NER в поисках брендов. Часть 1
Опыт показывает, что построение результативных коммуникаций в маркетинге требует пристального изучения целевой аудитории и неочевидных знаний о ней. А значит, нужны новые подходы. Наши специалисты из CleverData предлагают использовать практику data science и рассмотреть один из таких подходов, как бренд-анализ. Хотим поделиться опытом, как с помощью NER (техники распознавания именованных сущностей) мы начали выделять бренды в покупках целевой аудитории одного из европейских производителей автомобилей.Оказалось, что эта аудитория предпочитает бутилированную воду, товары для взрослых Durex и электронику Apple. Расскажем, как мы пришли к таким выводам и чем они могут быть полезны.

Что такое бренд-анализ
К этому виду исследования мы пришли, когда проводили audience research для одного из клиентов CleverData. Audience research — это data-изыскание, основанное на данных и фактических паттернах поведения целевой аудитории. Его проводят для увеличения эффективности рекламных кампаний и коммуникаций.
В процессе такой работы у нас возникла интересная задача — с помощью внешних данных определить в целевой аудитории клиента (целевом сегменте потенциальных покупателей) приверженцев тех или иных брендов, которые часто приобретают их товары. Причем такие бренды клиент изначально не задавал, их необходимо было выявить.
Для начала изучили несколько целевых аудиторий — самого клиента, европейского производителя автомобилей, и его конкурента из Азии. В результате исследования мы выдвинули и подтвердили следующие гипотезы:
а) существуют определенные категории покупок, которые являются общими для исследуемых аудиторий;
б) внутри категорий есть конкретные бренды с высоким индексом аффинитивности — бренды-спутники.
Аффинитивность показывает в процентном соотношении, насколько сильно аудиторию продавца или производителя интересует конкретный бренд в сравнении со средним показателем по широкой аудитории.
Таким образом, мы выявили новый тип аудиторного исследования — бренд-анализ. Под бренд-анализом мы подразумеваем data-исследование, цель которого — выявить бренды-спутники для аудитории компании-продавца. Бренды-спутники — это те бренды, чьи продукты аудитория компании-продавца предпочтет в других категориях товаров.
Как проводили исследование и с какими сложностями столкнулись
Коротко описать процесс, проведенного нами бренд-анализа можно так. Практика CleverData Science постоянно сотрудничает с партнерами, которые предоставляют данные для исследований и обучения моделей. Поэтому сначала один из наших партнеров собрал для исследуемых аудиторий обезличенные данные о покупках за два года. Затем на основании NER-моделей (модели машинного обучения для выявления сущностей в текстах) была построена система распознавания бренда в больших данных с чеками онлайн-покупок, которые совершали исследуемые сегменты. В каждом чеке мы определяли бренды и производили расчет их аффинитивности, на основании чего и определяли бренды-спутники.
Итак, было принято решение использовать подходы NER для внешних данных, но выделять только наименования брендов и организаций. Здесь стоит добавить, что все эксперименты, о которых будем говорить дальше, — только первый подход к бренд-анализу. Наша цель — обучить собственную предсказательную ML-модель, которая бы распознавала бренды с минимальными ошибками.
NER (Named entity recognition) – распознавание именованных сущностей. Сущности — это наиболее важные фрагменты конкретного предложения (словосочетания с существительными, глагольные словосочетания и др.). По-другому можно сказать, что NER — это процесс обнаружения в тексте именованных объектов. Например, имен людей, названий мест, компаний и т. д.
NER является одной из базовых задач NLP, с помощью которой решаются различные бизнес-вопросы: создают автоматизированные чат-боты, анализаторы контента, выявляют инсайты о клиентской аудитории и т.д.
NLP (Natural Language Processing) — обработка естественного языка, подраздел информатики и AI, посвященный тому, как компьютеры анализируют естественные (человеческие) языки. NLP позволяет применять алгоритмы машинного обучения для текста и речи.

Основной сложностью применения NER-подходов к данным являются двуязычность и сильные различия в форматировании чеков. Так, могут попадаться «мусорные» чеки, в которых встречается написание известных брендов транслитом, ИП и малоизвестные бренды, орфографические ошибки, использование различных спецсимволов. Эти проблемы крайне усложняют поставленную задачу, поэтому после тестирования разных подходов, было решено использовать сразу несколько методов NER одновременно.
В целом наше исследование состояло из следующих этапов:
сбор сэмпла данных и первичная очистка,
построение предикторов (прогностических параметров),
построение правил принятия решений.
Расскажем подробнее о каждом из этапов. Предупреждаем, что повествование, скорее всего, будет интересным для тех, кто в теме: кто ориентируется в NER и машинном обучении.
Этап 1. Сбор сэмпла данных и первичная очистка
Для проведения экспериментов был взят кусок данных в 50 000 чеков, состоящий из двух столбцов:
0 — изначальный чек покупки
test — чек после обработки (удаление стоп-слов, лемматизация — помогает поисковым системам находить дубли, которые отличаются только словоформами)
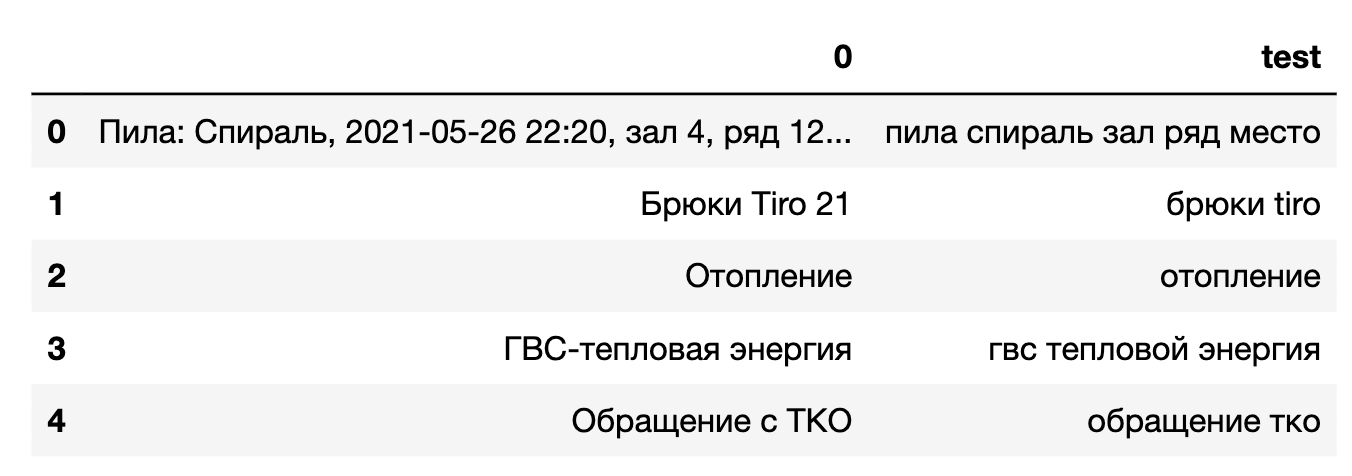
В этой задаче мы выделяем бренды покупок, но часть чеков не содержит таких данных. Именно поэтому было необходимо очистить сэмпл от таких строк. После их удаления осталось 41 673 чека, почти 17% чеков оказались «мусорными». Далее мы использовали различные методы NER для получения более точного результата.
Этап 2. Построение предикторов
Использование предобученных NER-моделей. Речь пойдет о моделях машинного обучения, созданных и натренированных на большом наборе общедоступных данных, которые схожи с целевыми. Важный нюанс – предобученные модели не умеют распознавать именованные сущности-бренды. Они умеют выделять организации, чтона самом деле нам тоже подходит — такие компании, как, например, Apple тоже являются организациями и выделяются предобученными моделями. Ниже список моделей, которые мы использовали:
Spacy
Natasha
NER Rus_Bert torch (DeepPavlov)
NER Ontonotes Bert mult torch (DeepPavlov)
Об их работе стоит сказать, что нет ни одной модели, которая была бы однозначно лучше, чем другие. И главное, ни одна из них не может работать самостоятельно, так как будет слишком много неразмеченных строк.
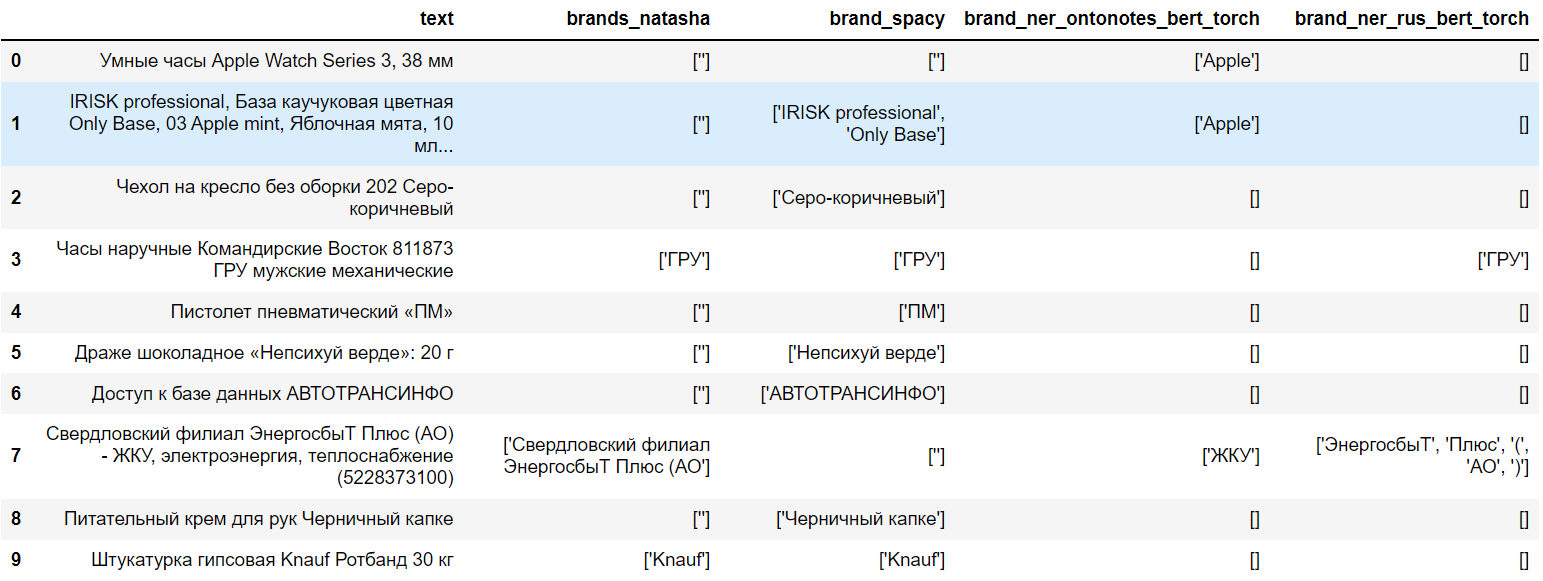
Использование регулярных выражений. Даже комбинация из всех предобученных моделей не позволяет разместить все строки чеков с брендами. Особенно часто проблема возникает с названиями на русском языке. Также не всегда выделяются малоизвестные иностранные названия. Поэтому мы использовали регулярные выражения в качестве дополнительного предиктора (то есть при помощи «регулярок» делали дополнительное предсказание брендов). Мы добавили две группы регулярных выражений:
выделение содержимого кавычек,
выделение слов на латинице.
Регулярные выражения — язык поиска и осуществления манипуляций с подстроками в тексте. Говоря проще, это некий шаблон, по которому фильтруется текст. Можно написать нужный шаблон (регулярное выражение) и таким образом искать в тексте необходимые символы, слова и т.д.

Использование подготовленного словаря брендов. В нашем скрипте использование словаря брендов применяется в разном виде на нескольких этапах.
В качестве самостоятельного предиктора — в рамках этого применения происходит поиск неточного вхождения брендов в исходной строке чеков.
Для поиска самых ближайших по расстоянию брендов из словаря в уже предсказанных другими предикторами вариантах. Это будет служить одним из последних этапов для разрешения спорных предсказаний.


Бренды были выделены по каждой букве отдельно и разбросаны по словарю, чтобы не перебирать весь алфавит (потому что поиск неточных вхождений и измерение расстояний при полном переборе всех брендов происходит очень долго). Вместо полного поиска происходит выделение первых букв каждого слова в строке или в варианте предсказания. Далее неточные вхождения или измерение расстояний происходит уже только по брендам, начинающимся с выделенных первых букв.
 Пример содержания одного из таких файлов с брендами
Пример содержания одного из таких файлов с брендами
Этап 3. Построение правил принятия решений
Вышеописанные этапы и методы поодиночке не позволяют получить качественную разметку по брендам. Во-первых, индивидуально модели часто ошибаются, во-вторых, нередко какой-либо прогноз по строке чека отсутствует. Поэтому пайплайн (сводка действий) определения бренда выглядит следующим образом.
1. Голосование и объединение в словарь очищенных от символов результатов с подсчётом частоты каждого из вариантов.
2. Распределение результатов на группы:
0 — чеки без прогноза,
1 - чеки со спорным прогнозом (когда есть несколько прогнозов с максимальным числом голосов),
2 - чек с одним вариантом прогноза,
3 - чеки с прогнозом, набравшим более 50% голосов,
4 — чеки, где прогноз с максимальным числом голосов имеет максимальную близость со словарём брендов среди других прогнозов,
5 - нераспределенные чеки.
3. Применение действия к каждой группе.
Группа 0: нет бренда.
Группа 1: применяется функция, которая объединяет все варианты в строчку и выделяет в этой строке слова с максимальной частотой (может быть несколько).
Пример: {футболка adidas:1, adidas:1, мужской: 1} → футболка adidas adidas мужской → adidas.
Группа 2: используется единственный доступный прогноз.
Группа 3: выбирается вариант, набравший максимальное число голосов.
Группа 4: для того, что не было отнесено к группам 1–3, рассчитываем дистанцию между каждым спрогнозированным вариантом до словаря бренда (выводим ближайшие со скором не менее n).
Для нашей конкретной задачи нам нужна программа, которая может автоматически определять неправильное написание, поэтому мы использовали FuzzyWuzzy-метод. Этот метод довольно эффективен для различения двух строк, относящихся к одному и тому же объекту, но написанных немного по-разному.
Далее, если самое близкое по дистанции (или одно из самых близких) из словаря брендов пересекается с одним из спрогнозированных вариантов, выделяем его как бренд.
Группа 5: к словарю вариантов добавляются бренды из словаря брендов со скором выше порогового (80).
К обновленному словарю прогнозов вновь определяется группа 1–4 с соответствующим действием. Если бренд даже после этого остался без прогноза, ему присваивается тот, что набрал больше всех голосов.

Что дальше? Выстроенный алгоритм хорошо определяет как популярные, так и непопулярные бренды в очищенных данных. Однако пайплайн достаточно тяжелый: предполагает применение четырех моделей и регулярных правил, а также запуск алгоритма голосования прогнозов сверху. Применение такого пайплайна затруднительно в качестве постоянного продуктивизированного решения, но отлично подходит для задачи разметки данных с целью дальнейшего обучения собственной NER-модели.
Какие инсайты получили
Эта часть рассказа может пригодиться всем, кто причастен к маркетингу и ищет новые подходы, поскольку здесь мы поделимся инсайтами, родившимися в процессе исследования.
В результате анализа собранных данных удалось выяснить, что, например, аудитория автомобилей европейского бренда предпочитает бутилированную воду, товары для взрослых Durex и электронику Apple, закупается большими партиями продуктов в магазинах Metro Cash and Carry. Аудитория азиатского автопроизводителя покупает фильтры для воды, товары для взрослых бренда Contex, оптимизирует затраты на электронику и не отрицает китайские марки, часто пользуется услугами онлайн-оплаты топлива.
Чтобы подтвердить наши выводы по автомобильному бренд-анализу, мы провели аналогичное исследование для более массового продукта — детских подгузников. Для трех брендов подгузников, американских Huggies и Pampers, а также китайского Yokosun с применением нашего подхода были также выявлены бренды-спутники. В результате мы выяснили, что у приверженцев каждой из торговых марок подгузников есть явные предпочтения среди детских косметических брендов, продуктов питания, бытовой техники и электроники. Например, аудитория Yokosun предпочитает корейские косметические бренды (такие, как Elizavecca), Huggies — бренд детской косметики Bubchen, а Pampers — чаще ищет скидки на другие товары.
Этот подход работает для любых товаров и услуг. По нашей оценке, для других категорий товаров примерами таких спутников могут быть конкретные бренды в сегментах:
одежда + косметика,
спортивные товары + питание,
обувь + путешествия,
финансовые услуги + автомобили,
спецпитание + одежда.
В процессе своей работы мы получили неочевидные аудиторные знания, которые креативные маркетологи могут эффективно использовать. Каким же образом? Давайте рассмотрим примеры.
Таргетинг и поиск новых сегментов. Кампания со специальным предложением, таргетинг которой настроен на аудиторию бренда-спутника. Например, любители подгузников Huggies часто покупают ополаскиватель R.O. C.S. Зная это, можно запустить акцию на сегмент покупателей ополаскивателя бренда. Наше предложение для акции: «Если вы приобретаете R.O. C.S., то получаете скидку на покупку Huggies». Таким образом, можно находить новые сегменты и настраивать на них таргетинг. Здесь есть возможность и для стимулирования продаж подгузников Pampers. Как вариант — кампания конкурента с таргетингом на аудиторию Huggies: «При покупке подгузников Pampers ополаскиватель R.O. C.S. — в подарок».
Программы лояльности и премирование. Премирование наилучшим образом срабатывает, когда клиенту интересен и важен бренд подарка. Это стимулирует лояльность и включение так называемого сарафанного радио с положительным отзывом от компании-дарителе. Наш отчет показал, что владельцы европейского бренда автомобиля часто делают покупки большими партиями в магазинах определенной торговой сети. Идея торгового предложения для такой аудитории — при покупке или премиальном обслуживании автомобиля вручается подарочная карта сети.
Коллаборации брендов и расширение аудитории. Бренд-анализ также применим в коллаборации брендов. Например, сейчас коллаборации популярны среди производителей одежды и аксессуаров. Бренды, с различным позиционированием, но аффинитивные друг другу (например, бренд одежды в стиле кэжуал и спортивный бренд) запускают совместные коллекции. Подобные коллаборации для расширения аудитории, как правило, очень успешны.
Трейд-маркетинг и выкладка товаров. Кроме производителей товаров воспользоваться результатами исследования могут и ритейлеры. Информацию о брендах-спутниках можно использовать при выкладке товаров в магазинах. А именно ставить рядом на полках товары, которые аффинитивны друг другу.
Таким образом бренд-анализ помогает выявить заметные корреляции интересов и на их основании изменить существующие, разрабатывать новые кампании, коллаборации брендов и системы премирования в программах лояльности.
Вывод
Более пристальное изучение целевой аудитории особенно важно в условиях, когда нужно пересматривать подходы в маркетинге, уходить от экстенсивных к интеллектуальным методам продвижения. Практика CleverData Science предоставляет актуальные инструменты для маркетинга, который должен быть эффективным в заданных обстоятельствах. Бренд-анализ — один из таких инструментов, потому что это быстро, точно и дает неочевидные инсайты о целевой аудитории.
Опираясь на это знание, вы сможете разрабатывать новые предложения и более эффективные персонализированные кампании. Это подтверждает наш опыт работы. Например, персонализация для кампании с ретаргетингом, которую запустил европейский производитель автомобилей, дала в итоге рост конверсии на 37%. А в одной из сети оптик персонализация позволила увеличить в два раза объем повторных продаж в канале email-рассылок по собственной базе.
Если вы хотите следить за нашими новостями и узнавать об интересных решениях для управления данными, заходите на каналы CleverData в социальных сетях: Telegram, In, vk, Youtube
Статья подготовлена при участии: @Alex643, @Crytox, @itisdanil.
