Настойка можжевельника: готовим Juniper SRX. Часть 1
juniper — можжевельник (англ.)Намедни в мои цепкие лапы попали два Juniper SRX 550. Попали не просто так, а для организации надежного ipsec и NAT-шлюза, а также OSPF-роутера. Ну, а так как главное для нас — надежность, то именно с нее и начнем.
Для того, чтобы обеспечить отказоустойчивость сервисов, критично важные узлы обычно дублируют. Для ЦОДов это уже практически стандарт — N+N или хотя бы N+1. При этом устройства могут работать как независимо друг от друга, так и в кластере. Для обоих типов есть свои плюсы и минусы, но если нужен не просто роутинг/свитчинг, но нечто более «интеллектуальное» (например, те же NAT или IPSec), то без кластера тут точно не обойтись. Так что при плановом апгрейде в качестве замены Cisco 7201 рассматривались именно роутеры, способные работать в кластере. В связи с этим ASR 1k отправился лесом (как и ISR), ASA не рассматривалась (потому как готовить ее не умею), а VSS из Cat6503 — это уж слишком жирно и в плане цены, и в плане съедаемой электроэнергии. Герой нашего рассказа. (Здесь и далее — картинки с официального сайта Juniper)Так что после поисков (недолгих) выбор пал на Juniper SRX 550, и выбор, на мой взгляд, оказался правильным.Juniper SRX — решение уровня филиала/головного офиса (branch office/HQ) для организации VPN, доступа в интернет и фильтрации трафика вплоть до L7.
Герой нашего рассказа. (Здесь и далее — картинки с официального сайта Juniper)Так что после поисков (недолгих) выбор пал на Juniper SRX 550, и выбор, на мой взгляд, оказался правильным.Juniper SRX — решение уровня филиала/головного офиса (branch office/HQ) для организации VPN, доступа в интернет и фильтрации трафика вплоть до L7.
Это весьма удачная линейка, успешно конкурирующая с семейством ASA от Cisco. Хотя позиционируется она как фаерволы, по факту это полноценное решение для маршрутизации и фильтрации трафика, а также организации VPN. Область применения — от маленьких офисов до ЦОДов. Возможности — от IPSec до VPLS (включая Zone-based NAT, Firewall, IPS/IDS и антивирусную защиту). К этому стоит добавить вменяемую политику лицензирования (привет, Cisco!), обилие поддерживаемых интерфейсов (существуют карты для xDSL, E1/T1 transport, ethernet switching, а также модели с поддержкой 3G/LTE) и на выходе мы получим практически идеальное «пограничное» решение для энтерпрайза (как центрального офиса, так и филиалов). Практически — потому что нет пока, увы, полноценной поддержки телефонии, и еще кучи всего, что есть, например, в том же ISR. А в остальном — просто супер.
Внутри — полноценный JunOS со всеми вытекающими. Соответственно, если есть опыт в настройке другого оборудования Juniper, то проблем не возникнет совершенно.
Перво-наперво, из двух SRX соберем один кластер, который обеспечит нам HA, сотрудникам — стабильную связь, а админам — крепкий и здоровый сон. Для этого между устройствами потребуется два линка — data и control. Управление, при этом, у каждого может быть свое. Младшие серии SRX поддерживают только Active-Standby кластеризацию, при которой одно устройство будет заниматься обработкой трафика, а другое — периодически с ним синхронизироваться, вплоть до состояния TCP и IPSec сессий, чтобы, если с первым чего случится, сразу же взвалить на себя его обязанности без простоя для пользователя. Схема довольно распространенная на сегодняшний день, Juniper ничего нового изобретать не стал. Для старших линеек, позиционируемых в ЦОД, возможна Active-Active работа.
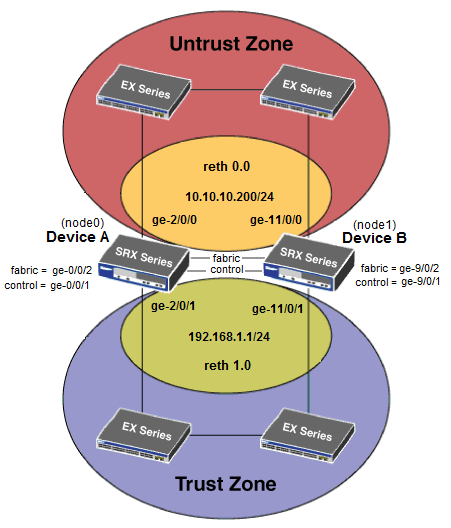
1. Готовим линкиУправление у нас будет жить на портах ge-0/0/0 каждого маршрутизатора. Он же будет fxp0.Далее собираем fabric-link (data) и control-link (signaling). fabric собирается на портах ge-0/0/2; control — на ge-0/0/1. При этом control будет обозначаться как fxp1. И при этом еще эти интерфейсы device-specific, т.е. управляться может каждое устройство в отдельности (ниже я покажу, как настроить роутинг для управления обеими нодами сразу).Подробнее про назначение этих линков можно почитать прямо на сайте Juniper (английская мова).
Остальные порты можно использовать как угодно по своему желанию.
2. Собираем кластерСобираем кластер тривиальной командой:
set chassis cluster cluster-id <0-15> node <0-1> reboot Где 0–15 это id стека (на самом деле 1–15, 0 это inactive stack). Номер стека влияет на генерируемый virtual mac для внешнего reth-интерфейса, поэтому если у вас в сети больше одной пары srx, cluster id у них должны различаться.0–1 это номер ноды. Соответственно, для сборки кластера мы должны на каждой ноде выполнить эту команду, при этом cluster id должен быть одинаковым, а node id различаться.После ребута интерфейсы на второй ноде будут именоваться как ge-9/0/x во избежание путаницы.
3. Настройка
Теперь настраиваем управление #Тут все стандартно — настраиваем hostname и ip set groups node0 system host-name jpsrx550–1 set groups node0 interfaces fxp0 unit 0 family inet address 192.168.1.241/24 set groups node1 system host-name jpsrx550–2 set groups node1 interfaces fxp0 unit 0 family inet address 192.168.1.242/24 #Тут настраиваем т.н. backup-router, #чтобы достучаться можно было не только до active-ноды, но и для standby set groups node0 system backup-router 192.168.1.1 #Destination можно указать любой, хоть 0.0.0.0/0, #но я ограничился только сетью, из которой будет производиться управление set groups node0 system backup-router destination 192.168.0.0/24 set groups node1 system backup-router 192.168.1.1 set groups node1 system backup-router destination 192.168.0.0/24 #А этой строчкой мы, собственно, применяем изменения. #При этом настройки применяются не ко всему кластеру в целом, а отдельно к каждой ноде. set apply-groups »${node}» Собираем fabric-интерфейсы, по которым роутеры будут обмениваться данныим set interfaces fab0 fabric-options member-interfaces ge-0/0/2 set interfaces fab1 fabric-options member-interfaces ge-9/0/2 4. FailoverRedundancy Groups — это виртуальный интерфейс, включающий в себя порты с обеих нод. Один из интерфейсов находится в состоянии Active, второй — в standby. Как только active-нода по какой-либо причине выходит из строя, или на active-интерфейсе пропадает линк, трафик переключается на бэкапную ноду. При этом агрегированные интерфейсы (ae) добавлять в reth-группы нельзя.Сборка Redundancy Groups #Настраиваем failover-группы, т.н. redundancy-group, #в которых определяем, какая нода будет главной, а какая — не очень set chassis cluster redundancy-group 0 node 0 priority 100 set chassis cluster redundancy-group 0 node 1 priority 1 set chassis cluster redundancy-group 1 node 0 priority 100 set chassis cluster redundancy-group 1 node 1 priority 1 # Так же можно выставить приоритеты конкретных интерфейсов set chassis cluster redundancy-group 1 interface-monitor ge-0/0/3 weight 255 set chassis cluster redundancy-group 1 interface-monitor ge-0/0/4 weight 255 set chassis cluster redundancy-group 1 interface-monitor ge-9/0/3 weight 255 set chassis cluster redundancy-group 1 interface-monitor ge-9/0/4 weight 255 Теперь самое интересное — т.н. reth-интерфейсы. Это не portchannel в классическом понимании, это именно failover-пары. Т.е. со стороны коммутатора это просто будут два порта с одинаковыми настройками.Настройка reth-групп #В лучших традициях Juniper, нужно заранее указать, #сколько reth-интерфейсов мы хотим использовать: set chassis cluster reth-count 2 #Сначала интерфейсы попарно собираем в reth-пары #Со стороны коммутатора это будут обычные порты, не объединенные #в etherchannel! set interfaces ge-0/0/4 gigether-options redundant-parent reth1 set interfaces ge-9/0/4 gigether-options redundant-parent reth1 set interfaces ge-0/0/3 gigether-options redundant-parent reth0 set interfaces ge-9/0/3 gigether-options redundant-parent reth0 #Потом определяем, к каким redundancy-группам они будут относиться. #Я решил не усложнять и оставить всех в одной set interfaces reth1 redundant-ether-options redundancy-group 1 set interfaces reth0 redundant-ether-options redundancy-group 1 #reth-интерфейсы ведут себя, по сути, как обычные routed-порты. #Т.е. можно ровно так же вешать на них ip, создавать sub-if и т.д. set interfaces reth1 unit 0 family inet address 192.168.1.1/24 set interfaces reth0 unit 0 family inet address 10.10.10.200/24 #Т.к. правила у нас будут zone-based (но о правилах и политиках в следующий раз), #то не забываем записать интерфейс в нужную зону set security zones security-zone untrust interfaces reth0.0 set security zones security-zone trust interfaces reth1.0 Как вы, наверное, могли заметить, с помощью приоритетов можно настроить failover-группы так, что оба устройства будут задействованы примерно равномерно. Это, разумеется, не полноценная active-active работа, но зато, например, можно «разложить» нагрузку на оба устройства.Применяем изменения:
commit 5. Легкие штрихиКластер мы настроили, остались мелкие штрихи, которые потом, думаю, обязательно пригодятся:
Наводим красоту #Назначаем hostname кластера set system host-name jpsrx550-X #Устаналиваем часовой пояс set system time-zone Europe/Moscow #Настраиваем DNS. Здесь лучше всего #прописать ваш внутренний DNS, #это позволит резолвить имена клиентов set system name-server 8.8.8.8 set system name-server 8.8.4.4 #Настраиваем доп. пользователя set system login user admin uid 2000 set system login user admin class super-user set system login user admin authentication encrypted-password «XXXXXXXXXXXXXX» #Syslog, куда будут капать наши логи set system syslog host 192.168.1.100 any any #Сервер точного времени set system ntp server 192.168.1.2 prefer #Настройки SNMP set snmp location DataCenter set snmp contact «noc@nixman.info» set snmp community public authorization read-only #Для зоны trust разрешаем все _входящие_ подключения. #Все, что идет не роутеру, а дальше, регулируется policy set security zones security-zone trust host-inbound-traffic system-services all set security zones security-zone trust host-inbound-traffic protocols all #Разрешения можно задавать не только для всей зоны, но и для каждого интерфейса в этой зоне set security zones security-zone trust interfaces reth0.0 host-inbound-traffic system-services all #Снаружи нас можно только пинговать set security zones security-zone untrust host-inbound-traffic system-services ping set security zones security-zone untrust host-inbound-traffic system-services traceroute Снова говорим commit и проверяем admin@jpsrx550-X> show chassis cluster status Cluster ID: 1 Node Priority Status Preempt Manual failover Redundancy group: 0, Failover count: 1 node0 100 primary no no node1 1 secondary no no Redundancy group: 1, Failover count: 4 node0 0 secondary no no node1 0 primary no no {primary: node0} admin@jpsrx550-X> show chassis cluster interfaces Control link status: Up Control interfaces: Index Interface Status 0 fxp1 Up Fabric link status: Up Fabric interfaces: Name Child-interface Status (Physical/Monitored) fab0 ge-0/0/2 Up / Up fab0 fab1 ge-9/0/2 Up / Up fab1 Redundant-ethernet Information: Name Status Redundancy-group reth0 Down 1 reth1 Down 1 reth2 Down 1 reth3 Down Not configured reth4 Down Not configured reth5 Down Not configured Redundant-pseudo-interface Information: Name Status Redundancy-group lo0 Up 0 Interface Monitoring: Interface Weight Status Redundancy-group ge-9/0/4 255 Down 1 ge-0/0/4 255 Down 1 ge-9/0/6 255 Down 1 ge-0/0/6 255 Down 1 ge-9/0/3 255 Down 1 ge-0/0/3 255 Down 1 Диагностика работы кластера: show chassis cluster statistics show chassis cluster control-plane statistics show chassis cluster data-plane statistics show chassis cluster status redundancy-group 1 На этом кластер можно считать готовым к работе.P.S. Конфиги, по возможности, убрал под спойлеры, думаю, так правильныей. Если надо достать — пишите в комментариях.
