Настраиваем связку Apache Zeppelin + Oracle
Давно ищу удобный инструмент для выполнения ad hoc SQL-запросов в БД Oracle, с возможностью быстрого построения различных типов графиков на полученных данных. Все, что может облегчить оперативное создание отчетов, как говорится «на лету». Совсем недавно наткнулся на вот такой инструмент как Apache Zeppelin. Короткий обзор возможностей в документации на сайте и демо-видео показал, что это штука достаточно интересная и имеет смысл более плотно исследовать ее и настроить доступ из Apache Zeppelin к СУБД Oracle.

Вводная часть
Взрывной рост индустрии Big Data, Machine Learing потребовал новых инструментов и подходов для работы с большими массивами данных. Появились такие экосистемы и программные продукты Big Data как Hadoop, Spark, Storm, Elasticsearch и др… Десятки различных фрэймворков для машинного обучения с предустановленными алгоритмами. Ведущие университеты мира создают множество бесплатных курсов по машинному обучению и работе с Big Data.
Появились также и инструменты, которые решают задачи по визуализации данных. Хотел бы выделить два инструмента: это экосистема языка программирования R, созданная для статистической обработки данных и работы с графикой. И Weka – набор средств визуализации и алгоритмов для интеллектуального анализа данных и решения задач прогнозирования. Кстати, разработки обоих инструментов/языков программирования стартовали в 1993 году и оба из Новой Зеландии :). Ну и конечно, это множество других средств визуализации, которые практически каждая команда, предлагающая уже конечный продукт, делает сама под себя с использованием популярных фрэймворков для визуализации данных: D3.js, JfreeChart, HighCharts.js и другие.
Отдельно хотелось бы выделить направление интерактивных оболочек для работы с большими данным и машинного обучения. Самый известный и популярный инструмент — это продукт Python-сообщества – IPython. Судя по количеству упоминаний (сам я с ним плотно не работал), является стандартом де-факто в среде специалистов по машинному обучению. С 2014 создатель IPython начал новый проект Jupyter Notebook, цель которого создать полностью независимый от языка программирования интерактивный shell. Также, в этом направлении активно работают компании DataBricks, Beaker, которые развивают направление интерактивных shell инструментов для Data Scientist с упором на облака. Кроме Jupyter Notebook, есть и другие аналогичные инструменты, например Spark Notebook.
Итак, Apache Zeppelin – это один из представителей направления интерактивных оболочек для работы с Big Data и машинного обучения.
Работа над созданием Zeppelin была начата в недрах южнокорейской софтверной компании NFLabs в 2012-2013 годах (подробнее история создания от разработчика системы здесь).
Изначально цель была создать пользовательский интерфейс для разнообразных систем SQL over Hadoop, таких как Hive, Presto и Shark etc. Потом стало понятно, что существует потребность в создании более мощного инструмента для Data Scientist для совместной работы на больших проектах, не ограниченных только SQL. Поэтому была реализована встроенная интеграция с Apache Spark фрэймворком и возможность совместной работы в Notebook через WEB.
Возможности Apache Zeppelin:
- WEB-доступ к интерактивной консоли, SQL доступ к данным, Scala, Java итд.;
- концепция хранения результатов анализа и визуализаций в виде записной книжки (Notebook);
- визуализация данных с помощью различных типов графиков;
- возможности по созданию сводных таблиц (Pivot);
- динамическая установка параметров запросов в специальных формах (Dynamic Form);
- возможности по подключению других окружений исполнения, SQL-backend с помощью Interpreter API;
Установка Apache Zeppelin
Системные требования и инструкция по установке Apache Zeppelin доступны на странице проекта на GitHub или на сайте проекта.
Можно настроить окружение Apache Zeppelin и с помощью Vagrant на своей клиентской машине:
1. github.com/arjones/vagrant-spark-zeppelin
2. github.com/felixcheung/vagrant-projects
или Docker:
hub.docker.com/r/internavenue/centos-zeppelin/~/dockerfile
В своей работе я использовал Vagrant + ручную компиляцию из исходных кодов. Вы можете выбрать любой из предложенных способов.
Настройка связки Apache Zeppelin + Oracle
Качаем JDBC драйвер от Oracle (например ojdbc7.jar) по ссылке (требуется регистрация на сайте) и выкладываем драйвер по путям CLASSPATH. В случае Apache Zeppelin выкладываем файл драйвера в корневую директорию (/usr/zeppelin). Для Apache Spark – в SPARK_HOME/lib (теоретически загружать jdbc драйвер можно динамически, с использованием Dependency loader, но добиться видимости классов в SparkContext у меня не получилось).
Для работы с ojdbc7.jar возможно потребуется настроить Timezone при старте приложения. Если при попытке получить доступ к данным будет получена ошибка вида: ORA-01882: timezone region not found., то в файле настроек Apache Zeppelin /usr/zeppelin/conf/zeppelin-env.sh необходимо будет добавить значение своей, установленной на сервере, timezone. Например так: ZEPPELIN_JAVA_OPTS -Duser.timezone=UTC
Попытка № 1
Первая попытка получить доступ к Oracle была предпринята из окружения Apache Spark. С версии Spark 1.3 работу с БД рекомендуется вести через Spark SQL data source API. Указываем url доступа к БД, таблицу/набор данных и jdbc драйвер для соединения к БД. Проверить какие поля доступны для выборки, и загрузить набор данных как таблицу в память в окружении SQLContext с помощью процедуры registerTempTable(), после чего можно делать запросы к источнику данных.
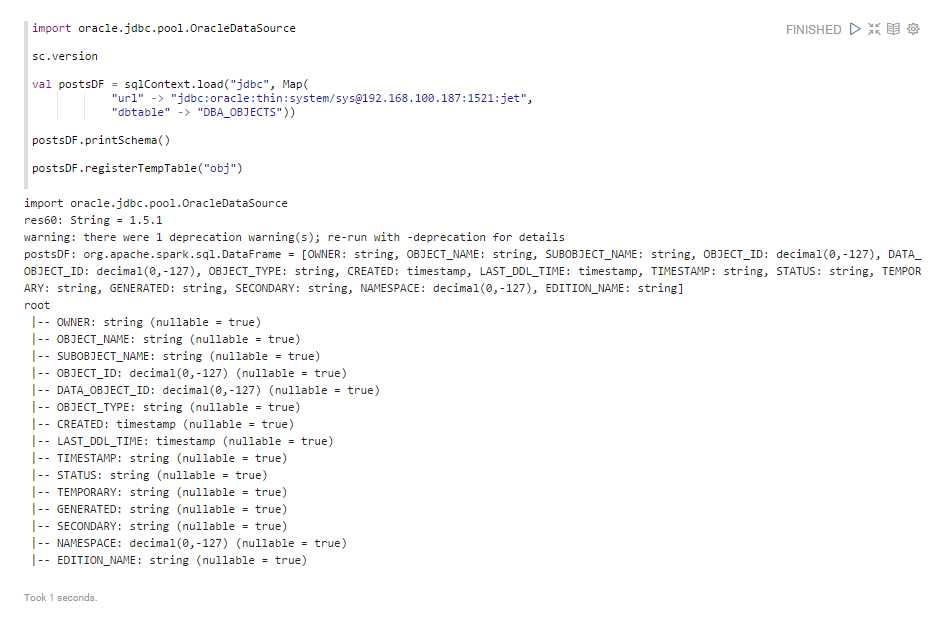
Теперь все готово для выполнения запроса по таблице OBJ
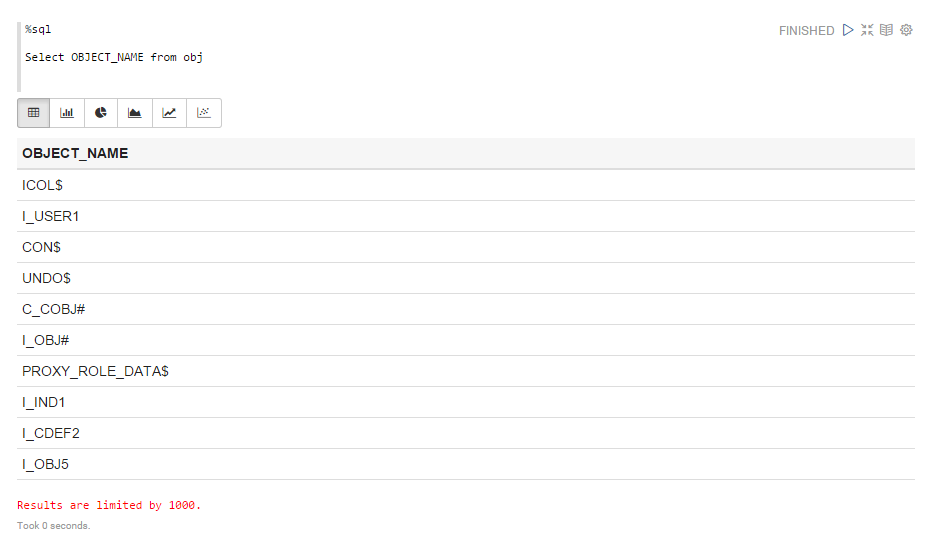
К сожалению, полноценный доступ к данным Oracle в Apache Spark не работает. При попытке выбрать данные с типом данных NUMBER, получаем следующую ошибку:

Данная проблема известна и описана в JIRA проекта Apache Spark: Spark sql jdbc fails for Oracle NUMBER type columns
Пока решения нет, соответственно полноценно, напрямую, работать с данными СУБД Oracle в Apache Spark непросто. Как обходное решение, в СУБД Oracle можно создавать представления, в которых делать конвертацию NUMBER to VARCHAR2 и использовать их для работы из Apache Spark. Но это дополнительные сложности с администрированием, выдачей прав etc.
Попытка № 2
Попробуем получить доступ к СУБД Oracle напрямую, не через Spark. Разработчики придумали систему расширений для этих целей — называется Interpreters. Отдельного плагина для БД Oracle еще нет. Но мы попробуем воспользоваться готовым для Postgresql – ведь это JDBC. Делаем необходимые правки в интерфейсе Zeppelin на закладке Interpreters для psql:
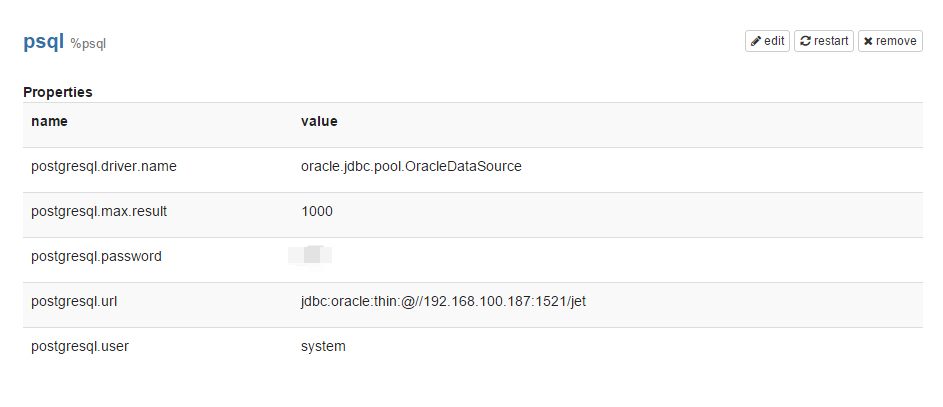
И пробуем выполнить тестовый запрос:

Попробуем визуализацию данных из истории активных сессий:
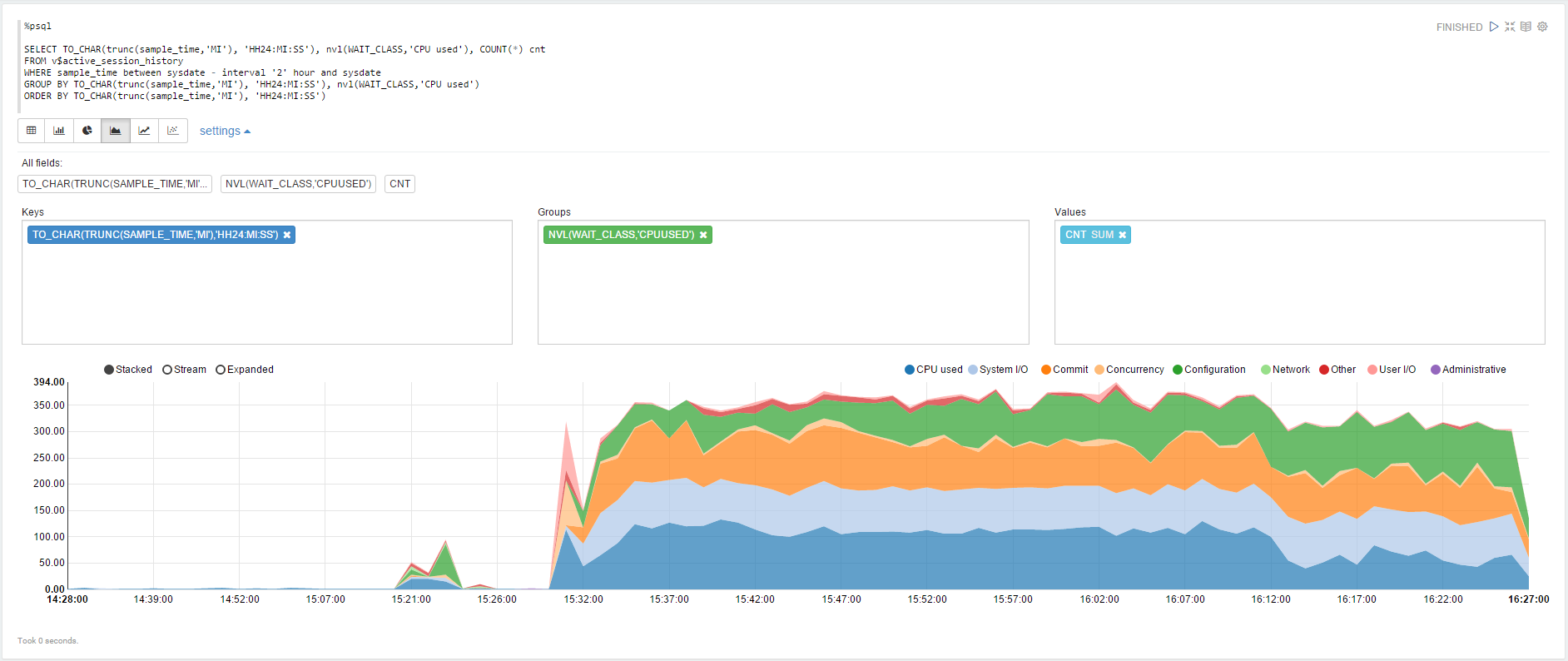
То же, но с использованием динамической формы для изменения диапазона выбираемых данных:
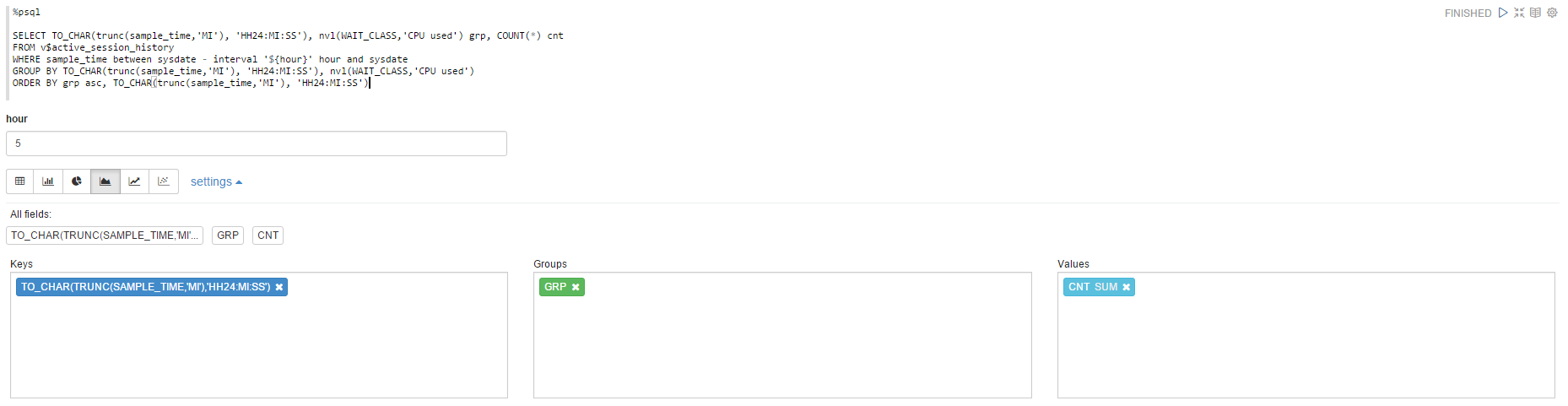
Можно также попробовать динамически обновляемые в страницы, например статистику твитов аккаунта: Capture Tweets from the Twitter от Gustavo Arjones
Указываем параметры приложения для доступа к своей ленте:
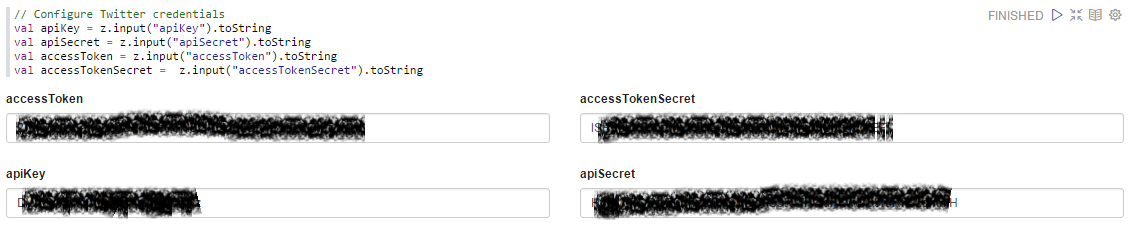
Сам код, который творит магию:

Динамически обновляемая статистика твитов из вашей ленты в отдельном окне:
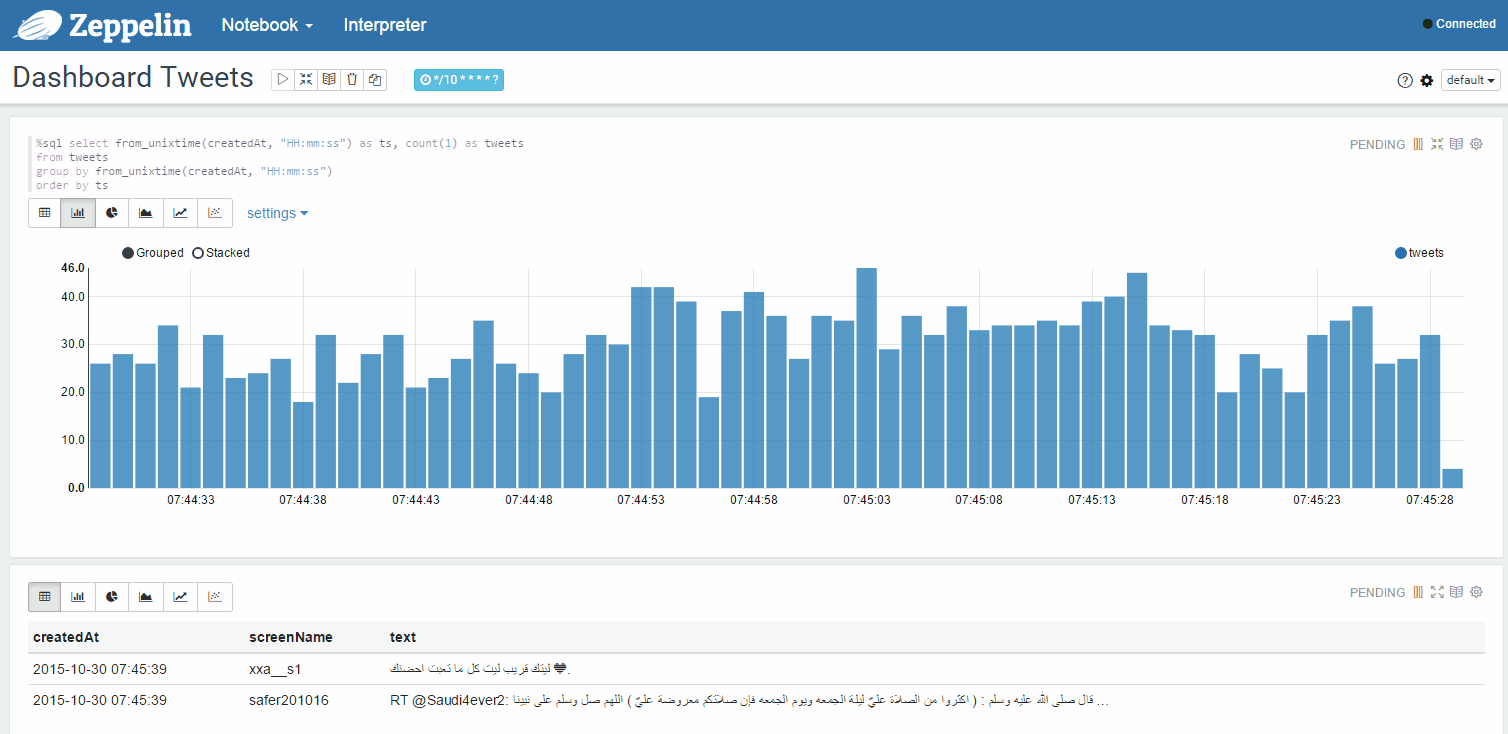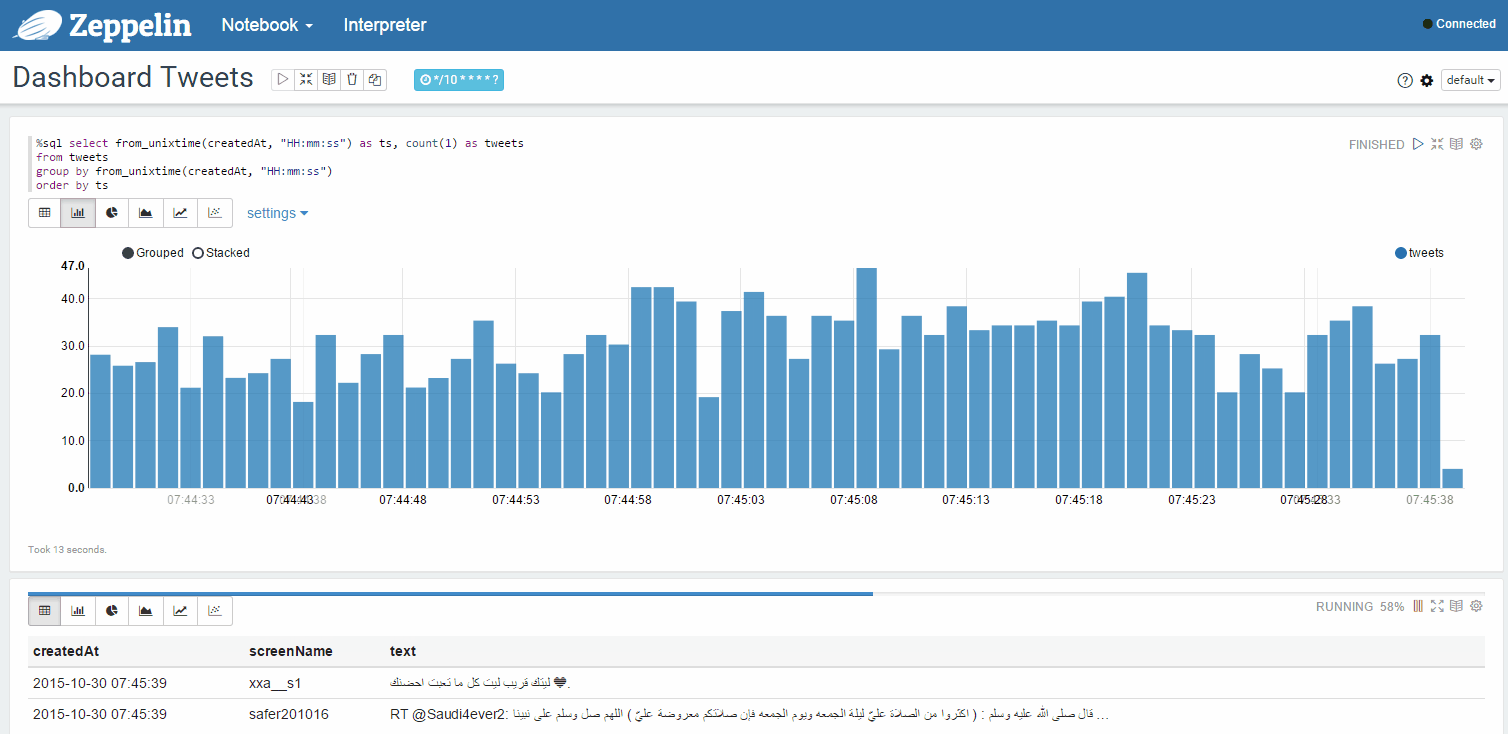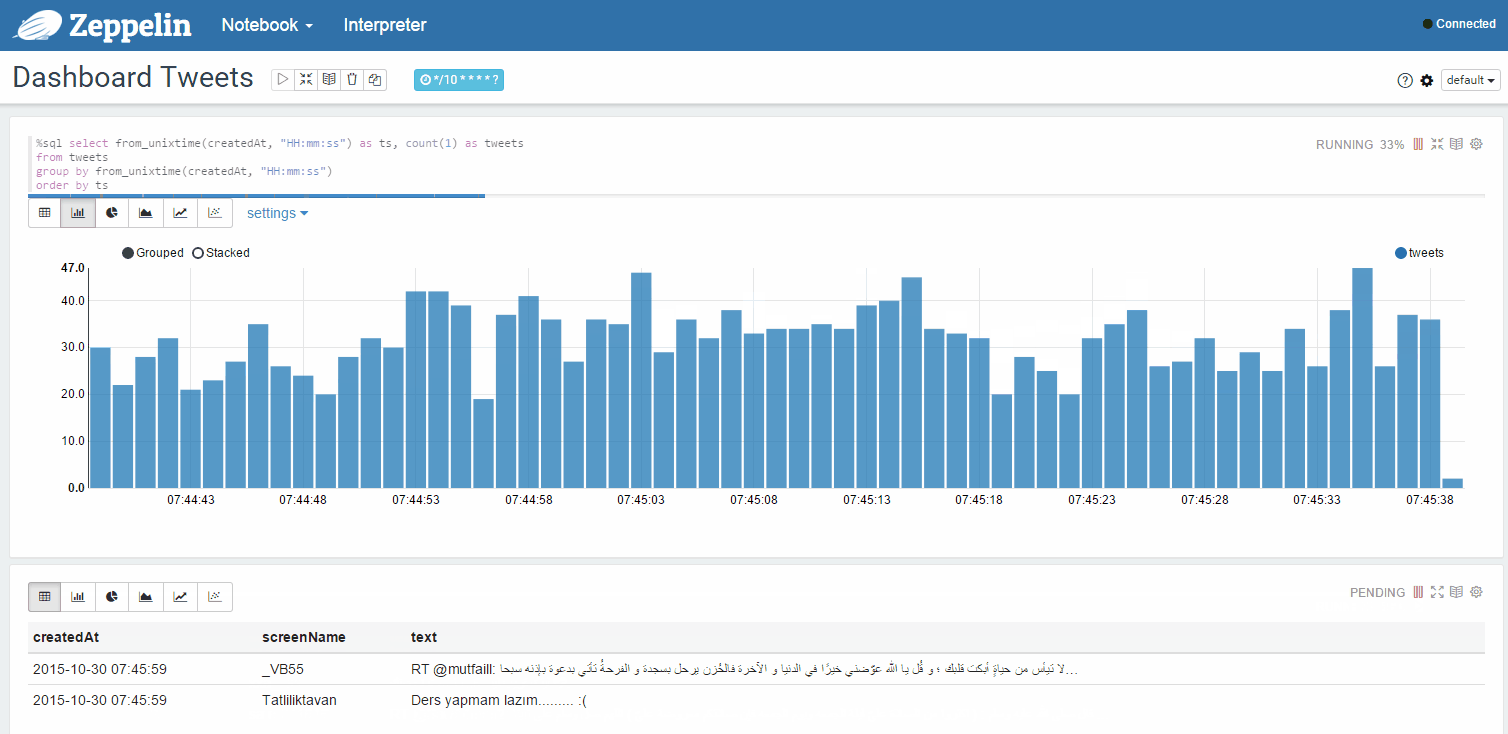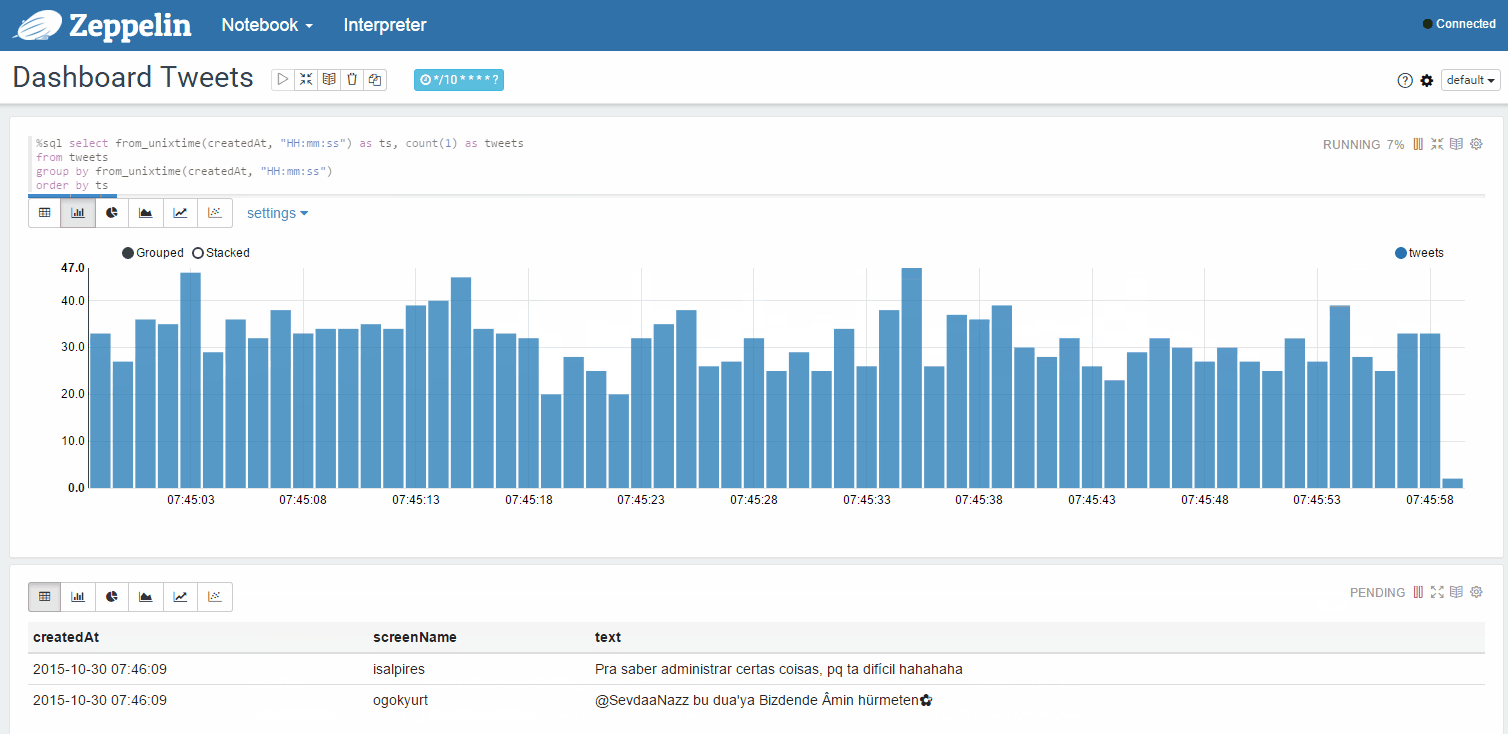
Возможные варианты использования (дополнительные):
— Генератор отчетов для ad hoc запросов;
— Создание гибко настраиваемых окружений для несложных систем мониторинга и наблюдения за ключевыми показателями ИТ-систем.
Недостатки:
— Пока слабо развито сообщество разработчиков. Количество пишуших код в Apache Zeppelin по сравнению с Jupiter Notebook;
— Набор типов графиков пока маловат, у конкурентов побогаче будет;
— Есть небольшие баги, которых немного, но они не мешают полноценно, без нервотрепки, использовать основной функционал. «It just works».
Apache Zeppelin – интерактивная оболочка для выполнения запросов над Big Data, работы с Machine Learning, последующей визуализации результатов и коллективной разработки.
В связи с ростом объемов данных, новых задач по поиску новых знаний требуют для исследователей удобного инструмента (окружения) для своей работы. Ниша интерактивных оболочек на данный момент одно из перспективных направлений: June 12, 2015, 8 New Big Data Projects To Watch, author: Alex Woodie. Мы наблюдаем интересную тенденцию – это появление гибридных программных комплексов, позволяющих упростить задачи подготовки и анализа больших данных, визуализации и совместной работы для Data Scientist. Удобный интерфейс для визуализации, который предоставляет Apache Zeppelin, также будет полезен администратором и разработчикам БД.
Судя по активности разработчиков по передаче кода в открытый доступ под крыло Apache Foundation в рамках программы Apache Incubator, созданию специализированного портала ZeppelinHub для выкладывания подготовленных Notebook, команда разработчиков планирует активное развитие продукта и выход на более широкую аудиторию.
Используемое ПО:
Спасибо за внимание!
