Нейрозапятые, или как мы оставили своих редакторов без работы (ну почти)

Всем привет, меня зовут Владислав Соболев — ML-инженер в компании «БАРС Груп». Сегодня я хотел бы рассказать о том, зачем и как мы расставляем знаки препинания в текстах, сравним аналоги, и посмотрим на то, как устроена работа инструмента, который мы написали, чтобы обучать такого рода модели (ссылочка в самом конце). Начнем!
Зачем?
У нас в компании есть ряд ML-проектов, внутри которых используется анализ текста, в том числе и надиктованного голосом. Мы командой долго думали над тем, как можно реализовать данные проекты.
В итоге пришли к выводу, что проще всего для наших целей проводить лингвистический анализ текста искать в нём слова-действия, такие как «сгруппируй», «покажи», определять связи и зависимости между словами, искать ключевые слова, ранжировать их. И на основе всех этих данных — взаимодействовать с сервисами.
Сначала для анализа текста мы используем библиотеку SpaCy v3, в ней есть модель для русского языка, а также удобное API, в том числе и для поиска зависимостей слов. Мы также искали, тестировали и сравнивали другие библиотеки/модели для русского языка, которые работают out-of-the-box. Например, модель от DeepPavlov показывала примерно такие же результаты, как и парсер от SpaCy, местами даже лучше, но у SpaCy более удобное API, и модель весит меньше.
Необходимым условием для корректного синтаксического разбора моделями, определяющих зависимости слов, которые мы тестировали, являются знаки препинания, которых нет в текстовых данных, полученных на основе Speech2Text. Оно и понятно, ведь модели обучались на данных, где присутствует пунктуация.
Поэтому перед нами встала задача автоматической расстановки пунктуации в предложениях. У нас было два выбора:
Сделать свою модель распознавания речи, которая бы умела расставлять знаки препинания.
Сделать модель восстановления знаков препинания у текста, который будет получен с помощью Speech-to-Text сервиса.
Мы сразу решили не переизобретать велосипед (первый вариант), а сделать отдельный модуль по восстановлению знаков препинания, который можно будет прикрутить и к другим проектам/задачам, если понадобится.
 Пример сервиса, где исправление опечаток может понадобиться
Пример сервиса, где исправление опечаток может понадобитьсяКак?
О процессе подготовки данных для обучения я расскажу чуть позже, сейчас же давайте пока разберемся с самой идеей.
Наша модель должна быть примерно такой: мы ей даем последовательность слов, а она нам говорит, после каких именно слов нужно поставить знак препинания (запятую или точку).
После проведенного ресерча (публикации интернет-статьи, чаты, NLP комьюнити) мы создали шорт-лист популярных методов восстановления знаков препинания:
N-граммы.
Цепи Маркова (и похожие).
Простые нейронные сети.
Сети — трансформеры.
Первые два метода — статистические, быстро обучаются, но качество оставляет желать лучшего.
Нейронные сети, напротив, долго обучаются, занимают больше места в памяти, но обеспечивают достаточно высокую точность.
Так как нам в первую очередь важно было качество, а размер модели для нас не так важен, было принято решение делать нейронную сеть.
Данные
Препроцесинг
Чтобы обучить нейронную сеть, сначала необходимо подготовить данные привести их в должный вид:
Берем тексты.
Разбиваем их на предложения.
Разбиваем предложения на токены.
Для каждого токена, который является словом, записываем, что нужно поставить после него: пробел, запятую или точку.
Каждую такую пару (слово — знак) записываем в отдельную строку текстового файла.
Список выше — всего лишь краткий пересказ, на деле же очень часто приходится чистить промежуточные результаты от всякого рода артефактов, например: пустые токены, скрытые символы, дублирующиеся слова и тд.
Практически весь препроцессинг данных производится силами библиотеки SpaCy, плюс немного регулярок для очистки.
В итоге после всех манипуляций у нас должен получиться файл такой структуры:
СТОП! А ГДЕ САМИ ДАННЫЕ БЕРЁТЕ?
Благо, для такой задачи данных много подойдут любые тексты, если задача общего характера, в которых присутствуют знаки препинания. Мы решили взять датасет Lenta2 из библиотеки corus (проект Наташа) кстати, именно на библиотеках этого проекта основана модель для русского языка в SpaCy. Датасет Lenta включает в себя текст и заголовки статей с сайта lenta.ru в количестве 800 975 штук, весом почти в 2Гб, в каждом тексте примерно 5–10 предложений.
Данные для обучения
Прежде чем давать данные, которые мы обработали на обучение нейронной сети, нам необходимо перевести наши токены в числовой вид вот в таком формате:
x — токены
attention mask — маска внимания
y — таргеты, ответы к нашим токенам
y mask — маска ответов, аналогично с attention mask, только для ответов
В самом начале наши уже токенизированные тексты разбиваются дополнительно на subtoken«ы, но вы меня спросите: «Зачем?». А затем что есть разные методы токенизации данный метод разбиения на подслова (по сути, это наиболее популярные N-граммы букв) нужен для минимизации количества неизвестных слов во время использования сети. Если просто каждому слову присваивать свой индекс, например, при обучении мы встретили слово »всего» и слово »определенная», но не встретили слова »вселенная», то при модели, где есть слово »вселенная», нам придется заменить целое слово на токен UNK. А если бы мы разбивали на подтокены, то слово «всего» было бы как токен «все» и токен «го», а слово »определенная» — как »опреде» и »ленная», и в итоге, когда модель увидит неизвестное слово »вселенная», просто разобьет его на два уже известных токена »все» и »ленная». А затем переводим каждый токен в число…
Также в начало и конец последовательности мы добавляем специальные токены для обозначения, соответственно, начала и конца последовательности.
Еще нам нужно определиться с длиной последовательности (seq_len) обучающих данных. Если количество токенов меньше параметра seq_len, то мы добавляем токены-пустышки (PAD) для заполнения матрицы.
С маской внимания все просто для каждого токена маска будет равна 1, за исключением токена PAD.
С таргетами чуть интереснее: так как наша цель — расставлять знаки препинания, а они не могут встретиться посреди слова, значит только для токенов, которые являются целыми словами, или для токенов, которые в конце слова, мы будем передавать наш таргет и маску 1, в остальных случаях 0.
Давайте подведем небольшой итог по подготовке данных:
Изначально у нас текст в виде строки: «казнить нельзя, помиловать.»
Затем разбиваем на слова и записываем в файл:
казнить O
нельзя COMMA
помиловать PERIOD
Затем переводим эти данные в числовое представление:
tokens : [ '[SOS]', 'казнить', 'нельзя', 'помил', '##овать', '[EOS]', '[PAD]', '[PAD]' ]
x : [101, 65272, 18960, 34994, 6123, 102, 0, 0]
attn_mask: [1, 1, 1, 1, 1, 1, 0, 0]
y : [0, 0, 1, 0, 2, 0, 0, 0]
y_mask : [1, 1, 1, 0, 1, 1, 0, 0]
Модель
Чем меньше весит модель, чем быстрее ее обучить, тем лучше, но качество всегда в приоритете. Сначала мы решили попробовать обучить простую модель, основываясь на данном исследовании. Но качество оставляло желать лучшего.
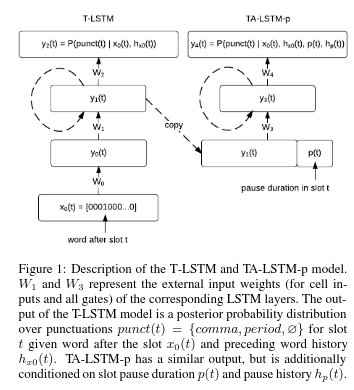 С этой архитектурой ничего не получилось
С этой архитектурой ничего не получилосьПосле апробирования других архитектур из разных исследований, мы решили, что хватит с нас экспериментов с небольшими нейронками, пора перейти к тяжелой артиллерии, к «золотому стандарту» — к трансформерам (если интересно, что такое трансформеры, то почитайте это это или это).
В поисках эффективных архитектур (и возможных готовых решений) мы наткнулись на этот репозиторий (к нему прилагается еще и публикация, они расставляют пунктуацию для английского и бенгальского языков). Решили взять за основу их наработки, немного изменили, оптимизировали некоторые моменты и обучили модель, но обо всем по-порядку.
Архитектура модели:
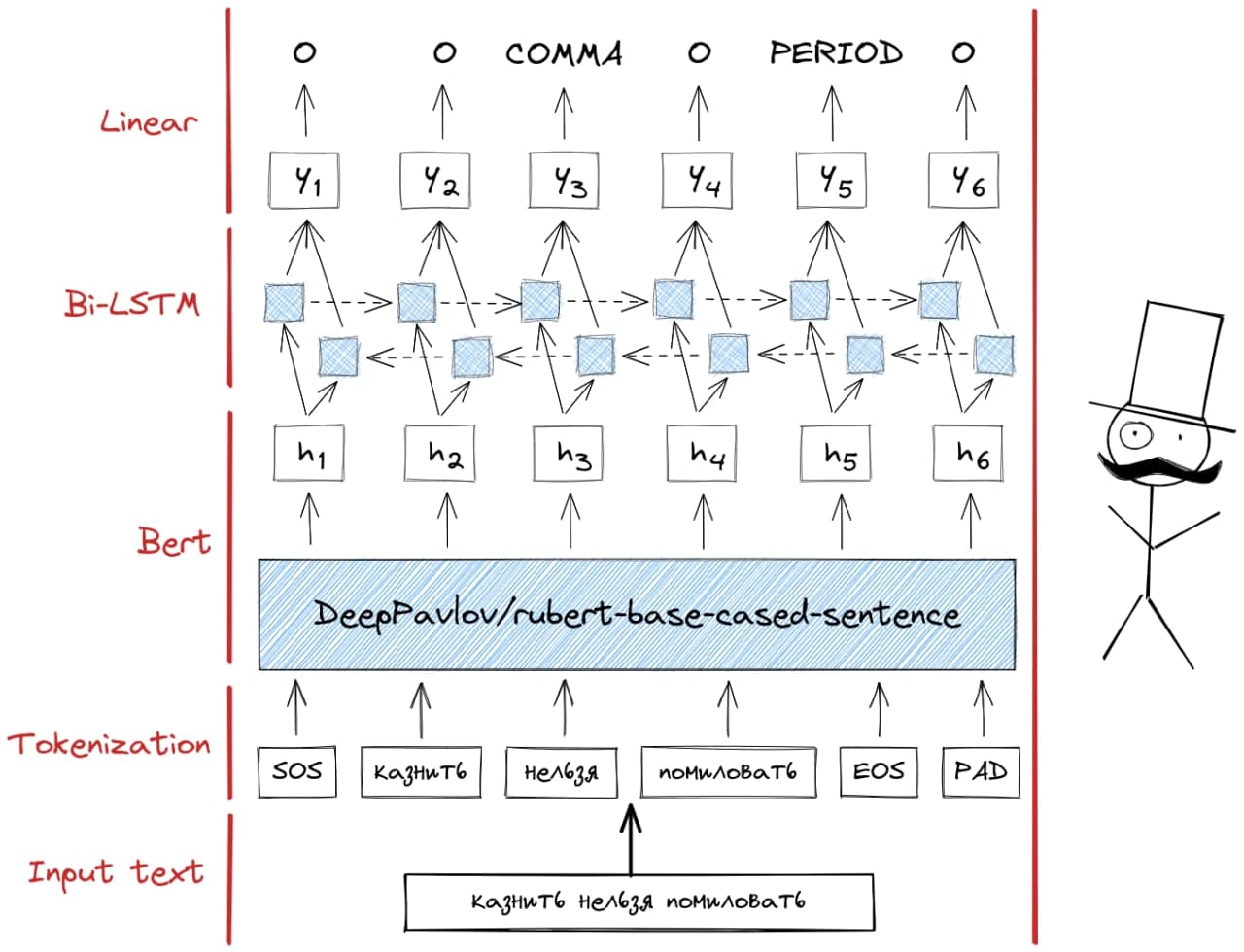 Архитектура нашей нейронки
Архитектура нашей нейронкиДавайте чуть подробнее разберем, что делает каждый слой и в чем их смысл.
Тяжелая, предобученная, Bert модель пытается понять «смысл» текста (в виде токенов), передавая на следующий слой скрытые состояния h1 - hn. Эти скрытые состояния — математическое представление этого самого «смысла» для каждого токена в контексте целой последовательности.
На следующем этапе LSTM слои упрощают эти скрытые состояния (переводят их в менее размерное пространство).
И финальный, линейный слой — на основе всех упрощений выносит вердикт нужно ли ставить знак препинания и если нужно, то какой.
На самом деле модель с такой архитектурой можно использовать не только для расстановки знаков препинания, но и для других самых разных задач в которых нужна классификация токенов (Token classification) или по-другому NER (Named Entity Recognition). Именно поэтому мы решили не просто один раз обучить модель и использовать её, а написать инструмент-сервис, для последующей поддержки переобучения, fine-tuning«а модели, про которую сейчас вам и хочу рассказать.
Сервис
Лично я в своей работе постоянно сталкиваюсь с одной и той же проблемой: пока ты экспериментируешь, т.е. обучаешь одну и ту же модель с разными параметрами, в какой-то момент наступает осознание того, что ты уже забыл, где и какие параметры поставил. И вы даже не представляете, как бывает обидно, когда обучаешь модель несколько часов (или еще хуже — дней), а потом случайно перезаписываешь сохраненные веса.
 Когда два дня нейронка обучалсь, а потом ты затер веса
Когда два дня нейронка обучалсь, а потом ты затер весаБольшую часть времени при разработке модели я трачу не на создание архитектуры, модели или скрипта, тренировки, а на создание инфраструктуры, чтобы было удобно обучать, сохранять, использовать модель, подбирать параметры и контролировать обучение.
Так как мы запланировали реализовать еще пару идей с использованием модели с данной архитектурой, а значит, создание хорошего и удобного сервиса — это инвестиция в недалекое будущее, с которой мы хотим поделиться.
При разработке, мы хотели, чтобы код был легко-модифицируем под похожие задачи, но в то же время, чтобы он не был громоздким и был дружелюбным для новичков и людей со стороны.
Структура:
files — директория, в которой «сырые» данные
data — директория, в которой хранятся предобработанные данные
models — директория с моделями, здесь хранятся веса, логи и параметры обучения моделей, каждая в отдельной папочке с уникальным названием
notebooks — директория для ноутбуков
scripts — директория со скриптами
src — кодовая база, место, где происходит вся «магия»
.lambl — логи кеш файлы сервиса labml
Особенности:
Для запуска обучения необходимо запустить файл train.py с дополнительными аргументами. В зависимости от выбранных параметров мы можем:
Обучить с нуля
Продолжить обучение (например, в случае непредвиденной ошибки)
Fine-tuning — продолжение обучения, но с иным количеством нейронов на последнем слое
Предостережение затирания результатов
при обучении с нуля и fine-tuning«е создаются директории в формате model-name^1, если директория с именем model-name уже существует.
при продолжении обучения (resume) загружаются последние сохраненные веса
Сохранение параметров обучения в json объект
Онлайн отслеживание работы модели с помощью labml — очень удобно смотреть с мобильных устройств (в том же WaB или TensorBoard, с телефона не так удобно) можно сравнивать как идет обучение по-сравнению с другими моделями.
Возможность использования нескольких файлов для обучения, валидации и тестирования.
Dockerfile и docker-compose.yaml файлы для поднятия веб-сервера для запросов к модели на базе FastAPI.
Результат
Нейронную сеть обучали с такими параметрами:
{
"model_name": "repunct-model",
"targets": {
"O": 0,
"COMMA": 1,
"PERIOD": 2
},
"weights": null,
"resume": false,
"fine_tune": false,
"store_best_weights": true,
"store_every_weight": false,
"augment_rate": 0.15,
"augment_type": "all",
"sub_style": "unk",
"alpha_sub": 0.4,
"alpha_del": 0.4,
"cuda": true,
"seed": 1,
"pretrained_model": "DeepPavlov/rubert-base-cased-sentence",
"freeze_pretrained": false,
"lstm_dim": -1,
"train_data": [
"data/repunct/train"
],
"val_data": [
"data/repunct/test"
],
"test_data": null,
"batch_size": 4,
"sequence_length": 256,
"lr": 5e-06,
"decay": 0,
"gradient_clip": -1,
"epoch": 7,
"labml": true,
"save_dir": "models/"
}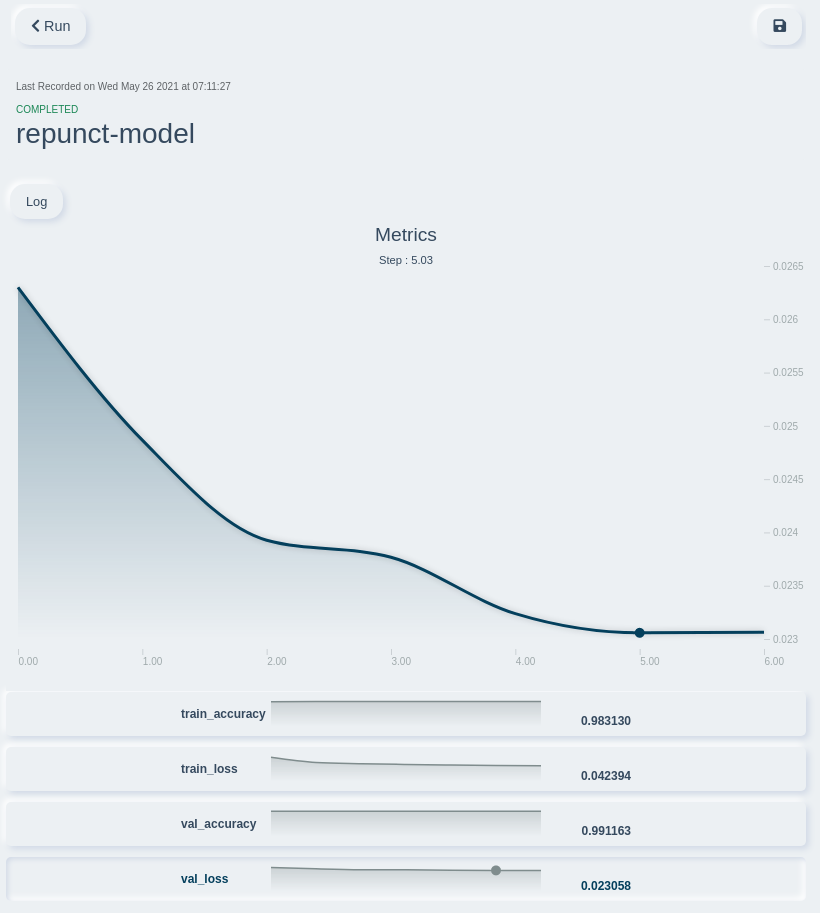 Ошибка на валидационных данных
Ошибка на валидационных данныхПосле 5 эпохи наблюдается переобучение — точность на тренировочных данных увеличивается, но прирост на валидационных незначительный.
Результаты обучения приведены ниже:
Best validation Acc: 0.9832204226585259
Confusion Matrix:
[21489384 144837 40369]
[ 188716 1890897 8915]
[ 33862 5237 1359430]
O:
Precision: 0.9897
Recall: 0.9915
F1 score: 0.9906
COMMA:
Precision: 0.9265
Recall: 0.9054
F1 score: 0.9158
PERIOD:
Precision: 0.965
Recall: 0.972
F1 score: 0.9685
COMMA + PERIOD:
Precision: 0.9422
Recall: 0.9321
F1 score: 0.9371Сравнение с аналогами
В процессе поиска готовых решений мы не нашли в открытых источниках готовых и обученных моделей, но зато нашли один репозиторий уже после того, как обучили свою модель. Мы не расстроились и решили провести небольшое сравнение. К сожалению, в данном репозитории не предусмотрено вычисление каких-то метрик или промежуточных результатов в виде токенов. Поэтому сказать объективно, какая из моделей лучше — нельзя (вообще можно, но нужно разобраться в коде репозитория), но зато можно оценить субъективно, просто сравнив результаты расставления знаков препинания в сложных предложениях:
Оригинальный текст
Конспирологи предположили, что, возможно, пасхальное фото — это намек на скорое воссоединение пары, ведь шлепанцы явно велики, а значит, модель могла одолжить их у супруга.
Bert-Russian-punctuation:
конспирологи предположили, что возможно пасхальное фото это — намек на скорое воссоединение пары, ведь шлепанцы явно велики, а значит модель могла одолжить их у супруга.
Наша модель:
Конспирологи предположили, что, возможно, пасхальное фото — это намек на скорое воссоединение пары, ведь шлепанцы явно велики, а значит, модель могла одолжить их у супруга.
Как можно заметить, у нашей модели есть ряд преимуществ, кроме того, что она идеально расставила знаки препинания так, она не приводит весь текст в нижний регистр, в отличии от модели из найденного репозитория. И так в целом во многих текстах.
Заключение
В данном репозитории на GitHub мы выкладываем не только наш инструмент-сервис для обучения модели, но также во вкладке Releases мы выкладываем веса нейронной сети, чтобы вы могли использовать данную модель для ваших задач. Надеемся, что из данной статьи вы узнали для себя что-то новое или хотя бы нашли то, что искали.
GitHub: https://github.com/sviperm/mistakes-correction
PLOT TWIST: мы не могли вас оставить без сюрприза! Возможно, вы заметили, что в некоторых местах запятых не хватает, в других, наоборот, запятые стоят там, где не надо. В этом виноваты не наши редакторы, а нейронная сеть. Мы решили, что лучшая демонстрация возможностей сетки — это расставить с её помощью запятые во всех предложениях данной статьи.
