Нейросеть LipNet читает по губам с точностью 93,4%

Командир Дэйв Боумен и второй пилот Фрэнк Пул, не доверяя компьютеру, решили отключить его от управления кораблём. Для этого они совещаются в звукоизолированной комнате, но HAL 9000 читает их разговор по губам. Кадр из фильма «Космическая одиссея 2001 года»
Чтение по губам играет важную роль в общении. Ещё эксперименты 1976 года показали, что люди «слышат» совершенно другие фонемы, если наложить неправильный звук на движение губ (см. «Hearing lips and seeing voices», Nature 264, 746–748, 23 December 1976, doi: 10.1038/264746a0).
С практической точки зрения чтение по губам — важный и полезный навык. Можно понимать собеседника не выключая музыку в наушниках, читать разговоры всех людей в поле зрения (например, всех пассажиров в зале ожидания), прослушивать людей в бинокль или подзорную трубу. Область применения навыка очень широка. Освоивший его профессионал без труда найдёт высокооплачиваемую работу. Например, в сфере безопасности или конкурентной разведке.
У автоматических систем чтения по губам тоже богатый практический потенциал. Это медицинские слуховые аппараты нового поколения с распознаванием речи, системы для беззвучных лекций в публичных местах, биометрическая идентификация, системы скрытой передачи информации для шпионажа, распознавание речи по видеоряду с камер наблюдения и т.д. В конце концов, компьютеры будущего тоже будут читать по губам, как HAL 9000.
Поэтому учёные уже много лет пытаются разработать системы автоматического чтения по губам, но без особого успеха. Даже для относительно простого английского языка, в котором количество фонем гораздо меньше, чем в русском языке, точность распознавания невысока.
Понимать речь на основании мимики человека — сложнейшая задача. Освоившие этот навык люди пытаются распознавать десятки согласных фонем, многие из которых очень похожи внешне. Неподготовленному человеку оcобенно трудно различить пять категорий визуальных фонем (то есть визем) английского языка. Другими словами, различить по губам произношение некоторых согласных звуков практически невозможно. Неудивительно, что люди очень плохо справляются с точным чтением по губам. Даже самые лучшие среди инвалидов по слуху демонстрируют точность всего лишь 17±12% из 30 односложных слов или 21±11% из многосложных слов (здесь и далее результаты для английского языка).
Автоматическое чтение по губам — одна из задач машинного зрения, которая сводится к покадровой обработке видеоряда. Задача сильно усложняется низким качеством большинства практических видеоматериалов, которые не позволяют точно считывать спатиотемпоральные, то есть пространственно-временные характеристики лица во время разговора. Лица двигаются и поворачиваются в разные стороны. Последние разработки в области машинного зрения пытаются отслеживать движение лица в кадре, чтобы решить эту проблему. Несмотря на успехи, до последнего времени они были способны распознавать только отдельные слова, но не предложения.
Значительного прорыва в данной области добились разработчики из Оксфордского университета. Обученная ими нейросеть LipNet стала первой в мире, которая успешно распознаёт по губам речь на уровне целых предложений, обрабатывая видеоряд.
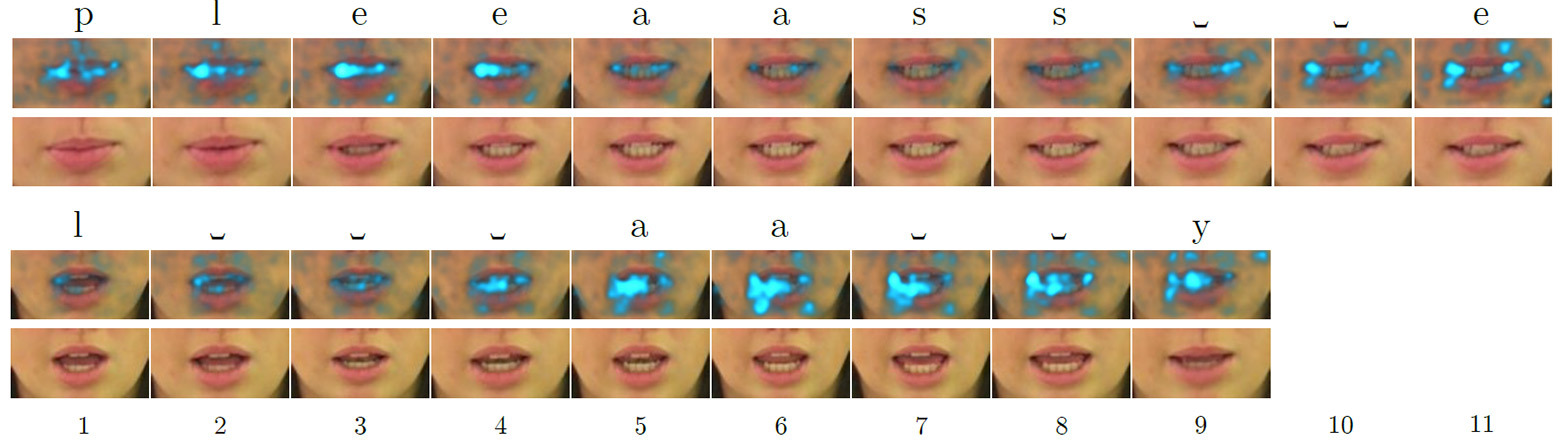
Покадровые карты салиентности для английских слов «please» (вверху) и «lay» (внизу) при обработке нейросетью, которая читает по губам, выделяя наиболее привлекающие внимание (салиентные) признаки
LipNet — рекуррентная нейросеть типа LSTM (long short-term memory). Архитектура показана на иллюстрации. Нейросеть обучали с использованием метода нейросетевой темпоральной классификации (Connectionist Temporal Classification, CTC), который широко используется в современных системах распознавания речи, поскольку с ним отпадает необходимость обучения на наборе входных данных, синхронизированным с правильным результатом.
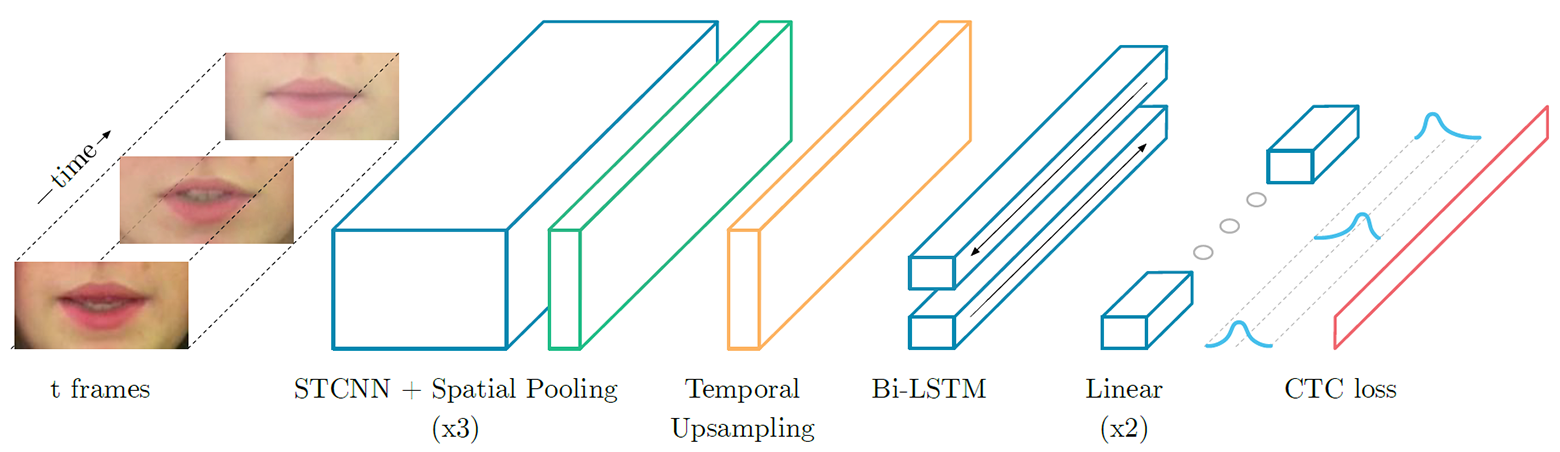
Архитектура нейросети LipNet. На входе подаётся последовательность кадров T, которые затем обрабатываются тремя слоями пространственно-временной (спатиотемпоральной) свёрточной нейросети (STCNN), каждый из которых сопровождается слоем пространственной выборки. Для извлечённых признаков повышается частота дискретизации по временной шкале (апсемплинг), а затем они обрабатываются двойной LTSM. Каждый временной шаг на выходе LTSM обрабатывается двухслойной сетью прямого распространения и последним слоем SoftMax
На особом корпусе предложений GRID нейросеть показывает точность распознавания 93,4%. Это не только превышает точность распознавания других программных разработок (которые указаны в таблице ниже), но и превосходит эффективность чтения по губам специально обученных людей.
| Метод | Набор данных | Размер | Выдача | Точность |
|---|---|---|---|---|
| Fu et al. (2008) | AVICAR | 851 | Цифры | 37,9% |
| Zhao et al. (2009) | AVLetter | 78 | Алфавит | 43,5% |
| Papandreou et al. (2009) | CUAVE | 1800 | Цифры | 83,0% |
| Chung & Zisserman (2016a) | OuluVS1 | 200 | Фразы | 91,4% |
| Chung & Zisserman (2016b) | OuluVS2 | 520 | Фразы | 94,1% |
| Chung & Zisserman (2016a) | BBC TV | >400000 | Слова | 65,4% |
| Wand et al. (2016) | GRID | 9000 | Слова | 79,6% |
| LipNet | GRID | 28853 | Предложения | 93,4% |
Особый корпус GRID составлен по следующему шаблону:
command (4) + color (4) + preposition (4) + letter (25) + digit (10) + adverb (4),
где цифра соответствует количеству вариантов слов для каждой из шести словесных категорий.
Другими словами, точность 93,4% — это всё-таки результат, полученный в тепличных лабораторных условиях. Разумеется, при распознавании произвольной человеческой речи результат будет гораздо хуже. Не говоря уже об анализе данных с реальной вилдеосъёмки, где лицо человека не снимают крупным планом в отличном освещении и с высоким разрешением.
Работа нейросети LipNet показана на демонстрационном видео.
Научная статья подготовлена к конференции ICLR 2017 и опубликована 4 ноября 2016 года в открытом доступе.
