Непрерывная инфраструктура в облаке
Демонстрация использования инструментов с открытым исходным кодом, таких как Packer и Terraform, для непрерывной поставки изменений инфраструктуры в любимую пользователями облачную среду.
Материал подготовлен на основе выступления Пола Стека (Paul Stack) на нашей осенней конференции DevOops 2017. Пол — инфраструктурный разработчик, который раньше работал в HashiCorp и участвовал в разработке инструментов, используемых миллионами людей (например, Terraform). Он часто выступает на конференциях и доносит практику с переднего края внедрений CI/CD, принципы правильной организации operations-части и умеет доходчиво рассказать, зачем вообще админам этим заниматься. Далее в статье повествование ведется от первого лица.
Итак, начнем сразу с нескольких ключевых выводов.
Долгоработающие сервера — отстой

Ранее я работал в организации, где мы развернули Windows Server 2003 еще в 2008 году, и сегодня они по-прежнему в продакшне. И такая компания не одна. Используя удаленный рабочий стол на этих серверах, на них устанавливают ПО вручную, загружая бинарные файлы из интернета. Это очень плохая идея, потому что серверы получаются нетиповые. Вы не можете гарантировать, что в продакшене происходит то же самое, что и в вашей среде разработки, в промежуточной среде, в среде QA.
Неизменяемая инфраструктура
В 2013 году появилась статья в блоге Чада Фоилера «Выбросьте ваши серверы и сожгите код: неизменяемая инфраструктура и одноразовые компоненты» (Chad Foiler «Trash your servers and burn your code: immutable infrastructure and disposable components»). Это разговор по большей части о том, что неизменяемая инфраструктура — это путь вперед. Мы создали инфраструктуру, а если нам нужно ее изменить, мы создаем новую инфраструктуру. Такой подход очень распространен в облаке, потому что здесь это быстро и дешево. Если у вас есть физические центры обработки данных, это немного сложнее. Очевидно, если вы запускаете виртуализацию ЦОД, все становится проще. Однако, если вы все еще каждый раз запускаете физические серверы, для ввода нового требуется немного больше времени, чем для изменения существующего.
Одноразовая инфраструктура
По мнению функциональных программистов, «неизменяемая» — на самом деле неправильный термин для этого явления. Поскольку, чтобы быть действительно неизменяемой, вашей инфраструктуре нужна файловая система «только для чтения»: никакие файлы не будут записаны локально, никто не сможет использовать SSH или RDP и т.д. Таким образом, похоже, что на самом деле инфраструктура не является неизменяемой.
Терминология обсуждалась в Twitter в течение шести или даже восьми дней несколькими людьми. В итоге они пришли к согласию, что «одноразовая инфраструктура» — это более подходящая формулировка. Когда жизненный цикл «одноразовой инфраструктуры» заканчивается, ее можно легко уничтожить. Вам не нужно за нее держаться.
Приведу аналогию. Коров на фермах обычно не рассматривают как домашних питомцев.

Когда у вас на ферме есть крупный рогатый скот, вы не даете ему индивидуальные имена. У каждой особи есть номер и бирка. Так же и с серверами. Если у вас в продакшне все еще есть серверы, созданные вручную в 2006 году, они имеют значимые имена, например «база данных SQL на продакшне 01». И у них очень специфический смысл. И если один из серверов падает, начинается ад.
Если одно из животных стада умирает, фермер просто покупает новое. Это и есть «одноразовая инфраструктура».
Непрерывная поставка
Итак, как это объединить с непрерывной поставкой (Continuous Delivery)?
Все, о чем я сейчас рассказываю, существует довольно давно. Я лишь пытаюсь совместить идеи развития инфраструктуры и разработки программного обеспечения.
Разработчики ПО в течение долгого времени практикуют непрерывную поставку и непрерывную интеграцию. Например, Мартин Фаулер (Martin Fowler) писал о непрерывной интеграции в своем блоге еще в начале 2000-х годов. Джез Хамбл (Jez Humble) долгое время продвигал непрерывную поставку.
Если вы присмотритесь внимательнее, здесь нет ничего созданного специально для исходного кода ПО. Есть стандартное определение из «Википедии»: непрерывная поставка — это набор практик и принципов, направленных на создание, тестирование и выпуск программного обеспечения максимально быстро.
Определение не говорит о веб-приложениях или API, это о программном обеспечении в целом. Для создания работающего программного обеспечения требуется много кусочков головоломки. Таким образом вы можете точно так же практиковать непрерывную поставку для кода инфраструктуры.
Разработка инфраструктуры и приложений — довольно близкие направления. И люди, которые пишут код приложений, также пишут код инфраструктуры (и наоборот). Эти миры начинают объединяться. Больше нет такого разделения и специфических ловушек каждого из миров.
Принципы и практики непрерывной поставки
Непрерывная поставка имеет ряд принципов:
- Процесс выпуска / развертывания программного обеспечения должен быть повторяемым и надежным.
- Автоматизируйте все!
- Если какая-то процедура сложна или болезненна, выполняйте ее чаще.
- Держите все в системе управления версиями.
- Сделано — значит «зарелизено».
- Интегрируйте работу с качеством!
- Каждый несет ответственность за процесс выпуска.
- Повышайте непрерывность.
Но гораздо важнее, что непрерывная поставка имеет четыре практики. Возьмите их и перенесите непосредственно в инфраструктуру:
- Создавайте бинарные файлы только один раз. Создайте свой сервер один раз. Здесь речь об «одноразовости» с самого начала.
- Используйте одинаковый механизм развертывания в каждой среде. Не практикуйте разный деплой в разработке и на продакшне. Вы должны использовать один и тот же путь в каждой среде. Это очень важно.
- Протестируйте ваш деплой. Я создал много приложений. Я создавал множество проблем, потому что не следил за механизмом деплоя. Всегда надо проверять, что происходит. И я не говорю, что вы должны потратить пять или шесть часов на масштабное тестирование. Достаточно «дымового теста». У вас есть ключевая часть системы, которая, как вы знаете, позволяет вам и вашей компании зарабатывать деньги. Не поленитесь запустить тестирование. Если вы этого не сделаете, могут возникнуть перебои, которые будут стоить вашей компании денег.
- И наконец, самое главное. Если что-то сломалось, остановитесь и исправьте это немедленно! Вы не можете допустить, чтобы проблема росла и становилась все хуже и хуже. Вы должны это исправить. Это действительно важно.
Кто-нибудь читал книгу «Continuous delivery»?

Я уверен, ваши компании оплатят вам экземпляр, который вы сможете передавать внутри команды. Я не говорю, что вы должны сесть и потратить выходной день на ее прочтение. Если вы это сделаете, вероятно, вы захотите уйти из ИТ. Но я рекомендую периодически осваивать небольшие кусочки книги, переваривать их и думать о том, как перенести это на свою среду, в свою культуру и в свой процесс. Один маленький кусочек за раз. Потому что непрерывная поставка — это разговор о постоянном улучшении. Это не просто сесть в офисе вместе с коллегами и боссом и начать разговор с вопроса: «Как мы будем внедрять непрерывную поставку?», потом написать 10 вещей на доске и через 10 дней понять, что вы ее реализовали. Это занимает много времени, вызывает много протестов, поскольку по мере внедрения меняется культура.
Сегодня мы будем использовать два инструмента: Terraform и Packer (оба — разработки Hashicorp). Дальнейший рассказ будет о том, почему мы должны использовать Terraform и как интегрировать его в свою среду. Я не случайно говорю об этих двух инструментах. До недавнего времени я также работал в Hashicorp. Но даже после того как я покинул Hashicorp, я все еще вношу вклад в код этих инструментов, потому что на самом деле считаю их очень полезными.
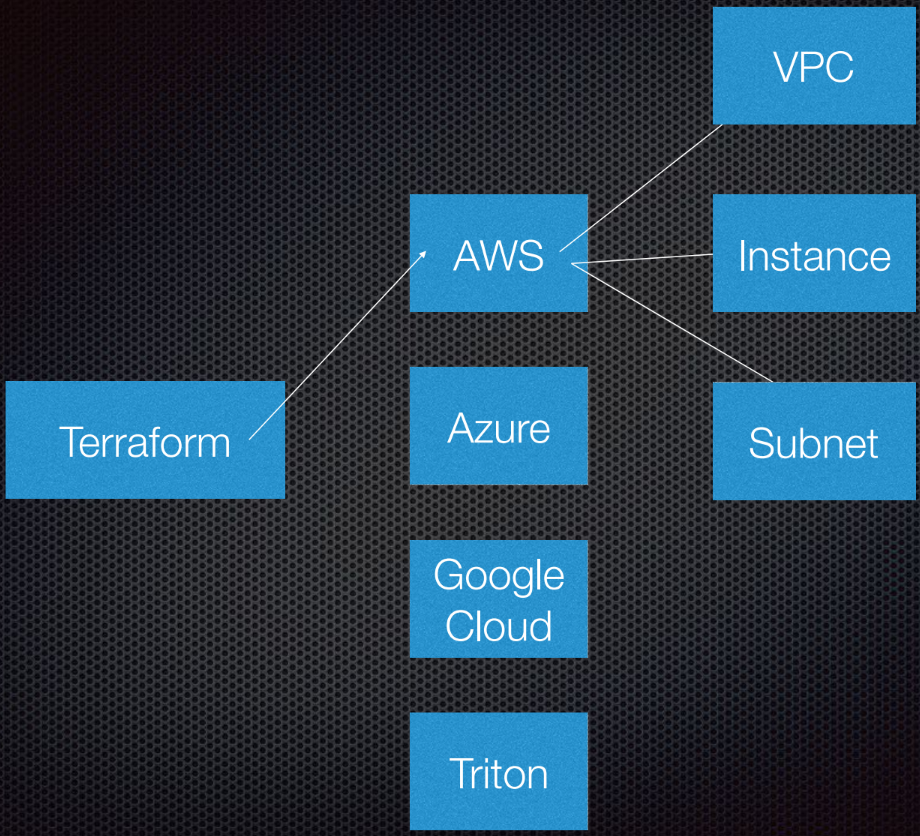
Terraform поддерживает взаимодействие с провайдерами. Провайдеры — это облака, Saas-сервисы и т.п.
Внутри каждого поставщика облачных услуг есть несколько ресурсов, например подсеть, VPC, балансировщик нагрузки и т. д. С помощью DSL (предметно-ориентированный язык, domain-specific language) вы указываете Terraform, как будет выглядеть ваша инфраструктура.
Terraform использует теорию графов.

Вероятно, вы знаете теорию графов. Узлы — это части нашей инфраструктуры, например балансировщик нагрузки, подсеть или VPC. Ребра — это отношения между этими системами. Это все, что я лично считаю необходимым знать о теории графов для использования Terraform. Остальное оставим экспертам.

Terraform на самом деле использует направленный граф, потому что он знает не только взаимоотношения, но и их порядок: что A (предположим, что A — VPC) должен быть установлен до B, который является подсетью. И B должен быть создан до C (инстанс), потому что есть предписанный порядок создания абстракций в Amazon или любом другом облаке.
Более подробная информация по этой теме есть в YouTube Пола Хензе (Paul Hinze), который все еще работает в Hashicorp директором по инфраструктуре. По ссылке — прекрасная беседа об инфраструктуре и теории графов.
Практика
Напишем код, это гораздо лучше, чем обсуждать теорию.
Ранее я создал AMI (Amazon Machine Images). Для их создания я использую Packer и собираюсь показать вам, как это делается.
AMI — это экземпляр виртуального сервера в Amazon, он предопределен (в плане конфигурации, приложений и т. п.) и создается из образа. Мне нравится, что я могу создать новые AMI. По сути, AMI — это мои контейнеры Docker.
Итак, у меня есть AMI, у них есть ID. Отправившись в интерфейс Amazon, мы видим, что у нас есть всего один AMI и ничего больше:

Я могу показать вам, что находится в этом AMI. Все очень просто.
У меня есть шаблон JSON-файла:
{
"variables": {
"source_ami": "",
"region": "",
"version": ""
},
"builders": [{
"type": "amazon-ebs",
"region": "{{user ‘region’}}",
"source_ami": "{{user ‘source_ami’}}",
"ssh_pty": true,
"instance_type": "t2.micro",
"ssh_username": "ubuntu",
"ssh_timeout": "5m",
"associate_public_ip_address": true,
"ami_virtualization_type": "hvm",
"ami_name": "application_instance-{{isotime \"2006-01-02-1504\"}}",
"tags": {
"Version": "{{user ‘version’}}"
}
}],
"provisioners": [
{
"type": "shell",
"start_retry_timeout": "10m",
"inline": [
"sudo apt-get update -y",
"sudo apt-get install -y ntp nginx"
]
},
{
"type": "file",
"source": "application-files/nginx.conf",
"destination": "/tmp/nginx.conf"
},
{
"type": "file",
"source": "application-files/index.html",
"destination": "/tmp/index.html"
},
{
"type": "shell",
"start_retry_timeout": "5m",
"inline": [
"sudo mkdir -p /usr/share/nginx/html",
"sudo mv /tmp/index.html /usr/share/nginx/html/index.html",
"sudo mv /tmp/nginx.conf /etc/nginx/nginx.conf",
"sudo systemctl enable nginx.service"
]
}
]
}
У нас есть переменные, которые мы передаем, а у Packer есть список так называемых Builders для разных областей; их множество. Builder использует специальный источник AMI, который я передаю в AMI-идентификаторе. Я даю ему имя пользователя и пароль SSH, а также указываю, нужен ли ему публичный IP-адрес, чтобы люди могли получить к нему доступ извне. В нашем случае это не имеет особого значения, потому что это инстанс AWS для Packer.
Также мы задаем имя AMI и теги.
Вам необязательно разбирать этот код. Он здесь только для того, чтобы показать вам, как он работает. Самая важная часть здесь — это версия. Она станет актуальной позже, когда мы войдем в Terraform.
После того как builder вызывает инстанс, на нем запускаются провизионеры. Я фактически устанавливаю NCP и nginx, чтобы показать вам, что я могу здесь сделать. Я копирую некоторые файлы и просто настраиваю конфигурацию nginx. Все очень просто. Затем активирую nginx, чтобы он стартовал при запуске инстанса.
Итак, у меня есть сервер приложений, и он работает. Я могу его использовать в будущем. Однако я всегда проверяю свои шаблоны Packer. Потому что это JSON-конфигурация, где вы можете столкнуться с некоторыми проблемами.
Чтобы это сделать, я запускаю команду:
make validate
Получаю ответ, что шаблон Packer проверен успешно:
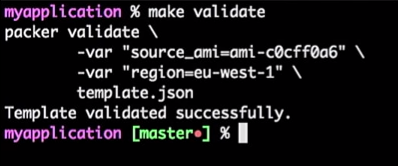
Это всего лишь команда, поэтому я могу подключить ее к инструменту CI (любому). Фактически это будет процесс: если разработчик изменит шаблон, будет сформирован pull request, инструмент CI проверит запрос, выполнит эквивалент проверки шаблона и опубликует шаблон в случае успешной проверки. Все это можно объединить в «Мастер».
Получаем поток для шаблонов AMI — нужно просто поднять версию.
Предположим, что разработчик создал новую версию AMI.
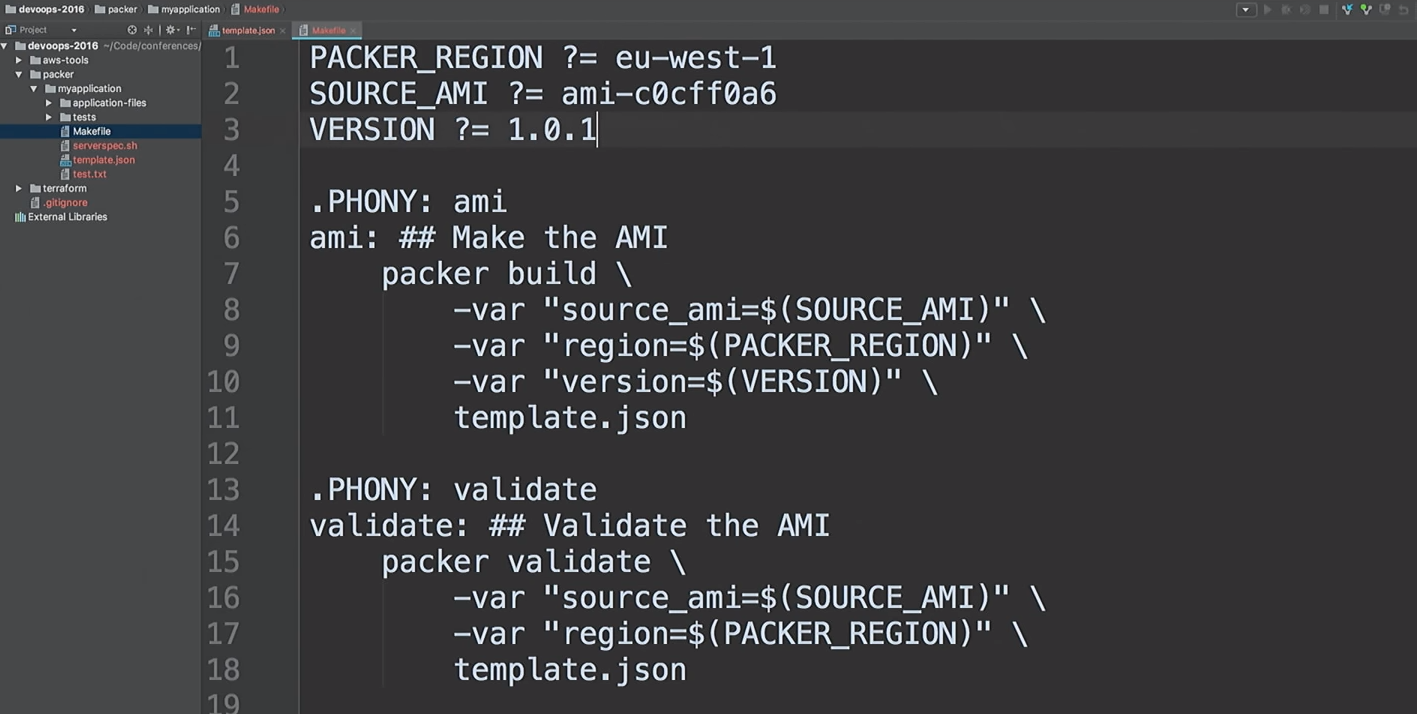
Я просто поправлю версию в файлах с 1.0.0 на 1.0.1, чтобы показать вам разницу:
Welcome to DevOops!
Welcome!
Welcome to DevOops!
Version: 1.0.1
Вернусь в командную строку и запущу создание AMI.
Я не люблю запускать одни и те же команды. Мне нравится создавать AMI быстро, поэтому я использую make-файлы. Давайте заглянем при помощи cat в мой make-файл:
cat Makefile

Это мой make-файл. Я даже предусмотрел Help: я набираю make и нажимаю табуляцию, и он мне показывает все target.

Итак, мы собираемся создать новый AMI версии 1.0.1.
make ami

Вернемся к Terraform.
Акцентирую внимание, что это не код с продакшена. Это демонстрация. Есть способы сделать то же самое лучше.
Я везде использую модули Terraform. Поскольку я больше не работаю на Hashicorp, поэтому могу высказать свое мнение про модули. Для меня модули находятся на уровне инкапсуляции. Например, мне нравится инкапсулировать все, что связано с VPC: сети, подсети, таблицы маршрутизации и т. п.
Что происходит внутри? Разработчики, которые с этим работают, могут не заботиться об этом. Им нужно иметь общие представления о том, как работает облако, что такое VPC. Но совершенно не обязательно вникать в детали. Только люди, которым действительно нужно изменить модуль, должны в нем разбираться.
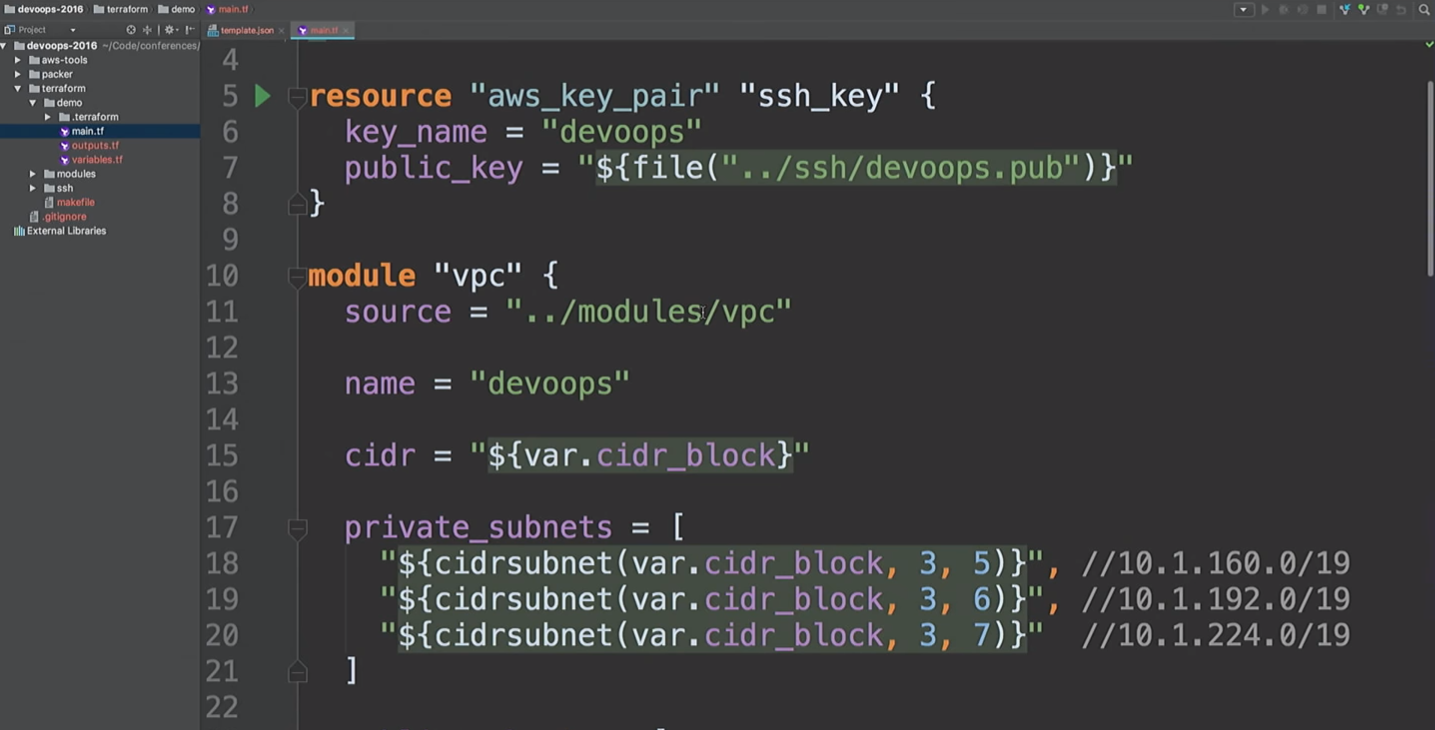

Здесь я собираюсь создать AWS resource и модуль VPC. Что тут происходит? Берется cidr_block верхнего уровня и создаются три частные подсети и три публичные подсети. Далее берется список acailability_zones. Но мы не знаем, что это за зоны доступности.

Мы собираемся создать VPN. Только не используйте этот модуль VPN. Это openVPN, который создает один инстанс AWS, не имеющий сертификата. Он использует только публичный IP-адрес и упомянут здесь лишь для того, чтобы показать вам, что мы можем подключиться к VPN. Существуют более удобные инструменты для создания VPN. Мне потребовалось около 20 минут и два пива, чтобы написать собственный.
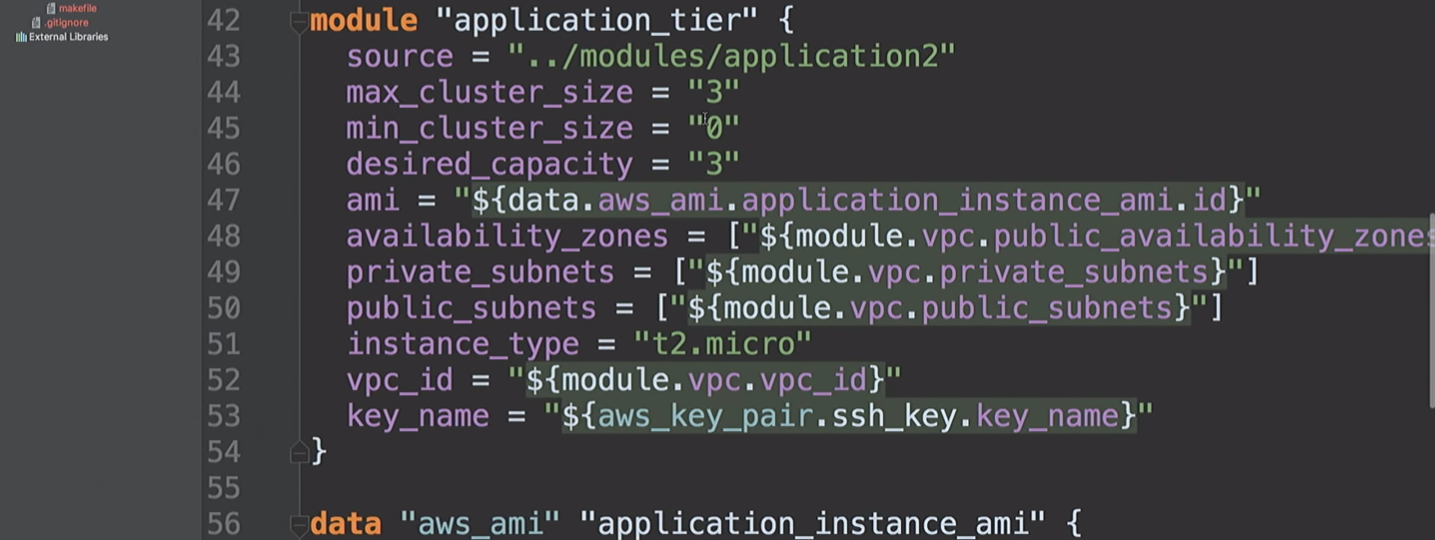


Затем мы создаем application_tier, который является auto scaling group — балансировщиком нагрузки. Некоторая конфигурация запуска основана на AMI-ID, и она объединяет несколько подсетей и зон доступности, а также использует SSH-ключ.
Вернемся к этому через секунду.
Ранее я уже упоминал зоны доступности. Они отличаются для разных учетных записей AWS. Моя учетная запись в США на Востоке может иметь доступ к зонам A, B и D. Ваша учетная запись AWS может иметь доступ к B, C и E. Таким образом, фиксируя эти значения в коде, мы будем сталкиваться с проблемами. Мы в Hashicorp предположили, что можем создать такие источники данных, чтобы можно было запросить у Amazon, что именно доступно для нас. Под капотом мы запрашиваем описание зон доступности, а затем возвращаем список всех зон для вашей учетной записи. Благодаря этому мы можем использовать источники данных для AMI.
Теперь мы добрались до сути моей демонстрации. Я создал auto scaling group, в которой запущены три инстанса. По умолчанию все они имеют версию 1.0.0.
Когда мы задеплоим новую версию AMI, я снова запущу конфигурацию Terraform, это изменит конфигурацию запуска, и новый сервис получит следующую версию кода и т. д. И мы можем этим управлять.

Мы видим, что работа Packer закончена и у нас есть новый AMI.
Я возвращаюсь к Amazon, обновляю страницу и вижу второй AMI.

Вернемся к Terraform.
Начиная с версии 0.10 Terraform разбил провайдеров по отдельным репозиториям. И команда init terraform получает копию провайдера, который нужен для запуска.

Провайдеры загружены. Мы готовы двигаться вперед.
Далее мы должны выполнить terraform get — загрузить необходимые модули. Они сейчас находятся на моей локальной машине. Так что Terraform получит все модули на локальном уровне. Вообще модули могут храниться в их собственных репозиториях на GitHub или где-то еще. Именно поэтому я говорил о модуле VPC. Вы можете дать команде сетевиков доступ для внесения изменений. И это API для команды разработчиков для совместной работы с ними. Действительно полезно.
Следующим шагом мы хотим построить граф.
Начнем сterraform plan

Terraform возьмет текущее локальное состояние и сравнит с учетной записью AWS, указав различия. В нашем случае он создаст 35 новых ресурсов.
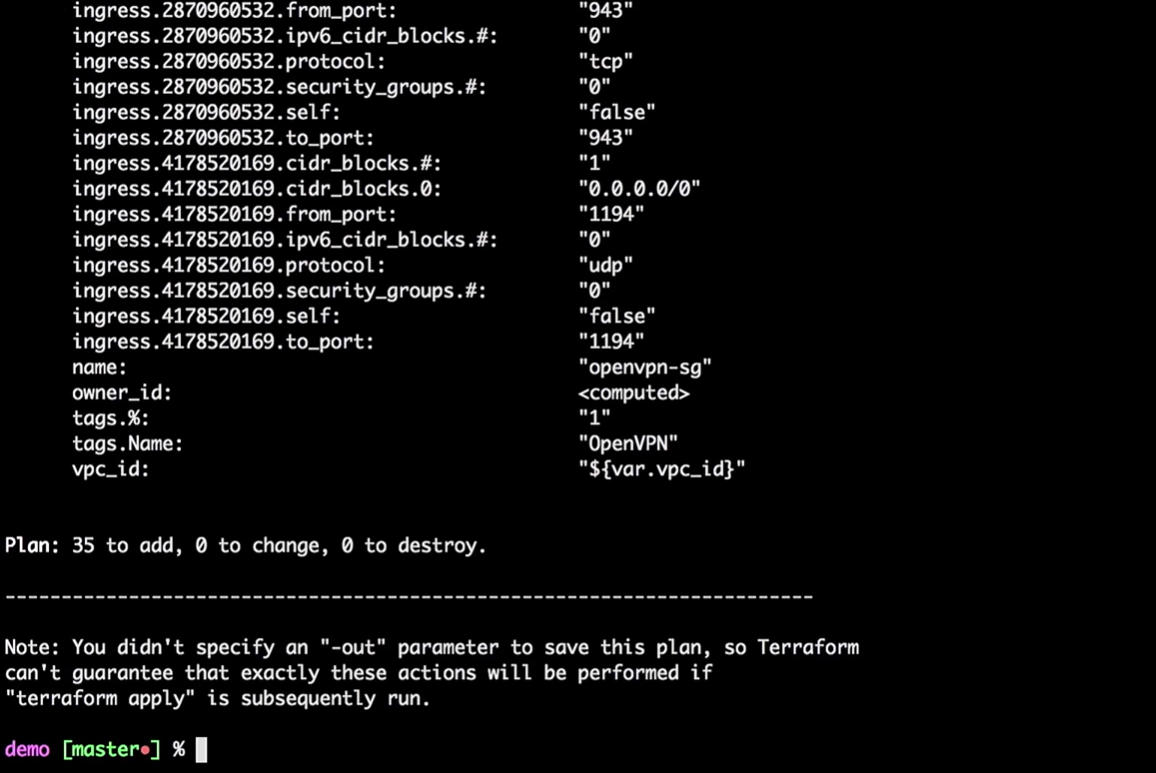
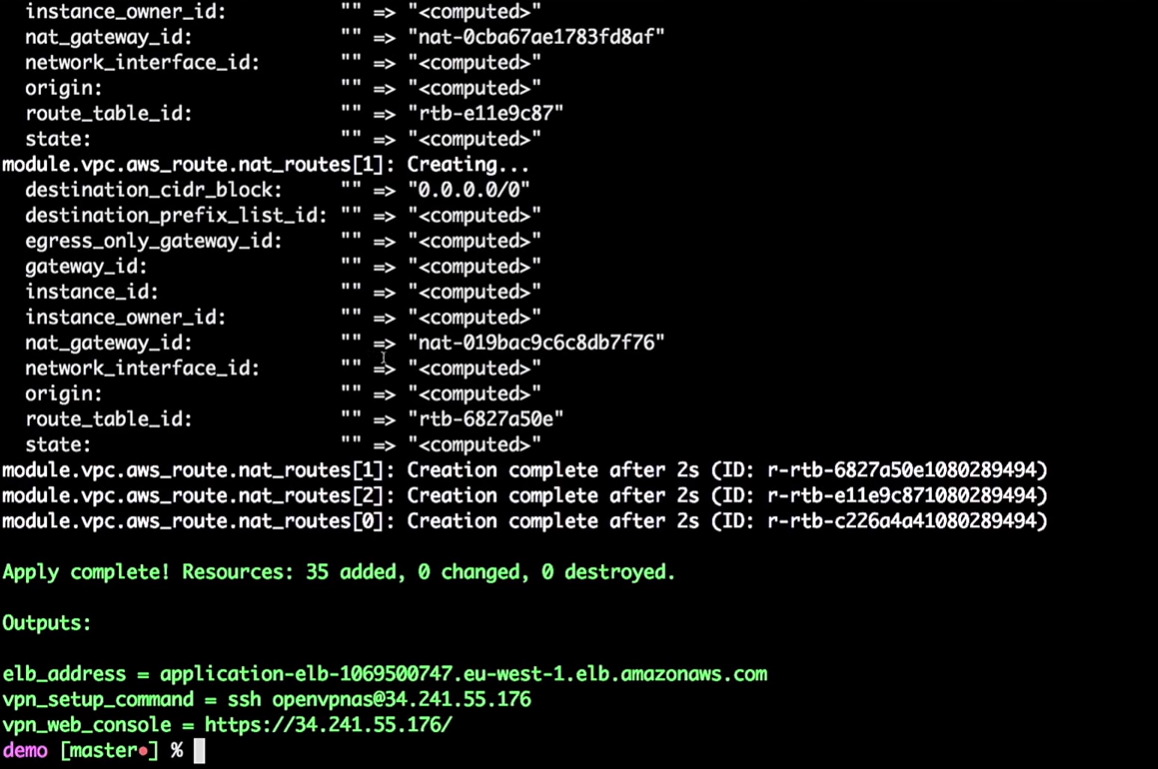
Теперь мы применим изменения:
terraform apply
Вам необязательно делать все это с локальной машины. Это просто команды, передача переменных в Terraform. Вы можете перенести этот процесс в инструменты CI.
Если вы хотите переместить это в CI, вы должны использовать удаленное состояние. Я бы хотел, чтобы все, кто когда-либо использует Terraform, работали с удаленным состоянием. Пожалуйста, не используйте локальное состояние.
Один из моих приятелей отметил, что даже после всех лет работы с Terraform он все еще открывает для себя что-то новое. Например, если вы создаете инстанс AWS, вам нужно предоставить ему пароль, и он может сохранить его в вашем состоянии. Когда я работал в Hashicorp, мы предполагали, что будет совместный процесс, который изменяет этот пароль. Поэтому не старайтесь хранить все локально. И тогда вы сможете поместить все это в инструменты CI.
Итак, инфраструктура для меня создана.

Terraform может построить граф:
terraform graph
Как я сказал, он строит дерево. Фактически он и вам дает возможность оценить, что происходит в вашей инфраструктуре. Он покажет вам отношения между всеми разными частями — все узлы и ребра. Поскольку связи имеют направления, мы говорим о направленном графе.
Граф будет представлять собой JSON-список, который можно сохранить в PNG- или DOC-файле.
Вернемся в Terraform. У нас действительно создается auto scaling group.

Группа Auto scaling group имеет емкость 3.

Интересный вопрос: можем ли мы использовать Vault для управления секретами в Terraform? Увы, нет. Нет источника данных Vault для чтения секретов в Terraform. Существуют другие способы, например переменные среды. С их помощью вам не нужно вводить секреты в код, можно читать их как переменные среды.
Итак, у нас есть некоторые объекты инфраструктуры:
Вхожу в мой очень секретный VPN (не взламывайте мои VPN).
Самое главное здесь, что у нас есть три экземпляра приложения. Мне, правда, стоило отметить, какая версия приложения на них запущена. Это очень важно.
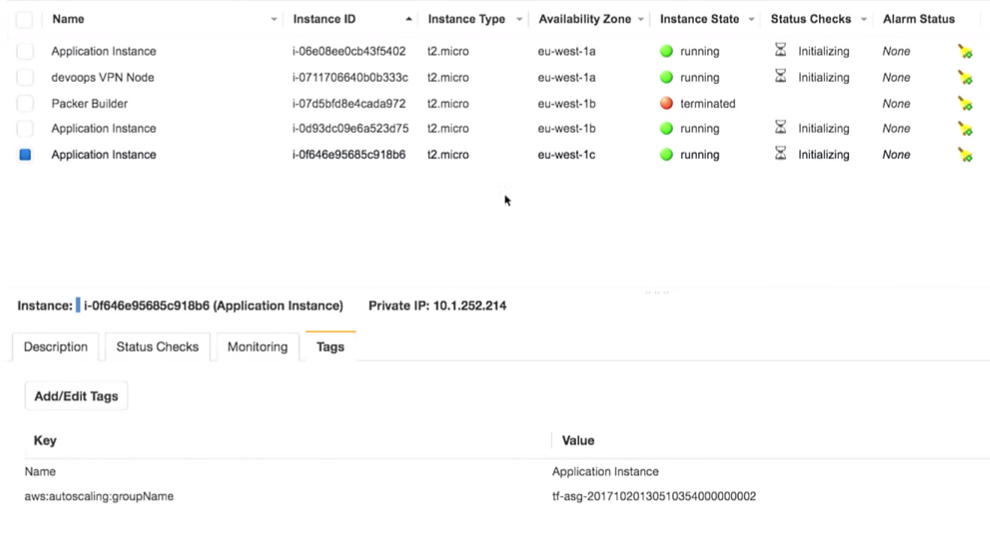
Все действительно находится за VPN:

Если я возьму это (application-elb-1069500747.eu-west-1.elb.amazonaws.com) и вставлю в адресную строку браузера, получу следующее:

Напомню, я подключен к VPN. Если я выйду из системы, указанный адрес будет недоступен.
Мы видим версию 1.0.0. И сколько бы мы не обновляли страницу, мы получаем 1.0.0.
Что произойдет, если в коде изменю версию с 1.0.0 до 1.0.1?
filter {
name = "tag:Version"
values = ["1.0.1"]
}
Очевидно, инструменты CI обеспечат вам создание нужной версии.
Отмечу, никаких ручных обновлений! Мы неидеальны, делаем ошибки и можем поставить при ручном обновлении версию 1.0.6 вместо 1.0.1.
filter {
name = "tag:Version"
values = ["1.0.6"]
}
Но перейдем к нашей версии (1.0.1).
terraform plan
Terraform обновляет состояние:
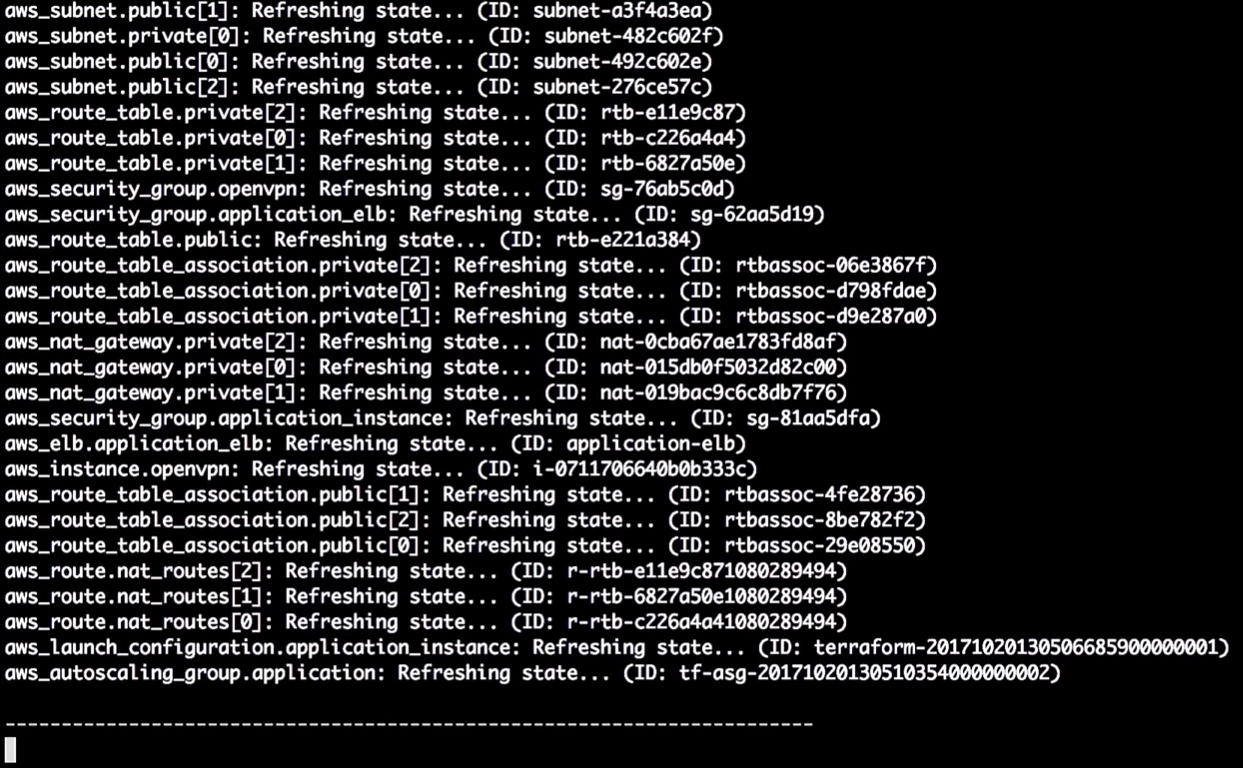

Итак, в этот момент он говорит мне, что собирается изменить в конфигурации запуска версию. Из-за изменения идентификатора он будет принудительно перезапускать конфигурацию, при этом изменится auto scaling group (это необходимо, чтобы включить новую конфигурацию запуска).
Это не изменяет запущенные инстансы. Это действительно важно. Вы можете следить за этим процессом и тестировать его, не изменяя инстансы в продакшене.
Замечание: вы всегда должны создать новую конфигурацию запуска, прежде чем уничтожить старую, иначе будет ошибка.
Давайте применим изменения:
terraform apply
Теперь вернемся к AWS. Когда все изменения применены, мы заходим в auto scaling group.
Перейдем к конфигурации AWS. Мы видим, что есть три инстанса с одной конфигурацией запуска. Они одинаковые.
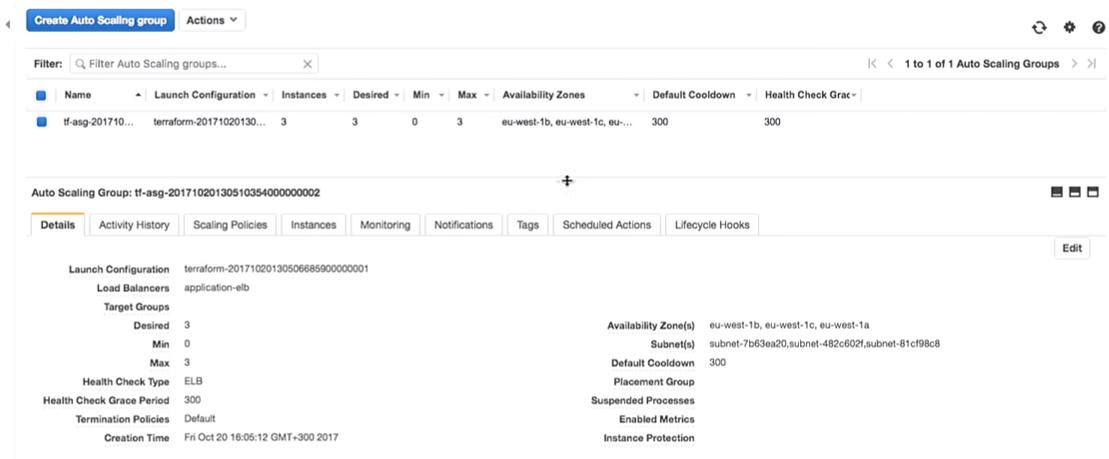
Amazon гарантирует нам, что, если мы захотим запустить три экземпляра службы, они действительно будут запущены. Вот почему мы платим им деньги.
Перейдем к экспериментам.
Была создана новая конфигурацию запуска. Поэтому, если я удалю один из инстансов, остальные не будут повреждены. Это важно. Однако если вы используете инстансы напрямую, при этом изменяете данные пользователя, это уничтожит «живые» инстансы. Пожалуйста, не делайте этого.
Итак, удалим один из инстансов:

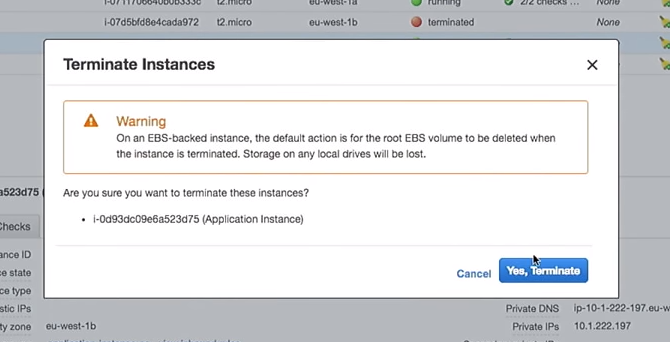
Что произойдет в auto scaling group, когда он выключится? На его месте появится новый инстанс.
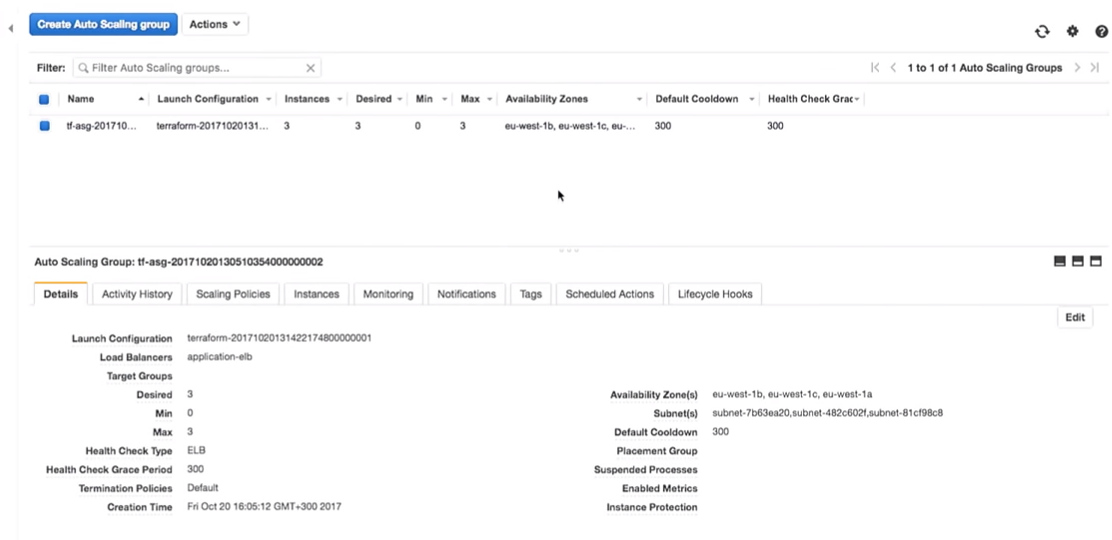
Здесь вы попадаете в интересную ситуацию. Инстанс будет запущен с новой конфигурацией. То есть в системе у вас может оказаться несколько разных образов (с разной конфигурацией). Иногда лучше не сразу удалять старую конфигурацию запуска, чтобы подключать по необходимости.
Здесь все становится еще интереснее. Почему бы не делать это с помощью скриптов и инструментов CI, а не вручную, как я показываю? Есть инструменты, которые могут это сделать, например отличный AWS-missing-tools на GitHub.

И что делает этот инструмент? Это bash-сценарий, который проходит по всем инстансам в балансировщике нагрузки, уничтожает их по одному, обеспечивая создание новых на их месте.
Если я потерял один из своих инстансов с версией 1.0.0 и появился новый — 1.1.1, я захочу убить все 1.0.0, переведя все на новую версию. Потому что я всегда двигаюсь вперед. Напомню, мне не нравится, когда сервер приложений живет долгое время.
В одном из проектов каждые семь дней у меня срабатывал управляющий скрипт, который уничтожал все инстансы в моей учетной записи. Так что серверу было не более семи дней. Еще одна вещь (моя любимая) — помечать с помощью SSH in a box серверы как «запятнанные» и каждый час уничтожать их с помощью скрипта — мы же не хотим, чтобы люди делали это вручную.
Подобные управляющие скрипты позволяют всегда иметь последнюю версию с исправленными багами и обновлениями безопасности.
Вы можете использовать скрипт, просто запуская:
aws-ha-relesae.sh -a my-scaling-group
-a — это ваша auto scaling group. Скрипт пройдет по всем инстансам вашей auto scaling group и заменит его. Запускать его можно не только вручную, но и из инструмента CI.
Вы можете сделать это в QA или на продакшене. Вы можете сделать это даже в локальной учетной записи AWS. Вы делаете все, что захотите, каждый раз используя один и тот же механизм.
Вернемся в Amazon. У нас появился новый инстанс:

Обновив страницу в браузере, где мы ранее видели версию 1.0.0, получаем:

Интересная вещь заключается в том, что, поскольку мы создали сценарий создания AMI, мы можем протестировать создание AMI.
Есть несколько прекрасных инструментов, например ServerScript или Serverspec.
Serverspec позволяет создавать спецификации в стиле Ruby, чтобы проверить, как выглядит ваш сервер приложений. Например, ниже я привожу тест, который проверяет, что nginx установлен на сервере.
require ‘spec_helper’
describe package(‘nginx’) do
it { should be_installed }
end
describe service(‘nginx’) do
it { sould be_enabled }
it { sould be_running }
end
describe port(80) do
it { should be_listening }
end
Nginx должен быть установлен и запущен на сервере и слушать 80-й порт. Вы можете сказать, что пользователь X должен быть доступен на сервере. И вы можете поставить все эти тесты на свои места. Таким образом, когда вы создаете AMI, CI-инструмент может проверить, подходит ли этот AMI для заданной цели. Вы будете знать, что AMI готов к продакшену.
Вместо заключения
Мэри Поппендьек (Mary Poppendieck), вероятно, одна из самых удивительных женщин, о которых я когда-либо слышал. В свое время она рассказывала о том, как в течение многих лет развивалась бережливая разработка программного обеспечения. И о том, как она была связана с 3M в 60-х, когда компания действительно занималась бережливой разработкой.
И она задала вопрос: сколько времени потребуется вашей организации для развертывания изменений, связанных с одной строкой кода? Можете ли вы сделать этот процесс надежным и легкоповторяемым?
Как правило, этот вопрос всегда касался кода ПО. Сколько времени мне понадобится, чтобы устранить одну ошибку в этом приложении при развертывании на продакшене? Но нет причин, почему мы не можем использовать тот же вопрос применительно к инфраструктуре или базам данных.
Я работал в компании под названием OpenTable. В ней мы это называли длительностью цикла. И в OpenTable она была семь недель. И это относительно хорошо. Я знаю компании, которым требуются месяцы, когда они отправляют код в продакшен. В OpenTable мы пересматривали процесс четыре года. Это заняло много времени, поскольку организация большая — 200 человек. И мы сократили длительность цикла до трех минут. Удалось это благодаря измерениям эффекта от наших преобразований.
Сейчас уже всё заскриптовано. У нас так много инструментов и примеров, есть GitHub. Поэтому берите идеи с конференций, подобных DevOops, внедряйте в вашей организации. Не пытайтесь реализовать все. Возьмите одну крошечную вещь и реализуйте ее. Покажите кому-нибудь. Влияние небольшого изменения можно измерить, измеряйте и двигайтесь дальше!
Пол Стек приедет в Петербург на конференцию DevOops 2018 с докладом «Sustainable system testing with Chaos». Пол расскажет о методологии Chaos Engineering и покажет, как пользоваться этой методологией на реальных проектах.
