Нагрузочное тестирование игры с парой сотен тысяч виртуальных пользователей
Привет, Хабр!
Я работаю в игровой компании, которая разрабатывает онлайн-игры. На текущий момент все наши игры делятся на множество «маркетов» (один «маркет» на страну) и в каждом «маркете» есть дюжина миров, между которыми распределяются игроки при регистрации (ну или иногда они могут выбрать его сами). Каждый мир имеет одну базу данных и один или несколько web/app-серверов. Таким образом, нагрузка делится и распределяется по мирам/серверам почти равномерно и в итоге мы получаем максимальный онлайн в 6K-8K игроков (это максимум, в основном в разы меньше) и 200–300 запросов в «прайм»-тайм на один мир.
Такая структура с делением игроков по маркетам и мирам изживает себя, игрокам хочется чего-то глобального. В последних играх мы перестаём делить людей по странам и оставили только один/два маркета (Америка и Европа), но до сих пор со множеством миров в каждом. Следующим этапом будет разработка игр с новой архитектурой и объединением всех игроков в одном единственном мире с одной базой данных.
Сегодня я хотел немного рассказать о том, как мне была поставлена задача проверить, а что если весь онлайн (а это 50–200 тысяч пользователей одновременно) одной из наших популярных игр «отправить» играть в следующую игру, построенною на новой архитектуре и сможет ли вся система, в особенности база данных (PostgreSQL 11) практически выдержать такую нагрузку и, если не сможет, узнать, где же наш максимум. Расскажу немного о возникших проблемах и решениях подготовки к тестированию такого количества пользователей, самом процессе и немного о результатах.
Intro
В прошлом, в InnoGames GmbH каждая игровая команда создавала игровой проект на свой вкус и цвет, используя зачастую разные технологии, языки программирования и базы данных. В довесок, у нас есть множество внешних систем, ответственных за платежи, отправки push — нотификаций, маркетинг и прочее. Для работы с этими системами разработчики также создавали свои уникальные интерфейсы кто как мог.
В текущее время в мобильном игровом бизнесе огромные деньги и, соответственно, огромная конкуренция. Здесь очень важно с каждого потраченного доллара на маркетинг получить его назад и ещё чуть-чуть сверху, поэтому все игровые компании очень часто «закрывают» игры ещё на этапе закрытого тестирования, если они не оправдают аналитических ожиданий. Соответственно, терять время на изобретение очередного колеса невыгодно, поэтому было принято решение создать унифицированную платформу, которая будет предоставлять разработчикам уже готовое решение для интеграции со всеми внешними системами, базой данных с репликацией и всеми best-practices. Всё что, нужно разработчикам — это разработать и «наложить» поверх этого хорошую игру и не терять время на не относящееся к самой игре разработке.
Называется эта платформа GameStarter:

Так вот, к сути дела. Все будущие игры InnoGames будут построены на этой платформе, которая имеет две базы данных — master и game (PostgreSQL 11). Master хранит базовую информацию о игроках (login, пароль и прочее) и участвует, в основном, только в процессе логина/регистрации в саму игру. Game — база данных самой игры, где хранятся, соответственно, все игровые данные и сущности, которая и является ядром игры, куда и пойдет вся нагрузка.
Таким образом, встал вопрос сможет ли вся эта конструкция выдержать такое потенциальное количество пользователей, равное максимальному онлайну одной из наших самых популярных игр.
Задача
Сама задача звучала так: проверить, сможет ли база данных (PostgreSQL 11), с включенной репликацией, выдержать всю нагрузку, которую мы имеем на данный момент в самой нагруженной игре, имея в своём распоряжении весь гипервизор (HV) PowerEdge M630.
Уточню, что задача стояла на данный момент только проверить, с использованием уже имеющихся конфигов базы данных, которые мы сформировали с учетом best-practices и собственного опыта.
Скажу сразу база данных, да и вся система показала себя хорошо, за исключением пары моментов. Но данный конкретный игровой проект находился на стадии прототипа и в будущем с усложнением игровых механик, усложнятся и запросы в базу и сама нагрузка может значительно возрасти и её характер может изменится. Чтобы не допустить такого, необходимо итеративно тестировать проект при каждом более-менее значимом milestone. Автоматизация возможности запуска такого рода тестов с парой сотен тысяч пользователей стала основной задачей на данном этапе.
Профиль
Как и любое нагрузочное тестирование, начинается всё с составления профиля нагрузки.
Наше потенциальное значение CCU60 (CCU — максимальное количество пользователей за определенный период времени, в данном случае — 60 мин.) принято равным 250000 пользователей. Число конкурентных виртуальных пользователей (VU) ниже, чем CCU60 и аналитики подсказали, что можно смело делить на два. Округлим и примем 150000 конкурентных VU.
Общее количество запросов в секунду взяли из одной довольно нагруженной игры:
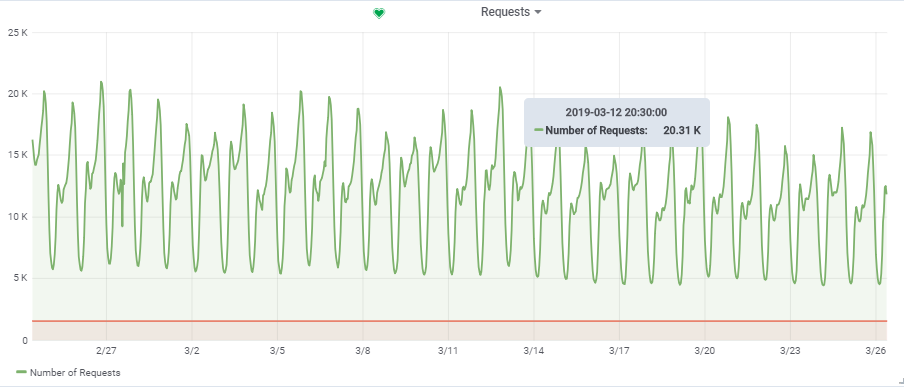
Таким образом, наша целевая нагрузка ~ 20000 запросов/с при 150000 VU.
Структура
Характеристики «стенда»
В прошлой статье я уже рассказывал об автоматизации всего процесса нагрузочного тестирования. Далее я может немного повторюсь, но некоторые моменты расскажу более детально.

На схеме, синие квадраты — это наши гиперизоры (HV), облако, состоящее из множества серверов (Dell M620 — M640). На каждом HV запущено посредством KVM с десяток виртуальных машин (VM) (web/app и db в перемешку). При создании любой новой VM происходит балансировка и поиск по множеству параметров подходящего HV и изначально неизвестно на каком сервере она окажется.
База данных (Game DB):
Но для нашей цели db1 мы зарезервировали отдельный HV targer_hypervisor на базе M630.
Краткие характеристики targer_hypervisor:
Dell M_630
Model name: Intel® Xeon® CPU E5–2680 v3 @ 2.50GHz
CPU (s): 48
Thread (s) per core: 2
Core (s) per socket: 12
Socket (s): 2
RAM: 128 GB
Debian GNU/Linux 9 (stretch)
4.9.0–8-amd64 #1 SMP Debian 4.9.130–2 (2018–10–27)
4.9.0–8-amd64 #1 SMP Debian 4.9.130–2 (2018–10–27)
lscpu
Architecture: x86_64
CPU op-mode (s): 32-bit, 64-bit
Byte Order: Little Endian
CPU (s): 48
On-line CPU (s) list: 0–47
Thread (s) per core: 2
Core (s) per socket: 12
Socket (s): 2
NUMA node (s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Model name: Intel® Xeon® CPU E5–2680 v3 @ 2.50GHz
Stepping: 2
CPU MHz: 1309.356
CPU max MHz: 3300.0000
CPU min MHz: 1200.0000
BogoMIPS: 4988.42
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 30720K
NUMA node0 CPU (s): 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38,40,42,44,46
NUMA node1 CPU (s): 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39,41,43,45,47
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2×2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm epb invpcid_single ssbd ibrs ibpb stibp kaiser tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm xsaveopt cqm_llc cqm_occup_llc dtherm ida arat pln pts flush_l1d
/usr/bin/qemu-system-x86_64 --version
QEMU emulator version 2.8.1(Debian 1:2.8+dfsg-6+deb9u5)
Copyright © 2003–2016 Fabrice Bellard and the QEMU Project developers
Краткие характеристики db1:
Architecture: x86_64
CPU (s): 48
RAM: 64 GB
4.9.0–8-amd64 #1 SMP Debian 4.9.144–3.1 (2019–02–19) x86_64 GNU/Linux
Debian GNU/Linux 9 (stretch)
psql (PostgreSQL) 11.2 (Debian 11.2–1.pgdg90+1)
seq_page_cost = 1.0
random_page_cost = 1.1 # У нас SSD
include '/etc/postgresql/11/main/extension.conf'
log_line_prefix = '%t [%p-%l] %q%u@%h '
log_checkpoints = on
log_lock_waits = on
log_statement = ddl
log_min_duration_statement = 100
log_temp_files = 0
autovacuum_max_workers = 5
autovacuum_naptime = 10s
autovacuum_vacuum_cost_delay = 20ms
vacuum_cost_limit = 2000
maintenance_work_mem = 128MB
synchronous_commit = off
checkpoint_timeout = 30min
listen_addresses = '*'
work_mem = 32MB
effective_cache_size = 26214MB # 50% от доступной памяти
shared_buffers = 16384MB # 25% от доступной памяти
max_wal_size = 15GB
min_wal_size = 80MB
wal_level = hot_standby
max_wal_senders = 10
wal_compression = on
archive_mode = on
archive_command = '/bin/true'
archive_timeout = 1800
hot_standby = on
wal_log_hints = on
hot_standby_feedback = on
hot_standby_feedback по умолчанию стоит в off, у нас был включен, но в последствии для проведения успешного теста пришлось выключить. Поясню позже почему.
Основное активные таблицы в базе (construction, production, game_entity, building, core_inventory_player_resource, survivor) предварительно заполнены данными (примерно 80GB), при помощи bash-скрипта.
#!/bin/bash
--clean
TRUNCATE TABLE production CASCADE;
TRUNCATE TABLE construction CASCADE;
TRUNCATE TABLE building CASCADE;
TRUNCATE TABLE grid CASCADE;
TRUNCATE TABLE core_inventory_player_resource CASCADE;
TRUNCATE TABLE survivor CASCADE;
TRUNCATE TABLE city CASCADE;
TRUNCATE TABLE game_entity CASCADE;
TRUNCATE TABLE player CASCADE;
TRUNCATE TABLE core_player CASCADE;
TRUNCATE TABLE core_client_device CASCADE;
--core_client_device
INSERT INTO core_client_device (id, creation_date, modification_date, device_model, device_name, locale, platform, user_agent, os_type, os_version, network_type, device_type) SELECT (1000000000+generate_series(0,999999)) AS id, now(), now(), 'device model', 'device name', 'en_DK', 'ios', 'ios user agent', 'android', '8.1', 'wlan', 'browser';
--core_player
INSERT INTO core_player (id, guest, name, nickname, premium_points, soft_deleted, session_id, tracking_device_data_id) SELECT (1000000000+generate_series(0,999999)) AS id, true, 'guest0000000000000000000', null, 100, false, '00000000-0000-0000-0000-000000000000', (1000000000+generate_series(0,999999)) ;
--player
INSERT INTO player (id, creation_date, modification_date, core_player_id) SELECT (1000000000+generate_series(0,999999)) , now(), now(), (1000000000+generate_series(0,999999)) ;
--city
INSERT INTO game_entity (id, type, creation_date, modification_date) SELECT (1000000000+generate_series(0,999999)) , 'city', now(), now();
INSERT INTO city (id, game_design, player_id) SELECT (1000000000+generate_series(0,999999)) , 'city.default', (1000000000+generate_series(0,999999)) ;
--survivor
INSERT INTO game_entity (id, type, creation_date, modification_date) SELECT (1001000000+generate_series(0,999999)) , 'survivor', now(), now();
INSERT INTO survivor (id, game_design, owning_entity_id, type) SELECT (1001000000+generate_series(0,999999)) , 'survivor.prod_1', (1000000000+generate_series(0,999999)) , 'survivor';
--core_inventory_player_resource
INSERT INTO core_inventory_player_resource (id, creation_date, modification_date, amount, player_id, resource_key) SELECT (1000000000+generate_series(0,1999999)) , NOW(), NOW(), 1000, (1000000000+generate_series(0,1999999)/2) , CONCAT('resource_', (1000000000+generate_series(0,1999999)) % 2);
--grid
DROP INDEX grid_area_idx;
INSERT INTO grid (id, creation_date, modification_date, area, city_id) SELECT (1000000000+generate_series(0,19999999)) , NOW(), NOW(), BOX '0,0,4,4', (1000000000+generate_series(0,19999999)/20) ;
create index on grid using gist (area box_ops);
--building
INSERT INTO game_entity (id, type, creation_date, modification_date) SELECT (1002000000+generate_series(0,99999999)) , 'building', now(), now();
INSERT INTO building (id, game_design, owning_entity_id, x, y, rotation, type) SELECT (1002000000+generate_series(0,99999999)) , 'building.building_prod_1', (1000000000+generate_series(0,99999999)/100) , 0, 0, 'DEGREES_0', 'building';
--construction
INSERT INTO construction (id, creation_date, modification_date, definition, entity_id, start) SELECT (1000000000+generate_series(0,1999999)) , NOW(), NOW(), 'construction.building_prod_1-construction', (1002000000+generate_series(0,1999999)*50) , NOW();
--production
INSERT INTO production (id, creation_date, modification_date, active, definition, entity_id, start_time) SELECT (1000000000+generate_series(0,49999999)) , NOW(), NOW(), true, 'production.building_prod_1_production_1', (1002000000+generate_series(0,49999999)*2) , NOW();
Репликация:
SELECT * FROM pg_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state
-----+----------+---------+---------------------+--------------+---------------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------------+-----------------+-----------------+---------------+------------
759 | 17035 | repmgr | xl1db2 | xxxx | xl1db2 | 51142 | 2019-01-27 08:56:44.581758+00 | | streaming | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 00:00:00.000393 | 00:00:00.001159 | 00:00:00.001313 | 0 | async
977 | 17035 | repmgr | xl1db3 |xxxxx | xl1db3 | 42888 | 2019-01-27 08:57:03.232969+00 | | streaming | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 00:00:00.000373 | 00:00:00.000798 | 00:00:00.000919 | 0 | async
Сервера приложений
Далее на продуктивных HV (prod_hypervisors) различной конфигурации и мощностей запущено 15 app серверов: 8 cores, 4GB. Основное что можно сказать: openjdk 11.0.1 2018–10–16, spring, взаимодействие с базой данных через hikari (hikari.maximum-pool-size: 50)
Среда нагрузочного тестирования
Вся среда нагрузочного тестирования состоит из одного главного сервера admin.loadtest, и нескольких generatorN.loadtest серверов (в данном случае их было 14).
generatorN.loadtest — «голые» VM Debian Linux 9, с установленной Java 8. 32 ядра/32 гига. Находятся на «непродуктовых» HV, чтобы не убить случайно производительность важных VM.
admin.loadtest — виртуалка Debian Linux 9, 16 ядер/16 гигов, на нём работают Jenkins, JLTC и другой дополнительный маловажный софт.
JLTC — jmeter load test center. Система на Py/Django, которая контролирует и автоматизирует запуск тестов, а также анализ результатов.
Схема запуска теста

Сам процесс запуска теста выглядит так:
- Тест запускается из Jenkins. Выбираем необходимый Job, далее необходимо ввести желаемые параметры теста:
- DURATION — длительность теста
- RAMPUP — время «разогрева»
- THREAD_COUNT_TOTAL — желаемое количество виртуальных пользователей (VU) или тредов
- TARGET_RESPONSE_TIME — важный параметр, чтобы не перегрузить всю систему с помощью него мы задаём желаемое время отклика, соответственно тест будет держать нагрузку на уровне, при котором время отклика всей системы не больше, чем заданный.
- Запуск
- Jenkins клонирует тестплан из Gitlab, отправляет его в JLTC.
- JLTC немного работает с тест-планом (например, вставляет CSV simple writer).
- JLTC вычисляет необходимое количество Jmeter-серверов для запуска желаемого количества VU (THREAD_COUNT_TOTAL).
- JLTC подключается к каждому генератору loadgeneratorN и запускает jmeter-сервера.
В процессе теста JMeter-client генерирует CSV-файл с результатами. Так в течение теста количество данных и размер этого этого файла растет сумасшедшими темпами, и его невозможно использовать для анализа после теста — был (в качестве эксперимента) придуман Daemon, который парсит его «на лету».
Тест-план
Сам тест-план вы можете скачать здесь.
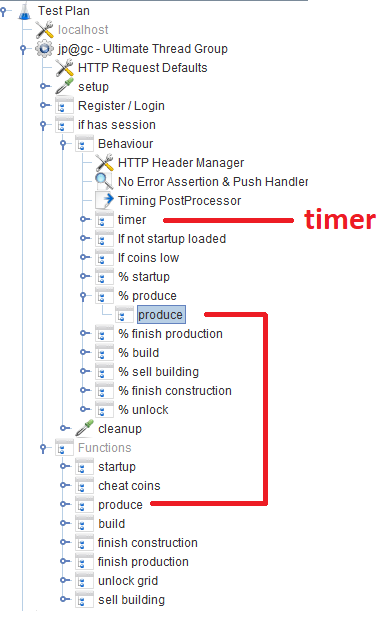
После регистрации/логина, пользователи работают в модуле Behavior, состоящем из нескольких Throughput controller`ов, задающих вероятность выполнения той или иной игровой функции. В каждом Throughput controller`е находится Module controller, который ссылается на соответствующий модуль, реализующий функцию.
Off-topic
В ходе разработки скрипта мы старались использовать Groovy по-полной и благодаря нашему Java-программисту я открыл для себя пару трюков (может кому полезно будет):
- Можно где-нибудь в начале тест-плана объявить функцию, и потом использовать её в других pre-, post- процессорах и сэмлерах. Подробнее Groovy Goodness: Turn Methods into Closures:
// Объявляем метод в начале тест-плана def sum(Integer x, Integer y) { return x + y } vars.putObject(‘sum’, this.&sum) // я не знаю как перевести closure. Может кто подскажет. // Теперь в любом другом sampler`е достаём метод и работаем с ним def sum= vars.getObject(‘sum’); println sum(2, 2); - groovy.json.JsonSlurper — прекрасный быстрый JSON-парсер. Совместно с groovy позволяет элегантно парсить данные и обрабатывать их:
import groovy.json.JsonSlurper def canBuild = vars.getObject(canBuild); // "Достаём" заранее подготовленную функцию для условной проверки def content = jsonSlurper.parseText(response).content def buildings = content[0].buildings // Берем массив с информацией о зданиях из респонса // Далее элегантно проходимся по зданиям и вызываем вышеуказанную функцию для проверки возможности постройки здания def constructableBuildingDefs = buildings .collect { k,v -> v } .grep{ it.definitions .grep { it2 -> it2['@type'] == 'type.googleapis.com/ConstructionDefinitionDTO'} .grep { it2 -> canBuild(it2) } // Здесь проверка .size() > 0 } if (!constructableBuildingDefs) { return; } Collections.shuffle(constructableBuildingDefs) // Берем рандомное из отобранных зданий и строим
VU/Threads
Когда пользователь вводит желаемое количество VU при помощи параметра THREAD_COUNT_TOTAL при конфигурации джоба в Jenkins, необходимо каким-то образом запустить необходимое количество Jmeter-серверов и распределить конечное количество VU между ними. Эта часть лежит на JLTC в части, называемой controller/provision.
По сути алгоритм такой:
- Делим желаемое количество VU threads_num на 200–300 тредов и исходя из более менее адекватного размера -Xmsm -Xmxm определяем необходимое значение памяти на один jmeter-сервер required_memory_for_jri (JRI — я называю Jmeter remote instance, вместо Jmeter-server).
- Из threads_num и required_memory_for_jri находим суммарное количество jmeter-server: target_amount_jri и суммарное значение необходимой памяти: required_memory_total.
- Перебираем все генераторы loadgeneratorN один за одним и запускаем максимальное количество jmeter-серверов исходя из доступной памяти на нём. До тех пор пока число запущенных инстансов current_amount_jri не равно target_amount_jri.
- (Если количество генераторов и общей памяти не достаточно, добавляем в пул новый)
- Подключаемся к каждому генератору, при помощи netstat запоминаем все занятые порты, и запускаем на рандомных портах (которые незаняты) необходимое количество jmeter-серверов:
netstat_cmd= 'netstat -tulpn | grep LISTEN' stdin, stdout, stderr = ssh.exec_command(cmd1) used_ports = [] netstat_output = str(stdout.readlines()) ports = re.findall('\d+\.\d+\.\d+\.\d+\:(\d+)', netstat_output) ports_ipv6 = re.findall('\:\:\:(\d+)', netstat_output) p.wait() for port in ports: used_ports.append(int(port)) for port in ports_ipv6: used_ports.append(int(port)) ssh.close() for i in range(1, possible_jris_on_host + 1): port = int(random.randint(10000, 20000)) while port in used_ports: port = int(random.randint(10000, 20000)) # ... Запускаем Jmeter-сервер на найденном рандомном порту - Собираем все запущенные jmeter-сервера в одну сроку в формате адрес: порт, например generator13:15576, generator9:14015, generator11:19152, generator14:12125, generator2:17602
- Полученный список и threads_per_host отправляем в JMeter-client при запуске теста:
REMOTE_TESTING_FLAG=" -R $REMOTE_HOSTS_STRING" java -jar -Xms7g -Xmx7g -Xss228k $JMETER_DIR/bin/ApacheJMeter.jar -Jserver.rmi.ssl.disable=true -n -t $TEST_PLAN -j $WORKSPACE/loadtest.log -GTHREAD_COUNT=$THREADS_PER_HOST $OTHER_VARS $REMOTE_TESTING_FLAG -Jjmeter.save.saveservice.default_delimiter=,
В нашем случае тест происходил одновременно с 300 Jmeter-серверов, по 500 тредов на каждый, сам формат запуска одного Jmeter-сервера с Java-параметрами выглядел так:
nohup java -server -Xms1200m -Xmx1200m -Xss228k -XX:+DisableExplicitGC -XX:+CMSClassUnloadingEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+ScavengeBeforeFullGC -XX:+CMSScavengeBeforeRemark -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -Djava.net.preferIPv6Addresses=true -Djava.net.preferIPv4Stack=false -jar "/tmp/jmeter-JwKse5nY/bin/ApacheJMeter.jar" -Jserver.rmi.ssl.disable=true "-Djava.rmi.server.hostname=generator12.loadtest.ig.local" -Duser.dir=/tmp/jmeter-JwKse5nY/bin/ -Dserver_port=13114 -s -Jpoll=49 > /dev/null 2>&1
50ms
Задача стоит определить сколько наша база данных может выдержать, а не перегрузить её и всю систему в целом до критического состояния. При таком количестве Jmeter-серверов необходимо как-то поддерживать нагрузку на определенном уровне и не убивать всю систему. За это отвечает задаваемый при запуске теста параметр TARGET_RESPONSE_TIME. Мы условились что 50ms — это оптимальное время отклика, за которое системы должна отвечать.
В JMeter по-умолчанию есть много разнообразных таймеров, позволяющих контролировать throughput, но вот откуда его взять в нашем случае неизвестно. Зато есть JSR223-Timer, с которым можно что-то придумать, используя текущее время отклика системы. Сам таймер находится в основном блоке Behavior:

// Изначальные параметры и значение таймера = 0
vars.put('samples', '20');
vars.putObject('respAvg', ${TARGET_RESPONSE_TIME}.0);
vars.putObject('sleep', 0.0);
// В JSR223-Timer в зависимости от среднего времени отклика понижаем или повышаем время "засыпания"
double sleep = vars.getObject('sleep');
double respAvg = vars.getObject('respAvg');
double previous = sleep;
double target = ${TARGET_RESPONSE_TIME};
if (respAvg < target) {
sleep /= 1.5;
}
if (respAvg > target) {
sleep *= 1.1;
}
sleep = Math.max(10, sleep);
// Чтоб не ждали дольше таймаута
sleep = Math.min(20000, sleep);
vars.putObject('sleep', sleep);
return (int)sleep;
Анализ результатов (daemon)
Помимо графиков в Grafana, необходимо также иметь агрегированные результаты тесты, чтобы тесты можно было впоследствии сравнивать в JLTC.
Один такой тест генерирует 16k-20k запросов в секунду, несложно подсчитать, что за 4 часа он генерирует CSV файл размером пару сотен GB, поэтому был необходимо было придумать job, который парсит данные каждую минуту, отправляет их в базу и чистит основной файл.
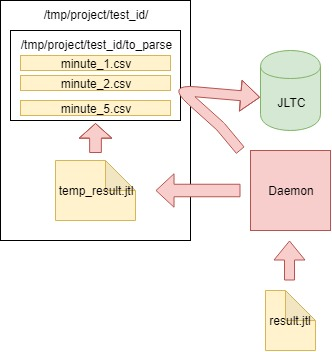
Алгоритм такой:
- Читаем данные из генерируемого jmeter-client CSV-файла result.jtl, запоминаем и чистим файл (необходимо чистить правильно, иначе пустой на вид файл будет иметь прежний FD с прежним размером):
with open(jmeter_results_file, 'r+') as f: rows = f.readlines() f.seek(0) f.truncate(0) f.writelines(rows[-1]) - Пишем прочитанные данные во временный файл temp_result.jtl:
rows_num = len(rows) open(temp_result_filename, 'w').writelines(rows[0:rows_num]) # avoid last line - Читаем файл temp_result.jtl. Распределяем прочитанные данные «по минутам»:
for r in f.readlines(): row = r.split(',') if len(row[0]) == 13: ts_c = int(row[0]) dt_c = datetime.datetime.fromtimestamp(ts_c/1000) minutes_data.setdefault(dt_c.strftime('%Y_%m_%d_%H_%M'), []).append(r) - Данные для каждой минуты из minutes_data пишем в соответствующий файл в папку to_parse/. (таким образом на данный момент каждая минута теста имеет свой собственный файл с данными, далее при агрегации не будет иметь значения в каком порядке данные поступали в каждый файл):
for key, value in minutes_data.iteritems(): # В качестве имени файла используем timestamp (key) temp_ts_file = os.path.join(temp_to_parse_path, key) open(temp_ts_file, 'a+').writelines(value) - Попутно анализируем файлы в папке to_parse и если какой-либо из них не менялся в течении минуты, то этот файл — кандидат на анализ данных, агрегацию и отправку в базу данных JLTC:
for filename in os.listdir(temp_to_parse_path): data_file = os.path.join(temp_to_parse_path, filename) file_mod_time = os.stat(data_file).st_mtime last_time = (time.time() - file_mod_time) if last_time > 60: logger.info('[DAEMON] File {} was not modified since 1min, adding to parse list.'.format(data_file)) files_to_parse.append(data_file) - Если такие файлы (один или несколько) имеются, то отправляем их парсится в функцию parse_csv_data (причем параллельно каждый файл):
for f in files_to_parse: logger.info('[DAEMON THREAD] Parse {}.'.format(f)) t = threading.Thread( target=parse_csv_data, args=( f, jmeter_results_file_fields, test, data_resolution)) t.start() threads.append(t) for t in threads: t.join()
Сам daemon в cron.d запускается каждую минуту:
daemon запускается каждую минуту посредством cron.d:
* * * * * root sleep 21 && /usr/bin/python /var/lib/jltc/manage.py daemon
Таким образом файл с результатами не разбухает до немыслимых размеров, а анализируется «на лету» и очищается.
Результаты
App
Наши 150000 виртуальных игроков:

Тест старается «соответствовать» времени отклика в 50ms, поэтому сама нагрузка постоянно скачет в районе между 16k-18k запросов/c:
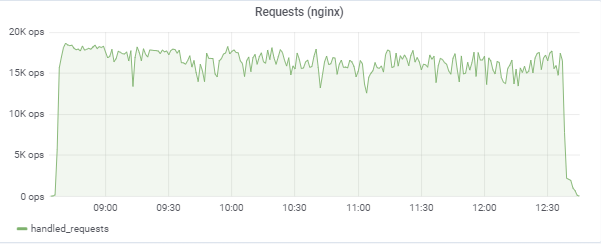
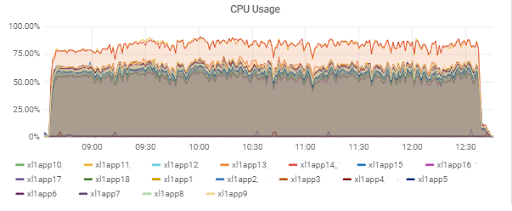
Нагрузка серверах приложений (15 app). Двум серверам «не повезло» оказаться на более медленных M620:
Время отклика базы данных (для app-серверов):

Database
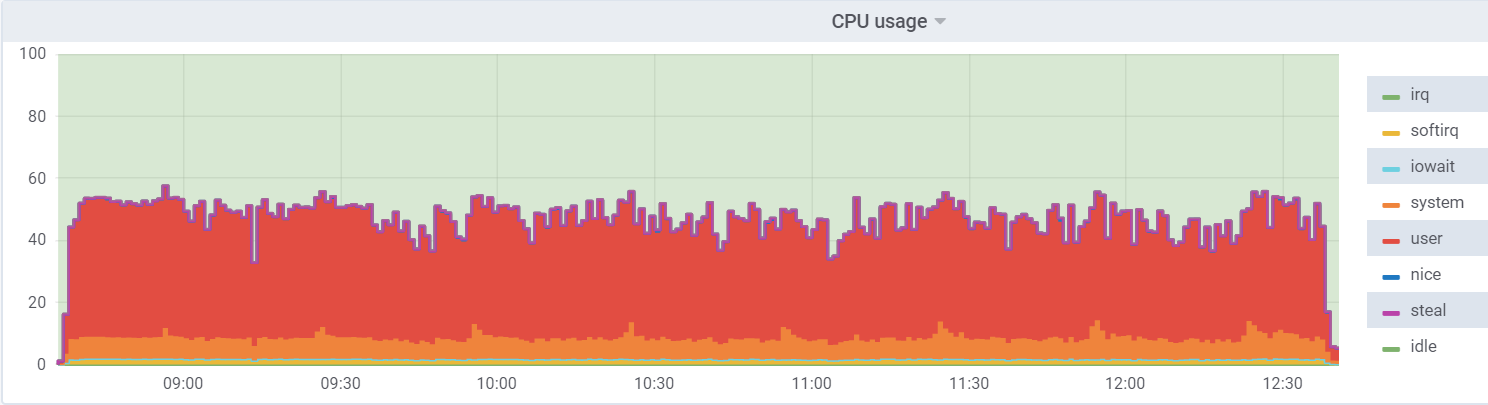
CPU util на db1 (VM):
CPU util на гипервизоре:
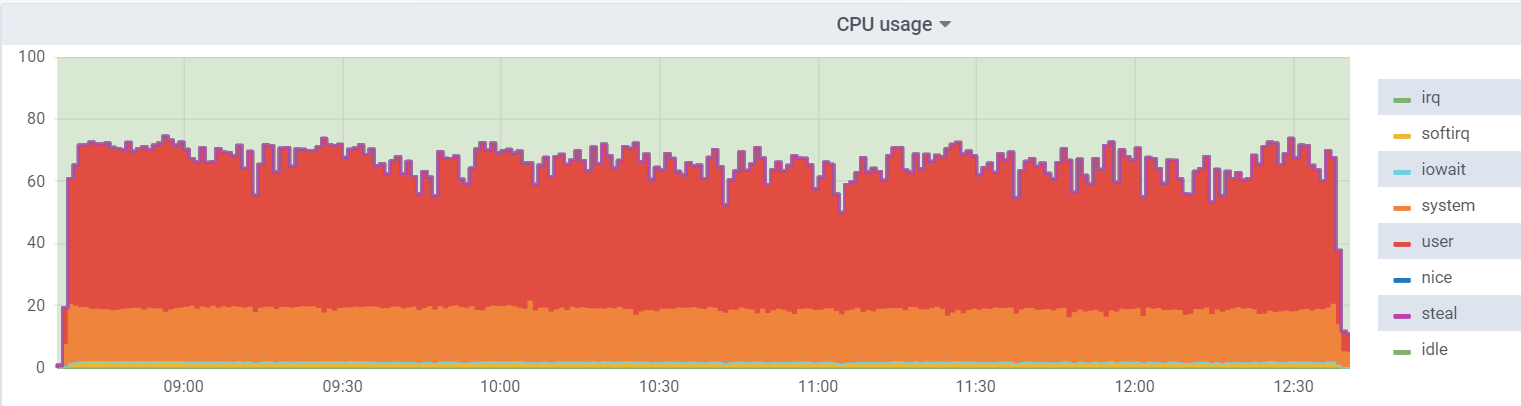
На виртуалке нагрузка ниже, так как она считает, что имеет 48 реальных ядер в распоряжении, на самом деле на гипервизоре их 24 с hyperthreading.
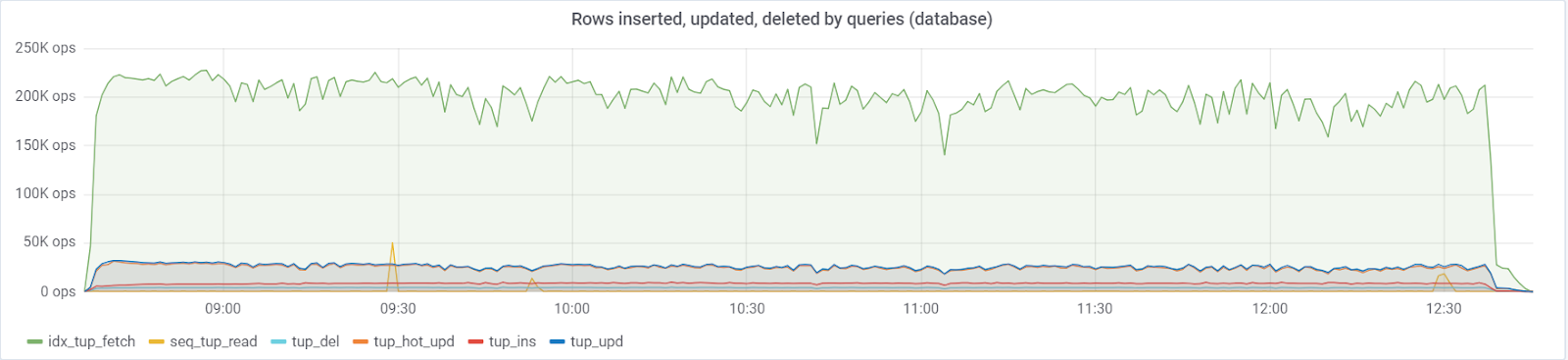
На базу идет максимум ~250K queries/s, состоящих из (83% selects, 3% — inserts, 11.6% — updates (90% HOT), 1,6% deletes):

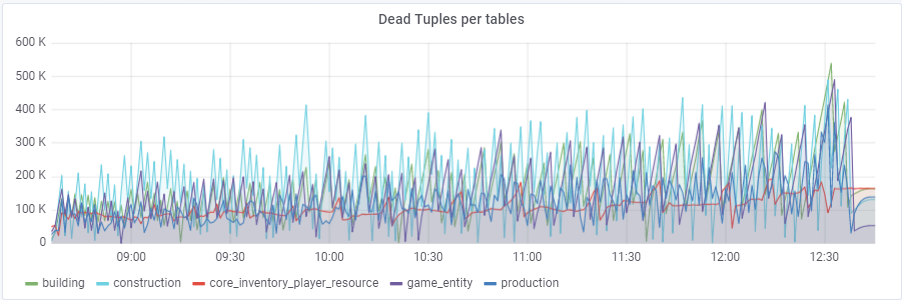
При дефолтном значении autovacuum_vacuum_scale_factor = 0.2 количество мертвых кортежей росло очень быстро с течением теста (при увеличении размеров таблиц), что приводило несколько раз к коротким проблемам с производительностью базы данных, которые несколько раз рушили весь тест. Пришлось «приструнить» данный рост для некоторых таблиц путём назначения персональных значений этого параметра autovacuum_vacuum_scale_factor:
ALTER TABLE construction SET (autovacuum_vacuum_scale_factor = 0.10);
ALTER TABLE production SET (autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE game_entity SET (autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE game_entity SET (autovacuum_analyze_scale_factor = 0.01);
ALTER TABLE building SET (autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE building SET (autovacuum_analyze_scale_factor = 0.01);
ALTER TABLE core_inventory_player_resource SET (autovacuum_vacuum_scale_factor = 0.10);
ALTER TABLE survivor SET (autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE survivor SET (autovacuum_analyze_scale_factor = 0.01);
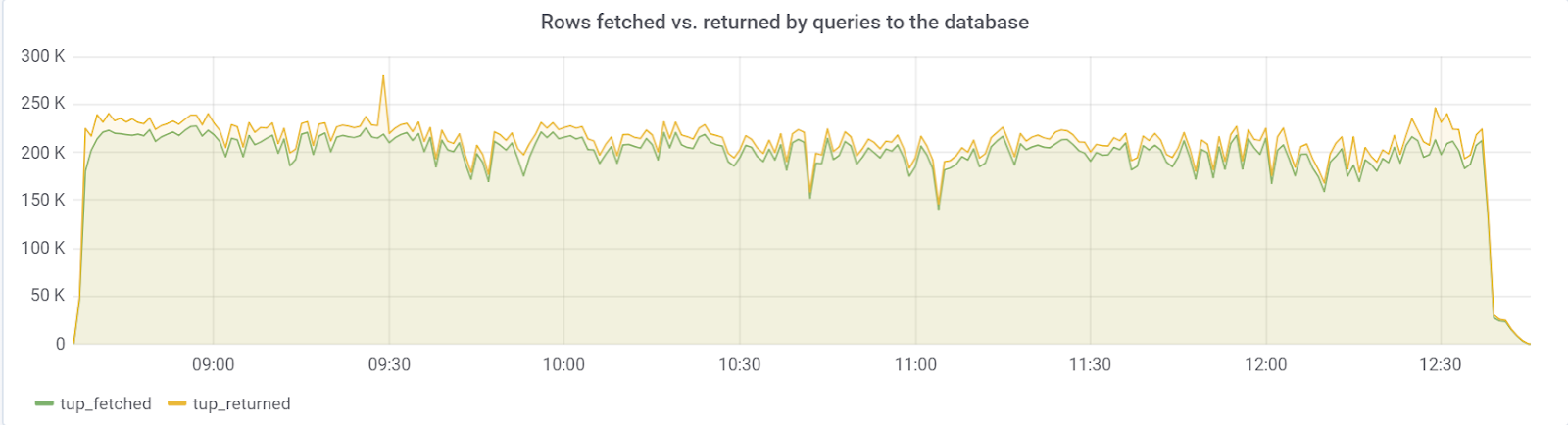
В идеале rows_fetched должно быть близко к rows_returned, что мы, к счастью, мы и наблюдаем:
hot_standby_feedback
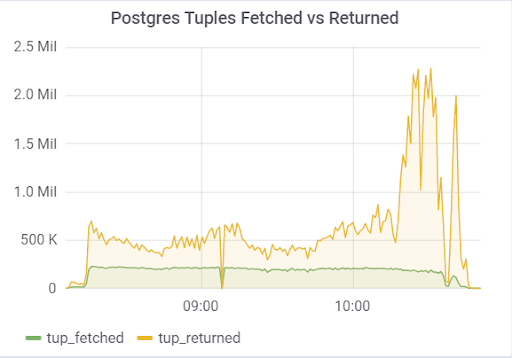
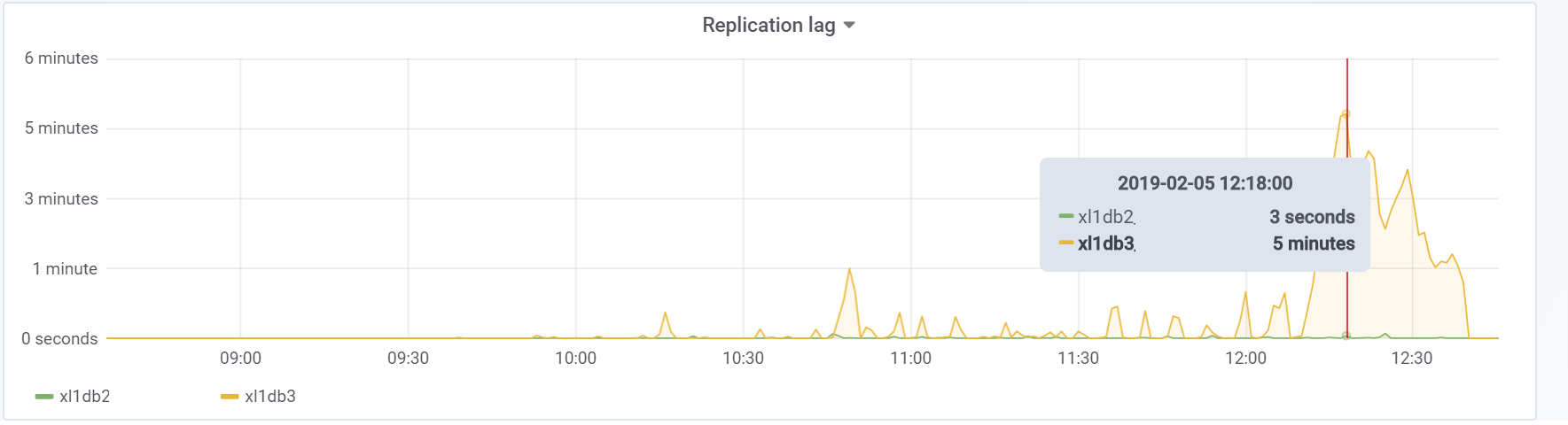
Проблема была с параметром hot_standby_feedback, который может очень сильно сказаться на производительности главного сервера, если его standby сервера не успевают применять изменения из WAL файлов. Документация (https://postgrespro.ru/docs/postgrespro/11/runtime-config-replication) гласит, он «определяет, будет ли сервер горячего резерва сообщать ведущему или вышестоящему ведомому о запросах, которые он выполняет в данный момент.» По дефолту он стоит off, но в нашем конфиге был включен. Что приводило к печальным последствиям, если есть 2 standby сервера и replication lag в ходе нагрузки отличен от нуля (по разным причинам), можно наблюдать такую картину, которая может привести в итоге к краху всего теста:

Всё из-за того, что при включенном hot_standby_feedback VACUUM не хочет удалять «мертвые» кортежи, если standby сервера отстают в своих transaction id, чтобы предотвратить конфликты репликации. Подробная статья What hot_standby_feedback in PostgreSQL really does:
xl1_game=# VACUUM VERBOSE core_inventory_player_resource;
INFO: vacuuming "public.core_inventory_player_resource"
INFO: scanned index "core_inventory_player_resource_pkey" to remove 62869 row versions
DETAIL: CPU: user: 1.37 s, system: 0.58 s, elapsed: 4.20 s
………...
INFO: "core_inventory_player_resource": found 13682 removable, 7257082 nonremovable row versions in 71842 out of 650753 pages
DETAIL: 3427824 dead row versions cannot be removed yet, oldest xmin: 3810193429
There were 1920498 unused item pointers.
Skipped 8 pages due to buffer pins, 520953 frozen pages.
0 pages are entirely empty.
CPU: user: 4.55 s, system: 1.46 s, elapsed: 11.74 s.
Такое большое мертвых кортежей и приводит к картине показанной выше. Здесь два теста, с включенным и выключенным hot_standby_feedback:
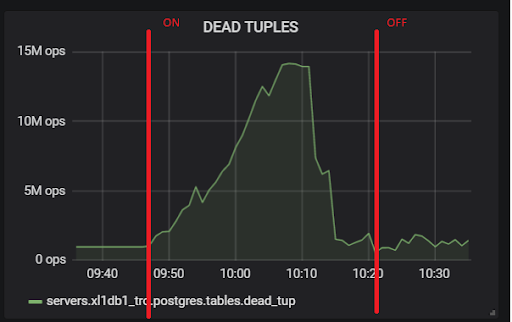
А это наш replication lag в ходе теста, с которым необходимо будет что-то делать в будущем:
Заключение
Данный тест, к счастью (или к сожалению для контента статьи) показал, что на данном этапе прототипа игры вполне реально осилить желаемую нагрузку со стороны пользователей, что достаточно для дачи зелёного света на дальнейшее прототипирование и разработку. При последующих стадиях разработки, необходимо следовать базовым правилам (сохранять простоту выполняемых запросов, не допускать переизбытка индексов, так же как и неидексированных чтений и т.п) и что самое важное, тестировать проект на каждом существенном этапе разработки, чтобы находить и исправлять проблемы как можно раньше. Возможно скоро, я напишу статью как мы решали уже конкретные проблемы.
Удачи всем!
Наш GitHub на всякий случай ;)
