Нейросети в генерации видео: Imagen video и Phenaki

Мы видели уже большое количество генеративных нейросетей способных превращать текстовые запросы в изображение, но почему все забыли про видео? Разве никто не хочет примерить на себе кресло режиссёра без съёмочной группы и выхода за пределы комнаты с любимым компьютером? Google начал делать первые шаги в этой области, и сейчас мы рассмотрим их нейросети: Imagen video и Phenaki. Приготовьтесь к приключению в глубины машинного обучения, где искусственный интеллект превращает написанное слово в завораживающее зрелище.
▍ Чем видео отличается от картинок?
Видео (по своей сути) представляет собой не что иное, как последовательность изображений, воспроизводимых очень быстро. Тем не менее воздействие видео на человеческий мозг значительно отличается от воздействия отдельных изображений. Движение и прогрессия изображений в видео создают более захватывающий и динамичный опыт, позволяя мозгу взаимодействовать с контентом так, как не могут отдельные изображения. Это всё равно что сравнивать опыт чтения книги с просмотром фильма, основанного на этой книге. Хотя оба варианта предоставляют одну и ту же информацию, последний обеспечивает более увлекательный и захватывающий опыт. Вот почему видео стали таким мощным инструментом общения, образования и развлечения. Они позволяют нам не только потреблять информацию, но и переживать её.
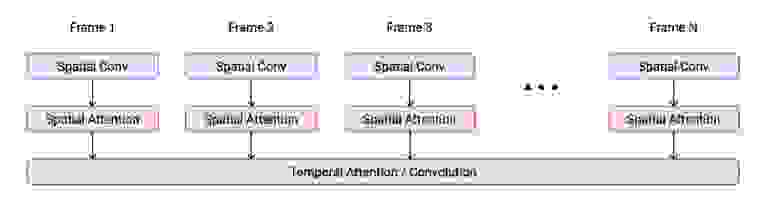
Нейросети для генерации видео мало чем отличаются от тех, что генерируют изображения, но им важно помнить прошлые кадры для генерации следующих и при этом не забывать про текстовый запрос.
▍ Imagen video

Imagen Video — это модель для текстово-обусловленной генерации видео высокого разрешения. Она работает с использованием графика шума, который уменьшает отношение сигнал/шум до тех пор, пока он не будет близко моделировать целевые данные. Затем используется генеративная модель для обратного процесса и генерации образцов из распределения видеоданных. Модель также включает в себя методы пространственного и временного суперразрешения для повышения точности и качества выходного видео. Кроме того, Imagen Video использует два различных метода выборки — родовую выборку или детерминированную выборку DDIM — в зависимости от того, какой тип результатов требуется для каждой конкретной задачи.
Imagen Video работает по каскадной схеме начиная с ввода текстовой подсказки и заканчивая созданием 5,3-секундного видеоролика 1280×768 с частотой 24 кадров в секунду. На первом этапе используется языковая модель (T5-XXL) для генерации эмбендингов из текстовой подсказки, которые затем вводятся во все модели в конвейере. Затем следует одна базовая модель диффузии видео и 3 модели пространственного сверхразрешения (SSR), а также 3 модели временного сверхразрешения (TSR) — всего 7 моделей диффузии видео с 11,6 миллиардами параметров! На каждом этапе данные обрабатываются до соответствующего разрешения путём пространственного изменения размера или пропуска кадров, после чего поступают на последующие этапы и, наконец, достигают выходных кадров высокого разрешения со скоростью 24 кадра в секунду.
Модель была обучена на комбинации внутренних и общедоступных наборов данных и оценена с помощью различных метрик, таких как FID для отдельных кадров, FVD для временной согласованности и CLIP для выравнивания видео и текста. После обучения Imagen Video был способен генерировать видео с художественными стилями, понимать 3D структуры и визуализировать текст в различных анимационных стилях. Также было показано, что Imagen Video улучшается при масштабировании моделей большего размера. Также было проведено сравнение моделей -prediction и v-prediction для задач пространственного сверхразрешения видео. Было обнаружено, что предсказание даёт худшие результаты, чем v-предсказание. В конце статьи исследователи Google обсуждали метрики качества восприятия и дистилляция, где было показано, что дистилляция обеспечивает благоприятный компромисс между временем выборки и качеством восприятия, позволяя ускорить выборку при сопоставимой производительности.

▍ Phenaki
Чтобы сделать великий фильм, необходимы три вещи — сценарий, сценарий и ещё раз сценарий.
— Альфред Хичкок
Phenaki — это модель, которая может генерировать реалистичное видео из своеобразного сценария. Phenaki использует трансформер — тип модели глубокого обучения для преобразования текстовых токенов (например, слов или фраз) в видео-токены.
(Про генерацию аналогичным образом изображений я писал в этой статье)

«A photorealistic teddy bear is swimming in the ocean in San Francisco. The teddy bear goes underwater. The teddy bear keeps swimming under the water with colorful fishes. A panda bear is swimming underwater.»
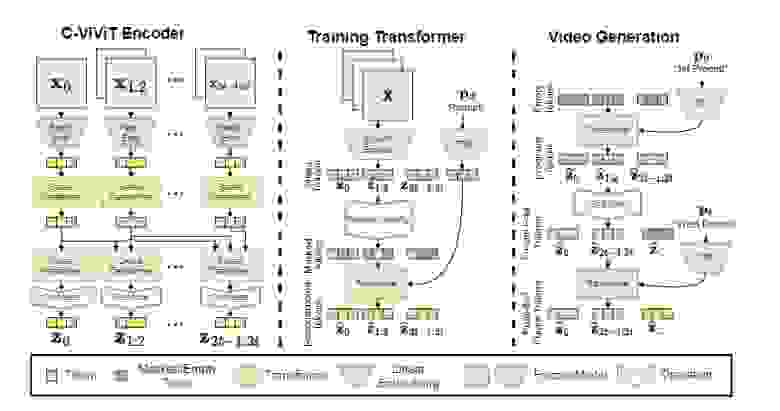
Она работает, принимая последовательность текстовых подсказок и сжимая видео в токены с помощью кодера под названием C-ViViT. Затем эти токены де-токенизируются для создания видео, которое может быть произвольной длины и обусловлено изменяющимся во времени текстом или историями. Чтобы максимизировать количество данных, они проводят совместное обучение на парах изображение-текст и меньшем количестве примеров видео-текст из таких наборов данных, как LAION5B и JFT4B, чтобы обобщение выходило за рамки того, что доступно в существующих наборах данных.
Нейросеть использует векторное квантование (VQ) для создания видеопредставления из текста, каузальную вариацию архитектуры ViViT для сжатия кадров видео и двунаправленный трансформер для создания видеотокенов из текста, что позволяет ей генерировать длинные видео с фиксированным шагом дискретизации. Также используются функции потерь, такие как L2, потери восприятия изображений и видео, а также состязательные потери для того, чтобы видео-токены точно соответствовали соответствующему тексту.
Модель использует авторегрессивный подход, то есть создаёт видео со временем, поскольку каждая подсказка соответствует сцене в сюжете. Это позволяет создавать динамически меняющиеся сцены, чего раньше не удавалось сделать с помощью подобной технологии.
Визуальное рассказывание историй с помощью динамического ввода текста — это функция Phenaki, которая позволяет создавать видеоролики, сцены которых могут динамически меняться, чтобы рассказать историю. Принцип работы заключается в получении подсказки в определённый момент времени и использовании этой подсказки для создания видеокадра на основе предыдущих N кадров. Это первая известная нейросеть, которая позволяет создавать длинные видео, где каждая подсказка соответствует сцене из видео. Кроме того, эта нейронная сеть позволяет решать задачи кодирования и реконструкции видео с меньшим количеством подсказок и лучше моделировать пространственно-временную динамику, чем другие.
А может ли она предсказывать продолжение к существующему видео? Phenaki не предназначена специально для предсказания видео. Она не включает некоторые функции других методов предсказания видео, такие как «пропуск связей U-net», которые помогают улучшить производительность. Тем не менее — Phenaki всё ещё имеет конкурентоспособную производительность по сравнению с другими методами предсказания видео. Его сила заключается в способности понимать и использовать изменяющуюся динамику видео для создания новых видео на основе описаний в тексте.
Модель имеет всевозможные применения — как положительные, так и отрицательные. Она может внести существенный вклад в ускорение творческого процесса, что является неоспоримым плюсом. Однако, не менее важным является отрицательный эффект, а именно, её использование в плохих целях для лёгкого создания злонамеренного фейкового контента. Кроме того, известно, что некоторые наборы данных, на которых обучается эта модель, содержат нежелательные предубеждения. По этим причинам авторы пока не готовы обнародовать базовые модели или код и вместо этого сосредоточат свои усилия на лучшем понимании данных и их фильтрации.
▍ Выводы
Модели Imagen Video и Phenaki от Google проложили путь в новую эру технологии создания видео, когда творческие умы могут воплощать свои идеи в жизнь не выходя из-за компьютера. Эти модели демонстрируют мощь глубокого обучения и его способность обрабатывать большие объёмы данных, в результате чего получаются видео высокого разрешения с впечатляющей точностью и качеством. Однако вместе с такой технологией приходит и ответственность, поскольку авторы моделей признают возможность злоупотреблений и наличие предубеждений в обучающих данных. Тем не менее — это значительный шаг к раскрытию всего потенциала генеративных моделей, и будет интересно посмотреть, как эта технология будет развиваться в будущем.

Играй в наш скролл-шутер прямо в Telegram и получай призы!
