Наши 5 лет с инфраструктурой «ВсеИнструменты.ру»: от нескольких ВМ до отказоустойчивого решения в трёх дата-центрах
Cтатья посвящена проекту «ВсеИнструменты.ру» — крупнейшему интернет-магазину DIY-товаров и нашему клиенту по совместительству. Расскажем, с чего начинали сотрудничество почти пять лет назад, как сейчас идут дела и куда мы вместе идём. Поговорим о сопровождавших этот путь технических вызовах и особенностях решений в инфраструктуре, которые позволили бизнесу добиться впечатляющего роста.
«ВсеИнструменты.ру» — изначально онлайн-ритейлер товаров для дома и дачи, строительства и ремонта. С 2006 года активно развивает сеть фирменных торговых точек, а в настоящее время насчитывает более 600 собственных магазинов в 264 городах России и маркетплейс. Численность сотрудников превышает 7000 человек. 93% продаж приходится на онлайн, а это порядка 1000 RPS и ~1 млн уникальных посетителей в день.

Акт первый. Подъём на борт
Когда проект пришёл к нам, это была классическая схема с несколькими виртуальными машинами, каждой из которых отводилась своя роль. Основными компонентами инфраструктуры были:
База данных — нестареющий реляционный столп в виде MySQL версии 5.5. Размеры её не превышали 50 ГБ.
Backend — сердце приложения на базе Nginx + PHP-FPM 7.0. Было простое масштабирование: если приложение не справлялось с нагрузкой, разворачивалась новая виртуальная машина-клон.
Memcache для кэширования данных из СУБД.
Sphinx для поиска.
NFS — ведь нет более простого способа пошарить код или файлы статики между несколькими машинами.
Команду разработки составляли около 15 человек.
Подведём итог, что имелось по инфраструктуре и процессам её сопровождения на тот момент:
Виртуальные машины разворачивались вручную, и весь софт на них устанавливался «по требованию» и по мере необходимости руками.
Системы управления конфигурациями не использовалось.
Для хранения статики использовался NFS, смонтированный на ВМ с бэкендом. Забегая вперёд, хочется сказать, что он оказался очень живучим и надолго «прилип» к проекту, решая свою основную задачу, но мешая развитию (ежемесячно требуя жертву в виде инженеро-часов).
Распределения или резервирования, предусматривающего наличие больше одного дата-центра, предусмотрено не было.
По разработке:
Разработка и тестирование происходили локально. Окружение разворачивалось на машине разработчика с помощью Vagrant и Chef.
Деплой происходил с помощью самописной утилиты.
Миграции и прогрев кэша запускались на сервере вручную исполнителем после деплоя.
Акт второй. Таков путь
Несмотря на кажущуюся простоту и классическую конфигурацию, предстояло решить немало проблем:
недостаточная отказоустойчивость инфраструктуры;
отсутствие резерва и плана действий в случае проблем с ЦОД;
полуручной деплой;
сложность поддержки окружения для разработки, приближенной к production;
отсутствие автоматического тестирования;
деплоится только код, но не инфраструктурные зависимости (просто пакеты в ОС).
Глядя на задачи, стоявшие перед инфраструктурой, мы вскоре пришли к необходимости Kubernetes в проекте и переносу в него приложений. Забегая вперёд: в K8s было перенесено почти всё, с чем проект пришёл к нам, за исключением NFS и MySQL. О том, какие конкретно плюсы принесла миграция, рассказано дальше.
Несколько совместных встреч для обсуждения будущей инфраструктуры позволили нам понять основные актуальные задачи и начать их решать, каждый раз ставя перед собой новые цели. Было понятно, что нам нужна постепенная эволюция проекта, и потому опишем мы её тоже последовательно.
Отказоустойчивость
Каким бы хорошим ни был дата-центр, проблемы бывают у всех. А требования бизнеса к доступности критичного приложения диктуют свои условия: второй дата-центр жизненно необходим.
Вряд ли нужно рассказывать очевидные вещи о том, что резервирование:
значительно снижает время простоя;
даёт больше пространства для манёвров в случае деструктивных плановых работ;
позволяет деплоить потенциально проблемные релизы сначала на резервной площадке;
значительно повышает стоимость инфраструктуры и её обслуживания.
Техническая сторона вопроса на тот момент позволяла нам получить холодный резерв, то есть неактивную инфраструктуру, дублирующую production, но фактически без нагрузки. Конечно, хотелось бы сразу сделать горячий/активный резерв, но для его создания требовались серьёзные изменения как в инфраструктуре, так и со стороны работы приложения. Пойти на это тогда не получалось, потому что нужно было решать проблему отказоустойчивости в относительно короткие сроки. Идею активного резерва мы не забросили, но вернёмся к ней позже.
Я не зря акцентировал внимание на цене. Если вы хотите полноценный резерв, который будет надёжным плечом при отказе основных мощностей, нельзя пытаться сэкономить на его ресурсах или дублировать только часть инфраструктуры. Резерв должен быть полноценным (без урезания ресурсов) и полным (резерв всех компонентов). И в целях достижения необходимой бизнесу отказоустойчивости нашим выбором стали два географически распределённых дата-центра.
Сказано — сделано. Инфраструктура была продублирована, а между дата-центрами поднят VP LAN с двумя независимыми интернет-каналами. Для MySQL была организована репликация master-slave на старте и доросла до master-master репликации с RO на одном из узлов, а для NFS — синхронизация через lsync. Переключение клиентского трафика между дата-центрами (в случае аварий или по другой необходимости) в первое время производилось вручную, без детально описанного плана.
Аварийный план
Однако уже после нескольких переключений на резервный дата-центр стало очевидно, что эта операция требует очень продуманного, чётко упорядоченного плана действий — иначе что-то может пойти не так или попросту быть забыто. В результате план превратился в инструкцию, которая состояла из последовательности действий, требующих от исполнителя следовать им с минимальным пониманием происходящего.
Почему «с минимальным пониманием»? Всё просто: отказ инфраструктуры происходит в самый неподходящий момент. А ведь в такие моменты последнее, что хочется видеть при возникновении любых проблем, — это приборную панель самолёта с кучей «кнопочек и лампочек», в которых нужно долго разбираться…

Кроме того, чтобы выявить все недостатки/неточности плана и снять страх переключения — ведь речь идёт про нагруженный production, цена ошибки очень высока — был проведён ряд учений совместно с инженерами «ВсехИнструментов». Это был незабываемый месяц ночных посиделок для оттачивания переключений между дата-центрами. Без шуток, этот опыт был наполнен активным общением между инженерами двух компаний, что значительно сблизило наши коллективы, убирая ту самую стену между Dev и Ops, о которой сложены легенды.
В частности, во время этих испытаний всплыл интересный психологический барьер. Даже при наличии хорошего, проверенного плана не каждый инженер был морально готов нажать на красную кнопку (для переключения production-трафика) как можно скорее. Вам знакомо чувство «давайте ещё чуть-чуть подождём — вдруг сейчас всё [т. е. основной ЦОД] само заработает»?… Чтобы сократить downtime, в план был введён строгий лимит на время простоя, после которого переключение должно выполняться независимо от причин.
Итог этих учений — любая из сторон в случае подозрения (или явных проблем) могла самостоятельно и достаточно оперативно переключить трафик во второй дата-центр.
MySQL
Два дата-центра и… latency — антагонист любой инфраструктуры со множеством ЦОД и резервированием. Здесь нужно искать свой баланс между постоянными затратами на инфраструктуру, скоростью работы приложения и потенциальными рисками бизнеса в случае потери данных.
По итогам обсуждения возможных рисков пришли к довольно простой с технической точки зрения схеме: репликация типа master-master + для каждого master«а несколько slave-серверов в своём ДЦ, доступных для запросов только на чтение. «Второе плечо» нашей репликации, которое находится на стороне неактивного ЦОД, вообще полностью в read-only, чтобы избежать случайной записи в неактивную реплику.
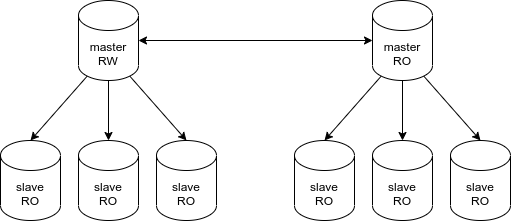
При такой схеме в случае нештатного переключения, когда полностью пропал доступ к текущему/активному ДЦ, трафик переключается с пониманием, что реплика перестаёт быть консистентной, и части данных может уже не быть в новом активном ДЦ. Это грозит нам необходимостью перезагружать данные во все базы «второго плеча», а коллегам из «ВсехИнструментов» — полуручным режимом восстановления данных, которые не успели синхронизироваться.
Основные проблемные места при эксплуатации такой схемы:
описанный выше split-brain;
длительное восстановление схемы в случае отказа одного из «плеч»;
человеческий фактор.
Для иллюстрации последнего достаточно передать привет товарищу, который однажды загрузил INSERT«ы в оба мастера MySQL. Мы не осуждаем этого человека: не ошибается тот, кто ничего не делает. Но после такого инцидента второй мастер стал не просто read-only, а super-read-only, чтобы как можно дальше отодвинуть человеческий фактор.
В процессе развития проекта БД MySQL выросла до 500+ Гб, то есть более, чем в десять раз. Поэтому перезаливка БД таких размеров уже начинает создавать сложности. Хотя как минимум трое человек из нашей команды могут восстановить репликацию, даже если их разбудят посреди ночи, а они будут с завязанными глазами. И вишенкой на этом торте стала простая особенность в репликации, когда MySQL, реплицируя только одну БД приложения, внезапно останавливалась от запроса на изменение пароля пользователя с мастера… И ты, Брут MySQL?
Переключения на резерв. Кто ты, человек или машина?
После нескольких учебных и аварийных переключений мы осознали, что не хотим заставлять задумываться инженеров подобными вопросами.
С помощью API CDN«а удалось автоматизировать переключение upstream«ов (а их много) и снять ощутимую часть ручных действий, отнимающих время у инженера. Благодаря этому удалось сократить downtime из-за человеческого фактора в несколько раз (!).
Однако, к сожалению, в схеме master-master с БД переключение базы осталось в полуручном режиме, так как часть функциональности приложения (cron, consumers) не предполагает работу в двух дата-центрах одновременно. Поэтому всегда нужен человек, принимающий сложное решение: ждём восстановления ЦОДа и оставляем cron«ы на месте или «сжигаем мосты», отключая проблемную инфраструктуру и СУБД, пока она не наделала проблем.
Возвращаясь к теме переключения трафика: зачем ждать инженера, который посмотрит на недоступный сайт и нажмёт заветную кнопку? Оказывается, в 90% случаев мы можем не терять время и на это. Следующий шаг по автоматизации переключения upstream«ов в CDN — простые правила для primary и backup:
Если основной upstream лёг — автоматически переключаем трафик на резерв. Но резерв оставляем в состоянии read-only (без части функциональности) — до решения дежурного инженера.
Дежурный инженер, видя, что трафик переключился, по сути просто «фиксирует» это переключение и продолжает с другими нужными действиями — по СУБД, cron, consumer — уже в более спокойном ритме.
Звучит странно? Но спросите в отделе продаж, что лучше: полностью недоступный сайт (полная потеря трафика) или «деградация» в его работе (потеря части функций)? Для нас это решение подошло как «меньшее из зол».
Благодаря этим улучшениям инструкцией по переключению на резерв мы пользоваться почти перестали, так как автоматики было достаточно. Исключения составляют ситуации, когда автоматика не отработала штатно. Для анализа этих ситуаций предусмотрен контрольный список для проверки всех событий (действий), которые должны были произойти.
Kubernetes
Самое время вернуться к упомянутой миграции инфраструктуры на Kubernetes. Этот процесс происходил не отдельно взятыми усилиями со стороны эксплуатации, то есть нас, а в постоянном взаимодействии с разработкой. Ключевой здесь была смена архитектуры проекта.
Достаточно простой монолит эволюционировал до большой микросервисной архитектуры. Это стало возможно благодаря:
разработчикам, силами которых приложения стали микросервисами, соответствующими 12 факторам;
роли Kubernetes именно как оркестратора, управляющего жизненным циклом контейнеров (создание, пробы, перезапуск, обновление…);
полной автоматизации CI/CD-процессов.
Процесс перехода к микросервисам происходил поэтапно: параллельно действующему монолиту запускались новые микросервисы, на которые переключалась нагрузка. Под капотом это выглядело как переключение определённых location в ingress на микросервисы, предназначенные для него. Первыми от монолита отделились сервисы, которые были наиболее критичны ко времени ответа и доступности.
Миграция сопровождалась появлением многочисленных фич, благоприятно повлиявших на жизнь всех занятых в разработке и эксплуатации. А в частности:
1. Канареечные выкаты
В статье упоминалась возможность выката в резервный ЦОД для тестирования потенциально опасных релизов. Однако на резерве нет реального пользовательского трафика, а нам очень хотелось бы тестировать новые релизы и на пользователях — точнее, на некоторой их части. На помощь приходит canary deployment, в случае которого процент трафика уходит на новую версию приложения (происходит A/B-тестирование).
Чтобы его реализацией на базе ingress-nginx в Kubernetes было удобно пользоваться (самим разработчикам), в административной панели приложения появились настройки, регулирующие, сколько именно и какой именно трафик уходит на новую версию.
2. Автомасштабирование consumer«ов
Иногда нужно «подкинуть угля» в какие-то функции сервиса, чтобы он смог выдать требуемую производительность в условиях ограниченных ресурсов. Речь о HPA. Понятно, что автомасштабирование идеально ложится на «резиновые» дата-центры вроде AWS/GCE/GKE. Но и в условиях фиксированного количества виртуальных машин HPA может использоваться, если имеется какой-то запас узлов для масштабирования сервисов.
Автоматическое масштабирование consumer«ов происходит в зависимости от нагрузки на них. В нашем случае источник такой метрики — Prometheus + exporter:
Exporter собирает как бизнес-метрики приложения, так и просто размеры очередей.
Есть N очередей, обрабатываемых разными consumer«ами. Поскольку система в целом сложна и взаимосвязана, нагрузка на каждую из очередей не всегда предсказуема.
HPA позволяет без вмешательства человека автоматически добавлять consumer«ов на внезапно активную очередь и уменьшать их количество, если нагрузка спала. Повторюсь, что это требует некоторый запас по ресурсам.
3. Штатные функции Kubernetes
Kubernetes выступает по сути супервизором для приложений — он следит за их жизненным циклом: перемещение между узлами, liveness/readiness probes, rolling updates, PodDistruptionBudget… Всё это позволяет обеспечивать нужный SLA:
В случае отказа узла Pod«ы с приложением переезжают на другой узел.
Проверки (probes) позволяют убирать из балансировки «призадумавшееся» приложение и дать ему «отдохнуть» или перезапустить, если оно зависло.
Rolling update обеспечивает плавный деплой без простоя.
PodDisruptionBudget защищает от автоматического вывода из балансировки критичного количества реплик приложения. Например, у Redis-кластера три узла — хотя бы один всегда должен быть Ready, чтобы можно было сделать evict Pod«ов с узла.
Подробнее об этих возможностях Kubernetes и наших рекомендациям по их конфигурации мы писали в другой статье.
4. Штатные функции Deckhouse
В особенности — прозрачный мониторинг/статистика. Deckhouse из коробки предоставляет преднастроенные Grafana со всевозможными графиками, в том числе по RPS/response_code для отдельных vhost/location/controller:
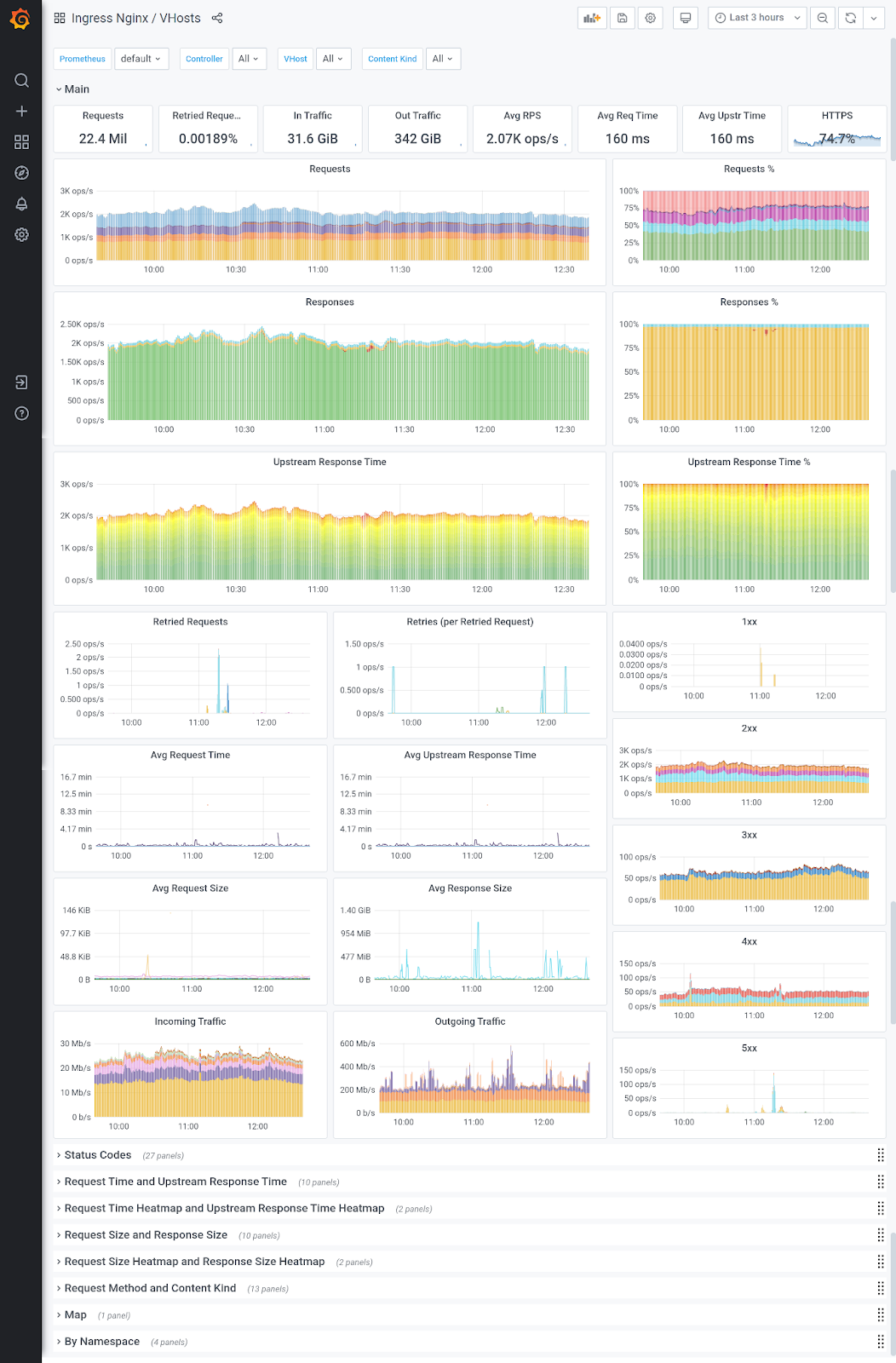
Вся это красота возможна благодаря тому, что «под капотом» — хорошо настроенный Prometheus, который собирает и множество других метрик. Кроме того, просто добавлять кастомные метрики, если ваше приложение может отдавать их, например, в Prometheus-формате.
Метрики и графики нужны не только для красоты: для реакции на них настроена отправка алертов через Alertmanager в нашу централизованную систему мониторинга. Каждый алерт проходит через определённые правила обработки: дедуплицируется, корректируется критичность алерта, обогащается дополнительными метками и инструкциями его обработки для инженеров.
Тема затрагивалась в нашем докладе »10 лет on-call. Чему мы научились?», из которого можно узнать подробности о пути алертов в системе.
5. Интеграция запуска тестов в CI
Тесты и их запуск — это большая отдельная тема для обсуждения. Поэтому лишь вкратце опишу хронологию их развития в проекте для общего понимания.
2017-й. Старт проекта. CI — полуручной, тесты — полностью ручные, выполняются на ПК разработчика.
Конец 2017-го. Появилась автоматическая сборка — тогда ещё на dapp (это старое название werf). Pipeline выглядит так: Build → Stage deploy → Production deploy.
Весна 2018-го. Появились:
тест-контур и возможность заливки в него БД с production по кнопке;
деплой во второй ЦОД (production, холодный резерв);
индивидуальные окружения для разработчиков.
Летом и зимой того же года добавлена интеграция с Blackfire и автоматические тесты PHPStan и Selenium.
Весна 2020-го. Добавлены CodeSniffer, юнит-тесты, canary deployments.
Текущее состояние. Ещё больше разных тестов и фич: deptrack-report, phploc, code coverage, GitLab pages (внутренняя документация), acceptance-тесты на canary, sanity-тесты на canary, тесты API.
6. Простое обновление PHP
Обновление с PHP 7.0 до 7.4 происходило безболезненно за счёт тестирования всех компонентов в отдельных изолированных окружениях с возможностью лёгкого отката.
Участие DevOps-инженеров/админов было минимальным и не требовало изменений со стороны инфраструктуры (да, пришлось поправить версии пакетов в werf.yaml). Теперь PHP обновляется полностью силами команды разработки.
Акт третий. Следуем за мечтой
За минувшее время вырос как наш опыт, так и возможности клиента. Потому мы не стоим на месте, продолжая решать новые и наболевшие нерешенные проблемы.
Главная амбициозная мечта, которая осуществилась, — мультиЦОД-решение. Оно подразумевает:
Не переключение между резервами, а одновременная работа в трёх разных дата-центрах со своими независимыми каналами, резервированием и зданиями.
Балансировщик пользовательского трафика, который распределяет пользователей на 3 дата-центра. Для части внутренних сервисов уже работает с внутренним балансировщиком и некоторой магией в виде split DNS.
Балансировщик для MySQL. А как же latency?… Ведь это три разных дата-центра. Решение этой проблемы стало возможно благодаря тесному взаимодействию коллег из «ВсехИнструментов» и из ЦОДов. У нас появилась локальная сеть между тремя независимыми зданиями трёх дата-центров, каждый из которых соединён с остальными выделенной оптикой, благодаря чему была получена отказоустойчивая локальная сеть с минимальным latency. Это было обязательным условием, позволившим нам собрать три одновременно работающих MySQL-инсталляции в кластере (Percona Xtradb Cluster) — уже настоящем, т.е. синхронном, а не реплике мастер-мастер — с балансировкой в виде ProxySQL перед ними. Синхронный кластер — это довольно «капризная» история, выдвигающая серьёзные требования к оборудованию, обеспечивающему его работу.
Балансировщик для memcache, RabbitMQ и внутренних компонентов. Общение внутренних компонентов также происходит через балансировщик, т.е. в случае отказа приложения А в первом ЦОДе из балансировки выводится только приложение А в первом ЦОДе, а приложение Б продолжает ходить в оставшиеся реплики приложения А в двух других ЦОДов. ЦОД не выводится полностью — только отказавший компонент.
Примечание: это, конечно же, не настоящее геораспределение по разным городам или континентам, так как для реализации последнего нужны совершенно другие подходы и требования к архитектуре приложения. Однако перед нами в этом проекте не стояло задачи делать подобное геораспределение — выбранные решения дают необходимый эффект при имеющейся архитектуре.
Другая большая задача — это NFS. Если точнее, то перенести всё содержимое — больше 3 ТБ статики и десятки миллионов файлов — к 2–3 независимым облачным провайдерам в современный объектное хранилище и забыть о синхронизации. (В процессе написания этой статьи работы уже были завершены.)
Заключение
Многолетняя кооперация «Фланта» и «ВсехИнструментов» представляется нам отличным примером, как сотрудничество, начавшееся с совершенно стандартного проекта средних размеров, с течением времени вырастает до крупных масштабов, принося понятную пользу обеим сторонам.
За 5 с лишним лет нашей совместной работы «ВсеИнструменты» выросли в 5 раз. В ИТ-департаменте работают 300 сотрудников, 170 из которых — разработчики. Мы с интересом наблюдали за развитием проекта и непосредственно в этом участвовали:
Инфраструктура разрослась от нескольких виртуальных машин, управляемых полностью вручную, до распределенного отказоустойчивого решения в трёх дата-центрах, использующего преимущества Kubernetes и сопровождаемого по модели IaC.
Приложение эволюционировало от простого монолита до микросервисов, соответствующих 12 факторам, готовых к масштабированию и высоким нагрузкам.
Сборка и разработка в окружении на личном компьютере, полуручной деплой были полностью автоматизированы и «обросли» многочисленными дополнениями, повышающими скорость разработки, качество кода и удобство его сопровождения.
Да, в процессе нашего совместного развития бывали ошибки, но правильные выводы из случившегося и предпринятые меры на будущее позволяют уверенно двигаться дальше, — и это замечательно! Завершая статью, хотелось бы от лица всего нашего коллектива поблагодарить коллег из «ВсехИнструментов» за все годы нашего увлекательного сотрудничества.
P.S.
Читайте также в нашем блоге:
