Netdata: мониторинг в реальном времени

Проблематику мониторинга, сбора и хранения метрик мы уже не раз рассматривали в предыдущих публикациях. Сегодня мы расскажем ещё об одном инструменте —Netdata.
В отличие от других инструментов аналогичного плана, он ориентирован на сбор и визуализацию метрик в реальном времени (при необходимости можно подключать бэкенды для сбора и хранения собранных метрик).
С помощью netdata можно отслеживать просто огромное количество показателей: статистику использования процессора, потребления памяти, операций ввода-вывода, сети (список далеко не полный). Также Netdata оснащен плагинами для отслеживания различных служб: Postfix, Squid, PHP-FPM и другие.
В этой статье мы расскажем, как установить и настроить Netdat на сервере под управлением OC Ubuntu 16.04.
Установка
Прежде чем приступать к установке Netdata, установим все необходимые зависимости:
$ sudo apt-get install git zlib1g-dev uuid-dev libmnl-dev gcc make autoconf autoconf-archive autogen automake pkg-config curl
$ sudo apt-get install python python-yaml python-mysqldb python-psycopg2 nodejs lm-sensors netcat
По завершении установки клонируем официальный репозиторий netdata:
$ git clone https://github.com/firehol/netdata.git --depth=1 ~/netdata
Далее выполним:
$ cd ~/netdata
$ sudo ./netdate-installer.sh
Последняя команда запустит скрипт автоматической сборки и установки Netdata. По завершении установки Netdata готов к работе. А если изменить некоторые параметры конфигурации, всё будет работать с гораздо большей скоростью и производительностью. Об этом мы более подробно поговорим в следующих разделах.
Включаем дедупликацию страниц памяти
Начнём мы с того, что активируем KSM (Kernel Same-Page Merging, объединения одинаковых страниц памяти). Эта технология позволяет объединять страницы памяти между разными процессами для совместного использования. Как уверяют сами создатели Netdata в своём блоге, с её помощью можно увеличить производительность на 40 — 60%.
Выполним команду:
$ sudo nano /etc/rc.local
Файл rc.local (его имя представляет собой сокращение от run control) представляет собой скрипт, который исполняет после того, как будут запущены все остальные службы и процессы. Отредактировать этот файл нужно так:
#!/bin/sh -e
#
# rc.local
#
# This script is executed at the end of each multiuser runlevel.
# Make sure that the script will "exit 0" on success or any other
# value on error.
#
# In order to enable or disable this script just change the execution
# bits.
#
# By default this script does nothing.
echo 1 > /sys/kernel/mm/ksm/run
echo 1000 > /sys/kernel/mm/ksm/sleep_millisecs
exit 0
Первая команда записывает единицу в файл /sys/kernel/mm/ksm/run и тем самым активирует KSM, а вторая — указывает, что демон KSM должен запускаться раз в секунду и проверять 100 страниц на наличие дубликатов.
KSM будет активирован после перезагрузки сервера.
Устанавливаем срок хранения метрик
Все настройки Netdata прописываются в конфигурационном файле /etc/netdata/netdata.conf.
В секции [global] (в ней прописываются общие настройки) найдём параметр history. Его значение — это срок (в секундах), в течение которого хранятся собранные метрики. От этого срока напрямую зависит и потребление памяти:
- для хранения данных в течение 3600 секунд (1 часа) требуется 15 MБ оперативной памяти;
- в течение 7200 секунд (2 часов) — 30 МБ оперативной памяти;
- в течение 14400 секунд (4 часов) — 60 МБ оперативной памяти;
- в течение 28800 секунд (8 часов) — 120 МБ оперативной памяти;
- в течение 43200 секунд (12 часов) — 180 МБ оперативной памяти;
- в течение 86400 секунд (т.е. суток) — 360 МБ оперативной памяти.
Здесь приведены показатели для стандартных дашбордов; для кастомных дашбородов объём потребляемой памяти может быть как больше, так и меньше. Выставим нужное значение (в нашем случае это 14 400) и сохраним внесённые изменения.
Более подробно об особенностях конфигурирования Netdata можно прочитать в официальной документации.
Дашборды: структура и функции
Страница, на которой Netdata отображает все метрики и графики, доступна в браузере по адресу http://[IP-адрес сервера]:19999. По внешнему виду она напоминает веб-интерфейс популярного инструмента Grafana, о котором мы уже не раз писали.
На самом первом дашборде показываются главные метрики системы:
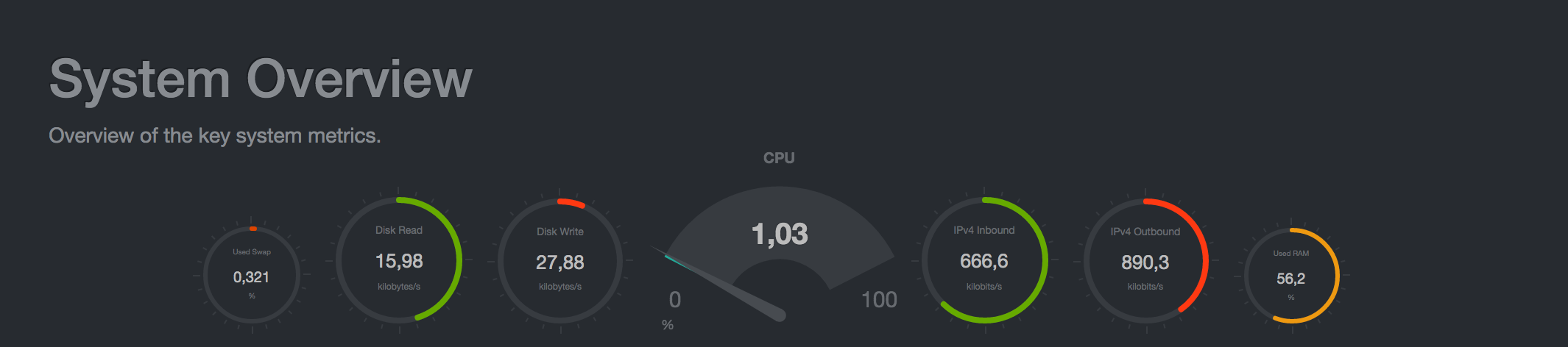
Далее идут графики использования ресурсов процессора, потребления памяти, операций ввода-вывода, сетевой активности и другие:



Мы можем увеличивать (или, наоборот, уменьшать) временные интервалы на графиках: для этого нужно подвести к дашбордку курсор, нажать SHIFT и покрутить колёсико мыши. На страницу можно добавлять многочисленные дополнительные графики; более подробно об этом можно прочитать здесь.
Настройка оповещений
Некоторые вида оповещений в Netdata настроены прямо «из коробки», в частности:
- оповещения об остановке любого из наблюдаемых приложений;
- оповещения об ошибках на сетевых интерфейсах;
- оповещения о нехватке дискового пространства.
Также Netdata вычисляет, сколько свободного места осталось на диске и в течение какого срока это свободное место будет исчерпано; если этот срок составляет менее 48 часов.
Как видим, для типичных ситуаций таких оповещений более чем достаточно. А если нужно настроить кастомные оповещения — в Netdata имеются специальные шаблоны, которые описываются в конфигурационных файлах, хранящихся в директории /etc/netdata/health.d.
Рассмотрим структуру и особенности синтаксиса этих шаблонов. Начнём со следующего примера:
template: disk_space_usage
on: disk.space
calc: $used * 100 / ($avail + $used)
units: %
every: 1m
warn: $this > (($status >= $WARNING ) ? (80) : (90))
crit: $this > (($status == $CRITICAL) ? (90) : (98))
delay: up 1m down 15m multiplier 1.5 max 1h
info: current disk space usage
to: sysadmin
Здесь всё интуитивно понятно: в шаблоне указано, когда нужно рассылать предупреждения об исчерпании дискового пространства. Разберём его структуру.
В поле template указано имя шаблона. В поле on указано, что шаблон нужно применять ко всем графикам, где context=disk.space (т.е. ко всем дашбордам со статистикой операций ввода/вывода).
Наибольший интересе для нас представляет, пожалуй, поле calc: в нём прописано, по какой формуле рассчитывается критический объём свободного места на диске. Она выглядит так: $used * 100 / ($avail + $used). Как нетрудно догадаться, $used — это объём использованного, а $avail — свободного дискового пространства.
В поле units мы указываем, что показатель выражается в процентах, а в поле every — что проверку следует проводить раз в минуту.
Обратите внимание на поля warn и crit: в них указываются значения, при которых нужно высылать соответственно предупреждение (в нашем случае это 80 -90%) и сообщение о критическом значении показателя (98%).
Здесь мы приводим лишь краткое описание; более подробно о шаблонах можно почитать здесь.
Ограничения
Как и у всякого инструмента, у Netdata есть свои ограничения и минусы. Первый минус заключается в том, что Netdata нельзя использовать для наблюдения за кластером серверов: его нужно устанавливать на каждый сервер в отдельности. А если и эти серверы доступны из Интернета, то интерфейс Netdata нужно в обязательном порядке закрыть для внешних посетителей (: злоумышленники могут использовать данные мониторинга в качестве подспорья в организации DOS-атаки.
Ещё один недостаток недостаток — поддержка очень ограниченного количества бэкендов для хранения метрик: на сегодняшний день в качестве таковых заявлены Graphite и OpenTSDB. Конечно, другие бэкенды «прикрутить» можно (см. здесь), но это не так просто, особенно для начинающих пользователей, не имеющих навыков программирования.
В числе минусов Netdata нужно также выделить недостаточно подробную и плохо структурированную документацию (пока что она доступна только в вики на Github): найти в ней ответ на нужный вопрос порой бывает крайне затруднительно.
Заключение
В этой статье мы проделали краткий обзор возможностей Netdata. Если вы хотите увидеть Netdata в действии — разработчики открыли для широкой аудитории доступ на демо-серверы, где можно все посмотреть и «пощупать». Если у вас уже используете Netdata — делитесь впечатлениями в комментариях.
В завершение по традиции приводим полезные ссылки для желающих узнать больше:
- https://github.com/firehol/netdata/wiki — официальная документация Netdata (недостаточно детальная и несколько хаотичная, как уже было сказано выше);
- https://www.digitalocean.com/community/tutorials/how-to-set-up-real-time-performance-monitoring-with-netdata-on-ubuntu-16–04 — неплохая инструкция по установке и настройке Netdata (мы её использовали при написании этой статьи);
- https://www.monitoring-fr.org/2016/04/netdata-real-time-performance-monitoring/ — неплохая статья-обзор возможностей Netdata (на французском языке).
Комментарии (2)
 Lordbl4
Lordbl4
23 декабря 2016 в 11:02
+1↑
↓
Очень красивый и информативный мониторинг для сервера. Надеюсь, проект будет активно развиваться. Спасибо автору за статью.Один вопрос — как отключить описания под графиками?
 andreymal
andreymal
23 декабря 2016 в 11:13
0↑
↓
В вебсокеты не умеет до сих пор, фи
