Нейродайджест: главное из области машинного обучения за май 2021

Управляемые складки одежды и морщины, фотореалистичные симуляции вождения, естественное освещение объектов при смене фона, китайский аналог DALL-E и многое другое: встречайте подборку самых интересных исследований и нейросетевых моделей, которые появились в прошедшем месяце.
DECA
Доступность: страница проекта / статья / репозиторий
Современные методы монокулярной трехмерной реконструкции создают лица, которые невозможно реалистично анимировать, поскольку они не моделируют изменение морщин в зависимости от выражения. Также модели, обученные на высококачественных сканированных изображениях, плохо работают на фото, сделанных в естественных условиях.

Данный подход регрессирует трехмерную форму лица и анимируемые черты лица, которые меняются в зависимости от артикуляции. Модель обучена создавать карту UV-смещений из низкоразмерного скрытого представления, которое состоит из специфичных для человека параметров, а регрессор обучен предсказывать параметры формы, позы и освещения из одного изображения. Для этого авторы создали функцию потерь, которая отделяет индивидуальные особенности лица от морщин, которые зависят от артикуляции. Такое разделение позволяет синтезировать реалистичные морщины, характерные для конкретного человека, и управлять параметрами выражения лица, сохраняя при этом индивидуальные особенности человека.
Garment Collision Handling
Доступность: страница проекта / статья
Симуляция деформации и движения одежды на человеке часто приводит к тому, что текстура одежды проникает внутрь модели тела. Существующие методы виртуальной примерки требуют этап постобработки, чтобы устранить этот нежелательный эффект. Данный подход напрямую выводит трехмерные конфигурации одежды, которые не пересекаются с телом.

Модель симулирует деформацию одежды и реалистичное движение складок в зависимости от изменения позы. Достигается это с помощью новогоканонического пространства для одежды, которое устраняет зафиксированные диффузной моделью человеческого тела деформации позы и формы, которая и экстраполирует свойства поверхности тела, такие как скиннинг и блендшейп, на любую трехмерную точку.
DriveGAN
Доступность: страница проекта / статья
Для автопилотов и реалистичных тренажеров нужны данные, которые приходится собирать вручную, а это очень долгий и трудоемкий процесс. Можно использовать машинное обучение, чтобы стимулировать ответную реакцию среды на действия непосредственно из данных. Исследователи из NVIDIA и MIT обучили нейросеть на сотнях часов дорожных видео, чтобы моделировать динамическую среду непосредственно в пиксельном пространстве на основе неразмеченных последовательностей кадров и связанных с ними действий.
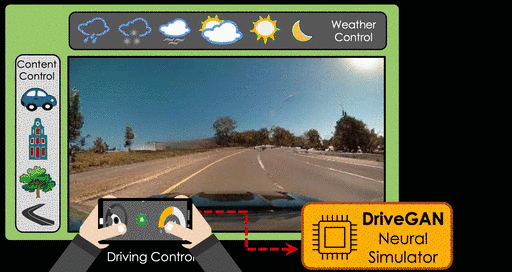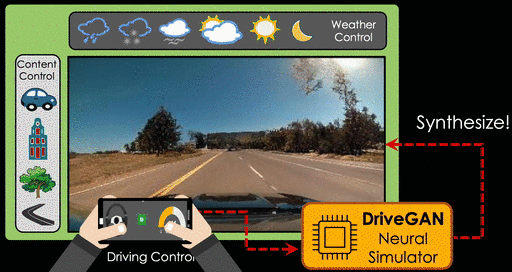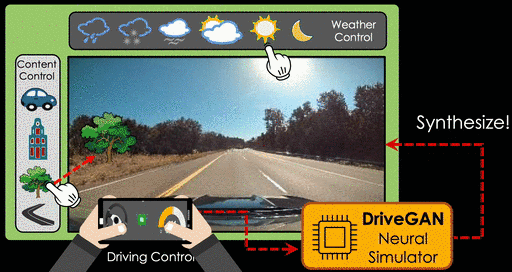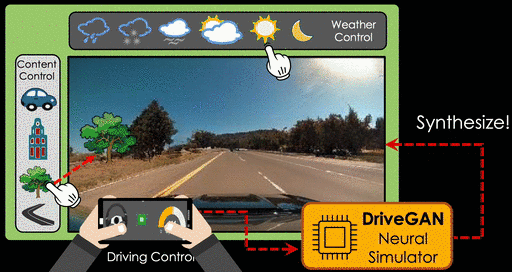
В получающихся синтезируемых дорожных путешествиях можно моделировать погодные условия, время суток и расположение объектов. Симуляцией можно управлять через графический интерфейс с помощью поворотов руля и изменения скорости.
Enhancing Photorealism Enhancement
Доступность: страница проекта / статья / репозиторий
Пока приходится ждать симулятор езды от NVIDIA, можно развлечь себя с помощью разработок от исследователей из Intel. Они представили подход к повышению реалистичности синтетических изображений. Сверточная нейросеть использует промежуточные представления, созданные обычными пайплайнами рендеринга, что позволяет добиться фотореалистичной картинки в GTA V.

CogView
Доступность: онлайн-демо / статья / репозиторий
Новая нейросеть для перевода текста в изображение. В основе модели трансформер на 4 миллиарда параметров и токенизатор VQ-VAE. Создатели утверждают, что их модель работает лучше DALL-E от OpenAI, и в статье также делятся подходом к файнтюнингу модели для решения других задач вроде обучения стилю, улучшению разрешения, а также стабилизации предварительного обучения.

Попробовать модель можно уже сейчас, правда онлайн-демо пока понимает только текст на китайском.
Expire-Span
Доступность: публикация в блоге / статья / репозиторий
В отличие от человеческой памяти, большинство нейронных сетей обрабатывают информацию целиком, без разбора. При небольших масштабах это не вызывает проблем. Но современные крупные модели, которые на вход принимают полноценные книги или десятки часов видеозаписей, требуют все больше вычислительные мощностей.
Исследователи из FAIR решили научить модели забывать информацию, чтобы фокусироваться только на том, что имеет значение. Сначала модель предугадывает информацию, которая наиболее актуальна для поставленной задачи. В зависимости от контекста, данным присваивается дата истечения срока действия, с наступлением которой информация выбрасывается моделью.
Wav2Vec-U
Доступность: публикация в блоге / статья / репозиторий
Есть много моделей распознавания речи, которые превосходно справляются с распространенными языками. Но множество диалектов все еще не поддерживаются этими технологиями. Это связано с тем, что высококачественные системы необходимо обучать с использованием большого количества размещенных аудиозаписей. Исследователи FAIR представили версию модели wav2vec-U, которая обучается без учителя и вообще не требуют размеченных данных.
Rethinking Style Transfer
Доступность: страница проекта / статья / репозиторий
Существует много качественных моделей для переноса стиля. В большинстве из них процесс стилизации ограничен оптимизацией пикселей. Это не совсем естественно, так как картины состоят из мазков кисти, а не пикселей. Данный метод предлагает стилизовать изображения путем оптимизации параметризованных мазков кисти и дифференцируемого рендеринга. Этот подход улучшает визуальное качество и обеспечивает дополнительный контроль над процессом стилизации — пользователь может управлять потоком мазков.

Relit
Доступность: страница проекта / статья
Когда вы сидите перед телевизором или монитором, ваше лицо активно освещается изменяющимся потоком света с экрана. Исследователи обучили нейронную сеть, которая принимает на вход фото лица и текущую картинку на мониторе и предсказывает, как будет выглядеть лицо в таком освещении с монитора. Таким образом, можно контролировать виртуальное освещение лица для видео с вебкамеры. Можно предстать перед коллегами в выгодном свете при очередном видеосозвоне.

Total Relighting
Доступность: страница проекта / статья
Исследователи из GoogleAI пошли дальше и представили систему, которая способна заменить фон фотографии и скорректировать освещение человека на ней, сохраняя четкими границы объектов. На вход подаются две фотографии — портретный снимок и картинка с новым окружением. Исследователи отмечают, что пока модель плохо справляется с альбедо, из-за чего некоторые типы одежды и глаза могут выглядеть неестественно.

Omnimatte
Доступность: страница проекта / статья
Работа со светом и тенью также нужна для качественного удаления объектов с изображений. Новая нейросеть от исследователей Google может автоматически связывать предметы в видео и вызванные ими эффекты в сцене. Это могут быть тени и отражения, а также рябь от объектов в воде или вообще посторонние объекты, движущиеся рядом, например, собака на поводке. На вход подается грубая маска объектов, а на выходе отдается два видео — с фоном и с отдельно вырезанным объектом.

DeepFaceEditing
Доступность: страница проекта / репозиторий
Создатели объединили подход с преобразованием фото в карандашный набросок с возможностями управления скрытым пространством GAN для сохранения эффектов освещения, реалистичности текстур и т.д. Таким образом для редактирования на вход подается оригинальное фото лица человека, оно преобразуется в скетч, который можно изменять штрихами.

StyleMapGAN
Доступность: репозиторий
Новый нейросетевой фотошоп, на этот раз от исследователей из корейской компании Naver. Метод позволяет редактировать отдельные области изображений. Как и у решений, которые мы рассматривали в апреле, здесь та же задача — управление скрытыми векторами генеративно-состязательной сети. В их подходе промежуточное скрытое пространство имеет пространственные измерения, и пространственно изменяющаяся модуляция заменяет адаптивную раздельную нормализацию. Таким образом кодировщик более точно создает вектора чем методы, основанные на оптимизации с сохранением свойств GAN.

GPEN
Доступность: онлайн-демо / статья / репозиторий
Китайские исследователи из Alibaba представили модель для реставрации размытых фото низкого качества, который в отличие от методов на основе GAN, создает не чрезмерно сглаженные изображения. Для этого модель использует GAN, чтобы сгенерировать высококачественное изображения лица, которое предварительно декодируется с помощью U-образной DNN.

CodeNet
Доступность: репозиторий
Исследователи из IBM представили крупнейший открытый датасет для проведения бенчмарков с участием программного кода. Набор данных содержит 500 миллионов строк кода на 55 языках программирования, включая C ++, Java, Python, Go, COBOL, Pascal и FORTRAN. CodeNet фокусируется на обнаружении сходств и отличий кода, чтобы продвигать разработку систем, которые смогут автоматически переводить код с одного языка программирования на другой.
DatasetGAN
Доступность: страница проекта / статья
Современные глубокие сети чрезвычайно требовательны к данным, поэтому обучение на крупномасштабных наборах данных требует много времени на разметку. NVIDIA представили генератор синтетических аннотированных датасетов для создания массивных наборов данных, который требует минимальных человеческих усилий. Метод основан на современных GAN и предлагает способ декодирования скрытого пространства для семантической сегментации изображений. Код обещают скоро опубликовать.
Golos
Доступность: репозиторий
Исследователи из Сбера опубликовали датасет с русским корпусом, подходящий для исследования речи. Набор данных в основном состоит из записанных и вручную размеченных аудиофайлов. Общая продолжительность аудиозаписи около 1240 часов.
В мае стали доступны:
На этом все, спасибо за внимание и до встречи в следующем месяце!
