NetXMS как система мониторинга для ленивых… и немного сравнения с Zabbix

0. Интро
Я не нашел на Хабре ни одной статьи по NetXMS, хотя очень искал. И только по этой причине решил написать сие творение, дабы уделить внимание данной системе.
Это и tutorial, и how to, и поверхностный обзор возможностей системы.
Данная статья содержит поверхностный анализ и описание возможностей системы. Глубоко в возможности я не закапывался по ряду причин. Да и описание всего функционала заняло бы далеко не одну статью.
Так как более-менее я работал только с Zabbix’ом — в статье будет часто упоминаться именно эта система для сравнения с сабжем. К тому же как-то так повелось, что все сравнивается с чем-то общепризнанным.
1. Что и зачем?
Система мониторинга, как видно из определения, — система, позволяющая в любой момент времени получить актуальную информацию по какому-либо узлу сети\машине\маршрутизатору\вписать нужное.
Зачем это нужно — так же очевидно. Чтобы быть в курсе происходящего.
Зачастую, система мониторинга может дать весьма исчерпывающую информацию о состоянии как инфраструктуры в целом, так и отдельных ее частей. Плюс к тому, если настроить оповещения (а без нее грош цена любому мониторингу), то на выходе мы получаем серьезный инструмент, который позволяет не только своевременно реагировать на уже возникшие аварийные ситуации, но и, в большинстве случаев, дает возможность эти аварии предотвратить.
2. Почему NetXMS?
И вот спустя несколько лет, повзрослев и заматерев, я решил, что пришло время освежить знания о системах мониторинга. И наконец-то сделать нормальный, стабильный мониторинг сети, так как эта проблема стала актуальной в связи с ростом сегментов, подключением филиала и прочих мелочей. Все ж течет, все меняется. И стал я тестировать всяческие инстрУменты. То эту систему поставлю, потрогаю, то ту. И везде чего-то не хватает, везде что-то не нравится. То интерфейс неудобный, то настраивать замучаешься, то еще чего. И тут мне подвернулась NetXMS. К слову: там, где с Zabbix я разбирался две недели, с NetXMS все пошло-поехало за пару часов. Возможно, сказался опыт работы с Zabbix, а может быть дело в самом NetXMS… трудно сказать.
NetXMS оказалась довольно простой в установке и настройке системой. У нее есть версии сервера и консоли администрирования как под Windows так и под Linux, построение графиков, встроенный «браузер», который позволяет изнутри консоли администрирования коннектиться к тем же маршрутизаторам по http\https протоколам, и интерфейс интуитивно понятный, а так же агент под любую ОС. Словом, эта система оказалась простой и удобной. На первый взгляд.
Документация у них, к слову сказать, на 8 из 10. Основные вещи в ней указаны, но, чтобы вникнуть в тонкости, нужно поковыряться.
Глубокий мониторинг сети
Автоматическое обнаружение, визуализация и поиск подключенных компонентов на уровне 2 и 3
Полная поддержка SNMPv3
Активное обнаружение с помощью сканирующих «зондов»
Пассивное обнаружение на основе информации от контролируемых устройств — ARP и таблиц маршрутизации, интерфейсов
Мониторинг приложений и серверов
Все основные метрики, которые вы ожидаете: процессор, файловые системы, ввод-вывод, память, трафик
Мост JMX для мониторинга приложений Java
Расширения для конкретных приложений: Oracle, MySQL, PostgreSQL, MongoDB, DB2, Tuxedo и многие другие
API интеграции для собственных приложений
Предназначен для больших сетей
Один сервер может отслеживать сотни метрик на тысячах устройств
Полная поддержка распределенного мониторинга и горизонтального масштабирования
Мониторинг перекрывающихся IP-подсетей
Гибкий контроль доступа для операторов и клиентов
3. Углубляемся
Как установить систему — есть целый мануал администратора, доступный на сайте разработчика, и ничего сложного в этом нет, поэтому на этом останавливаться не буду. Самое трудное в установке — подключение системы к базе данных… Тут разница будет лишь в выборе СУБД и ОС сервера. Я выбрал Windows (далее-далее-ввести данные-готово) и MSSQL, так как он у меня уже был.
3.1. Включаем автообнаружение
Автообнаружение узлов сети можно включить при установке. Если это не было сделано по каким-то причинам, то его всегда можно включить в «Configuration-Network Discovery» или щелкнув по иконке с тем же именем. В рабочей области появятся свойства обнаружения. Нужно его включить, переведя в пассивный или активный режим, и обозначить другие свойства, например, опрашиваемые подсети. Так же тут можно накрутить фильтры, причем можно как выбрать и донастроить встроенные в систему, так и написать собственные скрипты. Честно скажу — мне фильтры не понадобились. Но выглядит настройка довольно дружелюбно и понятно.
Так же здесь можно указать SNMP community по умолчанию и его credentials (читай авторизацию).
3.2. Добавление узлов
При включенном автообнаружении конечные ноды (ПК, принтеры) будут добавлены и распределены по подсетям автоматически. С активным сетевым оборудованием все несколько сложнее.
Начать следует с включения на сетевом оборудовании SNMP и настроив community. Если в свойствах автообнаружения узлов сети не менялось значение по умолчанию для SNMP community, то система использует public community, при этом данную настройку можно изменить для каждого узла в свойствах добавляемой ноды (node).
Для удобства можно группировать девайсы по любому удобному принципу, для этого в дереве можно создавать контейнеры в ветке Infrastructure Services и биндить в них ноды из Entrie Network.
После включения и настройки SNMP на маршрутизаторах и добавления их в список отслеживаемого оборудования, система сама с ними свяжется, опросит, определит, что это за девайсы, применит шаблоны, начнет сбор данных и покажет front pannel для каждого маршрутизатора. Сама. Из коробки. Когда я настраивал Zabbix, о подобном я мог только мечтать.
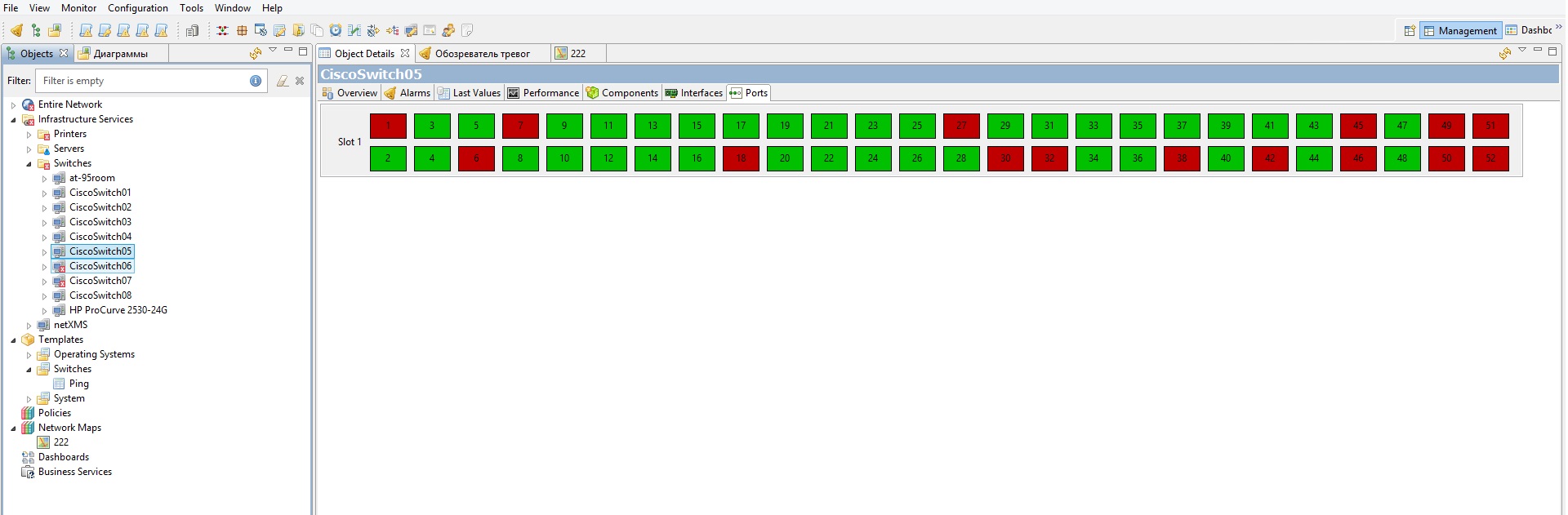
Я добавлял все свои сетевые железки вручную, так как сами они у меня по какой-то причине не обнаружились. Тут все просто. Создаем контейнер в Infrastructure Services с любым удобным названием (например switches), и ПКМ-создать-ноду, указать отображаемое имя ноды, ее IP-address и лучше поставить галку на «отключить использование NetXMS агента», так как его все равно невозможно установить на сетевое оборудование, а лишние пакеты ни к чему.
Встроенный браузер. Можно просто ПКМ на нужном маршрутизаторе и открыть web-интерфейс девайса. Мне это показалось удобнее, нежели каждый раз лезть в свои записи и искать нужный IP. Правда, браузер так себе.
3.3. Построение карты сети
Прежде всего нужно создать карту сети как объект. Как обычно — в ветке Networks Map ПКМ, создать, выбрать тип карты, задать параметры, и система дальше все сделает сама.
Типы карт следующие:
- Custom. Это карта, предназначенная для формирования вручную, по желанию пользователя.
- Layer 2 topology. Это карта, позволяющая автоматически сделать все за пользователя, опираясь на 2 уровень модели OSI (по-сути, строит карту основываясь на mac-адресах устройств).
- IP topology, она же Layer 3. То же самое, что и в случае с Layer 2, только карта строится на основе 3 уровня модели OSI (IP-адреса).
При выборе ручного составления карты нужно перетаскивать ноды из дерева на слой карты, соединять их и т.д. Обычное рисование.
В двух других случаях нужно выбрать точку отсчета, с которой система начнет строить карту. Например, ноду какого-нибудь маршрутизатора. Система считывает с него данные о подключенных устройствах и портах, к которым они подключены, после чего считывает данные со следующего маршрутизатора, сопоставляет, и так далее. После анализа всех устройств NetXMS сама нарисует связи между устройствами сети с указанием портов, куда что подключено. Так же можно указать, чтобы система поместила на карту в том числе и конечные устройства (принтеры, ПК, серверы), просто ткнув в соответствующий пункт в свойствах карты (ПКМ — свойства — свойства карты). Так же в этом пункте можно задать «радиус обнаружения» при желании или необходимости.
Маленькая рекомендация. Включите свойство Always fit layuot to screen, чтобы каждый раз обновляя карту сети не приходилось прокручивать рабочее пространство и работать зумом.
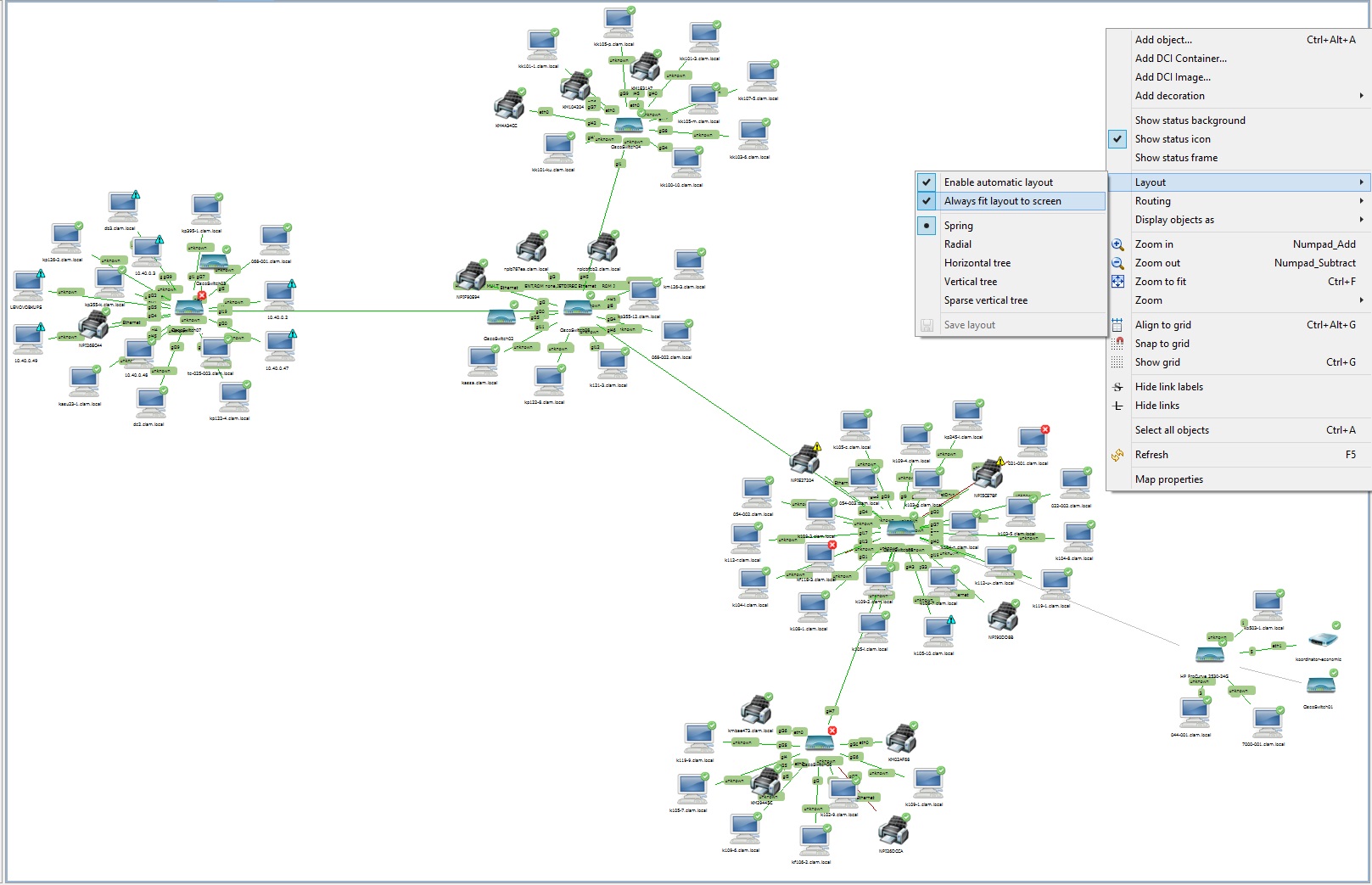
При распределенной топологии сети, можно наложить объекты на карту местности. Так же можно в качестве фоновой подложки использовать, например, фотку стойки с оборудованием в серверной, наложив на нее нужные объекты. Таким образом можно быстро определить статус любого девайса в стойке. На мой взгляд это крайне полезная штука в случае необходимости передать дела преемнику или вновь прибывшему коллеге объяснить положение дел. Наглядно, удобно, самоочевидно.
3.4. Агенты
Агенты существуют как для Windows, так и для Linux. Принцип работы такой же, как и у агентов того же Zabbix: устанавливается на машину, с которой нужно снимать метрики, и передает данные на сервер мониторинга. Агента можно установить как до добавления ноды в систему, так и после. После появления агента на ноде, система через некоторое время начнет принимать от него данные, применив стандартный шаблон. Добавить отслеживаемые параметры можно как для одной ноды, так и прицепив к ней один или несколько предопределенных шаблонов. Рекомендуется, естественно, работать с шаблонами, так как эта настройка более гибкая.
Список отслеживаемых параметров для агентов достаточно обширен. Полный перечень можно посмотреть в Wiki NetXMS
Как только система определит, что на ноде функционирует агент, она сразу же прикрепит эту ноду к одному из дефолтных шаблонов — Windows, Linux, HP-UX, Generic UNIX, AIX, в зависимости от операционной системы ноды.
Стандартный шаблон для Windows-хостов:

Добавить параметр для отслеживания конкретной ноде можно щелкнув »ПКМ-Data Collection Parameter», далее »ПКМ в рабочей области — New parameter», и выбрать нужное из списка. Тут же можно настроить и триггеры для отслеживаемого параметра.
Немаловажно, что агенты, так же как у Zabbix, умеют запускать пользовательские скрипты.
Тут вопрос в том — надо ли распространять агентов только на серверы, или вообще на все машины сети? Если серверы, и их немного — проще всего руками. Если много — политики домена, KIX, PoSh. Чем угодно. У агентов есть ключ /SILENT, что позволяет «внедрить» его прозрачно для пользователя (если мы говорим о распространении на все машины сети). Я предпочитаю скрипты, так как можно задать условие и создать некий флаг, в отличии от политик, которые будут ставить программу каждый раз при включении ПК. Итак, пишем скрипт из серии «проверить наличие файла-флага, если нет — запустить инсталлятор с ключом /SILENT и после успешной установки создать файл-флаг». Профит.
3.5. Триггеры
Триггеры можно настроить на реагирование на определенные события в собираемых данных. Например, превышение определенного значения ping-pong до маршрутизатора. Так же настраивается способ оповещения для каждого триггера (для каких-то достаточно значка в консоли, а какие-то сразу шлют оповещения куда только можно). Реакция на событие выбирается из преднастроенных в Action Configuration.
Для создания триггера: войти в Data Collection Cnfiguration ноды или шаблона, двойной щелчок по интересующему параметру (если нет, то надо его сперва создать), и в свойствах перейти на вкладку Thresholds, нажать кнопку добавить.
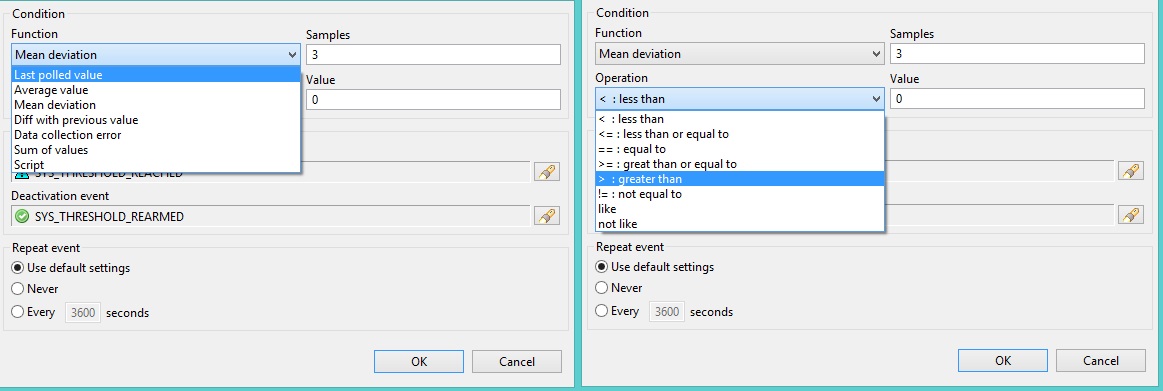
»Function» — какое или какие значения брать для вычисления условия. Может принимать следующие значения (количество используемых для проверки значений указывается в поле Samples):
— Last polled value: последнее/ние полученное/ные значение/ния
— Average value: среднее значение из последних
— Mean deviation: среднее отклонение
— Diff with previous value: разница с предыдущим значением
— Data collection error: ошибка получения данных
— Sum of values: сумма значений
— Script: значение, полученное в результате работы пользовательского скрипта
»Operation» — условие срабатывания триггера. Может принимать значения (значение указывается в соответствующем поле Value):
— <: less than: меньше, чем
— <=: less than or equal to: меньше или равно
— == equal to: эквивалентно
— >=: great than or equal to: больше или равно
— >: great than: больше, чем
— !=: not equal to: не эквивалентно
— like: приближенно к
— not like: не приближенно к
На счет двух последних параметров у меня нет уверенности в том, как они работают. По этому не буду даже предполагать какие границы в них встроены.
Словом, все как в том же Zabbix, только не надо руками формулы вписывать, боясь ошибиться или очепятаться. Для восстановления триггера (deactivation event) система сама подставит значение. (В Zabbix опять надо печатать и не опечататься).
3.6. Шаблоны
ПКМ-создать шаблон, ввести имя шаблона. ПКМ-Data Collection Cnfiguration.
Для сбора информации через SNMP в NetXMS есть огромный список предопределенных параметров, то есть можно не вписывать конкретный OID, а найти его в дереве MIB, что достаточно проблематично на самом деле… Но. В итоге нужно копаться в документации производителя и искать IOD значения для каждого девайса по-отдельности. Можно убить массу времени на настройку считывания информации с девайсов, натыкаясь на сообщение системы «UNSUPPORTED», а в итоге окажется, что данное конкретное устройство просто не умеет предоставлять запрошенную инфу. Тут остается только курить мануалы и надеяться.
Например, чтобы собирать информацию о времени отклика ноды (ping), нужно добавить новый параметр (ПКМ-new parameter), в поле Origin выбрать Internal, нажать кнопку Select, и выбрать Ping Time. Там есть поиск, о чем в Zabbix я только мечтал. Так же есть смысл изменить период опроса ноды (по умолчанию стоит 60 секунд, то есть если маршрутизатор перестанет отвечать сразу после того, как был опрошен системой мониторинга, то пройдет почти целая минута до того, как система поймет, что с ним что-то не так, и забьет тревогу).
Список Internal данных, которые можно обрабатывать:

После того, как в шаблон были добавлены все необходимые настройки, нужно нажать ПКМ-apply и выбрать все ноды, к которым этот шаблон нужно применить (ctrl+ЛКМ). И все. После этого в дереве под шаблоном появится ветка, раскрыв которую, можно увидеть все ноды, к которым этот шаблон применен.
При откреплении от шаблона ноды, собираемые данные не перестают собираться, чтобы отменить их сбор нужно для каждой ноды зайти в Data Collection Configuration и удалить все вручную, либо сначала удалить параметры из шаблона и только потом удалять из него ноды. Я не знаю, для чего сделано именно так, но, на мой взгляд, это крайне странная штука. Но… Уж как есть.
В шаблоне можно выбрать нужные собираемые данные, и скопировать их в другой шаблон. Массово. И не надо копипастить из одного шаблона в другой руками… Я уже начинаю ненавидеть Zabbix…
3.7. Dashboards
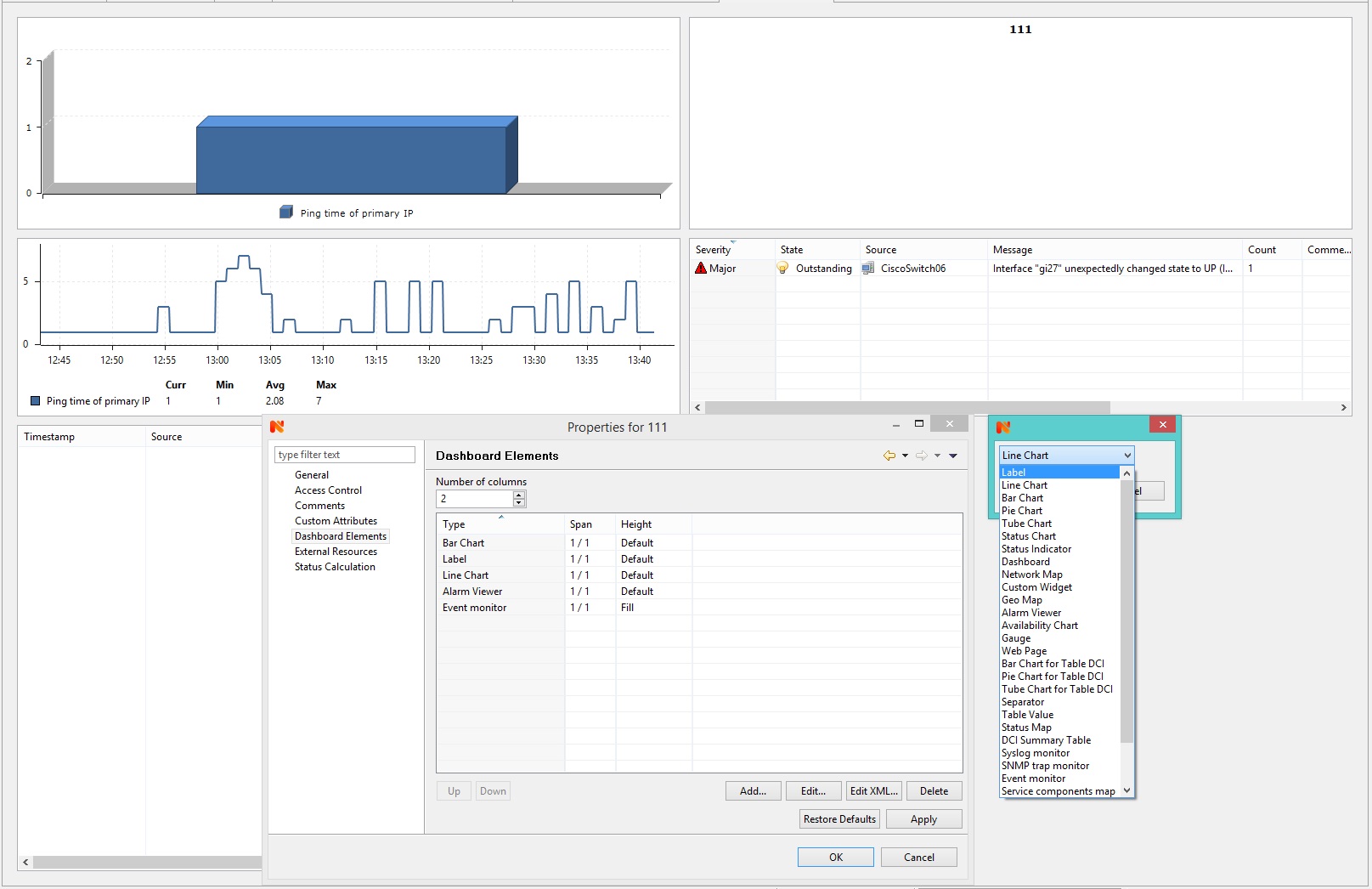
Как это ни странно, но NetXMS Wiki по этому поводу содержит лишь одну ссылку на youtube: Creating a Dashboard, нет даже списка и описания элементов, которые можно добавить на Dashboard. В принципе, там все так же интуитивно понятно. Label — это просто… ну… Label же… Я даже не знаю, как это перевести. Словом, поле с надписью, используется для обозначения и разграничения элементов, так как сами элементы названий не содержат. Line Chart — это линейный график. Bar Chart — это диаграмма. Alarm Viewer — список предупреждений для выбранного/ных узла/ов. Словом, названия говорят сами за себя.
Далее нужно открыть свойства дашборда и настроить представления. Нас интересует вкладка Dashboard Elements. Number of columns — это количество колонок, элементов, которые будут расположены по горизонтали. У каждого объекта есть свои свойства, и я бы рекомендовал снимать галку с пункта Layout-Grab execessive vertical space, чтобы минимизировать размер каждого элемента.
3.8. Action Configuration
(Configuration-Actions Configuration)
По-сути, это действия в ответ на срабатывание триггеров.
NetXMS умеет отправлять e-mail, sms, xmpp сообщение, в ответ на срабатывание триггера. Тут все тривиально — просто заполнить нужные поля.
Также можно:
— Передать оповещение на другой NetXMS сервер
— Выполнить команду на сервере администрирования NetXMS
— Выполнить команду на ноде с помощью агента NetXMS
— Выполнить NXSL скрипт (NSXL — это свой скриптовый язык программирования NetXMS)
После создания действия ему можно настроить время задержки выполнения, а так же применить макрос для выполнения. Время задержки нужно для того, чтобы не беспокоить оператора в случае, если проблема разрешится сама собой (например, время ответа на ping-запрос было больше заданного значения, но при следующей проверке оно может вернуться в норму, так зачем беспокоить по таким пустякам?).
3.9. Разграничение прав доступа
Для каждого объекта можно настроить свои права доступа. Для каждого объекта внутри другого объекта так же можно настроить права доступа. Это позволяет очень гибко распределять обязанности и возможности мониторинга для различных групп пользователей. Это все, что я хотел сказать.
4. Заключение
Я бы хотел опровергнуть название своей же статьи. NetXMS не для ленивых. Просто разработчики не сделали акцента на функциональности, как некоторые, но, помимо всего прочего, позаботились так же и об интерфейсе.
Давайте так. Я пользовался Zabbix’ом и NetXMS. По этому просто напишу свои ощущения от двух этих систем.
Итак.
NetXMS видится мне крайне дружелюбной к пользователю системой. Ну… к админу… да, к админу. У нее есть то, что называется интуитивно понятным интерфейсом, и это прям здорово. Не нужно писать свои формулы, читать кучу сопроводительной документации, чтобы включить проверку пингов до свича или еще какую-то простейшую вещь. Но. В Zabbix эта же простейшая вещь не многим отличается от чего-то реально непростого, то есть если освоил это — то так же сделаешь и все остальное. В NetXMS есть подсказки, большинство параметров можно найти в интерфейсе, выбрать мышкой и настроить. В Zabbix нужно узнать, а может ли система вот то-то и это, и если да — то как это пишется и какие параметры возвращает. Zabbix выигрывает в комьюнити и тоннах шаблонов на все случаи жизни… если в этой горе хлама получится найти то, что нужно… С другой стороны у NetXMS так же есть куча поклонников и созданных ими добавок к этой системе. Да и сама система из коробки умеет мониторить самые популярные приложения, о чем сказано на главной странице проекта.
Главным плюсом NetXMS против Zabbix для меня оказалась возможность запустить скрипт на проблемной ноде в ответ на срабатывание триггера. Поднялась температура ЦП выше порога — она сама погасит хост. А потом уже будем разбираться — в чем проблема. Возможно, в Zabbix такая штука тоже есть, но я не смог. Так же как и в мониторинг портов на маршрутизаторах. А тут само… Ну, как само… Надо освоить скриптовый язык, и все…
Права доступа в NetXMS позволяют очень гибко разграничивать возможности различных пользователей системы. Но чтобы все это настроить нужно прям повозиться.
В целом системы достаточно похожи, и возможности у них, на первый взгляд, кажутся как минимум сравнимыми. Хотя чувствуется, что Zabbix может больше, но эти возможности кроются глубоко под капотом и для простого смертного админа «все в одном» недостижимы. NetXMS же видится простой и понятной, дружелюбной и приятной.
У Zabbix отличная документация, wiki, how to, F.A. Q., best practice, а так же всевозможные форумы и т.д., где можно найти ответы практически на все вопросы. А если что — задать собственный.
Резюмируя, я бы хотел рекомендовать NetXMS для людей, которые только начинают или тем, кому не нужно глубоко погружаться в мониторинг всего и вся. Я уверен, что если разбираться с ней дальше, то можно накрутить в ней весьма и весьма тонкие наблюдения.
Но все же главным плюсом я вижу именно очень приятный интерфейс и простоту настройки.
5. Использованные материалы
youtube-канал Tomas Kirnak
NetXMS Wiki
Google-поиск
