Насколько легко доставить заказ, зная адрес клиента (не очень)
Всем привет! Меня зовут Денис Гирько, я системный архитектор e-commerce платформы в Lamoda. В прошлом году я выступал на конференции DevConf с докладом, которым хочу поделиться с вами.
Это обзорный доклад о том, с какими сложностями в процессе доставки заказа встречается крупный интернет-магазин и какие технические решения могут помочь их преодолеть (на примере решений, которые мы опробовали в Lamoda).

О чем пойдет речь? Расскажу:
- о процессе доставки и обозначу проблемы;
- как эффективно хранить территории доставки в базе;
- как повысить качество тех данных, которые мы получаем от клиента;
- как в адресной базе искать адресата, чтобы найти больше точных результатов.
Общая схема доставки заказа Lamoda
Lamoda — это интернет-магазин, у которого четыре страны доставки: Россия, Украина, Казахстан, Белоруссия. Мы доставляем товары уже на следующий день за счет того, что у нас есть собственная служба доставки и десяток сторонних партнеров, услугами которых мы пользуемся. Доставка — крупная часть нашего бизнеса.
Lamoda принимает заказ, спрашивает у клиента адрес во время оформления и передает его курьерской службе.
Что делать, если у нас не одна курьерская служба, а несколько? Тогда добавляется следующий шаг — определить, какой службой доставки мы повезем заказ.
Здесь могут быть какие-то бизнес-критерии выбора. Но первое, о чем нужно подумать — есть ли у этой курьерской службы доставка в выбранный клиентом город или нет. Поэтому первый шаг интеграции любой курьерской компании в нашу систему — это узнать её территорию покрытия.
Далее необходимо научиться проверять, попадает ли адрес клиента в эту территорию, или нет.
Общая схема усовершенствуется и будет выглядеть так:
- спросить адрес;
- выяснить, какие курьерские службы могут доставить ее;
- выбрать нужную из доступных.
Теперь чуть подробнее об этих шагах.
Спрашиваем у клиента адрес
Как можно его спросить?
- Попросить заполнить одно большое поле. Клиент забивает в него свой адрес, с которым далее не нужны никакие хитрые манипуляции. Адрес можно распечатать на листочке, отдать пешему курьеру, который дальше сам во всем разберется.
- Второй вариант посложнее. Просим клиента заполнить каждый компонент адреса в своем поле. Здесь уже можно кое-что сделать. Например, город Москва сравнить с заданным перечнем городов. Но сработает это плохо, потому что город Москва можно написать разными способами: «г. Москва», «город Москва», «городМосква» без пробела и так далее.
- Поэтому есть еще более усовершенствованный вариант. Так как список городов у нас конечный, то можно заранее составить их список и предложить клиенту выбрать нужный. Бонус в том, что каждому элементу такого списка мы можем уже здесь сопоставить какой-то идентификатор. Мы, разработчики, любим работать не со строками, а с идентификаторами, которые можно использовать во всех наших системах как эквивалент выбранного города. У меня на слайде в качестве идентификатора индекс центрального почтового отделения.

Какой службой доставки везем?
Раз у нас есть идентификатор (индекс), то пускай тогда и территория, которая хранится в нашей базе, будет представлена списком индексов. В таком случае алгоритм проверки попадания города в территорию очень простой. Так и сделаем: разместим территории доставки, полученные от курьерских служб, в базе в виде индексов.
У индексов есть свои плюсы и минусы. Я заранее скажу, что Lamoda на старте именно так и работала: результатом выбора клиентом города был индекс, и у нас индексы хранились в базе. Почему плюс? Как я сказал, индекс — это вещь всем понятная. Любой менеджер, который только пришел работать, знает, что такое индекс. Он может получить от курьерской компании города, как-то преобразовать их в индексы и использовать. Минус в том, что индекс — это идентификатор почтового отделения «Почты России». А рядом расположенные населенные пункты могут делить между собой один и тот же индекс.
Почему перестало хватать индексов?
Простой пример: Люберцы. Рядом расположена деревня Марусино. У Марусино нет своего почтового отделения, их корреспонденция приходит на одно из почтовых отделений Люберец. Если мы захотели добавить доставку в Люберцы, но не доставлять в Марусино, потому что это, возможно, нам финансово не выгодно, мы бы не смогли это сделать только индексом.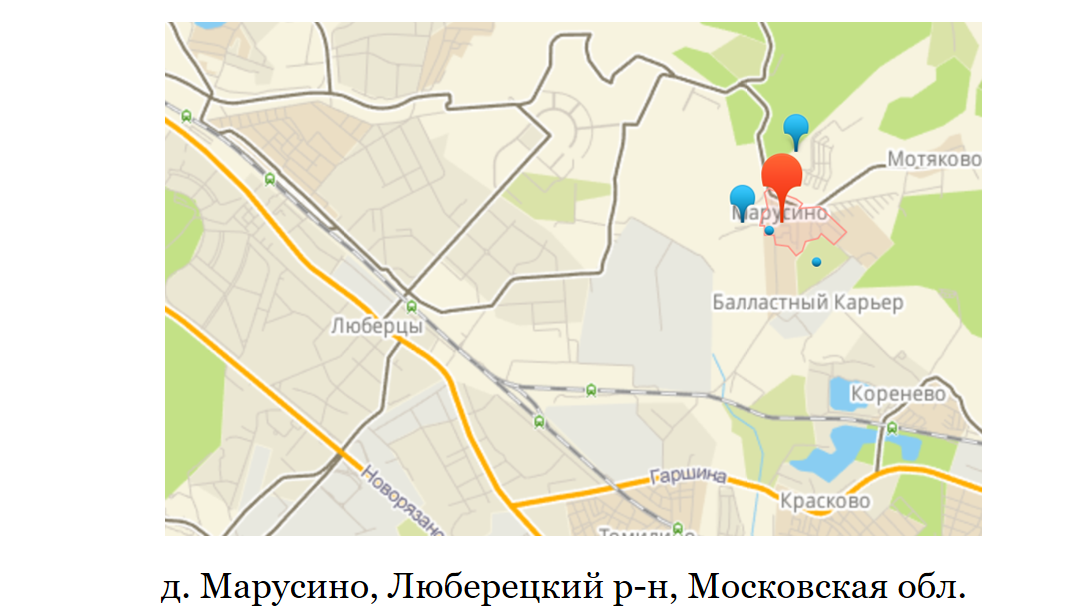
Другой пример, когда Lamoda расширилась и открыла второй транзитный склад в Москве. Понадобилось разделить Москву на северную и южную половины. И уже в момент оформления заказа понимать, из какого транзитного склада будет осуществляться доставка. В таком случае одного индекса на город не хватило бы.
Мы придумали использовать вместе с индексами геокоординаты. Берем адрес клиента, прогоняем через геокодер Яндекса. На выходе у нас получаются не только индекс, но и координаты. Индексы мы используем в тех кейсах, где детализация не важна. А координаты уточняют те случаи, когда нужно сделать тонкое разделение территории.
Предусмотрели интерфейс в своей программе настройки для логистов, который позволяет поверх карты нарисовать полигон. Все просто: попадает точка в полигон — есть доставка, не попадает — нет.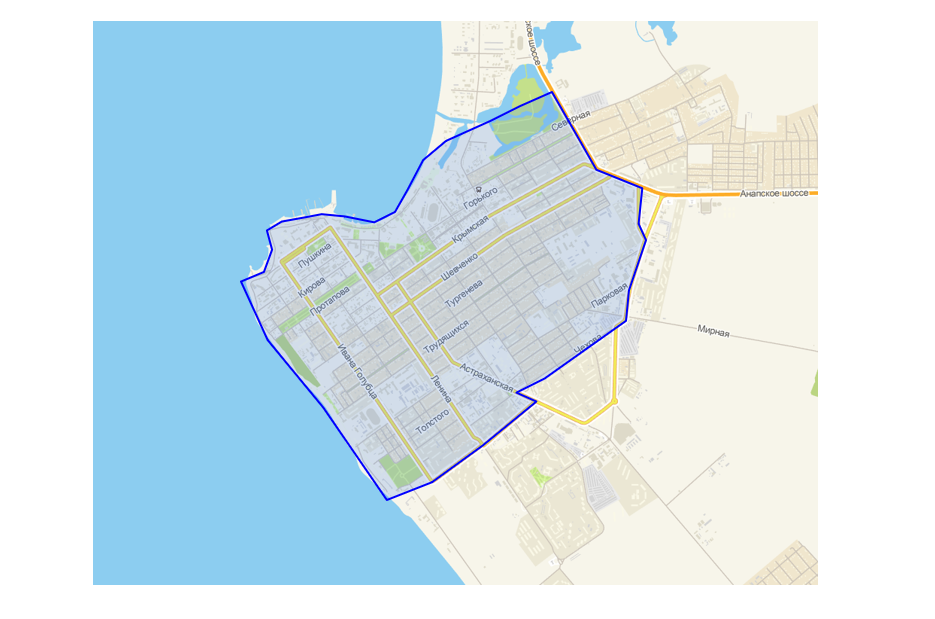
Интерфейс создания зоны с помощью полигона
Бонусом того, что мы имеем геокоординаты на каждый заказ, стала возможность усовершенствовать интерфейс, которым пользуются логисты для составления маршрутов для торговых представителей. В интерфейсе отображается карта, на которой отмечены заказы клиентов. Логист использует инструмент «лассо», который объединяет рядом расположенные заказы в один маршрут. Далее этот маршрут достается одному торговому представителю, то есть человеку не нужно в течение дня ехать из одного конца города в другой конец, чтобы отвести все свои заказы — они все территориально близки.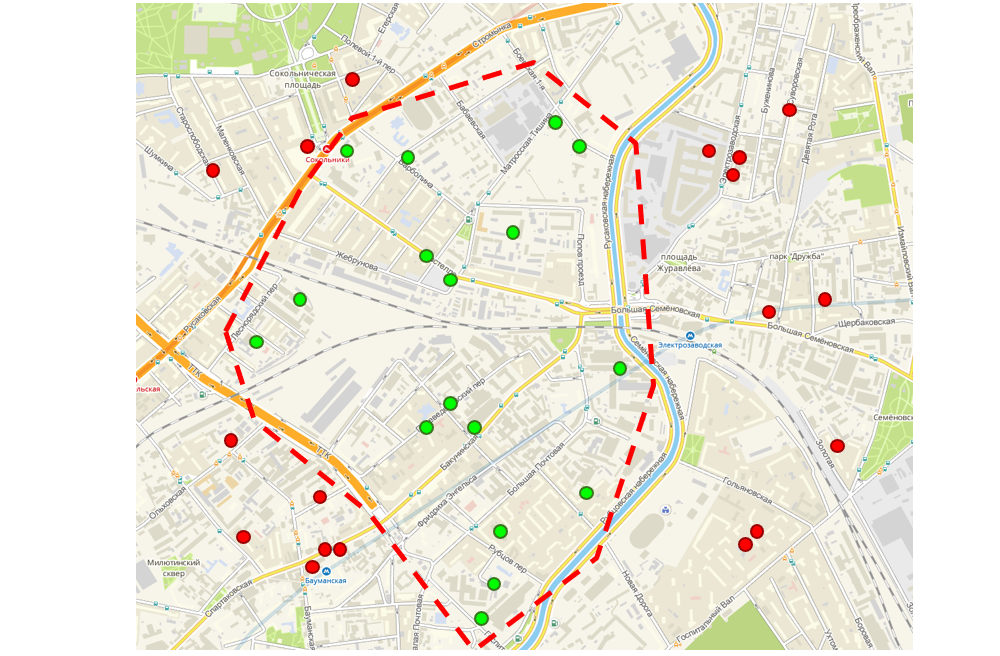
Интерфейс маршрутизации
Адрес, введенный клиентом, преобразуется в координаты. Вероятность того, что мы получим координаты для заданного адреса, напрямую зависит от качества того адреса, который ввел клиент. Поэтому первое, о чем мы задумались — это как увеличить число хорошо распознанных адресов. Следовательно, нужно помочь клиенту вводить правильный адрес.
Дело в том, что клиенты часто не следуют сценариям, которые мы для них предусматриваем, поэтому мы обзавелись адресными базами для каждой из 4 стран, в которые доставляем заказы. И сделали саджест не только для города, но и для улицы, и даже для номера дома. Чтобы составить список домов, мы распарсили открытые данные openstreetmap.org.
Форма оформления заказа предлагает подсказки, чтобы формализовать адресные данные
Адресная база
Чтобы делать саджест по адресной базе, ее нужно у себя хранить. Откуда мы достали все адресные базы для наших четырёх стран? В России — это ФИАС, адресная база, которая составляется и ведется нашей налоговой службой. Она довольно полная, хотя и не без огрехов. С другими странами нам помогли наши партнеры по доставке.
У нас есть еще набор PHP-скриптов, которые берут тот формат, с которым нам приходит адресная база, и примерно в том же виде складывает ее в PostgreSQL. Почему в том же виде? Потому что одной из задач является периодическое обновление этих баз из тех же самых источников. Это значит, что если бы мы предусматривали конвертацию, ее нужно было повторять при каждом обновлении.Таким образом, данные попадают в PostgreSQL, а оттуда они конвертируются и складываются в Apache Solr; Solr позволяет быстро по ним искать и делать саджест. Небольшой веб-сервер на PHP умеет строить запросы в Solr, по их результатам клиенту на сайте формируется список для саджеста.

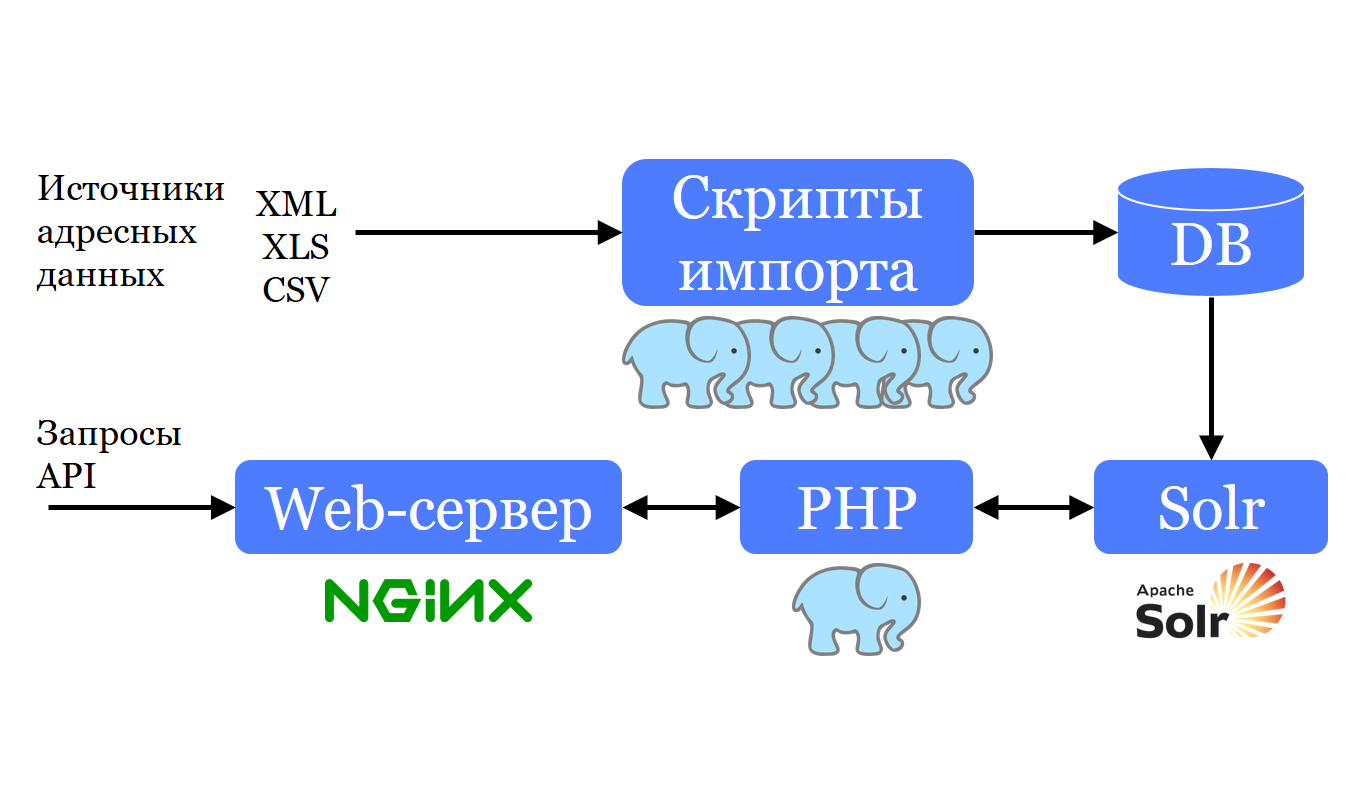
Мы загружаем данные из первоисточников примерно в том же виде, в котором они к нам поступили. То есть с тем же набором полей, с теми же типами столбцов и прочим. Складываем их, как есть. Мы пытались изначально использовать данные именно в таком виде, и чтобы преобразовывать их в те структуры, с которыми можно работать, написали несколько представлений (views). Так как у нас 4 страны, то все это умножалось на 4, и это было очень сложно и дорого в поддержке. Поэтому надо было с этим что-то сделать.
Первое, от чего мы избавились — это от неструктурированности, а точнее, от специфичной структурированности, на самом раннем этапе. То есть, как только загрузили сырые данные, с помощью views преобразовываем их в унифицированный формат, с которым дальше настроены все наши остальные преобразования. Это нас избавило от умножения на 4. И именно в этот момент мы забываем о той структуре, в которой к нам данные попали, и работаем только с тем, что сами себе придумали.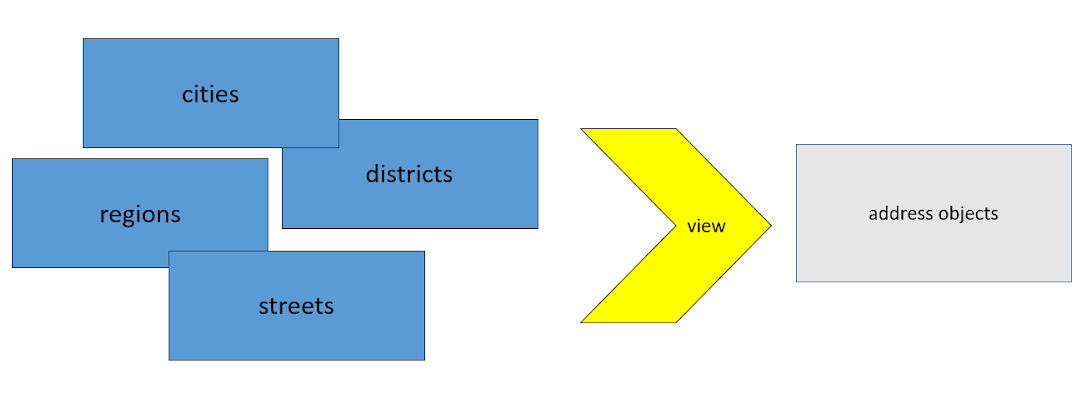
Если надо два источника — пожалуйста, загружаем. Главное, чтобы формат у этих данных на выходе после преобразования во views был одинаковый.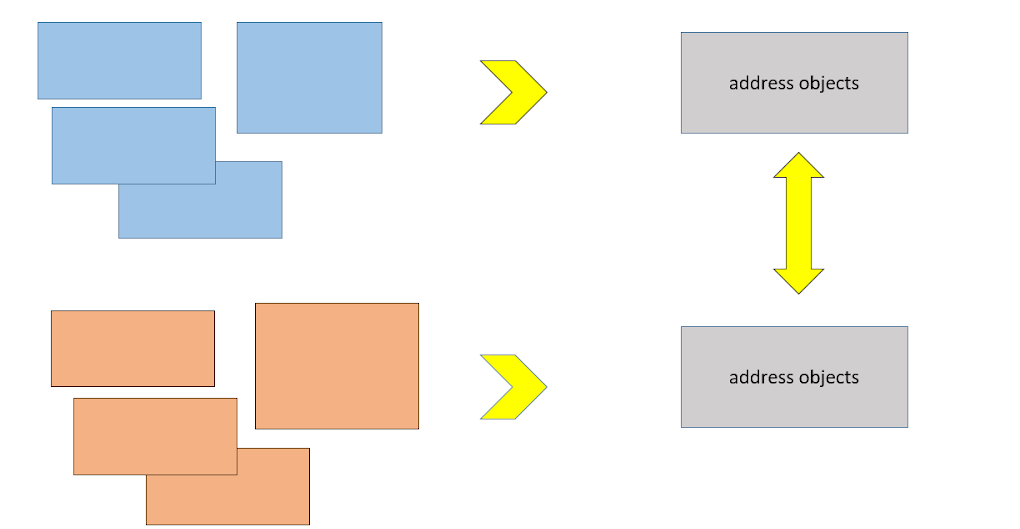
Еще одним требованием к загруженным адресным базам стало то, что нужно вносить в нее точечные исправления. Простой пример: в ФИАС-е Чувашская республика называется «Чувашская респ. — Чувашия». Ну, а мы хотим, чтобы была просто Чувашская республика. Зачем нам это тире? И при этом периодического обновления из источников нам все равно не избежать.
Вот следующие слои, которые расположены у нас в PostgreSQL.
Таблицы слева — это сырые данные, загруженные из первоисточников.
За ними views, которые преобразовывают данные в стандартный формат.
Local overridings — это у нас набор таблиц, которые точечно переопределяют какие-то атрибуты у загруженных адресных данных. Сюда мы внесли, например, что запись с таким-то идентификатором должна получить вместо «Чувашской респ. — Чувашии» наше выбранное имя.
Mapping table — это наше хранилище идентификаторов, которые мы сами назначили тем адресным объектам, которые загрузили — это позволило абстрагироваться нашим системам от источника, от тех идентификаторов, которые используется в источнике, а также спрятать за одним ID не один источник, а даже несколько — я расскажу чуть позже. Все это вместе объединяется и фиксируется в материализованном представлении (materialized view). Таким образом, у нас получается практически эквивалент финальной таблицы, который можно обновить запуском одной SQL-команды REFRESH MATERIALIZED VIEW.
Address objects — сформированная адресная база со всеми исправлениями и дополнениями.
Значит, на выходе у нас есть уже исправленные адресные объекты, уже с новыми названиями и нашими идентификаторами. Все это преобразовывается и денормализуется, как удобно для поиска, и складывается в Solr.
Так как у нас теперь есть адресные базы, классно бы по ним не только делать саджест для формы оформления заказа, но и делать поиск. Где может пригодиться поиск? Оказывается, много где. Те же самые зоны доставки, которые мы получаем от курьерских служб, очень часто представлены просто списком городов. А список городов таит в себе те же самые проблемы, как и с вводом пользователя: города могут иметь разночтения, разные названия и прочее.
У меня тут слайд специальный, такая страшилка — что нам приходилось бы делать, если бы мы брались все вручную это конвертировать на PHP: то есть Чечню, Чеченскую республику, и так для каждого источника данных — ад кромешный.

Дополнение: На скрине — кусок реального кода из сервиса, ставший ненужным как раз благодаря описываемым решениям.
Мы классифицировали эти проблемы.
1) Равнозначные названия одних и тех же объектов. Например, такие распространенные синонимы, как Чувашия и Чувашская Республика.
2) Переименованные города. На Украине сейчас активная фаза избавления от коммунистического прошлого, поэтому они буквально каждый день вносят изменения в названия своих населенных пунктов. По этой причине может получиться так, что в одной базе у нас старые названия, а в другой — новые.
3) Много и ошибок. Часто ошибаются в статусе населенных пунктов. Там деревня, здесь село или здесь село, там хутор.
4) Транслитерированные иностранные слова на русский, часто одно и то же название транслитерируют по-разному.
5) Много ошибок в иерархии: Зеленоград по привычке относится к Московской области, хотя формально и в ФИАСе он числится за Москвой. Правильно писать «Город Москва, Зеленоград».
Как мы придумали с этим бороться?
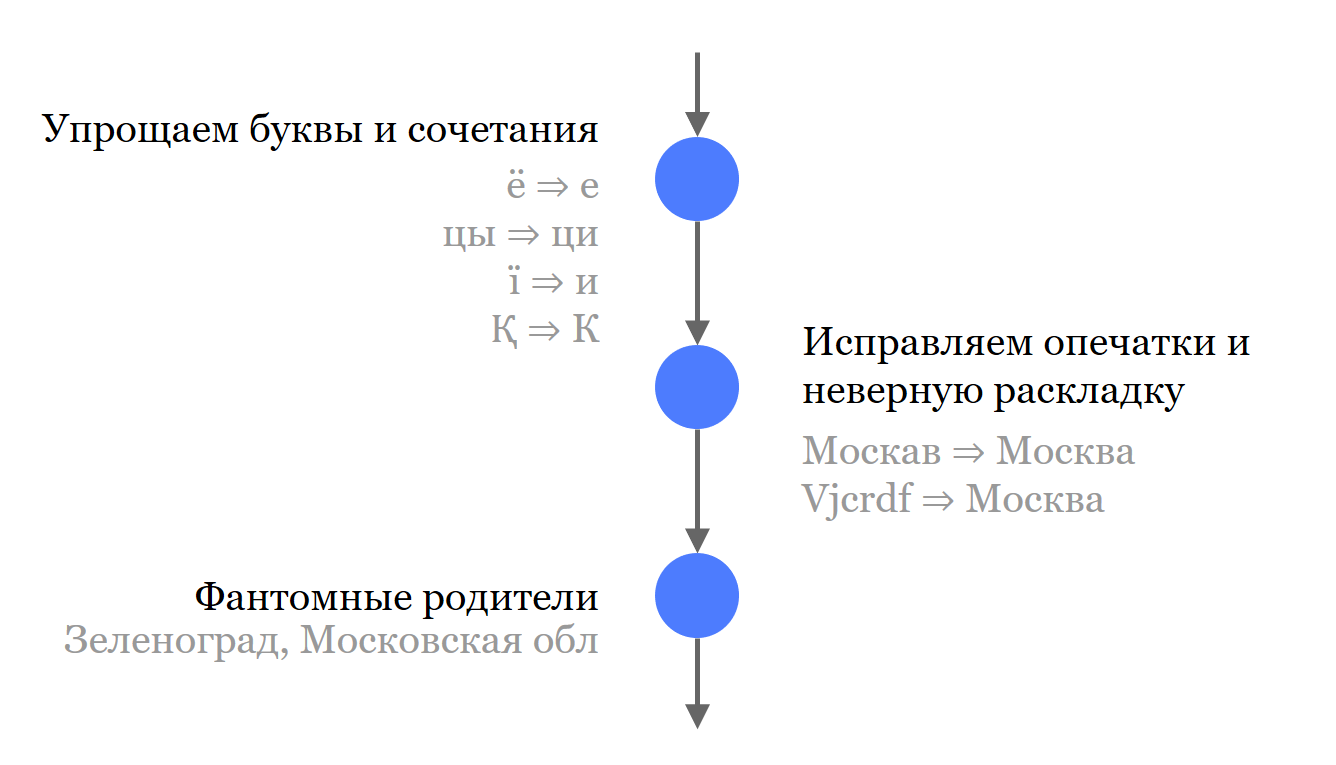
Первое, что мы делаем, отделяем все незначащие компоненты адреса от названий. Мы их не выбрасываем, они участвуют в поиске, но отдельно от значащих частей.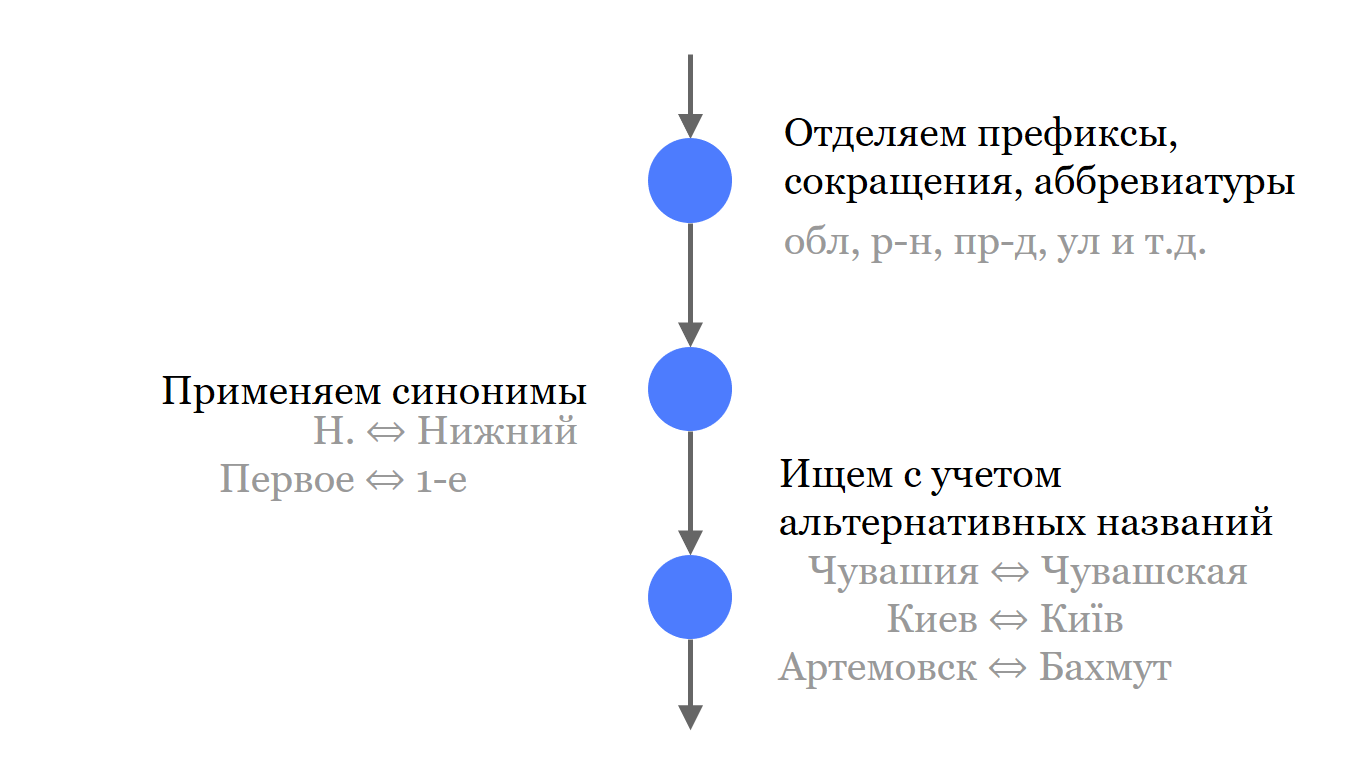
Далее мы составили небольшой список распространенных синонимов и сокращений, которые используются в названиях. Там, где это позволял первоисточник, мы загрузили и сложили в Solr все названия. Не только самые актуальные, но и возможные синонимы и исторические названия.
Чтобы лучше искалось, мы выкидываем все буквы, которые могут вносить разночтения. Это касается русского языка и тех языков, с которыми нам еще приходится иметь дело.
Исправляем опечатки и исправляем раскладку.
Наконец, мы придумали фантомных родителей — это родители, назначенные объектам. Они имеют значение при поиске, но не участвуют в выдаче результата поиска. Например, для Зеленограда мы добавили Московскую область. Теперь можно искать «Московская область, Зеленоград» и найти нужный нам объект, но в выдаче он все равно будет правильным «Москва, Зеленоград».
В зависимости от бизнес-требований нужна разная градация точности поиска. Поэтому у нас 4 степени, каждая из них дает результат с большей вероятностью, но с меньшей вероятностью это будет именно тот результат, который ищется.
И где мы нашли такому поиску применение?
- Мы еще раз прогоняем адрес, введенный клиентом, через такой поиск. Если он не использовал наши подсказки на странице оформления заказа, то у нас есть еще один шанс превратить строчки, которые он ввел, в идентификаторы. У нас получается формализованный адрес.
- Мы прогоняем через этот поиск все, что нам присылают курьерские службы — распознаем те города, которые они нам передают. Это позволило нам буквально по 10 штук в день запускать, это актуально для B2B — Lamoda предоставляет свою доставку сторонним компаниям, поэтому там очень много новых курьерских служб подключается в единицу времени.
- Это позволило нам «нанизать» на наши идентификаторы в адресных базах разные полезные сведения. Например, мы загрузили себе часовые пояса, IP-адреса, чтобы искать города по IP-адресам клиентов.
- У нас появилась возможность за одним нашим идентификатором скрыть объединенную из двух источников адресную базу. То есть, позволило избежать дубликатов и сопоставить одинаковые адресные объекты в обеих базах.
Мы не останавливаемся. Это процесс, который мы можем еще улучшить.
Во-первых, Lamoda работает на индексах. То есть наши идентификаторы — индексы, о минусах которых мы знаем. Уже почти все наши системы перешли на новый API, они оперируют не индексами, а теми самыми идентификаторами, которые мы сами назначили нашим адресным объектам. Плюс в том, что проверка попадания города в территорию настолько же простая, как с индексами. Однако нет минуса в том, что за одним ID могут крыться несколько населенных пунктов.
Дополнение: Прошло время с момента моего выступления, и теперь я рад поправить себя: индексы у нас сейчас остались только в кейсе, когда курьерка нам передает свою территорию в виде их списка, например «Почта России». В остальных случаях индексы были вытеснены нашими внутренними адресными идентификаторами.
На слайде кусок интерфейса, который позволяет вручную настраивать территорию, но вообще-то все настраивается из загружаемых пакетно списков адресных объектов в виде строк.
Мы загрузили геокоординаты из openstreetmap.org для домов. Теперь в большом проценте случаев нам не нужно ходить во внешний сервис для того, чтобы узнать местоположение. Это сократило нам в 10 раз где-то походы в Яндекс, что естественно сэкономило деньги.
Мы избавляемся от РНР в цепочке поиска по адресным данным. Переписали на Lua код, который обращался в Solr. Заменили nginx на Openresty, теперь все очень быстро и выдерживает большую нагрузку. 95% ответов нашего сервиса поиска укладывается в 10 миллисекунд, что нас более, чем устраивает.

Дополнение: Использование Openresty и Lua, которые привлекли своей производительностью — это был своего рода эксперимент, который себя оправдал: сервис работает быстро, стабилен под нагрузкой и легко поддерживается. Но с тех пор Lamoda приняла в качестве одного из языков программирования для нагруженного бекенда Golang, который обладает теми же качествами. Если бы решение о разработке сервиса принималось сейчас, мы бы отдали предпочтение ему.
Вывод
Моя личная мораль из всей проведенной работы, что адресные данные — это та область, где нельзя ждать идеального качества данных. Такого никогда не будет. Мы никогда не получим идеальных данных от клиента или из внешних источников. Поэтому приходится выжимать максимум из того, что есть.
