и второй покупатель. При проверке кассир разрешит купить молоко первому, а второму откажет, поскольку реально была только одна бутылка и ее уже забрали раньше.
Менеджер транзакций фиксирует все действия с сохранением исходной последовательности операций. При этом уже важно состояние исходного объекта не на момент входа, а на момент подтверждения транзакции. Отклоненные транзакции нигде не фиксируются.
У использования MVCC в СУБД несколько важных преимуществ:
- можно получить изоляцию любого уровня;
- нет блокировок;
- со своей копией данных можно работать неограниченное время.
Есть и недостатки:
- риск отклонения транзакции: менеджер транзакций может найти несоответствие и попросить повторить действия после тайм-аута;
- для поддержки множества параллельных снапшотов надо много ресурсов, в первую очередь памяти и CPU;
- подход сложнее в разработке.
Но, учитывая преимущества, с недостатками можно мириться.
Как может быть устроен MVCC в дисковых БД
Из-за особенностей носителей в дисковых БД старт чтения или записи длительный, но потоковое чтение последовательных данных очень быстрое: головка читает с нужной дорожки, а не перескакивает с места на место. Более того, диски дешевые, поэтому дисковые БД в десятки раз дешевле In-memory БД.
Исходя из этих особенностей, при создании дисковых БД надо учитывать, что:
- БД должна работать асинхронно — одновременно обрабатывать несколько операций;
- данные должны быть упорядочены и разбиты на блоки: основные ресурсы уходят на начало чтения, поэтому смежная информация должна быть расположена вместе;
- из-за технических ограничений диска нагрузка на БД всегда будет низкой, поэтому сложные алгоритмы для локальных данных не нужны.
Работа с блоками данных в дисковых БД
При работе с блоками данных основным элементом БД выступает индекс — указатель, который обрабатывает транзакцию и помогает понять, где находятся нужные данные.
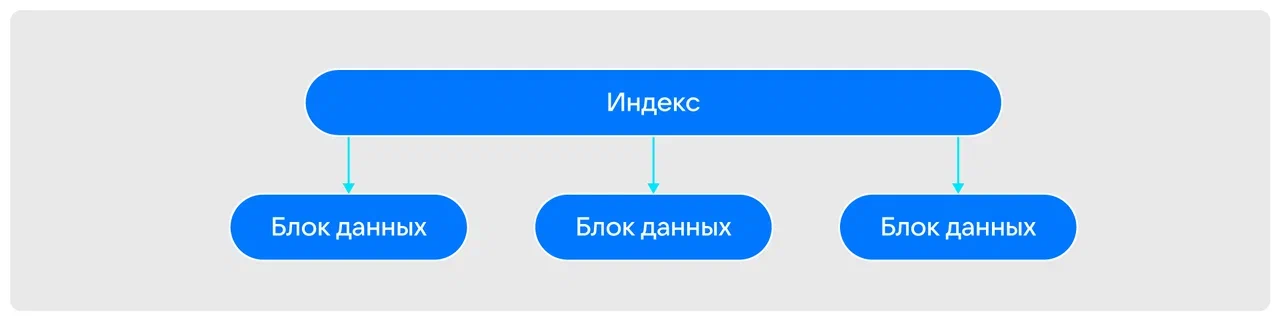
Как в примере с магазином, индекс — это табличка-указатель, которая помогает понять, в каком отделе нужный товар.
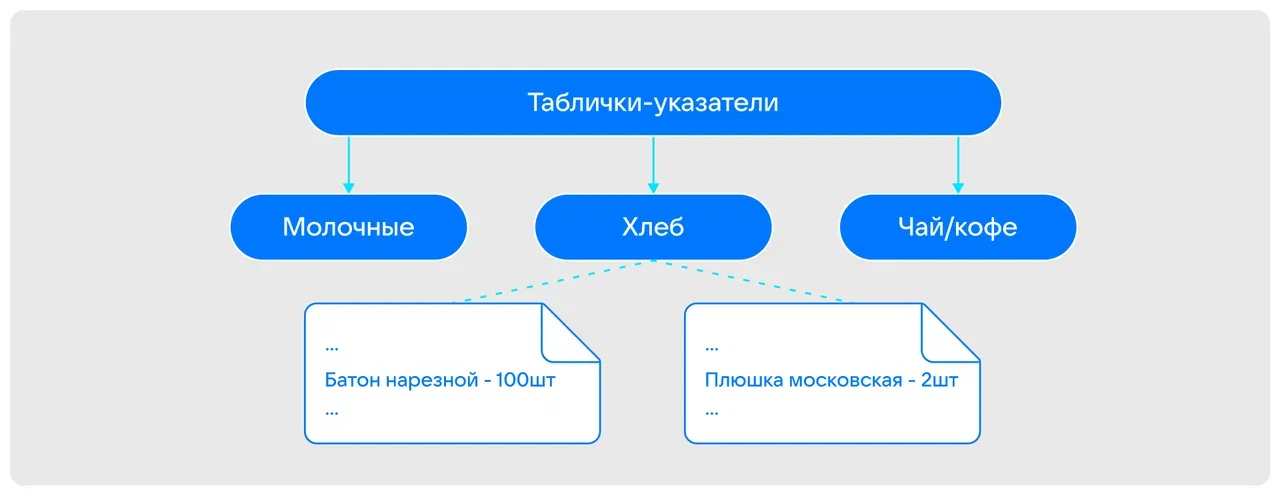
Но если в магазине категорий товаров немного, то даже в небольшой БД зачастую огромное количество каталогов и уровней хранения. Поэтому индекс тоже нередко делят на блоки.
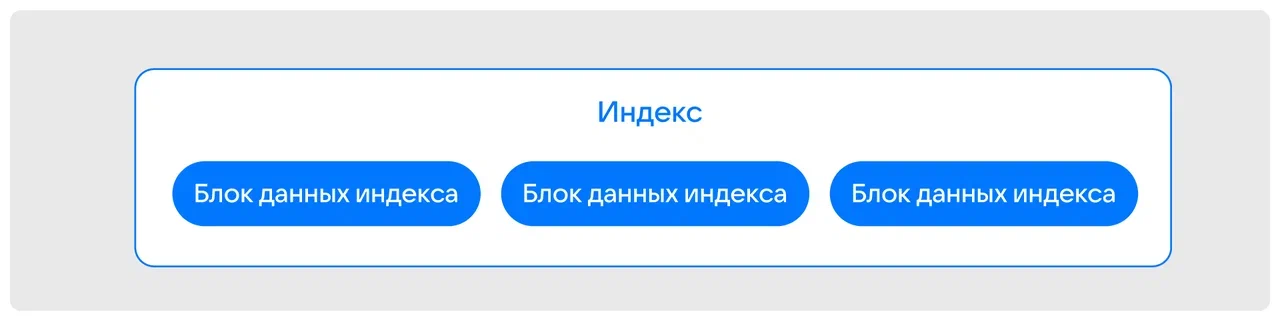
При рекурсивном повторении такого деления получается структура хранения «Б-дерево», в которой на блоки разбито все.

В такой структуре корень выступает в роли основного индекса, узлы маршрутизируют запросы, а листы хранят пользовательские данные. Уровней может быть и больше, но алгоритм всегда один: запрос идет от корня к листу с данными.
Реализация MVCC в дисковых БД
Есть два основных способа реализации MVCC в дисковых БД:
- сохранение копии данных;
- сохранение истории изменений.
Сохранение копии данных
При сохранении копии данных для каждого пользователя создают копии узлов БД, с которыми он работает.
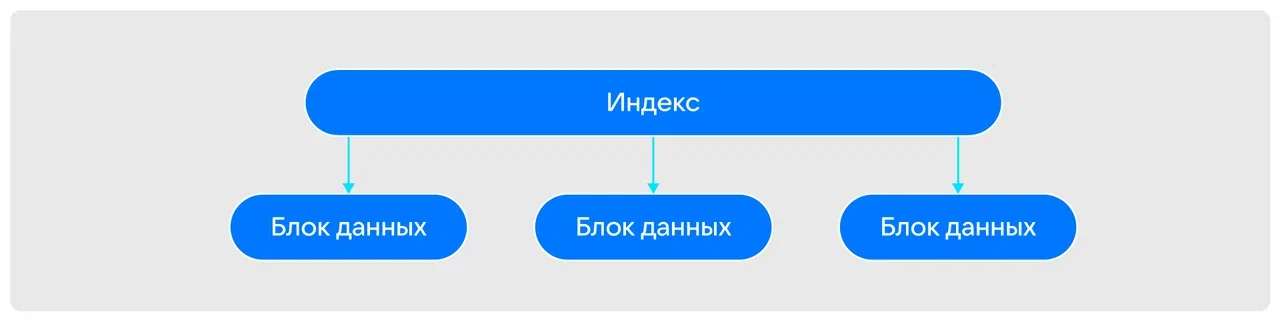
При этом пользователь работает в изолированной среде и не влияет на исходные данные. Более того, при таком подходе каждый скопированный персональный блок данных становится основным для конкретного пользователя. То есть если один из трех блоков в БД изменился, индекс будет ссылаться на два исходных блока и на один измененный. Соответственно, при сохранении копии данных на любом из уровней сохраняется и копия индекса с измененной схемой запросов.
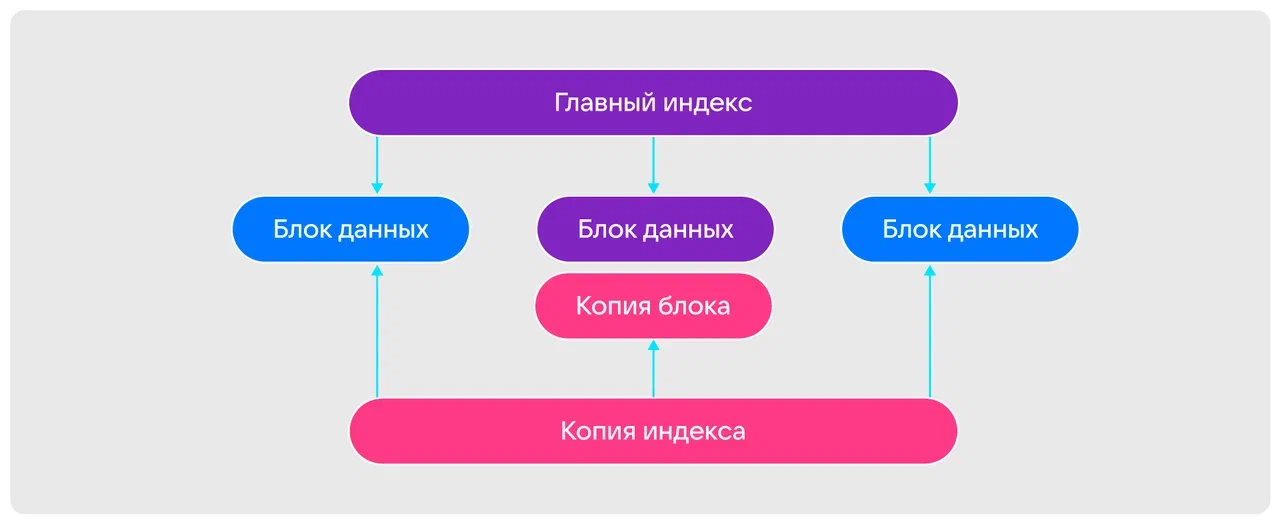
Если главный индекс большой, при сохранении копии можно разделить его на блоки и изменять только нужный. Подход тот же, что и при работе с копированными блоками, и упрощает работу с индексами.

Если данные хранятся в структуре «Б-дерево», для внесения изменений в конечный лист с пользовательскими данными надо копировать весь путь от корня, то есть всю высоту дерева.

Таким образом, сохранение копии данных:
- это простой и понятный подход;
- требует минимум ресурсов CPU;
- позволяет читать персональную копию данных из тредов.
Но у подхода есть ряд недостатков:
- на каждое изменение нужно скопировать целый блок данных, даже если надо изменить всего один байт;
- часто приходится копировать много блоков: данные могут быть в разных ветвях и уровнях, поэтому нередко приходится копировать всю высоту дерева БД целиком ради каждого пользователя;
- возможна ошибка «Недостаточно места» при удалении: если нужно удалить блок, но у него есть пользователь, его нужно предварительно скопировать. Как результат, в какой-то момент места на диске становится меньше и может не хватить для завершения операции.
Сохранение истории изменений
Второй подход — сохранение истории изменений. Он подразумевает не копирование отдельного блока данных, а создание записи об изменениях. Например, если мы изменяем блок, в записи отражается, что именно было изменено, а если объект был удален, возле него добавляется «надгробие», которое указывает, что данных больше нет. Исходный блок при этом остается без изменений.
Записи об изменениях добавляются с сохранением хронологии, поэтому их можно упорядочить по времени или Sequence Number (SN). Это позволяет читать историю изменений до любого уровня, отсекая ненужные изменения: например, можно посмотреть, каким был блок БД неделю назад.
Поскольку дисковые БД не адаптированы под случайное чтение, в них записи об изменениях размещают непосредственно возле блока данных, так можно считывать нужную информацию быстро и за один раз. При этом в дисковых БД проблем с внедрением подхода нет: данные на дисках и так упорядочивают по какому-то признаку, поэтому нужно просто добавить в ключ SN.
Для наглядности можно адаптировать подход к вышеупомянутому условному магазину. Например, человек подходит к полке с хлебом и видит, что было 100 батонов, но рядом написано, что несколько батонов принадлежит другим покупателям. Исходя из этой истории, покупатель может узнать, сколько батонов осталось фактически. После покупки он тоже должен оставить аналогичную запись — обязательно документируется каждая операция.
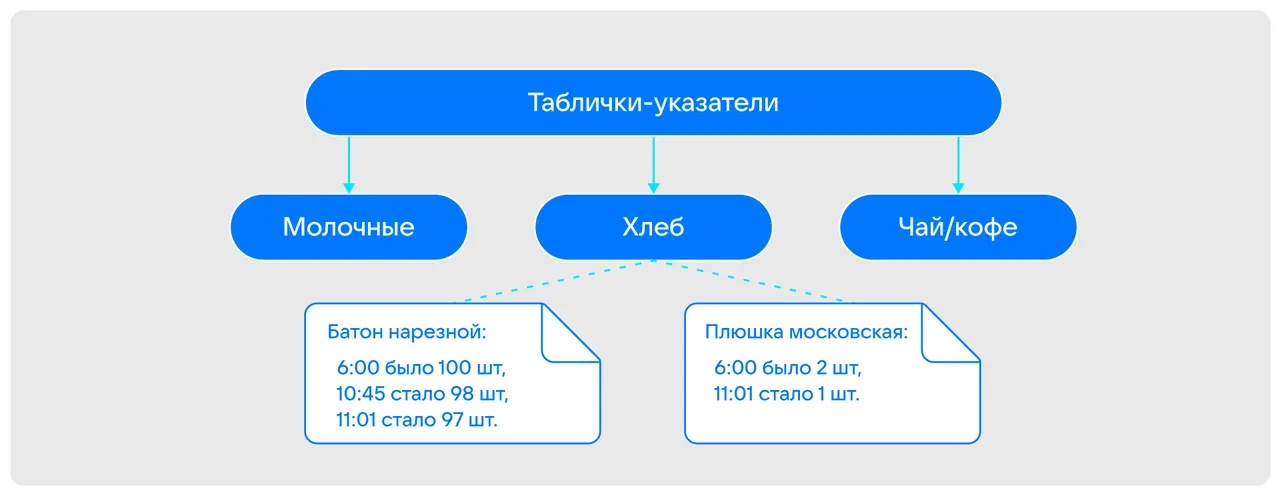
Для такого подхода подходит структура данных «LSM-дерево».

LSM-дерево по умолчанию накапливает историю изменений, распределяет их по уровням, обеспечивает связь между ними и сжимает устаревшие или невостребованные данные. Поэтому для реализации MVCC при такой структуре достаточно настроить правила взаимодействия и сжатия записей в Backend.
Подход сложнее сохранения копий данных, и с ним на обычное чтение надо больше ресурсов. Но он требует меньше дискового пространства и позволяет использовать удобную структуру данных. Поэтому в Tarantool мы используем LSM-дерево в качестве дискового движка, а MVCC организовываем с помощью сохранения истории изменений.
Как может быть устроен MVCC в In-memory БД
In-memory — относительно новый тип БД, в котором унаследованы многие алгоритмы и подходы из дисковых БД, хоть и с небольшой адаптацией. In-memory БД работают быстрее дисковых и хорошо справляются не только с потоковым, но и со случайным чтением данных.
Вместе с тем In-memory БД дороже дисковых, требуют более сложных алгоритмов и со временем все равно требуют сохранения данных на диск, чтобы обеспечить надежность хранения.
Для организации In-memory БД можно выбрать бинарное дерево поиска. Это ошибочный путь: бинарное дерево в среднем занимает 32 байта на запись, а это значит, что на миллиард записей нам потребуется (дополнительно!) 32 ГБ памяти. Б-дерево компактнее, поэтому больше подходит для In-memory БД. В Tarantool мы используем именно его. Кроме того, мы используем:
- специальный аллокатор;
- трансляцию адресов: вместо 8-байтового указателя на блок используем короткие ID;
- Б*-дерево — модификацию структуры, в которой блоки должны быть заполнены не менее чем на 2/3, то есть доступное место используется эффективнее.
Реализация MVCC для БД в памяти
Есть несколько способов реализации MVCC в In-memory БД:
- адаптация алгоритмов из дисковых БД;
- применение алгоритмов со случайным доступом к памяти;
- запрет асинхронности.
Запрет асинхронности подразумевает, что транзакции выполняются по-настоящему атомарно: сначала целиком одна, потом другая, после — третья и так далее. В дисковых системах такой подход практически неприменим, так как задержки при чтении с диска делают транзакции долгими и при отсутствии асинхронности итоговая производительность будет печальной. Однако в базах данных в памяти это отлично работает. При таком подходе исключены любые конфликты, а сама работа с памятью исключает ожидание чтения, и процессор используется без простоев. Но это накладывает ряд ограничений: например, в транзакциях запрещены сложные операции, интерактивные (параллельные) транзакции тоже запрещены, а сбой WAL может привести к грязным чтениям. Несмотря на это, запрет асинхронности — хороший способ реализации менеджера транзакций, который работает быстро и эффективно. В Tarantool мы его используем по умолчанию, если не включен основной MVCC-движок.
Сохранение копий данных в In-memory БД
Для реализации полноценного MVCC для индексов в In-memory БД также можно задействовать алгоритмы из дисковых БД. Так, в случае с Tarantool для индекса используется Б-дерево, в котором предусмотрена трансляция адресов — для идентификации блокам присвоены некоторые ID.
При адаптации этого алгоритма под In-memory БД можно не копировать всю высоту дерева при изменении всего одного блока: блоку, в который пользователь вносит изменения, просто присваивается аналогичный ID, а транслятору передается команда, что для этого пользователя актуальным блоком стал новый. То есть если изменен шестой блок, для одного конкретного пользователя он будет отличаться, но его ID останется прежним.

На таком принципе основан Matras — наш аллокатор с трансляцией адресов и CoW. Он универсален и позволяет организовать MVCC для индексов в любой структуре данных (например для Hash-индекса).
Но подход, реализованный для индекса, не подходит для данных в In-memory БД, потому что, в отличие от дисковых БД, которые хранят данные в листах, в памяти данные часто лежат отдельно и нужно хранить ссылки на них. А это значит, что если не предпринимать специальных действий, то при удалении данных в MVCC-индексе появится битая ссылка — указатель на удаленную (несуществующую, а может, уже и перезаписанную) запись. Поэтому для того чтобы работал MVCC, необходимо по необходимости откладывать физическое удаление записей до тех пор, пока они не перестанут быть нужны хотя бы одному читателю.
Так, в Tarantool мы добавляем каждой записи данных ID, который соответствует эпохе создания данных. Новая эпоха начинается тогда, когда появляется новый читатель новой версии данных. То есть для каждой записи появляется интервал из эпохи создания и удаления — «цикл жизни».
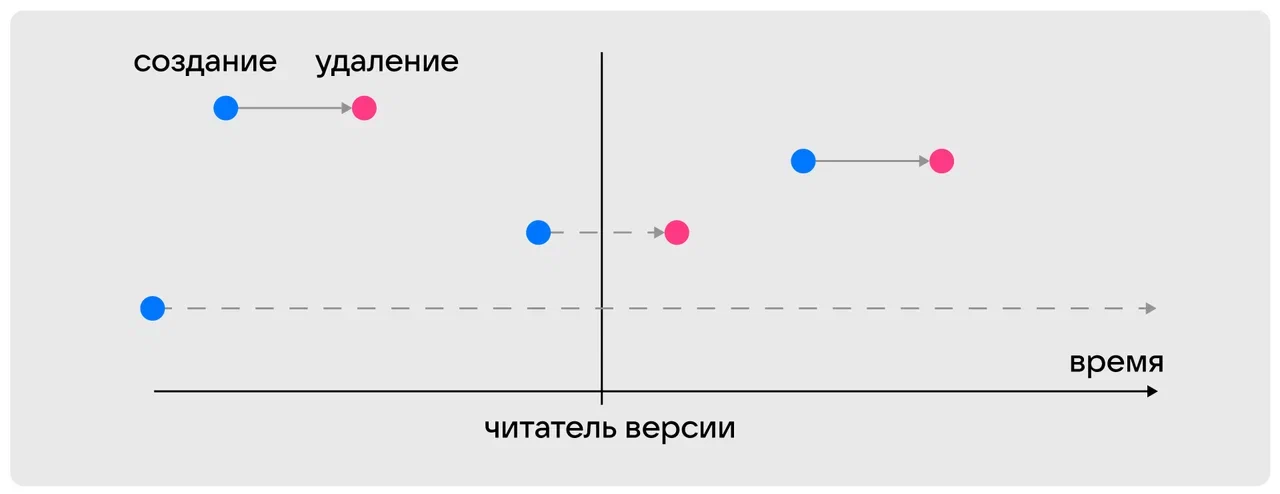
Подход работает аналогично, даже если записей и читателей больше.

Таким образом, читатели версии данных разграничивают эпохи. С таких подходом сразу становится понятно, какие записи можно физически удалять сразу, а какие следует придержать: если время жизни записи находится в пределах одной эпохи, значит, она не видна ни для какого из читателей: для всех, что левее на графике, она «еще не была создана», а для всех, что правее, она «была ранее удалена». И только если время жизни записи пересекает читателя версии, ее физическое удаление нужно отложить.
В Tarantool мы при таком откладывании физического удаления просто передаем данные во владение ближайшему читателю. Делается это при помощи простого интрузивного списка, то есть это очень дешево с точки зрения ресурсов. В ситуациях, когда данные важны для работы сразу нескольких читателей, мы для простоты и определенности добавляем их во владение самому позднему из читателей.
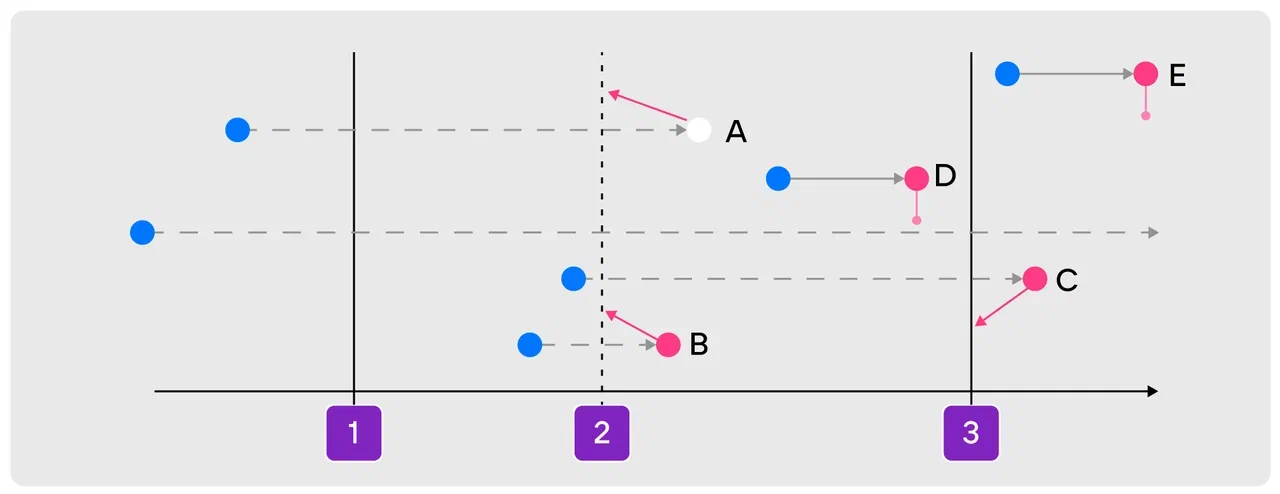
При уничтожении читателя надо удалить и данные, которые принадлежат только ему. При этом надо помнить, что данные, приписанные к этому читателю, могут быть нужны и более старым читателям, поэтому их надо передать во владение ближайшему читателю. В Tarantool для оптимизации такого перемещения у каждого читателя хранятся сразу несколько списков: первый для данных, которые видны только этому читателю, второй — этому и одному соседнему, третий — этому и двум соседним и так далее. Очевидно, что данные из первого списка должны быть удалены сразу, а остальные — перемещены в соответствующие списки соседнего читателя.

Итого:
- при удалении объект может быть отдан во владение Read View;
- у Read View много списков для оптимизации его уничтожения;
- при уничтожении Read View часть списков можно удалить сразу, а часть надо перенести в соседнее Read View;
- списки интрузивные, поэтому дополнительной памяти не требуется.
Такой подход можно использовать для разных задач — например, для сохранения снимка данных на диск или инициализации реплики.
Для наглядности изменений рассмотрим пример кода для Tarantool, которые использует Read View:
tarantool> box.space.test:select{}
—-
- - [1, ‘original’]
- [2, ‘another original’]
…
tarantool> rv = box.read_view.open()
tarantool> box.space.test:delete{2}
tarantool> box.space.test:insert{3, ‘new’}
…
В нем есть Space и определенный набор данных. После внесения изменений, например удаления или добавления объектов, данные в базе изменятся, а в Read View они остаются прежними.
tarantool> box.space.test:select{}
—-
- - [1, ‘original’]
- [3, ‘new’]
…
tarantool> rv.space.test:select{}
- - [1, ‘original’]
- [2, ‘another original’]
…
В целом подход с сохранением копий:
- позволяет использовать разные алгоритмы для индексов и данных;
- имеет оптимальную алгоритмическую сложность;
- позволяет работать с Read View из тредов без синхронизации.
Но подходит он только для Read-only-операций.
Сохранение истории изменений в In-memory БД
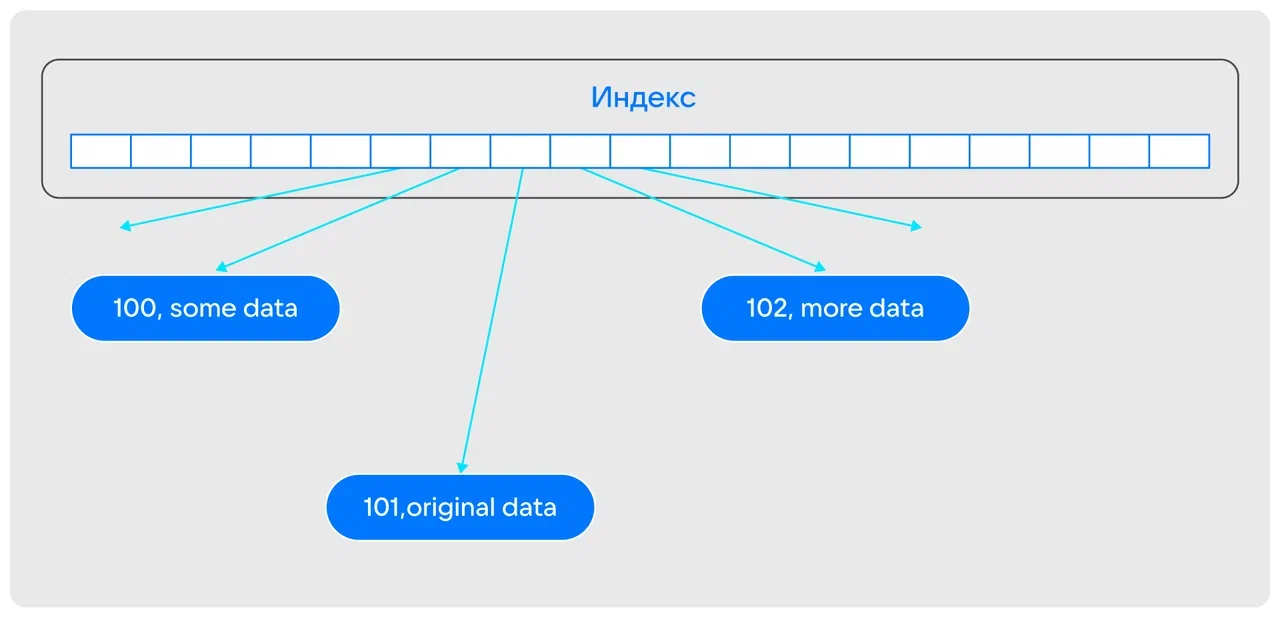
Подход с сохранением истории изменений мы используем в качестве основного MVCC-движка для менеджера транзакций. Но для работы в памяти его нужно адаптировать, чтобы алгоритм был простым, позволял не платить за неиспользуемые ресурсы, а историю изменений можно было бы хранить отдельно от объекта. Для этого в каждой записи мы заводим специальный флаговый бит, который по умолчанию сброшен. Если бит не установлен, то это означает, что запись простая, и означает безусловную видимость этой записи. Например, есть индекс, который ссылается (при помощи указателей) на отдельные записи:
При изменении записи мы без задержек выполняем запрос — например, сразу заменяем запись, будто MVCC нет. Но при этом в системном поле записи выставляем в 1 флаговый бит, который указывает, что у записи есть некоторая история.
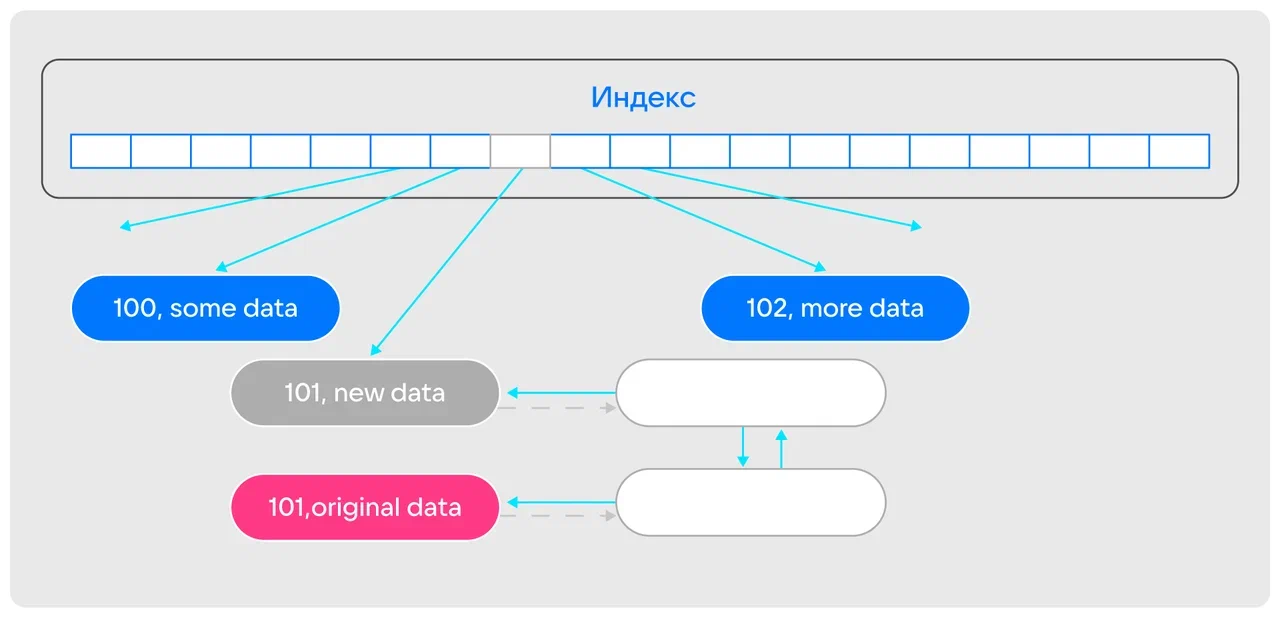
Если нужно, историю можно посмотреть в специальной хеш-таблице, которая лежит отдельно и хранит массивы ценной информации. Таким образом, мы получаем MVCC через историю.
Такой подход экономичен с точки зрения ресурсов (для большинства записей нет истории, и им нужен всего один бит), позволяет хранить все изменения и легко читать чистые данные.
Tarantool использует уровень изоляции Serializable, но это не уровень изоляции Snapshot. Это связано с тем, что MVCC у нас с «плавающим» Read View: мы гарантируем, что транзакция получает актуальный Read View, но изначально не говорим, на какой момент времени он актуален. Это дает некоторую свободу менеджеру транзакций, позволяя сделать так, чтобы пользователь получал максимально «свежий» Read View, что существенно сокращает вероятность конфликтов и противоречий. Также опции транзакции позволяют создавать снапшот из неподтвержденных данных (закоммиченных, но еще не записанных на диск).
Главное
- MVCC — механизм СУБД, который позволяет организовывать параллельный доступ к базам данных и подразумевает предоставление каждому пользователю персональной копии данных.
- MVCC позволяет исключить блокировку транзакций и получить изоляцию любого уровня.
- MVCC можно реализовать в дисковых и In-memory-базах данных. Основные способы реализации MVCC в дисковых БД — сохранение копии данных и истории изменений, в In-memory — адаптация алгоритмов из дисковых БД и полный запрет асинхронности.
