Нянчим проект на React-redux с пелёнок

В начале этого года мы в HeadHunter начали проект, нацеленный на автоматизацию различных HR-процессов у компаний-клиентов. Архитектурой этого проекта на фронте выбрали React-Redux стек.
За 9 месяцев он вырос из небольшого приложения для тестирования сотрудников в многомодульный проект, который сегодня называется «Оценка талантов». По мере его роста мы сталкивались с вопросами:
- хранения стейта, его нормализации;
- построения масштабируемой архитектуры проекта, удобной иерархии — как в структуре, так и в бизнес-логике.
Это проявлялось в изменении подхода к построению компонентов, архитектуры редьюсеров.
Давайте поговорим о том, как мы развивали проект и какие решения принимали. Некоторые из них могут оказаться «холиварными», а другие, напротив, «классикой» в построении большого проекта на redux. Надеюсь, что описанные ниже практики помогут вам при построении react-redux приложений, а живые примеры помогут разобраться, как работает тот или иной подход.
Общие сведения. Intro.
Веб-приложение представляет собой SPA. Рендеринг приложения только на клиенте (ниже расскажем почему). При разработке мы использовали React-redux стек с различными middlewares, например redux-thunk. В проекте используем es6, компилируемый при сборке через babel. Разработка ведется без применения es7, так как не хотим брать не принятые в стандарт решения.
Частично проект доступен на test.hh.ru, но воспользоваться им можно только компаниям, зарегистрированным на hh.
Структура проекта
В качестве структуры проекта мы изначально взяли разделение приложения на несколько частей. Получилась «классическая» структура для данного стека:
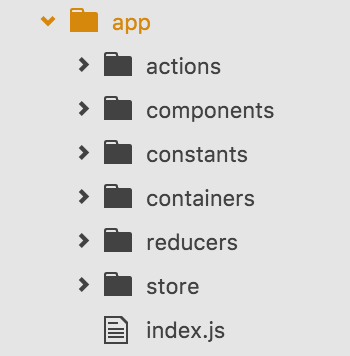
Здесь:
- actions отвечает за хранение всех action creators проекта.
- components — все react компоненты
- constants — константы. Важно, что в эту папку мы собираем не только константы наподобие
ENTER_KEY = 13, но и различные названия actions, например:export const FETCH_ACCOUNT = 'FETCH_ACCOUNT'; export const RECEIVE_ACCOUNT = 'RECEIVE_ACCOUNT';
Это сделано для того, чтобы по импортам можно было легко увидеть зависимости, без необходимости грепать строки.
Мы не выносим те константы, которые имеют значение только для конкретного компонента. Например: расстояние в пикселях от нижней границы контейнера, при достижении которого подгружаем новые данные (т. е. бесконечный скролл) - containers — специфичная директория. Состоит из страничных компонентов, которые при необходимости (например, недостатке данных) вызывают action creators и отправляют компоненты на рендеринг. Кроме подобных страничных компонентов, в папке находятся различные декораторы\фасады. Что представляет собой такой декоратор? Для этого разберем код одного из контейнеров:
import React, { Component } from 'react'; import { connect } from 'react-redux'; import { compose } from 'redux'; import Content from '../components/content/content'; import Managers from '../components/managers/managers'; import composeRestricted from './restricted/restricted'; import { loadManagers } from '../actions/managers'; import title from './title/title'; class ManagersPage extends Component { componentWillMount() { if (!this.props.firstLoad) { this.props.loadManagers(this.props.location); } } render() { return (); } } export default compose( connect( state => state.location, {loadManagers} ), title('managers', 'title.base'), composeRestricted({user: true}) )(ManagersPage);Здесь нам интересна нижняя часть, которая описывает export модуля. connect — стандартный декоратор react-redux. Он оборачивает наш компонент в дополнительный react компонент, который подписывается на изменения состояния глобального redux стора и передает location поле (плюс оборачивает action creator loadManagers в dispatch стора). Title, composeRestricted — самописные декораторы, которые аналогично оборачивают компонент. Здесь title добавляет заголовки. Второй декоратор — composeRestricted — отвечает за определение прав пользователя, отрисовку restricted страниц, если бекенд отправил соответствующую ошибку: например, нет прав или нет данных. Таких декораторов может быть большое количество: «что-то пошло не так», дополнительные вычисления и т. д.
- reducers — ничего интересного, просто управление стейтом приложения ;). Здесь же хранится «корневой» редьюсер, объединяющий все остальные (с помощью combineReducers)
- store — конфиг стора, его инициализация.
- index.js — точка входа в наше приложение. Инициализирует react, описывает роутинг, создает стор и т. п.
С такой структурой мы и начали разработку нашего проекта. Невозможно заранее предугадать все требования к системе и все сложности, с которыми можно столкнуться в процессе разработки. Поэтому мы выбрали путь инкрементальной модернизации нашего проекта. Работает это следующим образом:
- выбираем определенную модель приложения;
- сталкиваемся с тем, что какой-то подход не решает наши задачи так, как нам хочется;
- проводим рефакторинг, изменяем структуру приложения.
Разберем изменение структуры приложения с течением времени: Построение структуры. Детство
Когда проект молодой и не оброс большим количеством файлов, целесообразно выбрать простую модель построения. Именно так мы и сделали.
Все action creators хранились по принципу — одна группа операций, объединенная по смыслу = один файл. Все файлы хранились одним списком в папке.
Выглядело это следующим образом:
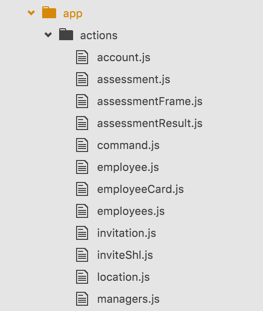
Что такое «одна группа операций»? Можно сказать, что один файл action creators отвечает за экшены внутри одного редьюсера. В таком случае и action creator и редьюсер имеют одинаковое имя, но такое бывает не в 100% случаев. По смыслу же, это операции над одним типом объектов. Например, employee.js содержит различные методы для работы с определенным объектом — «сотрудник». Это получение информации о нем, обработка ошибок загрузки данных, изменение данных и добавление нового сотрудника.
Типичный код подобных операций:
export function loadEmployee(id) {
return dispatch => {
// Генерируем action, в котором уведомляем, что начинаем асинхронную операцию с employee
dispatch(fetchEmployee());
fetch(`/employees/${id}`)
// Считываем ответ сервера
.then(checkStatus)
// Парсим
.then(result => result.json())
.then(result => {
// Генерируем экшен, который будет содержать нашего сотрудника (соответственно, далее этот сотрудник будет сохранен в редьюсер, произойдет изменение стора и рендеринг)
dispatch(receiveEmployee(result));
})
.catch(() => {
// Обработка ошибки, вызванная одной из нескольких ситуаций: 1) сервер ответил ошибкой; 2) не получилось распарсить результат; 3) ошибка при сохранении в редьюсер; 4) ошибка при рендеринге react компонент.
dispatch(releaseEmployee());
dispatch(errorRecord(t('employee.error')));
});
};
}Важно заметить, что в этом коде мы обрабатываем одним catch сразу группу ошибок — как серверных, так и работу редьюсеров и реакт-компонентов. Более подробно, почему мы решили сделать именно такую архитектуру — в разделе неоднозначных решений в конце статьи.
Аналогичная модель построения была принята для редьюсеров, контейнеров и компонентов. Для компонентов существуют только некоторые «условности». Каждый компонент находится в отдельной папке. Это позволяет нам класть внутрь папки как .js модуль, так и стили, а в некоторых случаях также и картинки\другие данные: 
Данная структура прожила ровно до окончания работы над первым модулем. Перед переходом к новому модулю мы посмотрели трезвым взглядом на полученный набор компонентов и решили, что при увеличении системы этот подход к структуре проекта принесет «кашу», где будет огромное количество файлов на одном уровне системы. Кроме того, если мы решим отдавать на фронт весь js не в одном файле (например, когда размер нашего js-бандла вырастет в мегабайты минифаенной-аглифаенной информации), а в нескольких бандлах, то нам придется довольно долго разруливать все зависимости модулей между собой.
Именно поэтому мы приняли следующее решение (опишу для двух модулей A и B, можно масштабировать на любое количество):
- Все action creators, редьюсеры и контейнеры делятся на три типа: common, moduleA, moduleB.
- Все константы, которые не описывают action type, лежат внутри папки constants. Эта же папка содержит директорию actions, в которой описываются нужные нам action types. Причем они также разделяются на два типа.
- Компоненты делятся на 4 типа:
common — включает в себя общие реакт модули. Они представляют собой dummy react component (т. е. компоненты, которые только описывают UI, не управляют им, не влияют\не зависят напрямую от стейта приложения, не вызывают actions) По сути, это реиспользуемые в любом месте приложения компоненты.
blocks — компоненты, которые зависят от общего стейта приложения. Например, блок «уведомления», или «нотификации».
moduleA, moduleB — специфичные компоненты для модуля.
И блоки, и модули могут быть smart-компонентами, вызывать какие-то actions и т. д.
С принятыми правилами структура приложения стала выглядеть следующим образом:

Таким образом, мы получили четкую структуру, описывающую модульную сущность проекта, в которой можно легко определить отношение js файла к тому или иному модулю, а значит, если мы решим создавать разные бандлы на модули, то нам это не составит никакого труда (достаточно «натравить» вебпак на нужные части).
Разделение стейта приложения на модули
Окей, мы разделили структурно наши файлы, глаз радуется, но что насчет поддержки многомодульной структуры на уровне логики, редьюсеров?
Для небольших приложений описание рутового редьюсера обычно такое:
export const createReducer = () => {
return combineReducers({
account,
location,
records,
managers,
tooltip,
validation,
progress,
restrictedData,
command,
translations,
status,
features,
module,
settings,
menu,
routing: routeReducer,
});
};Для небольших приложений это удобно, так как все данные расположены plain-коллекцией. Но с увеличением размеров приложения, увеличивается количество пересылаемых данных, появляется необходимость в дроблении редьюсеров, разделении их на модули. Как это можно сделать? Прежде чем перейти к результату, рассмотрим две ситуации.Ситуация первая: «Дробление объекта на отдельные редьюсеры»
Предположим, у нас есть сущность employees. Эта сущность отлично подойдет для разбора различных ситуаций и описания принятия решения. С сущностью «сотрудник» менеджеры компаний могут делать различные действия: загружать, редактировать, создавать, приглашать на тесты, смотреть результаты тестов. Данное поле представляет собой объект с двумя полями: status и data. status определяет текущее состояние поля (FETCH\COMPLETE\FAIL), а data — полезные данные, массив сотрудников. Этого достаточно, чтобы получить данные с сервера и отобразить список сотрудников.
Теперь нам нужно добавить возможность выбора сотрудников:
Решить такую задачу можно тремя способами:
Способ первый:Модифицируем элементы внутри массива employees.data таким образом, что кроме id, имени, фамилии, должности, каждый элемент будет содержать поле selected. При рендере чекбокса смотрим на это поле, а общую сумму считаем, например, так:
employees.data.reduce((employee, memo) => employee.selected ? memo + 1 : memo, 0);
Создаем отдельный редьюсер, например
selectedEmployees. Это иммутабельная мапа (при желании можно массив, просто объект), которая хранит только выбранные id. Добавление и удаление id из такой структуры выглядит гораздо проще. Отрисовка чекбокса усложняется только тем, что необходимо пройти по пути store.selectedEmployees.has(id). Соответственно, вся работа с выбранными сотрудниками уходит в отдельный редьюсер, отдельную группу actions.Данное решение лучше тем, что оно не занимается модификацией и нагрузкой другой части стейта, а добавляет рядом еще одно. Итого, если наше приложение состоит из этих двух редьюсеров, получим следующую структуру:
employees {state: COMPLETE, data: [{id: 1, ...}, {id: 2, ...}]}
selectedEmployees Map({1 => true})
С течением времени, если использовать второй способ каждый раз, мы получим раздувшийся стейт, который будет состоять из employees, selectedEmployees, employee, employeeTest и т. д. Заметим, что редьюсеры связаны друг с другом: selectedEmployees относится к employees, а employeeTest к employee. Поэтому структурируем приложение, создав комбинированный редьюсер. Это даст нам более четкую и удобную структуру:
employees:
- list [{id: 1, ...}, {id: 2, ...}]
- selected Map({1 => true})
- status COMPLETE
employee:
- data
- testДостигнуть такой структуры можно, построив иерархию из редьюсеров:
export const createReducer = () => {
return combineReducers({
employees: combineReducers({
list: employees,
selected: selectedEmployees,
status: employeesStatus
})
routing: routeReducer,
});
};Примечание: status не важен на этом уровне, его можно оставить внутри редьюсера, который отвечал за список сотрудников, как это было раньше.
Именно этот способ мы и решили использовать. Он отлично подходит для различных ситуаций, где необходима групповая работа с объектами.
Ситуация вторая: «Нормализация данных»При разработке SPA большую роль играет нормализация данных. Продолжим работать с нашими сотрудниками. Мы выбрали нужных сотрудников и отправили их на тест. Затем сотрудник проходит его, и компания получает результаты тестов. Нашему приложению необходимо хранить данные — результаты тестов сотрудников. У одного сотрудника может быть несколько результатов.
Подобную задачу можно также решить несколькими способами. Плохой способ (человек-оркестр)
Данный способ предлагает доработать структуру employees так, чтобы сохранять полные данные о тесте внутри себя. То есть:
employees: {
status: COMPLETE,
list: [
{
id: 1,
name: ‘Георгий’,
testResults: {
id: 123,
score: 5
speed: 146,
description: ‘...’
...
}
}
]
}Мы получили объект-оркестр в нашем сторе. Это неудобно, он несет в себе лишнюю вложенность. Намного красивее смотрится решение с нормализованными данными.
Хороший способЗаметим, что у сотрудника и теста есть id. В базе данных есть связь между тестами и сотрудниками как раз по id сотрудника. Перенимаем такой же подход с бекенда и получаем следующую структуру:
employees: {
status: COMPLETE,
list: [
{
id: 1,
name: ‘Георгий’,
testResults: [123]
}
]
},
tests: {
123: {
id: 123,
score: 5
speed: 146,
description: ‘...’
...
}
}В рутовом редьюсере получим:
export const createReducer = () => {
return combineReducers({
employees: combineReducers({
list: employees,
selected: selectedEmployees,
status: employeesStatus
}),
tests,
routing: routeReducer,
});
};Мы структурировали наш стор, разложили все по полочкам, получив четкое понимание функциональности приложения.
Добавляем модулиПри добавлении модулей разбиваем представление стейта на common группу и группы, принадлежащие разным модулям:
export const createReducer = () => {
return combineReducers({
moduleA: combineReducers({
employees: combineReducers({
list: employees,
selected: selectedEmployees,
status: employeesStatus
}),
tests,
}),
moduleB: combineReducers({...}),
// common группу расположим на первом уровне, не вкладывая отдельно
notifications,
routing: routeReducer,
});
};Данный способ позволяет в структуре стора повторить файловую структуру. Таким образом, структура приложения повторяется как на файловом, так и на логическом уровне. А значит, упрощается понимание работы всего приложения в целом и уменьшается порог вхождения новых разработчиков в проект.
Принципы построения React-компонентов
Мы успешно построили структуру приложения, разделили код на модули, наши экшены и редьюсеры иерархичны и позволяют писать масштабируемый код. Самое время вернуться к вопросу о том, как строить компоненты, отвечающие за UI.
Мы придерживаемся принципов redux, а это означает, что глобальный стор — единственный источник правды. Наша цель — строить приложение таким способом, что по данным из стора можно полностью восстановить отображение сайта в любой момент времени. Из допустимых погрешностей разрешаем себе не восстанавливать данные об анимациях\состояниях дропдаунов, тултипов — открыт\закрыт.
На основе этих условий построим модель приложения.
Хорошо описан подход к построению и разделению по данным признакам в следующих ресурсах: medium.com/@dan_abramov/smart-and-dumb-components-7ca2f9a7c7d0#.aszvx1fh1
jaketrent.com/post/smart-dumb-components-react
Мы придерживаемся аналогичного подхода. Все common-компоненты являются dummy-компонентами, которые только получают свойства и т. п. Компоненты, относящиеся к тому или иному модулю, могут быть как smart, так и dumb. Мы не вносим жесткого разграничения между ними в структуре, они хранятся рядом.
Чистые компонентыПрактически все наши компоненты не имеют собственного стейта. Такие компоненты либо получают стейт, action creators через декоратор connect, либо с помощью «водопада» от вышестоящих компонентов.
Но есть около 5% компонентов, обладающих собственным стейтом. Что такие компоненты представляют собой? Что хранят в своем стейте? Подобные компоненты в нашем приложении можно поделить на две группы.
Состояние всплывающих элементов: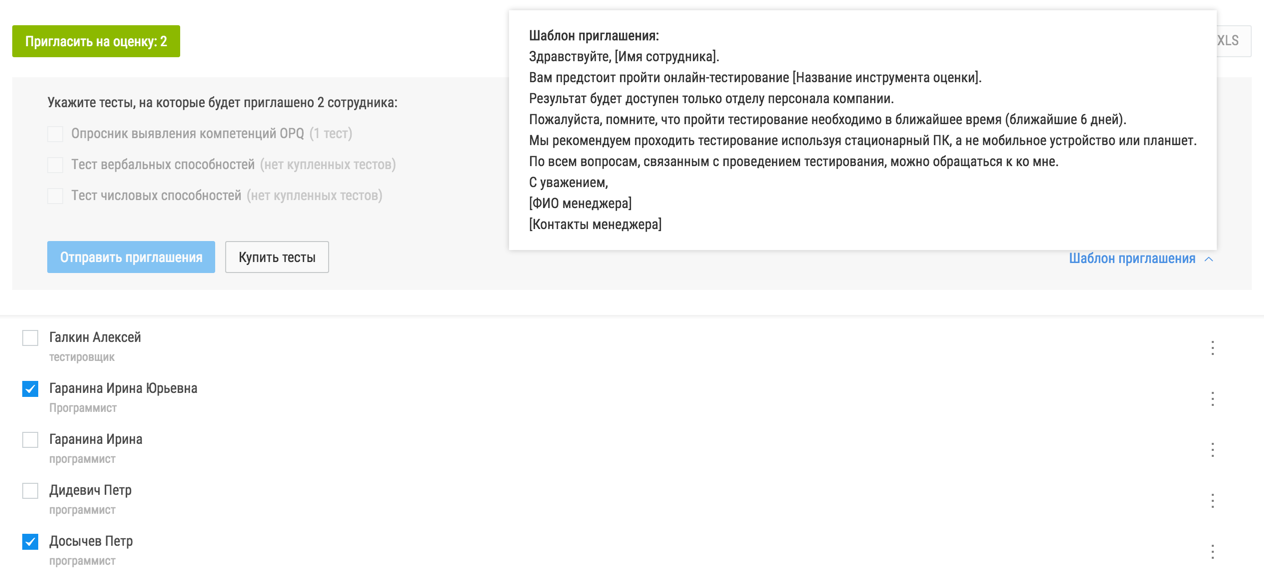
Еще один пример:

В эту группу попадают компоненты, которые хранят информацию — отображать всплывающий элемент (дропдаун, тултип) или нет.
Типичный код для такого компонента:
import React, { Component } from 'react';
import PseudoLink from '../pseudoLink/pseudoLink';
import Dropdown from '../../common/dropdown/dropdown';
import './dropdownHint-styles.less';
class DropdownHint extends Component {
constructor(props, context) {
super(props, context);
this.state = {
dropdown: false,
};
}
renderDropdown() {
if (!this.state.dropdown) {
return '';
}
return (
{
this.setState({
dropdown: false,
});
}}>
{this.props.children}
);
}
render() {
return (
{
this.setState({
dropdown: true,
});
}}>
{this.renderDropdown()}
{this.props.text}
);
}
}
export default DropdownHint;Рассмотрим следующий пример: 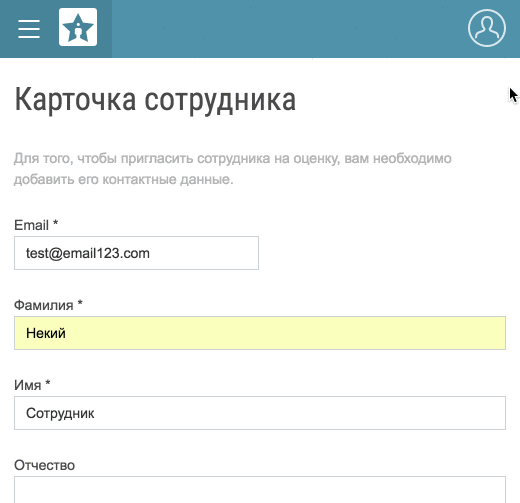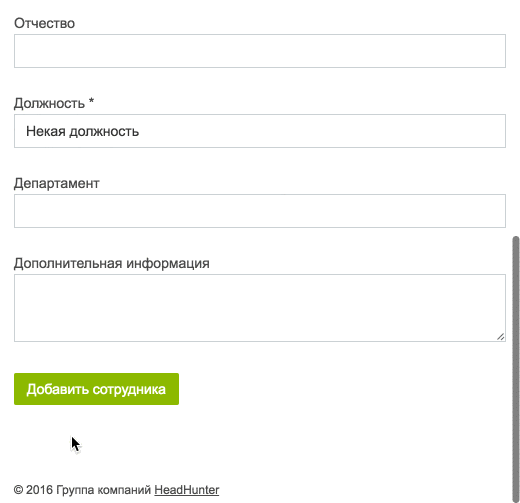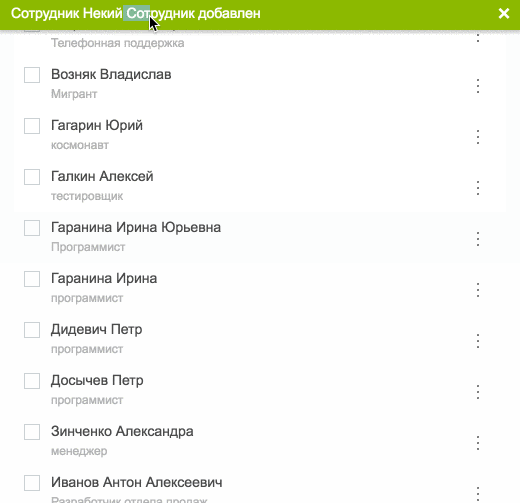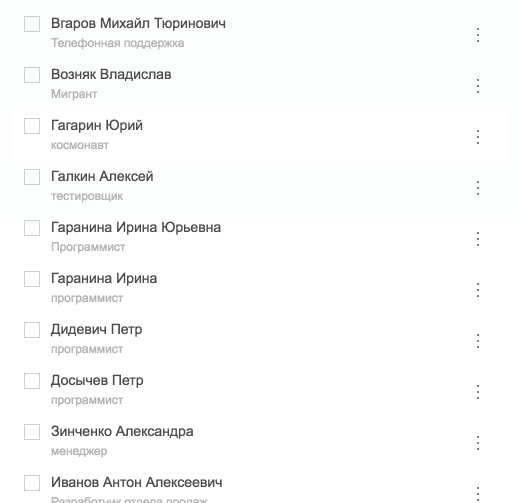
Нотификации наверху экрана анимируются при появлении и скрытии. Сама сущность нотификации хранится в глобальном стейте приложения, но для процесса скрытия (с последующим удалением) нотификации можно использовать один из нескольких подходов, не загрязняя глобальный стейт такой неважной информацией, как анимация.
Способ первый — кеширование.
Достаточно простой способ. Создаем компонент NotificationsManager, который отвечает за рендеринг компонентов-нотификаций (Notification). После того как NotificationsManager отрендерил очередную нотификацию, он запускает таймер, по окончании которого будет вызван экшен по скрытию нотификации. Перед его вызовом NotificationsManager кеширует нотификацию в своем стейте. Это позволяет удалить саму нотификацию из стора, а закешированные данные внутри локального стейта компонента позволяют провести анимацию ее исчезновения.
Этот способ неудобен тем, что мы обманываем наш стор — он считает, что нотификации никакой нет, но она на самом деле хранится в локальном стейте нашего компонента. Мы хотим «честный» стор, поэтому данный способ нам не подходит.
Способ второй — дополняем информацию из стора локально.
Этот способ более честный и привлекательный, так как не мешает с высокой точностью восстановить данные из стора. Заключается он в том, чтобы NotificationsManager при получении изменений нотификаций со стороны стора добавлял информацию в свой стейт о том, что необходимо делать с нотификацией (анимировать ее появление, исчезновение или ничего не делать). В таком случае NotificationManager уведомляет стор через экшен CLOSE_NOTIFICATION только в момент, когда анимация исчезновения нотификации закончена. Этот подход позволяет отказаться от лишней информации в сторе (статус анимирования нотификации), и в то же время стор остается «единственным источником правды», с помощью которого можно точно восстановить отображение всего приложения.
Опишем приближенно, каким образом будет работать такой подход.
В сторе получаем:
notifications: [
{
id: 1,
text: ‘Я мистер мисикс, посмотрите на меня’
},
{
id: 2,
text: ‘Двое из ларца, одинаковых с лица’
},
{
id: 3,
text: ‘Что тебе надобно, старче?’
},
]В локальном стейте компонента:
notifications: {
1: ‘out’,
3: ‘in’
}Разберем пример. На уровне всего приложения мы знаем, что у нас существует 3 нотификации. На локальном уровне компонента мы сохраняем информацию, которая не несет смысловой нагрузки для приложения, но важна для локального рендера: id === 1 исчезает, id == 3 выезжает, а id === 2 статична.
Эту информацию можно хранить в сторе, но она не несет никакой полезной смысловой нагрузки. Не нужна никаким компонентам, кроме как самим нотификациям. Даже при восстановлении состояния всего приложения из стора такая информация не нужна и может быть вредна в конкретно этом случае. Кто захочет открыть приложение и увидеть как «что-то резко скрылось».
Мы взяли на вооружение второй способ. В каждом случае с анимациями важно понимать, насколько оправданно заводить локальный стейт, нужен ли он, можно ли обойтись без стейтов вообще и т. д. Например, у нас во всем приложении этот способ применен только в нотификациях. В сторе мы не храним информацию об анимации.
Роутинг пользователя. Рендеринг
В роутинге пользователя у нас нет ничего сверхестественного. За роутинг отвечает стандартный компонент react-router, с redux мы связываем роутинг через react-router-redux.
Рендеринг нашего приложения происходит только на клиенте.
При первой загрузке страницы сервер отдает нам только стаб, в который для начальной инициализации кладет все данные в формате json, которые нам необходимы для отрисовки страницы: информацию об аккаунте, данные для страницы, описание ошибки (если есть). Затем уже клиентский код рендерит наше приложение.
Данный шаг был сделан по нескольким причинам:
- Без отработавшего js кода приложение бессмысленно;
- Нет необходимости поддержки рендеринга компонентов как на сервере, так и на клиенте;
- Отсутствие node.js на сервере.
После первоначальной загрузки приложения все запросы работают через json-формат. Типы получаемых данных описываем обычным acceptType-хидером.
Рассмотрим пример такой работы: 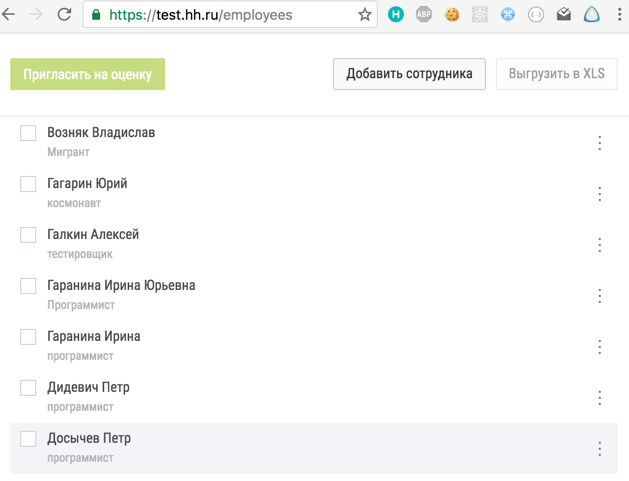
Для рендеринга страницы employees нам нужна информация о сотрудниках (employees) и об аккаунте пользователя (account).
Если пользователь вводит в браузере урл этой страницы, то сервер отдаст html-код, содержащий следующий json:
window.pageData = {
account: // информация об аккаунте
employees: // информация о сотрудниках
}Все редьюсеры, которые ожидают начальный стейт, умеют собирать нужные данные из этого объекта при инициализации.
Приведем схематический пример такой инициализации:
const initialData = window.pageData.employees;
export default function employees(state = initialData, actions) {
// reducer
}В реальной жизни поля employees может не оказаться, поэтому мы получаем данные немного по-другому, но суть остается та же.
Следующий случай — на страницу заходят во время работы с приложением. В этом случае страничный контейнер вызовет соответствующий action creator, который пойдет на сервер с acceptType: application/json и получит только необходимые данные (массив сотрудников). Затем отработает редьюсер. «И все будут жить долго и счастливо».
Неоднозначные решения
Единое место обработки ошибок
В самом начале статьи мы затрагивали код одного из action creator«ов:
export function loadEmployee(id) {
return dispatch => {
// генерируем action, в котором уведомляем, что начинаем асинхронную операцию с employee
dispatch(fetchEmployee());
fetch(`/employees/${id}`)
// считываем ответ сервера
.then(checkStatus)
// парсим
.then(result => result.json())
.then(result => {
// генерируем экшен, который будет содержать нашего сотрудника (соответственно, далее этот сотрудник будет сохранен в редьюсер, произойдет изменение стора и рендеринг)
dispatch(receiveEmployee(result));
})
.catch(() => {
dispatch(releaseEmployee());
dispatch(errorRecord(t('employee.error')));
});
};
}После получения данных с сервера мы диспатчим receiveEmployee. Соответственно, далее сотрудник будет сохранен редьюсером в стор, состояние стора изменится, произойдет рендеринг. Эти действия выполняются синхронно. Здесь может скрываться подводный камень — catch отловит следующие категории ошибок:
- сервер ответил ошибкой;
- не получилось распарсить результат;
- ошибка при сохранении в редьюсер;
- ошибка при рендеринге react компонент.
Это происходит из-за «синхронности» кода. Таким образом, если мы упали на моменте рендеринга реакт компонентов, то пользователь увидит сообщение t ('employee.error'). t — функция, которая по ключу подставит текст (перевод).
Мы получили «централизованное» место сбора ошибок. Такое решение нам подходит, так как мы намеренно хотим сообщить пользователю о том, что не получилось загрузить сотрудника, отобразить данные и т. п. Конечному пользователю все равно, где произошла ошибка: на стороне сервера или клиентской логики. В любом случае запрошенные данные он не увидит. Даже если бы мы разграничивали код, например так:
export function loadEmployee(id) {
return async dispatch => {
// генерируем action, в котором уведомляем, что начинаем асинхронную операцию с employee
dispatch(fetchEmployee());
let json;
try {
const res = await fetch(`/employees/${id}`);
checkStatus(res);
json = await getJson(res);
} catch () {
dispatch(releaseEmployee());
dispatch(errorRecord(t('employee.error')));
}
dispatch(receiveEmployee(result));
};
}То нам бы пришлось обернуть в try-catch последний dispatch:
dispatch (receiveEmployee (result));
и сделать в нем то же самое, что и в предыдущем блок catch:
export function loadEmployee(id) {
return async dispatch => {
// генерируем action, в котором уведомляем, что начинаем асинхронную операцию с employee
dispatch(fetchEmployee());
let json;
try {
const res = await fetch(`/employees/${id}`);
checkStatus(res);
json = await getJson(res);
} catch () {
dispatch(releaseEmployee());
dispatch(errorRecord(t('employee.error')));
}
try {
dispatch(receiveEmployee(result));
} catch() {
dispatch(releaseEmployee());
dispatch(errorRecord(t('employee.error')));
}
};
} В итоге мы получили лишнее дублирование кода, не выиграв в конкретно этом случае ничего.
Важно понимать, что при таком подходе нужно разграничивать те случаи, когда централизованная обработка допустима, и те случаи, когда этого стоит избегать.
Динамические редьюсерыПри увеличении количества редьюсеров, разделении их на разные модули и построении иерархической структуры, появляется необходимость избавляться от лишних данных, которые «не используются». В многомодульном приложении (например, когда у нас 5—10 модулей, в каждом из которых 40—50 редьюсеров) появляется закономерное желание хранить в сторе данные только о выбранном модуле и общие редьюсеры. Зачем так делать? Когда пользователь работает с тем или иным модулем, он с высокой долей вероятности не будет работать с другими модулями. Визуально разные модули отличаются в оформлении, цветовой палитре. Это сделано для того, чтобы пользователь «одним взглядом» понимал, в каком контексте он находится. Соответственно, если пользователь находится в одном модуле, то состояние стора для других модулей, во-первых, не важно, во-вторых, инвалидно (пусто, так как при переходе в другой модуль все данные будут перезагружены с сервера, обновлены). А также, если мы хотим полностью восстановить состояние приложения из стора, нам достаточно содержимого общих полей стора и содержимого полей активного модуля. Остальные модули нам не нужны. Руководствуясь этими принципами, мы решили воспользоваться динамической подменой редьюсеров.
В основе данного решения лежит информация из следующих источников:
github.com/reactjs/redux/issues/37#issue-85098222
gist.github.com/gaearon/0a2213881b5d53973514
stackoverflow.com/questions/34095804/replacereducer-causing-unexpected-key-error
Работает это следующим образом:
Шаг 1.
Создадим редьюсер, описывающий текущий модуль. Такой редьюсер отвечает за информацию, в каком модуле находится пользователь. Этот же редьюсер можем использовать для отрисовки меню (как пример).
Шаг 2.
Все наши модульные редьюсеры находятся внутри отдельного редьюсера. То есть до введения динамического переключения они выглядят следующим образом:
export const createReducer = () => {
return combineReducers({
moduleA: combineReducers({
employee: combineReducers({
list: employees,
selected: selectedEmployees,
status: employeesStatus
}),
tests,
}),
moduleB: combineReducers({...}),
// common группу расположим на первом уровне, не вкладывая отдельно
notifications,
routing: routeReducer,
});
}Теперь создаем возможность динамического добавления редьюсеров:
export const createReducer = (dynamicReducers = {}) => {
return combineReducers(Object.assign({}, {
notifications,
routing: routeReducer,
// редьюсер, описывающий выбранный модуль
module,
}, dynamicReducers));
};и описываем в файле редьюсеры, которые относятся к модулям:
export const aReducers = {
moduleA: combineReducers({
employee: combineReducers({
list: employees,
selected: selectedEmployees,
status: employeesStatus
}),
tests,
}),
}Шаг 3.
Немного изменяем код конфигурации стора для того, чтобы можно было добавлять динамические редьюсеры:
export function configureStore() {
const store = createStoreWithMiddleware(createReducer());
store.dynamicReducers = {};
storeInstance = store;
switch (store.getState().module) {
case A:
injectAsyncReducer(aReducers);
break
case B:
injectAsyncReducer(bReducers);
break;
// Аналогично далее
}
return store;
}
export function injectAsyncReducer(reducers) {
if (reducers !== storeInstance.dynamicReducers) {
storeInstance.dynamicReducers = reducers;
storeInstance.replaceReducer(createReducer(storeInstance.dynamicReducers));
}
}Мы получаем функцию injectAsyncReducer, с помощью которой в рантайме можем изменять редьюсеры.
Шаг 4.
Создаем необходимый action creator. С его помощью создаем action для смены выбранного модуля. Например такой:
export const checkoutAModule = () => {
// Заменяем набор редьюсеров
injectAsyncReducer(aReducers);
return {
type: CHECKOUT_MODULE,
module: A,
};
};Аналогично действуем для остальных модулей, либо создаем один, но дженерный.
Шаг 5.
Добавляем декоратор, который отвечает за переключение модуля. Он выглядит примерно так:
import React, { Component } from 'react';
import { connect } from 'react-redux';
import { checkoutModuleA } from '../../actions/module';
import { A } from '../../constants/module';
export default function checkoutA() {
return Container => {
class AContainer extends Component {
componentWillMount() {
if (this.props.module !== A) {
this.props.checkoutModuleA();
}
}
render() {
return (
Соответственно, так как модулей много, этот код легко можно сделать дженерным.
Шаг 6.
Добавляем этот декоратор для наших страничных контейнеров:
import React, { Component } from 'react';
import { connect } from 'react-redux';
import { compose } from 'redux';
import Content from '../components/content/content';
import Managers from '../components/managers/managers';
import composeRestricted from './restricted/restricted';
import { loadManagers } from '../actions/managers';
import title from './title/title';
class ManagersPage extends Component {
componentWillMount() {
if (!this.props.firstLoad) {
this.props.loadManagers(this.props.location);
}
}
render() {
return (
);
}
}
export default compose(
connect(
state => state.location,
{loadManagers}
),
checkoutA(),
title('managers', 'title.base'),
composeRestricted({user: true})
)(ManagersPage);Готово! Теперь мы обучили наше приложение изменять набор редьюсеров. Важно, что без острой необходимости данным способом пользоваться нежелательно. Это объясняется тем, что мы «обрубаем» часть стора. Такой подход является оправданным только для больших систем с похожей структурой (модульные, независимые части, объединенные одним проектом).
Вместо вывода
С текущей архитектурой проект продолжает развиваться. Многие вопросы остались за рамками данной статьи, которая вышла и без того внушительной. Мы успели затронуть вопросы, связанные с построением структуры как на файловом, так и на логическом уровне, разделения и нормирования стейта приложения, хранения локального стейта в компонентах. Проделанная работа, при некотором усложнении проекта (увеличении количества модулей), позволила нам не сделать его запутанным и помогла уменьшить порог вхождения в него новых разработчиков.
Комментарии (5)
 yury-dymov
yury-dymov
21 сентября 2016 в 10:46
+1↑
↓
Очень хорошая статья, по ходу чтения появилось несколько вопросов:
1) А backend данные тоже отдает «нормализированными»? Могли бы вы привести пример данных, которые сервис возвращает SPA
2) Смотрели ли вы в сторону Relay или других подобных решений? Что о них думаете?
3) Разработка с redux требует написания большого количества подобного кода. Используете ли какие-нибудь инструменты, которые упрощают жизнь?Я в своем относительно крупном проекте пришел к очень похожему способу использования редукса, как описано у вас.
 xnim
xnim
21 сентября 2016 в 11:02
+1↑
↓
Спасибо!1) А backend данные тоже отдает «нормализированными»? Могли бы вы привести пример данных, которые сервис возвращает SPA
В hh с бекендом у нас отличные отношения, что позволяет нам для разработки договариваться о нужном формате, который устроит всех. Соответственно при необходимости бекен
