Не можете измерить — не сможете улучшить: как мы используем метрики в разработке автотестов
Привет! Меня зовут Александр, я работаю QAA менеджером в компании Wrike, начинал с позиции QAA инженера в далеком 2010-ом и был первым в этой роли. За 12 лет нам удалось построить крутую команду и создать систему контроля качества, которая позволяет быстро и без багов деплоить продуктовый код в продакшен.
В статье я расскажу три истории из опыта нашей команды, которые наглядно показывают, что без правильно подобранных метрик сложно оценивать и отслеживать изменения в текущих процессах. Статья будет полезна, если вы хотите осознанно и качественно подходить к процессу разработки тестов, контролировать и улучшать этот процесс, используя данные, а также уметь оценивать результаты проведенных экспериментов.

Зачем нам потребовалась система сбора метрик
За время моей работы в Wrike мы прошли путь от маленького стартапа до большой продуктовой компании с 20 000+ компаний-клиентов. По мере роста клиентской базы возрастала ответственность за качество продуктового кода, увеличивалось и количество автотестов. Рост был настолько стремительный, что без должного контроля качества могла случиться катастрофа. Тогда мы решили осознанно подумать над тем, как можно контролировать весь процесс, прогнозировать потенциальные проблемы роста тестовой кодовой базы, определять текущие проблемы и узкие места в процессе разработки тестов.
Раньше мы собирали некоторые метрики и анализировали накопленную статистику, но делали это на скорую руку без четкого и построенного процесса. Тогда мы не задавались вопросами: «Для чего мы это делаем? Какую проблему решаем? Какая ценность есть у этой работы? С помощью каких метрик мы можем оценить пользу от проделанной работы?».
Фраза «Не можешь измерить — не сможешь улучшить» наиболее точно описывает основную идею этой статьи про подход к использованию метрик в нашей работе. Он позволяет оценить качество работы и тестов, гарантировать качество продукта, а также дает возможность улучшать тесты, тестовый фреймворк и тестовую инфраструктуру только там, где это действительно требуется.
Мы — сторонники эволюционного подхода. Сломать все и отстроить заново с учетом ошибок — это, конечно, тоже подход, и где-то он может сработать, но в нашем случае такой процесс может занять год или даже несколько лет.
Подход Team Sky
Несколько лет назад мне попалась интересная статья про подход, который применил Дэвид Брэйлсфорд в английской профессиональной велокоманде Team Sky. Основной задачей генерального менеджера в 2010-м году была победа команды в Тур де Франс. До этого ни один британский велосипедист не выигрывал эту престижную веломногодневку.

Дэвид — сторонник концепции накопления минимальных улучшений. Его подход был очень простым: если команда улучшит каждый показатель хотя бы на 1%, то суммарно эти улучшения дадут значительный эффект.
Команда менеджеров прошлась по всем аспектам жизни велогонщиков: начиная от пересмотра и улучшения рациона питания, плана тренировок, эргономики велосипедов, правильной посадки на них, заканчивая специально подобранными подушками для сна, на которых спортсмены спали в любом отеле мира. Для гонщиков подобрали оптимальный гель для массажа и даже обучили их эффективному способу мытья рук, чтобы избежать попадания инфекции в организм.
Брэйлсфорд считал: если стратегия сработает, то команда выиграет Тур де Франс через 5 лет. Но он ошибся. Team Sky взяла трофей через 3 года. Через год они повторили успех. В 2012-м году сборная Великобритании по велоспорту под руководством Дэвида выиграла на олимпийский играх 8 золотых, 3 серебряных и 2 бронзовых медали.

Я разделяю такой подход, который позволяет поступательно двигаться к цели. Да, может показаться, что это не быстро, но если посмотреть на процесс ретроспективно, то можно увидеть, что он позволяет команде накопить качественный и количественный потенциал, определить зоны развития и в итоге уверенно прийти к намеченным целям.
Принципы выбора метрик
Собирать какую-либо статистику просто для того, чтобы она была, а затем строить гипотезы по внедрению каких-либо улучшений — не самый удачный и эффективный подход. Важно понимать, каким именно образом статистика по собираемой метрике отражает процесс, алгоритм и тд.
Для себя мы сформулировали два принципа, которые помогают команде строить метрики.
Первый — сбор статистики по процессам мы выстраиваем исходя из проблем, которые хотим решить с помощью более эффективных процессов. Например, одна из таких проблем нашей команды — долгие мердж-реквесты кода в мастер. Это четко сформулированная проблема, и мы примерно понимаем, какие метрики могут помочь оценить полезность проделанной работы.
Второй принцип — определение зоны улучшений и подбор метрик, которые позволят контролировать и оценивать степень этих улучшений. Например, если мы увеличим количество перезапусков упавших тестов в рамках одного билда на N, то как будут меняться время прогона и стабильность тестов? В этом случае наша задача — найти оптимальное значение количества перезапусков упавших тестов, которое позволит повысить стабильность тестов и в то же время не сильно увеличить общее время работы билда.
Кейс 1: ускоряем процесс код-ревью
Написание тестов — достаточно трудоемкий процесс, который состоит из нескольких этапов: дизайн тест-кейса и самого теста, написание кода автотеста на тест-кейс, ревью кода и мердж в мастер. Это один из подпроцессов разработки продуктовых фич, и для бизнеса важно уметь быстро доставлять проверенный код в продакшен, и этот код должен быть без багов.
Так, на одном из квартальных планирований несколько продуктовых команд обратили наше внимание на долгий процесс разработки тестов — часто фича ехала в продакшен без полностью покрытого автотестами чеклиста.
Мы стали разбираться, в чем проблема: на примере недавно срезанной фичи рассмотрели, сколько времени занял каждый этап разработки автотестов. Решили начать с последнего этапа — мердж в мастер. В нашем случае этот этап является финалом код-ревью и потенциально выглядит узким местом: в процессе участвуют как минимум два инженера, и человеческий фактор вносит коррективы в процесс ревью кода — инженер может быть на больничном, уйти в отпуск на две недели или просто заниматься другими более приоритетными задачами для его команды.
Мы собрали статистику по времени жизни мердж реквеста — интервала времени между моментом, когда разработчик автотестов отправил код на ревью и мерджем кода в мастер после прохождения ревью. Так появилась метрика «Время жизни мердж реквеста».
Дальше встал вопрос о том, как оценивать эту метрику: какое значение мы будем считать хорошим, а какое — плохим. Мы хотели понять, сколько часов можем позволить себе на ревью кода тестов при условии, что продуктовые команды работают двухнедельными спринтами. С учетом загрузки разработчиков тестов мы нацелились на 48 часов: время ревью кода тестов не должно превышать 48 часов по 80-му перцентилю: 80% всех мердж реквестов за заданный период времени N укладываются в 48 часов.
Собранная помесячно статистика за прошедший квартал показала, что время жизни мердж реквеста превышает заданный интервал в 2–2.5 раза.
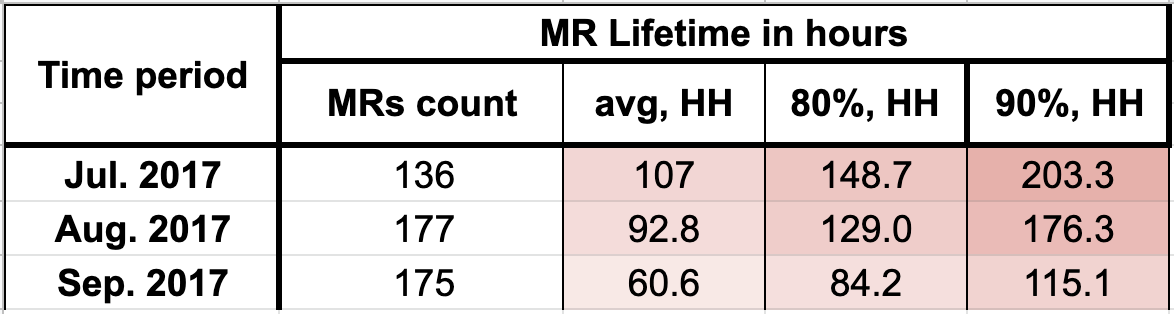
Помесячная статистика за третий квартал 2017-го года
Так мы сформулировали задачу на четвертый квартал — уменьшить время жизни мердж реквеста до 48 часов.
Мы собрали фидбек от ревьюеров: ребята сказали, что им может помочь инструмент, который автоматически назначает задачи и высылает напоминание о том, что необходимо сделать ревью кода. Так в нашей команде появился JiGit. Этот инструмент позволяет автоматически назначать исполнителя и напоминать ему про ревью. Подробно про создание инструмента и его функциональность мы рассказали в этой статье.
Уже в первом квартале 2018-го года наша статистика по метрике «Время жизни мердж реквеста» стала лучше, а еще через квартал мы вышли на установленный срок в 48 часов.
Статистика после внедрения JiGit, первый квартал 2018-го:

Продуктовые команды подтвердили эффективность инструмента ревью, а метрика показала то же самое на языке цифр.
Так мы живем уже больше четырех лет.
Статистика за четвертый квартал 2022-го:
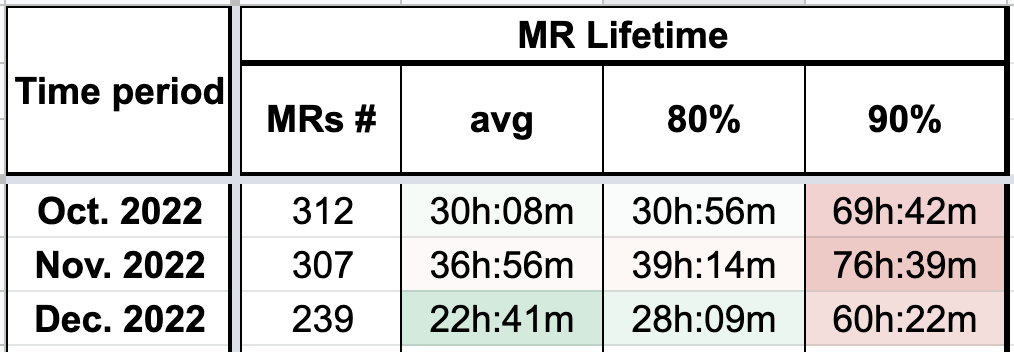
С помощью метрики мы контролируем и оцениваем скорость доставки кода тестов в мастер, а в случае каких-то аномальных отклонений можем точечно анализировать причины.
Например, мы обратили внимание, что в летние месяцы метрика по 80-му перцентилю приближается к пограничному значению (48 часов) и иногда незначительно выходит за его пределы. Мы изучили самые долгие мердж реквесты, которые очевидно влияли на финальную статистику, и выяснили, что многие ребята были в отпусках, про которые JiGit, конечно, «не знал». Тогда мы решили добавить код, который обрабатывает подобные кейсы, и вернули метрику в заданные значения.
Метрика «Время жизни мердж-реквеста» помогла нам оценить эффективность примененных улучшений и ускорить процесс код-ревью.
Кейс 2: оптимизируем время прогона тестов
В квартальном планировании QAA команды всегда есть цель по ускорению тестов: мы постоянно думаем о том, какие возможности и механизмы со стороны инфраструктуры и внутри тестового фреймворка могут позволить нам быстрее прогонять сборки с тестами.
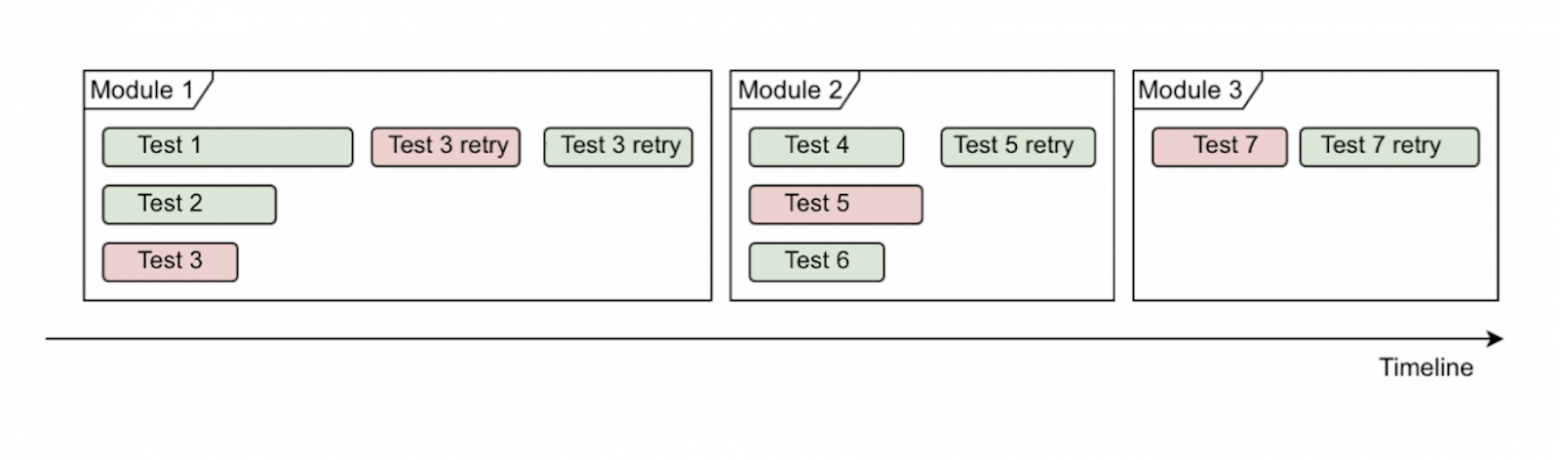
В нашем тестовом фреймворке порядка 55 тысячи тестов, и эти тесты расположены в 100+ модулях. Обычно для проверки скоупа отдельной продуктовой команды не требуется прогон всех тестов — c помощью разметки команды формируют свои паки/билды с тестами для проверок.
В большинстве случаев наборы с тестами лежат в разных модулях, и с ростом тестовой базы мы столкнулись с проблемой — регулировать количество потоков для параллельного запуска тестов стало сложно, потому что перезапуск упавших тестов после прогона всего модуля увеличивал время прогона всей сборки до 50%.
Так выглядит схема запуска мультимодульной сборки:
А так выглядел таймлайн сборки в Allure Report:
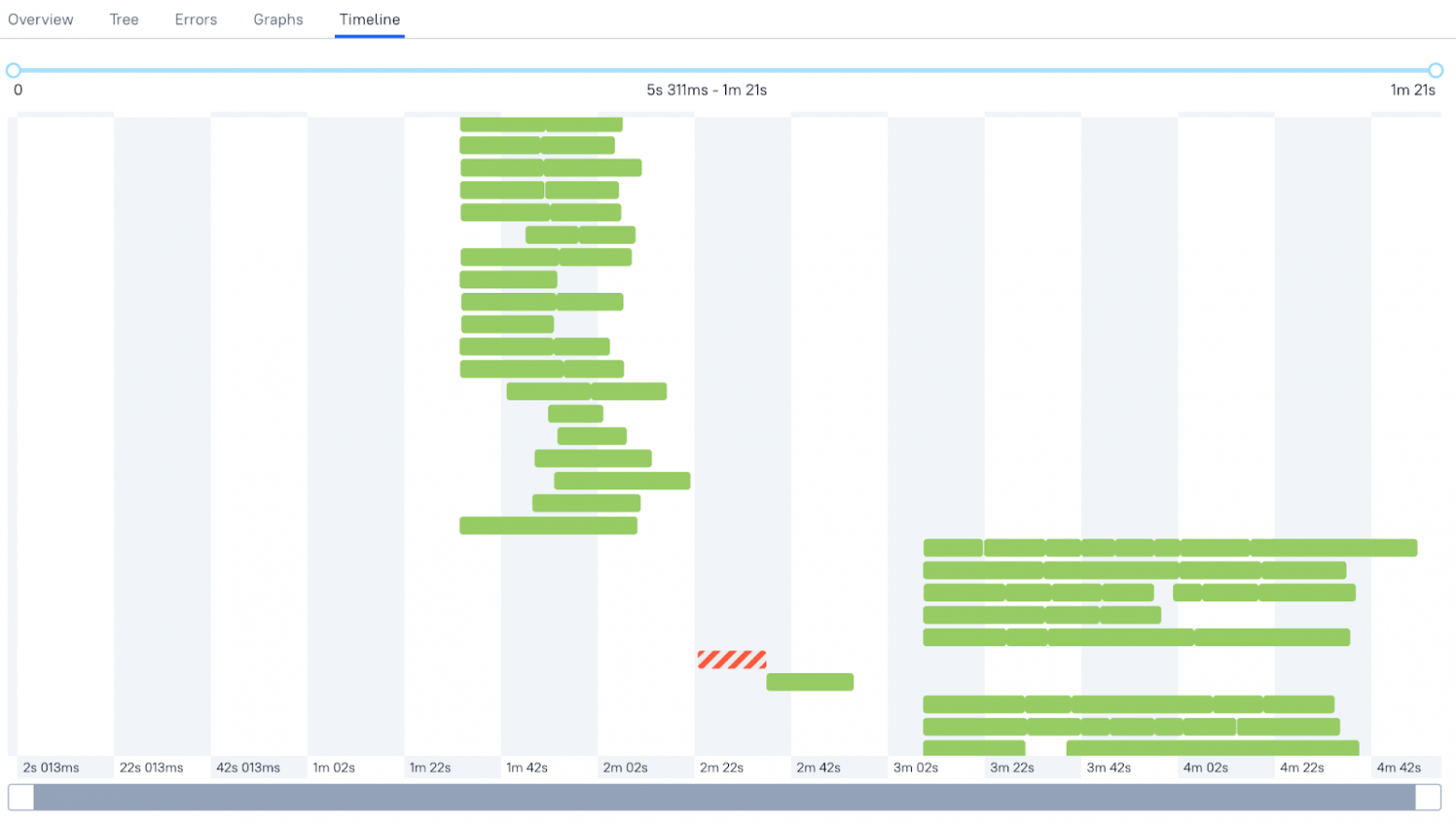
Внутри команды мы это называли дырявым «забором», через который утекает наше время и деньги
В этом случае наша задача — создать механизм объединения и запуска тестов из разных модулей внутри одного билда.
Мы попробовали объединить тесты из разных модулей в один, чтобы не столкнуться с проблемой неоптимального использования многопоточности и перезапуска упавших тестов.
Так схематично выглядит результат:
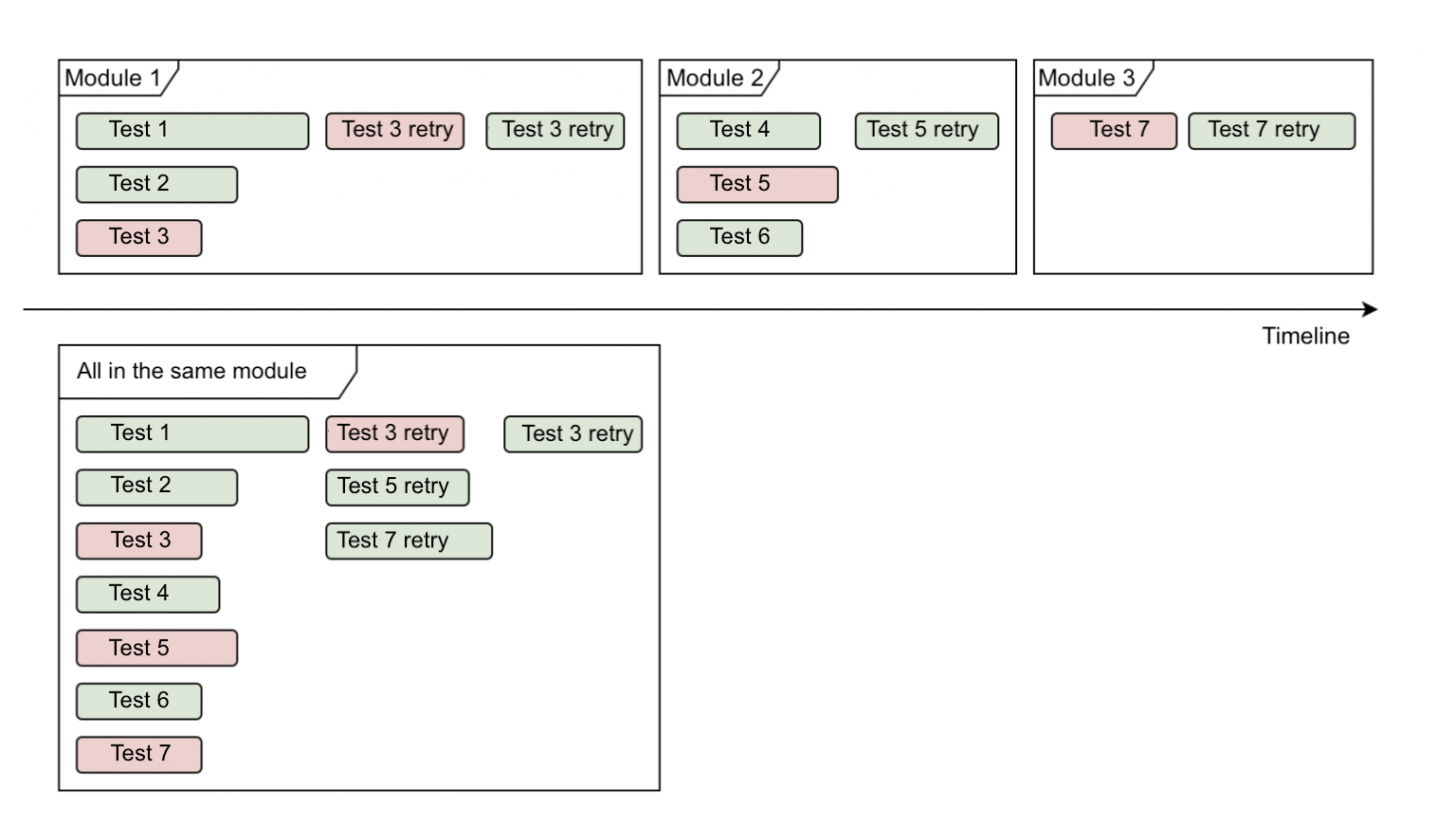
Для сравнения я включил схему запуска тестов до реализации механизма объединения тестов из разных модулей
Так таймлайн выглядит после внедрения мерджера модулей тестов:
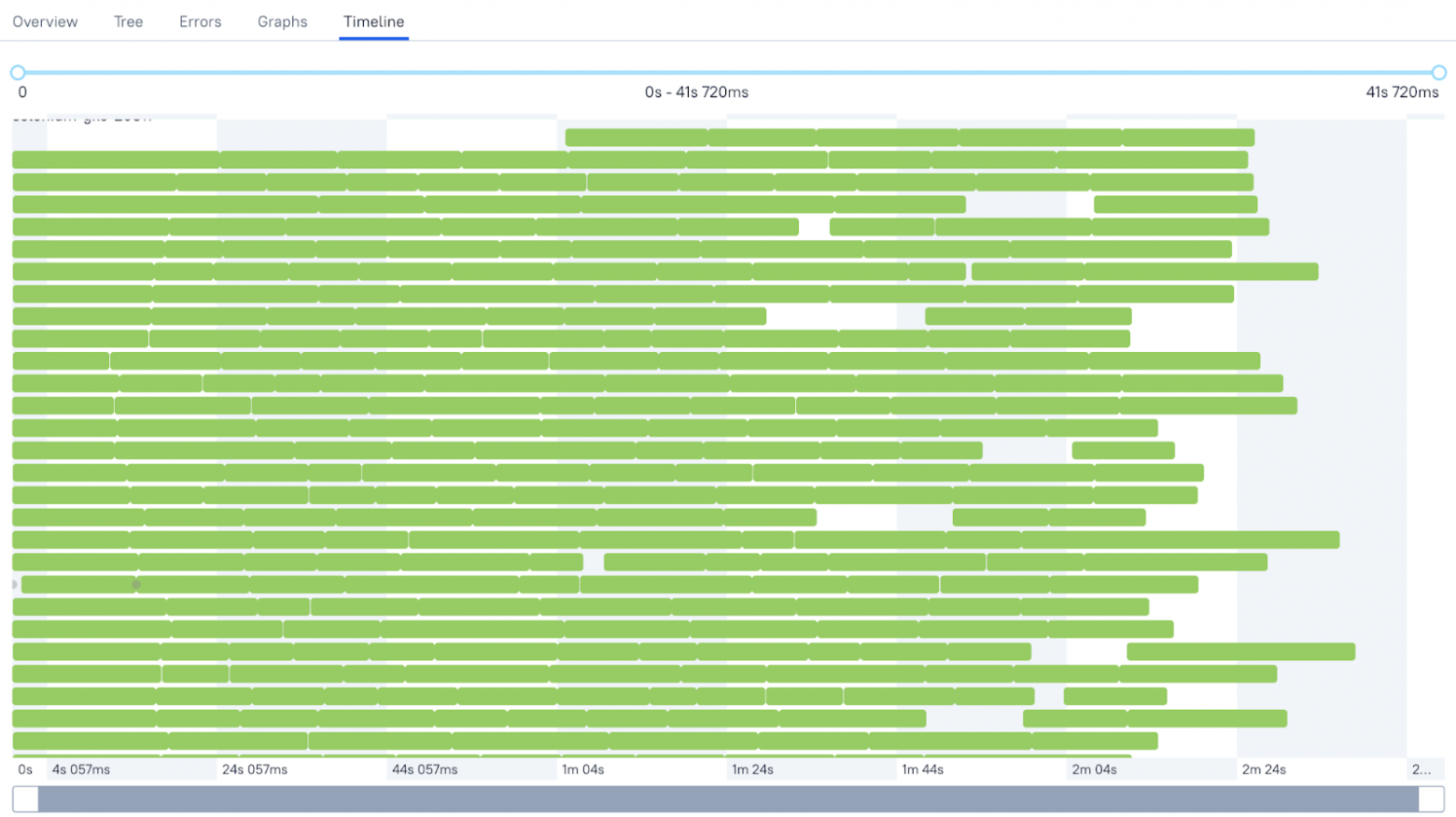
Кажется, что «забор» стал надежнее
Чтобы понять, насколько полезным оказался реализованный механизм, мы использовали метрику — «Время прогона многомодульной сборки тестов».
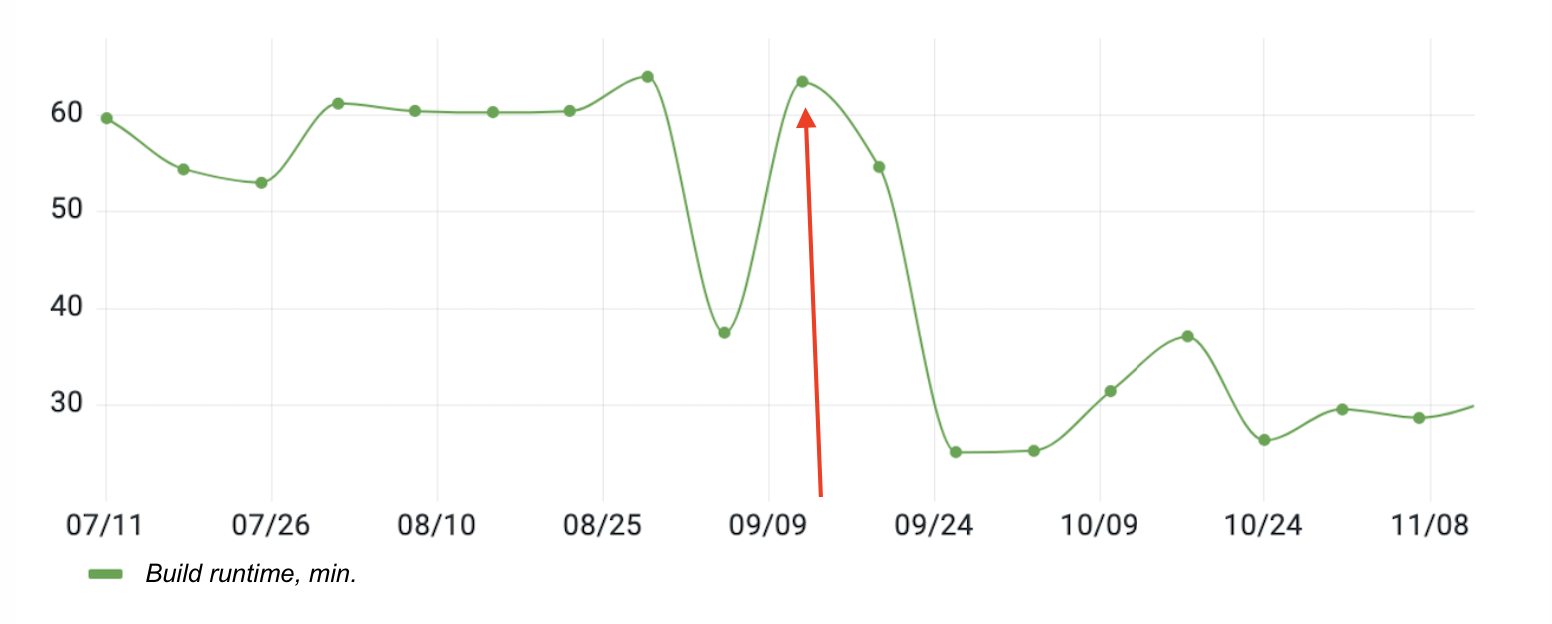
Сборка компонентных тестов, которая запускает порядка 11 000 тестов из 138 модулей, ускорилась ровно в два раза. Для проверки работы механизма мы выключили его на день — 09.09, этим объясняется скачок времени на графике
Мерджер модулей помогает нам экономить до 30% суммарного времени на прогоны тестов, а метрика «Время прогона билда с тестами» позволяет оценить его эффективность.
Кейс 3: стабилизируем тесты
Мы не только оптимизируем время прогона тестов, но и ежеквартально работаем с проблемой стабильности. Falls positives в UI-тестах — одна из главных проблем QAA команды. В нашем случае один из способов борьбы с нестабильными тестами — перезапуск упавших тестов в рамках одного прогона, который позволяет существенно повысить метрику «успешность тестов» (success rate).
На планировании задач на третий квартал 2022-го мы решили провести эксперимент и проверить, до какого значения мы можем увеличить количество перезапусков. При этом мы считаем допустимым увеличение общего времени прогона сборки не более чем на 20%.
Исторически сложилось так, что дефолтное значение retry count (перезапуска тестов) для всех сборок — 3.
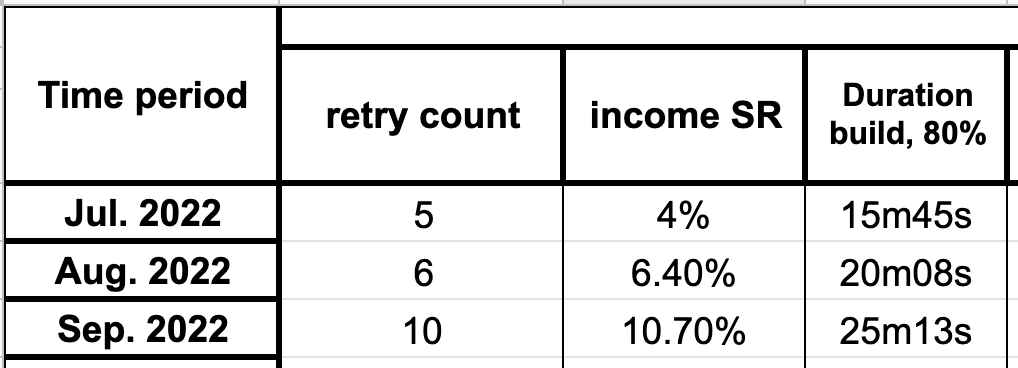
График показывает, что увеличение retry count до 5 увеличивает success rate на 4%. При увеличении с 5 до 6 success rate увеличивается еще на 2.4%, но время время работы билда выходит за допустимое значение в +20%. Если retry count равен 10, то success rate увеличивается больше чем в 2 раза, но и время сборки не отстает, наблюдаем почти двукратный рост.
Эти данные собирались с прогонов тестов по веткам фичей, которые находятся в разработке: в этом случае другие внешние факторы тоже влияют на success rate (баги, доля инфраструктурных падений, и тд). Но эксперимент позволил нам осознанно увеличить дефолтный retry count для всех наших сборок с тестами до 5, повысив success rate тестов в среднем на 3–4%.
В качестве эталонной метрики мы используем success rate регресc пака.
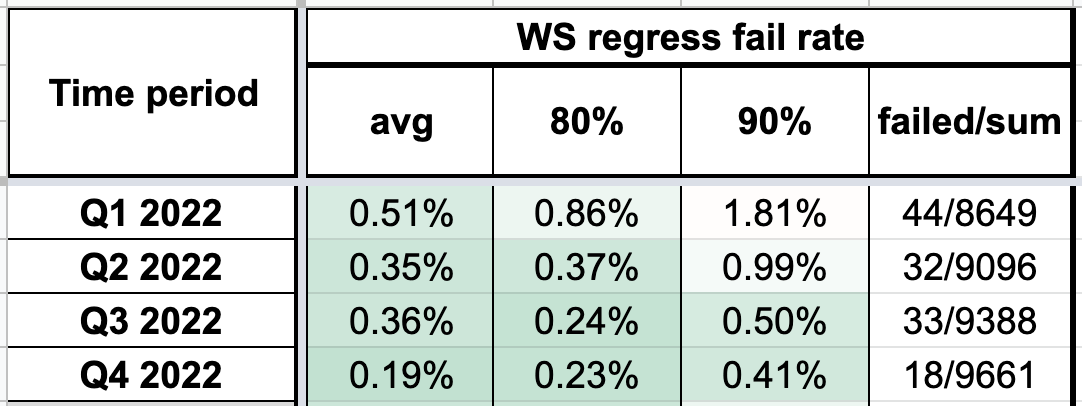
Увеличение retry count до 5 позволило повысить success rate на 0.13–0.14% в третьем и четвертом квартале 2022-го
Стратегия точечного улучшения процессов и кода по собираемым метрикам в нашем случае позволяет адресно и эффективно оптимизировать процессы, а также корректировать и оценивать степень влияния этой работы.
Сейчас мне крайне сложно представить работу команды без системы метрик. Я бы сравнил этот процесс с управлением современным самолетом со множеством приборов, которые облегчают и упрощают работу пилота, и управление самолетом 20–30х годов 20-го века с помощью бумажных карт, компаса и прочих механических инструментов, требующих сильно большей вовлеченности со стороны команды.
Надеюсь, что наш опыт будет вам полезен! Буду рад ответить на вопросы и комментарии.
