Надежный выбор лидера в Tarantool Cartridge

Сегодня я немного расскажу о том, какие есть мысли по поводу фейловера в tarantool/cartridge. Сначала пару слов про то, что такое cartridge: это кусок lua-кода, который работает внутри tarantool и объединяет тарантулы друг с другом в один условный «кластер». Это происходит за счет двух вещей:
- каждый тарантул знает сетевые адреса всех других тарантулов;
- тарантулы регулярно «пингуют» друг друга через UDP, чтобы понять кто жив, а кто нет. Тут я намеренно немного упрощаю, алгоритм пинга сложнее чем просто request-response, но это для разбора не сильно принципиально. Если интересно — погуглите алгоритм SWIM.
Внутри кластера все обычно разделяется на тарантулы «с состоянием» (master/replica) и «без состояния» (router). Тарантулы «с состоянием» ответственны за хранение данных, а тарантулы «без состояния» — за маршрутизацию запросов.
Вот как это выглядит на картинке:
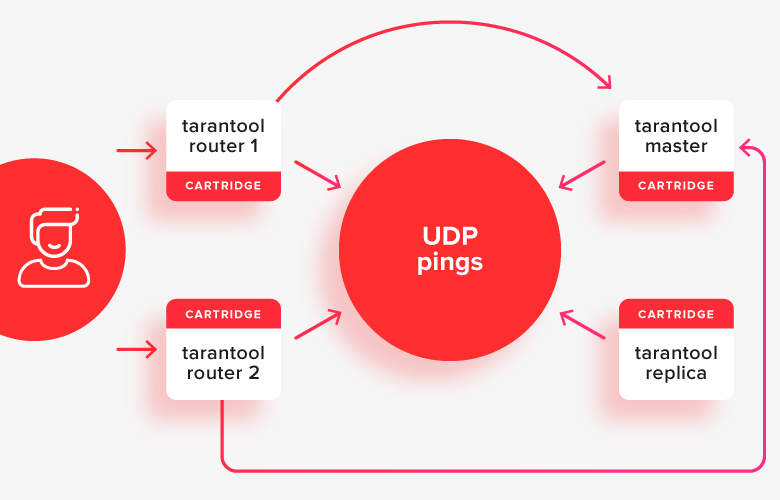
Клиент делает запросы к любому из активных роутеров, а те перенаправляют запросы на тот из стораджей, который сейчас является активным мастером. На картинке эти пути показаны зелеными и синими стрелочками.
Сейчас пока не хочется усложнять и вводить в разговор о выборе лидера шардинг, но с ним ситуация будет мало отличаться. Единственная разница — роутеру еще нужно принять решение на какой репликасет из стораджей сходить.
Сначала поговорим о том, как узлы узнают адреса друг друга. Для этого у каждого из них на диске лежит yaml-файл с топологией кластера, то есть с информацией о сетевых адресах всех членов, и кто из них кем является (с состоянием или без). Плюс потенциально дополнительной настройки, но пока это тоже оставим в стороне. Конфигурационные файлы содержат настройки всего кластера целиком, и одинаковы для каждого тарантула. Если в них вносятся изменения — то вносятся синхронно для всех тарантулов.
Сейчас изменения в конфигурации можно внести через API любого из тарантулов в кластере: он соединится со всеми остальными, разошлет им новую версию конфигурации, все ее применят и везде будет новая версия, снова одинаковая.
Сценарий — отказ узлов, переключение
В ситуации когда отказывает роутер, все более или менее просто: клиенту достаточно пойти в любой другой активный роутер, и он доставит запрос до нужного стораджа. Но как быть, если упал, например, мастер одного из стораджей?
Прямо сейчас у нас для такого случая реализован «наивный» алгоритм, который опирается на UDP ping. Если реплика в течение небольшого промежутка времени не «видит» откликов от мастера на ping, она считает, что мастер упал, и сама становится мастером, переключаясь в read-write режим из read-only. Роутеры действуют точно так же: если они не видят некоторое время отклика на ping от мастера, они переключают трафик на реплику.
Это работает относительно неплохо в простых случаях, кроме ситуации «split brain», когда половина узлов оказывается отделено от другой какой-то сетевой проблемой:
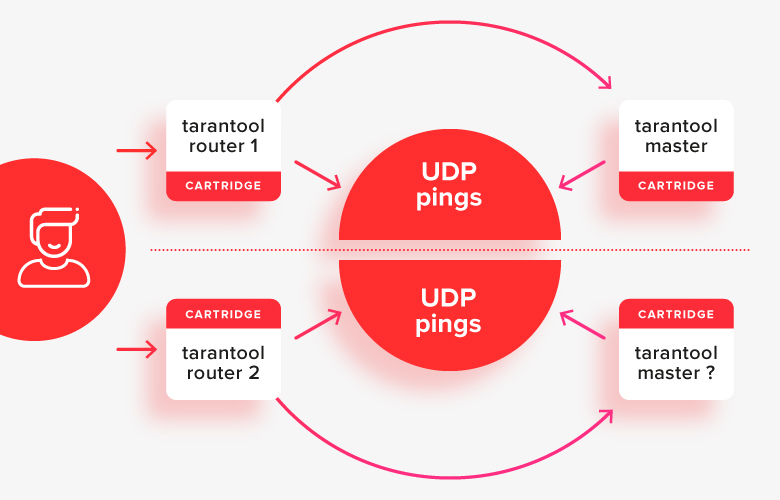
В этой ситуации роутеры увидят, что «другая половина» кластера недоступна, и будут считать свою половину основной, и получится, что в системе одновременно два мастера. Это первый важный кейс, который нужно решить.
Сценарий — редактирование конфигурации при сбоях
Еще один важный сценарий — это замена вышедшего из строя тарантула в кластере на новый, или добавление в кластер узлов, когда кто-то из реплик или роутеров недоступен.
При штатной работе, когда все в кластере доступны, мы можем подключиться через API к любому узлу, попросить его отредактировать конфигурацию, и, как я уже говорил выше, узел «раскатает» новую конфигурацию на весь кластер.
Но когда кто-то недоступен, применять новую конфигурацию нельзя, потому что когда эти узлы снова станут доступны, будет непонятно, кто из них кластера обладает правильной конфигурацией, а кто — нет. Еще недоступность узлов друг для друга может означать, что между ними есть split brain. И редактировать конфигурацию просто небезопасно, потому что можно по ошибке ее отредактировать по-разному в разных половинках.
По этим причинам мы сейчас запрещаем редактировать конфигурацию через API, когда кто-то недоступен. Поправить ее можно только на диске, через текстовые файлы (вручную). Тут вы должны хорошо понимать, что вы делаете и быть очень внимательными: автоматика уже ничем не поможет.
Это делает эксплуатацию неудобной, и это второй кейс, который нужно решить.
Сценарий — стабильный фейловер
Еще одна проблема наивной модели фейловера в том, что переключение с мастера на реплику в случае отказа мастера нигде не записывается. Все узлы принимают решение о переключении самостоятельно, и когда мастер оживет, на него снова переключится трафик.
Это может как быть, так и не быть проблемой. Мастер перед включением обратно «догонит» с реплики транзакционные логи, поэтому большого отставания по данным скорее всего не случится. Проблема будет только в том случае, когда есть неполадки в сети, и есть потеря пакетов: тогда скорее всего будет периодическое «мигание» мастера (flapping).
Решение — «сильный» координатор (etcd/consul/tarantool)
Для того чтобы избежать проблем со split brain, и дать возможность редактировать конфигурацию при частичной недоступности кластера, нам нужен сильный координатор, который устойчив к сегментации сети. Координатор должно быть можно распределить по 3-м датацентрам, чтобы при отказе любого из них сохранять работоспособность.
Сейчас есть 2 популярных координатора, основанных на RAFT, которые для этого используют — etcd и consul. Когда в tarantool появится синхронная репликация, его тоже можно будет для этого использовать.
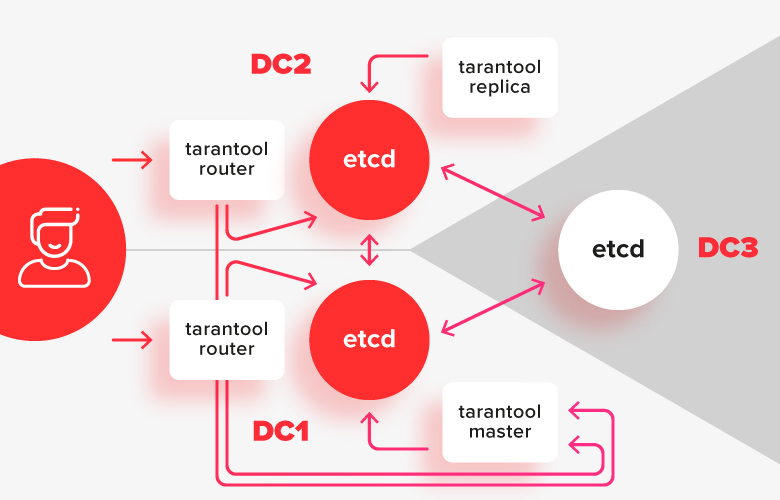
В такой схеме инсталляции тарантула разделены по двум датацентрам, и подключаются к своей локальной инсталляции etcd. Экземпляр etcd в третьем датацентре служит как арбитр для того, чтобы в случае отказа одного из датацентров, точно сказать кто из них остался в большинстве.
Управление конфигурацией с сильным координатором
Как я говорил выше, при отсутствии координатора и отказе одного из тарантулов, мы не могли редактировать конфигурацию централизовано, потому что потом невозможно сказать, какая конфигурация на каком из узлов является правильной.
В случае с сильным координатором все проще: мы можем хранить конфигурацию на координаторе, а каждый экземпляр тарантула будет содержать у себя на файловой системе кэш этой конфигурации. При успешном подключении к координатору он будет обновлять свою копию конфигурации на ту, что есть в координаторе.
Редактирование конфигурации тоже становится проще: это можно сделать через API любого тарантула. Он возьмет блокировку в координаторе, заменит нужные значения в конфигурации, дождется пока все узлы ее применят, и отпустит блокировку. Ну или в крайнем случае можно будет отредактировать конфигурацию в etcd вручную, и она применится ко всему кластеру.
Редактировать конфигурацию можно будет даже если какие-то тарантулы недоступны. Главное, чтобы было доступно большинство узлов координатора.
Фейловер с сильным координатором
Надежное переключение узлов с координатором решается за счет того, что в дополнение к конфигурации, мы будем хранить в координаторе информацию о том, кто является текущим мастером в репликасете, и куда были сделаны переключения.
Алгоритм фейловера меняется вот как:
- Один из тарантулов в кластере выигрывает роль «главного» при помощи механизма блокировок в координаторе.
- Если главный тарантул видит через UDP-пинг, что кто-то из мастеров умер, он начинает процесс фейловера.
- Дальше он принимает решение о том, кто должен быть новым мастером.
- Пишет нового мастера в координатор.
- Все тарантулы в кластере получают уведомление об изменении конфигурации в координаторе и меняют свои роли соответственно, переходя в read-only или read-write.
- Если главный тарантул падает или оказывается отрезан по сети от других датацентров, он теряет роль главного, и через координатор проходят перевыборы.
С координатором также возможна защита от flapping-а. В координаторе можно фиксировать всю историю переключений, и если в течение последних X минут было переключение мастера на реплику, то обратное переключение делается только явно админом.
Еще один важный момент — это так называемый «Fencing». Тарантулы, которые оказываются отрезаны от других датацентров (либо подключены к координатору, потерявшему большинство), должны предполагать, что скорее всего оставшаяся часть кластера, к которой потерян доступ, имеет большинство. И значит в течение определенного времени все отрезанные от большинства узлы должны перейти в read-only.
Проблема с недоступностью координатора
Пока мы обсуждали подходы к работе с координатором, мы получили просьбу сделать так, чтобы если координатор падает, но все тарантулы целые, не переводить весь кластер в read only.
Сначала казалось, что сделать это не очень реально, но потом мы вспомнили, что кластер сам следит за доступностью других узлов через UDP-пинги. Это означает, что мы можем ориентироваться на них и не запускать перевыборы мастера внутри репликасета, если через UDP-пинги видно, что весь репликасет жив.
Такой подход поможет меньше беспокоиться о доступности координатора, особенно если нужно его например перезагрузить для обновления.
Планы на реализацию
Сейчас мы собираем обратную связь и приступаем к реализации. Если вам есть что сказать — пишите в комментарии или в личку.
План примерно вот такой:
- Сделать поддержку etcd в tarantool [готово]
- Фейловер с использованием etcd как координатора, с фиксацией состояния [готово]
- Фейловер с использованием тарантула как координатора, с фиксацией состояния [готово]
- Хранение конфигурации в etcd [в процессе]
- Написание CLI-инструментов для ремонта кластера [в процессе]
- Хранение конфигурации в тарантуле
- Управление кластером при недоступности части кластера
- Fencing
- Защита от flapping–а
- Фейловер с использованием consul как координатора
- Хранение конфигурации в consul
В будущем мы почти наверняка будем полностью отказываться от работы кластера без сильного координатора. Скорее всего это совпадет с реализацией синхронной репликации в тарантуле на базе RAFT.
Благодарности
Спасибо разработчикам из Почты Mail.ru и админам за предоставленный фидбэк, критику и тестирование.
