Несколько советов по OpenMP
 OpenMP– стандарт, определяющий набор директив компилятора, библиотечных процедур и переменных среды окружения для создания многопоточных программ.
OpenMP– стандарт, определяющий набор директив компилятора, библиотечных процедур и переменных среды окружения для создания многопоточных программ.
Много статей статей было по OpenMP. Однако, статья содержит несколько советов, которые помогут избежать некоторых ошибок. Эти советы не так часто фигурируют в лекциях или книгах.
1. Именуйте критические секцииВ очередь, сукины дети, в очередь! //М.А. Булгаков «Собачье сердце»
С помощью директивы critical мы можем указать участок кода, который будет исполняться только одним потоком в один момент времени. Если один из потоков начал выполнение критической секции с данным именем, то остальные потоки, начавшие выполнение этой же секции, будут заблокированы. Они будут ждать своей очереди. Как только первый поток завершит выполнение секции, один из заблокированных потоков войдет в нее. Выбор следующего потока, который будет выполнять критическую секцию, будет случайным.
#pragma omp critical [(имя)] новая строка структурированный блок Критические секции могут быть именованными или не именованными. В различных ситуациях улучшает производительность. Согласно стандарту все критические секции без имени, будут ассоциированы одним именем. Присвоение имени позволит вам одновременно выполнять две и более критические секции одновременно.
Пример:
#pragma omp critical (first) { workA (); } #pragma omp critical (second) { workB (); } //секции с workA () и workB () будут выполнены одновременно
#pragma omp critical { workC (); } #pragma omp critical { workD (); } // будет завершена секция с workC () , а только потом с workD () При присвоении имени будьте осторожны, не стоит присваивать имена системных функций или же имена, которые были уже использованы. Если ваши критические секции работают с одним и тем же ресурсом (вывод в один файл, вывод на экран) стоит присвоить одно и тоже имя или же не присваивать вовсе.
2. Не стоит использовать != в управлении циклом Директива for накладывает ограничения на структуру соответствующего цикла. Определенно, соответствующий цикл должен иметь каноническую форму.
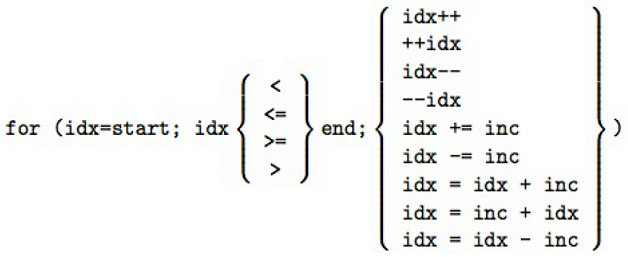
Ответ разработчиков из OpenMP Architecture Review Board
Если мы разрешим !=, программисты могут получить неопределенное количество итераций цикла. Проблема в компиляторе когда он генерирует код для вычисления количества итераций.
Для простого цикла как:
for (i = 0; i < n; ++i ) можно определить количество итераций, n если n>=0, и ноль итераций если n for (i = 0; i!= n; ++i) можно определить n итераций, если n>=0; если n for (i = 0; i < n; i += 2 ) число итераций целая часть от ((n+1)/2) если n >= 0, и 0 если n for (i = 0; i!= n; i += 2) не можем определить когда i равняется n. Что если n нечетное число? for (i = 0; i < n; i += k ) количество итераций наибольшее целое от ((n+k-1)/k) если n >= 0, и 0 если n for (i = 0; i!= n; i += k) i увеличивается или уменьшается? Будет ли равенство? Это все может привести к бесконечному циклу.3. Внимательно устанавливайте nowait Если Хатико хочет ждать, он должен ждать.// Хатико: Самый верный друг
Если клауза nowait не указана, то конструкция for неявно завершится барьерной синхронизацией. В конце параллельного цикла происходит неявная барьерная синхронизация параллельно работающих потоков: их дальнейшее выполнение происходит только тогда, когда все они достигнут данной точки; если в подобной задержке нет необходимости, опция nowait позволяет потокам, уже дошедшим до конца цикла, продолжить выполнение без синхронизации с остальными.
Пример:
#pragma omp parallel shared (n, a, b, c, d, sum) private (i) schedule (dynamic) { #pragma omp for nowait for (i = 0; i < n; i++) a[i] += b[i];
#pragma omp for nowait for (i = 0; i < n; i++) c[i] += d[i];
#pragma omp for nowait reduction (+: sum) for (i = 0; i < n; i++) sum += a[i] + c[i]; } Данном примере есть ошибка, она заключается в schedule(dynamic). Дело в том, что зависимых по данным циклы nowait допустим только c schedule(static). Только в этом способе планирования работ стандарт гарантирует корректную работу c nowait для циклов зависимых по данным. В нашем случае достаточно стереть schedule(dynamic) в большинстве реализаций по умолчанию используется schedule(static).
4. Тщательно проверьте код перед использованием task untied int dummy;
#pragma omp threadprivate (dummy) void foo () {dummy = …; } void bar () {… = dummy; }
#pragma omp task untied { foo (); bar (); } task untied специфицирует, что задача не привязана к потоку, который начал ее исполнять. Другой поток может продолжить исполнение задачи после приостановки. В данном примере неправильное использование task untied. Программист предполагает, что обе функции в задаче будут исполнены одним потоком. Однако, если после приостановки задачи bar () будет выполнен другим. По причине того, что у каждого потока своя переменная dummy (в нашем случае она threadprivate). Присвоение в bar () произойдет некорректное.Надеюсь, данные советы помогут начинающим.
Полезные ссылки: Примеры OpenMP 4.0 pdfПримеры OpenMP 4.0 githubСтандарт OpenMP 4.0 pdfВсе директивы на 4 листах C++ pdfВсе директивы на 4 листах Fortran pdfОдни из лучших слайдов по OpenMP на русском языке от Михаила Курносова pdf
