На что стоит променять Cortex-M3?
 ARM Cortex-M3 — это, пожалуй, самое популярное на сегодняшний день 32-разрядное процессорное ядро для встраиваемых систем. Микроконтроллеры на его базе выпускают десятки производителей. Причина этому — универсальная, хорошо сбалансированная архитектура, а следствие — непрерывно растущая база готовых программных и аппаратных решений.
ARM Cortex-M3 — это, пожалуй, самое популярное на сегодняшний день 32-разрядное процессорное ядро для встраиваемых систем. Микроконтроллеры на его базе выпускают десятки производителей. Причина этому — универсальная, хорошо сбалансированная архитектура, а следствие — непрерывно растущая база готовых программных и аппаратных решений.
Ругать Cortex-M3, в общем-то, не за что, но сегодня я предлагаю подробно рассмотреть Cortex-M4F — расширенную версию всеми любимого процессорного ядра. Перенести проект с микроконтроллера на базе Cortex-M3 на кристалл на базе Cortex-M4F довольно просто, а для ряда задач такой переход стоит затраченных усилий.
Под катом краткий обзор современных Cortex’ов, обстоятельное описание блоков и команд, отличающих Cortex-M4F от Cortex-M3, а также сравнение процессорных ядер на реальной задаче — будем измерять частоту мерцания лампы на микроконтроллерах с разными ядрами.
Часть обзорная
О том как сменяли друг-друга поколения процессорных ядер ARM написано огромное количество статей и обзоров. Не вижу смысла расписывать всё то, что есть в википедии, но напомню основные факты.
Компания ARM Ltd. разрабатывает микропроцессорные и микроконтроллерные ядра с RISC-архитектурой и продает производителям электронных компонентов лицензии на производство кристаллов по соответствующей технологии. Таких производителей по всему миру десятки и даже сотни, есть среди них и отечественные компании.
Современные ядра ARM объединены названием Cortex.
Кстати говоря, слово «cortex» переводится как «кора головного мозга» — структура, отвечающая за согласованную работу органов, мышление, высшую нервную деятельность. По-моему, прекрасное название.
Итак, процессорные ядра ARM Cortex разделены на три основные группы:
- Cortex-A — Application Processors — для приложений, требующих высокой производительности; чаще всего на них запускается linux, android и им подобные ОС
- Cortex-R — Embedded Real-time Processors — для приложений реального времени
- Cortex-M — Embedded Processors — для встраиваемых систем
Рассмотрим последнюю группу, постепенно приближаясь к паре Cortex-M3 / Cortex-M4F. Всего на конец 2015 года представлено шесть процессорных ядер: Cortex-M0, -M0+, -M1, -M3, -M4, -M7.
Из этого списка часто «выпадает» Cortex-M1, это оттого, что -M1 разработан и используется исключительно в приложениях связанных с FPGA. Остальные ядра не имеют столь специализированной области применения и отличаются по производительности — от самого простого -M0 до высокопроизводительного -M7.

По сравнению с Cortex-M0, Cortex-M0+ дополнительно оснащен блоком защиты памяти MPU, буфером Micro Trace Buffer для отладки программ, а также имеет двухступенчатый конвейер вместо трехступенчатого и упрощенный доступ к периферийным блоками и линиям ввода/вывода.
Cortex-M0 и Cortex-M0+ имеют одношинную фон-неймановскую архитектуру, а ядро Cortex-M3 — уже гарвардскую. Cortex-M3 довольно сильно отличается от «младших» представителей линейки и имеет гораздо более широкие возможности.
Cortex-M4 построен по абсолютно той же архитектуре и «структурно» не отличается от Cortex-M3. Разница заключается в поддерживаемой системе команд, но об этом позже. Cortex-M4F отличается от -M4 наличием блока вычислений с плавающей точкой FPU.
Архитектура Cortex-M7 представлена относительно недавно и отличается от Cortex-M3/M4 так же сильно, как Cortex-M3/M4 отличаются от Cortex-M0. 6-ступенчатый суперскалярный конвейер, отдельная кэш-память для данных и команд, конфигурируемая память TCM и другие отличительные функции этого ядра «заточены» для достижения максимальной производительности. И действительно, возможности контроллеров на базе Cortex-M7 сравнивают скорее с Cortex-A5 и -R5, чем с другими контроллерами группы Embedded Processors. Границы применения технологий продолжают размываться.
Несмотря на совершенно разные возможности ядер группы Cortex-M, набор команд каждого ядра включает в себя все команды, поддерживаемые в более младших ядрах. Так обеспечивается возможность разработки программно-совместимых микроконтроллеров на базе разных ядер, этим и занимается большинство производителей микроконтроллеров.

Ядра Cortex-M0 и Cortex-M0+ имеют одну и ту же систему команд. Набор инструкций Cortex-M3 включает все команды Cortex-M0 и около сотни дополнительных инструкций. Процессорные ядра Cortex-M4 и Cortex-M7 имеют, опять же, идентичный набор команд — набора команд Cortex-M3 плюс так называемые DSP-инструкции. Ядро Cortex-M4F дополнительно к набору Cortex-M4 / -M7 поддерживает команды вычислений с плавающей точкой, а система команд Cortex-M7F включает ещё 14 команд для операций над числами с плавающей точкой двойной точности.
Часть теоретическая
Итак, ближайшими «соседями» популярного процессорного ядра Cortex-M3 являются Cortex-M4, дополненный поддержкой DSP-инструкций, и Cortex-M4F, дополнительно содержащий блок FPU и поддерживающий соответствующие команды. Рассмотрим DSP- и FPU-команды.
DSP-инструкции
Аббревиатура DSP чаще всего расшифровывается как Digital Signal Processor, т.е. отдельный и вполне самостоятельный контроллер или сопроцессор, предназначенный для задач цифровой обработки сигналов. Не стоит путать специализированную DSP-микросхему и набор DSP-инструкций. DSP-команды (расшифровывается Digital Signal Processing вместо Processor) — это набор команд, который поддерживается рядом процессорных ядрер ARM и соответствует некоторым типовым для цифровой обработки сигнала операциям.
Первая группа таких операций — это умножение с накоплением (Single-cycle Multiply Accumulate или просто MAC).
Для самых маленьких: умножение с накоплением описывается формулой S = S + A x B. Соответствующие команды описывают умножение двух регистров с суммированием результата в аккумулятор и смежные операции: умножение с вычитанием результата из аккумулятора, умножение без использования аккумулятора и т.д.
Операции предусмотрены для 16- и 32-разрядных переменных и играют важную роль во многих типовых алгоритмах цифровой обработки сигналов. Например, КИХ-фильтр (это классический, почти банальный «например») по сути представляет собой последовательность операций умножения с накоплением, а значит скорость его работы напрямую зависит от скорости выполнения умножения с накоплением.
Все MAC-инструкции в микроконтроллерах с ядром Cortex-M4(F) выполняются за один машинный цикл.
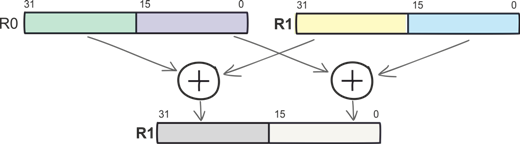
Вторая группа DSP-инструкций — это операции параллельной обработки данных (Single Instruction Multiple Data, SIMD), позволяющие оптимизировать обработку данных за счет параллелизма вычислений. Пары независимых переменных попарно помещаются в один регистр большей размерности, а арифметические операции проводятся уже над «большими» регистрами.
Например, команда SADD16 подразумевает одновременное сложение двух пар 16-разрядных знаковых чисел с записью результата в регистр, хранящий первый операнд.
SADD16 R1, R0
Поскольку регистры общего назначения имеют разрядность 32 бит, в каждый из них можно записать не только по две 16-разрядных переменных (полуслов), но и до четырех 8-разрядных переменных (байт). Несложно прикинуть зачем нужна команда SADD8.
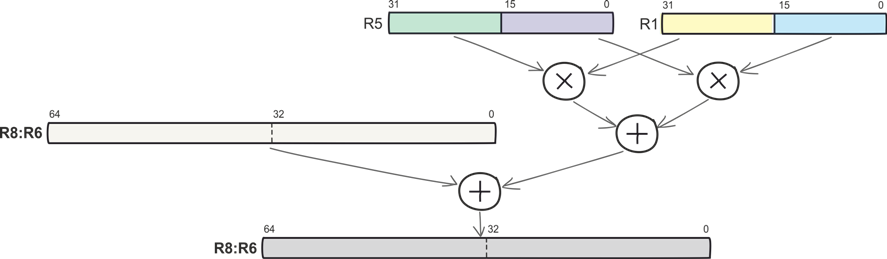
Вот более сложная операция: умножение старших полуслов, умножение младших полуслов и суммирование произведений между собой и с 64-разрядным накоплением. Команда SMLALD описывает все эти действия и выполняется Cortex-M4 за один машинный цикл. SMLALD, как и многие другие команды, совмещает умножение с накоплением и обработку данных по принципу SIMD.
SMLALD R6, R8, R5, R1
И простые SIMD-команды (знаковые и беззнаковые 8- и 16-разрядные сложение и вычитание и т.п.), и сложные команды, подобные SMLALD, выполняются за один машинный цикл.
Следующая группа DSP-инструкций — команды операций с насыщением (Saturating instructions). Они также известны как операции с отсечкой и представляют собой своеобразную защиту от переполнений. При использовании стандартных команд, регистр, хранящий результат, при переполнении «перезагружается» с нуля. Команды, предусматривающие насыщение, при переполнении фиксируют результат на допустимом разрядностью максимуме и с программиста снимается необходимость заботиться о флагах переполнения.
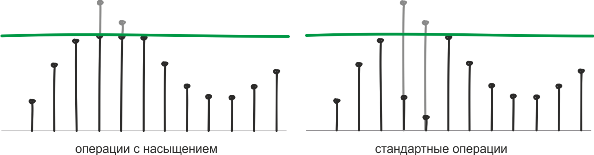
Среди команд процессорного ядра Cortex-M4 есть и «обычные» арифметические операции, и те же операции с насыщением. Использование последних особенно востребовано в задачах, где точностью вычислений можно пожертвовать ради скорости и таких в ЦОС немало.
FPU-инструкции
Аппаратная поддержка вычислений с плавающей запятой (или точкой, кому как больше нравится) — это особенность ядра Cortex-M4F и более старших представителей линейки Cortex-M.
Команды вычислений с плавающей точкой позволяют выполнять операции над вещественными числами с максимальной производительностью. Вообще, для представления вещественных чисел сегодня используется два формата — с фиксированной и плавающей точкой. В первом случае количество разрядов для записи целой и дробной частей зафиксировано и вычисления сводятся к операциям над целыми числами, во втором число представляется как совокупность знакового бита, нескольких разрядов порядка и мантиссы:
(-1)s * m × be,
где s — знак, b-основание, e — порядок, а m — мантисса
Использование формата с плавающей точкой предпочтительно при обработке сигналов за счет гораздо более широкого диапазона значений переменных формата float. Использование операций FPU также избавляет разработчика от необходимости следить за разрядностью. Формат чисел с плавающей точкой одинарной точности описывается стандартом IEEE 754, это представление и используется в микроконтроллерах с ядром Cortex-M4F. Диапазон допустимых значений составляет (10–38… 1038) при приблизительном пересчете в десятичные числа.

Для формата чисел с плавающей запятой двойной точности, как в Cortex-M7F, используется тот же принцип, но вместо 32-разрядного представления используется 64-разрядное, на порядок приходится 11 бит, а на мантиссу 52.
О том как и зачем используется формат с плавающей точкой не раз написано на хабре (вот , например, отличная статья). Мне, пожалуй, не написать лучше, поэтому идем дальше.
Список ассемблерных DSP- и FPU-команд
Чтобы немного прочувствовать масштаб и понять насколько может быть ускорена обработка данных с использованием Cortex-M4 можно поизучать полный перечень DSP- и FPU-инструкций. У меня есть большие сомнения на счет практической ценности этих таблиц, это хотя бы показательно. Все DSP- и большинство FPU-инструкций выполняются за один машинный цикл.
| Команда | Операция |
| PKHTB, PKHBT | перезапись полуслова из одного регистра в другой, при необходимости сдвиг содержимого «принимающего» регистра |
| QADD | знаковое сложение с насыщением |
| QADD16 | знаковое сложение соответствующих полуслов двух операндов (с насыщением) |
| QADD8 | знаковое сложение соответствующих байт двух операндов (с насыщением) |
| QASX | знаковое сложение младшего полуслова второго операнда и старшего полуслова первого операнда, знаковое вычитание старшего полуслова второго операнда из младшего полуслова первого операнда (с насыщением) |
| QDADD | удвоение второго операнда, суммирование результата с первым операндом (знаковое, с насыщением) |
| QDSUB | удвоение второго операнда, вычитание результата из первого операнда (знаковое, с насыщением) |
| QSAX | знаковое вычитание младшего полуслова второго операнда из старшего полуслова первого операнда + знаковое сложение младшего полуслова первого операнда и старшего полуслова второго операнда (с насыщением) |
| QSUB | знаковое вычитание (с насыщением) |
| QSUB16 | знаковое вычитание соответствующих полуслов двух операндов (с насыщением) |
| QSUB8 | знаковое вычитание соответствующих байт двух операндов (с насыщением) |
| SADD16 | знаковое сложение соответствующих полуслов двух операндов |
| SADD8 | знаковое сложение соответствующих байт двух операндов |
| SASX | знаковое сложение старшего полуслова первого пперанда и младшего полуслова второго операнда с записью в старшее полуслово результата, знаковое вычитание младшего полуслова второго операнда из старшего полуслова первого с записью в младшее полуслово результата |
| SEL | выбор байтов из операндов в соответствии с битами GE[3:0] («флаги», устанавливающиеся при выполнении различных условий типа «больше или равно» при выполнении арифметических операций) |
| SHADD16 | знаковое сложение соответствующих полуслов операндов, сдвиг двух результатов на один бит вправо |
| SHADD8 | знаковое сложение соответствующих байт операндов, сдвиг четырех результатов на один бит вправо |
| SHASX | знаковое сложение старшего полуслова первого операнда и младшего полуслова второго операнда, запись результата в старшее полуслово указанного регистра со сдвигом вправо на один бит, знаковое вычитание старшего полуслова второго операнда из младшего полуслова первого операнда, запись результата в младшее полуслово указанного регистра со сдвигом вправо на один бит |
| SHSAX | знаковое вычитание младшего полуслова второго операнда из старшего полуслова первого операнда, запись результата в младшее полуслово указанного регистра со сдвигом вправо на один бит, знаковое сложение старшего полуслова второго операнда и младшего полуслова первого операнда, запись результата в старшее полуслово указанного регистра со сдвигом вправо на один бит |
| SHSUB16 | знаковое вычитание старшего и младшего полуслов второго операнда из соответствующих полуслов первого операнда, сдвиг результат на бит вправо |
| SHSUB8 | знаковое вычитание старшего и младшего байт второго операнда из соответствующих байтов первого операнда, сдвиг результат на бит вправо |
| SMLABB, SMLABT, SMLATB, SMLATT | умножение верхних или нижних полуслов двух операндов с 32-разрядным накоплением |
| SMLAD, SMLADX | попарное умножение полуслов двух операндов, суммирование двух произведение с 32-разрядным накоплением |
| SMLALBB, SMLALBT, SMLALTB, SMLALTT | умножение знаковых полуслов двух операндов (старших или младших) с 64-разрядным накоплением и 64-разрядным результатом |
| SMLALD, SMLALDX | попарное умножение двух байт, взятых из первого операнда на два байта из второго операнда, суммирование двух полученных произведений с 64-разрядным накоплением и 64-разрядным результатом |
| SMLAWB, SMLAWT | умножение верхнего или нижнего полуслова первого операнда на второй операнд с 32-разрядным накоплением, в результирующий регистр записываюся первые 32 разряда 48-битного результата |
| SMLSD | вычитание произведения старших полуслов двух операндов из младших полуслов двух операндов с 32-разрядным накоплением |
| SMLSLD | вычитание произведения старших полуслов двух операндов из младших полуслов двух операндов с 64-разрядным накоплением |
| SMMLA | умножение двух операндов с 32-разрядным накоплением (берутся только 32 старших разряда произведения) |
| SMMLS, SMMLR | умножение двух операндов, вычитание результата из указанного регистра (берутся только 32 старших разряда произведения) |
| SMMUL, SMMULR | умножение операндов (результат — старшие 32-разрядна произведения) |
| SMUAD | умножение старших полуслов двух операндов, умножение младших полуслов двух операндов, сложение произведений |
| SMULBB, SMULBT SMULTB, SMULTT | умножение верхних или нижних полуслов двух оперндов |
| SMULWB, SMULWT | умножение первого операнда на верхнее или нижнее полуслово второго операнда, в результирующий регистр записываюся первые 32 разряда 48-битного результата |
| SMUSD, SMUSDX | умножение старших полуслов двух операндов, умножение младших полуслов двух операндов, вычитание первого произведения из второго |
| SSAT16 | знаковое насыщение полуслов до указанного значения |
| SSAX | знаковое вычитание младшего полуслова второго операнда из старшего полуслова первого операнда с записью в младшее полуслово результата, сложение старшего полуслова первого операнда и младшего полуслова второго операнда с записью в старшее полуслово результата |
| SSUB16 | знаковое вычитание соответствующих полуслов двух операндов |
| SSUB8 | знаковое вычитание соответствующих байт двух операндов |
| SXTAB | извлечение бит [7:0] из регистра и их преобразование в 32-разрядное слово с учетом знака, сложение результата со словом или полусловом |
| SXTAB16 | извлечение бит [7:0] и [23:16] из регистра, их преобразование в полуслова с учетом знака, сложение результата со словом или полусловом |
| SXTAH | извлечение бит [15:0] из регистра и их преобразование в 32-разрядное слово с учетом знака, сложение результата со словом или полусловом |
| SXTB16 | преобразование двух байт в два полуслова с учетом знака, сложение результата со словом или полусловом |
| UADD16 | беззнаковое сложение соответствующих полуслов двух операндов |
| UADD8 | беззнаковое сложение соответствующих байт двух операндов |
| USAX | сложение младшего полуслова первого операнда и старшего полуслова второго операнда с записью результата в младшее полуслово результата, беззнаковое вычитание младшего полуслова второго операнда из старшего полуслова первого операнда с записью в старшее полуслово результата |
| UHADD16 | беззнаковое сложение соответствующих полуслов двух операндов и сдвиг результатов на один бит вправо |
| UHADD8 | беззнаковое сложение соответствующих байт двух операндов и сдвиг результатов на один бит вправо |
| UHASX | беззнаковое сложение старшего полуслова первого операнда и младшего полуслова второго операнда со сдвигом результата сложения на один бит вправо и записью в старшее полуслово результата, беззнаковое вычитание старшего полуслова второго операнда из младшего полуслова первого операнда со сдвигом результата вычитания на один бит вправо и записью в младшее полуслово результата |
| UHSAX | беззнаковое вычитание млдашего полуслова второго операнда из старшего полуслова первого операнда со сдвигом результата вычитания на один бит вправо и записью в старшее полуслово результата, беззнаковое сложение младшего полуслова первого операнда и старшего полуслова второго операнда со сдвигом результата сложения на один бит вправо и записью в младшее полуслово результата, |
| UHSUB16 | беззнаковое вычитание соответствующих полуслов двух операндов, сдвиг результата на один бит вправо |
| UHSUB8 | беззнаковое вычитание соответствующих байт двух операндов, сдвиг результата на один бит вправо |
| UMAAL | беззнаковое умножение с двойным 32-разрядным накоплением и 64-разряжным результатом |
| UQADD16 | беззнаковое сложение 16-разрядных переменных (с насыщением) |
| UQADD8 | беззнаковое сложение 8-разрядных переменных (с насыщением) |
| UQASX | беззнаковое вычитание младшего полуслова второго операнда из старшего полуслова первого операнда, беззнаковое сложение младшего полуслова первого операнда и старшего полуслова второго операнда (с насыщением) |
| UQSAX | беззнаковое вычитание младшего полуслова второго операнда из старшего полуслова первого операнда, беззнаковое сложение младшего полуслова первого операнда и старшего полуслова второго операнда (с насыщением) |
| UQSUB16 | беззнаковое вычитание соответствующих полуслов двух операндов (с насыщением) |
| UQSUB8 | беззнаковое вычитание соответствующих байт двух операндов (с насыщением) |
| USAD8 | беззнаковое вычитание соответствующих байт двух операндов, сложение абсолютных разностей |
| USADA8 | беззнаковое вычитание соответствующих байт двух операндов, сложение абсолютных разностей, сложение результат операции с содержимым аккумулятора |
| USAT16 | беззнаковое насыщение полуслов до указанного значения |
| UASX | беззнаковое вычитание старшего полуслова второго операнда из младшего полуслова первого операнда с записью в младшее полуслово результата, сложение старшего полуслова первого операнда и младшего полуслова второго операнда с записью результата в старшее полуслова результата |
| USUB16 | беззнаковое вычитание соответствующих полуслов двух операндов |
| USUB8 | беззнаковое вычитание соответствующих байт двух операндов |
| UXTAB | извлечение бит [7:0] из регистра и их преобразование в 32-разрядное слово без учета знака, сложение результата со словом или полусловом |
| UXTAB16 | извлечение бит [7:0] и [23:16] из регистра, их преобразование в полуслова без учета знака, сложение результата со словом или полусловом |
| UXTAH | извлечение бит [15:0] из регистра и их преобразование в 32-разрядное слово без учета знака, сложение результата со словом или полусловом |
| UXTB16 | преобразование двух байт в два полуслова без учета знака, сложение результата со словом или полусловом |
| Команда | Операция |
| VABS.F32 | получение абсолютного значения операнда |
| VADD.F32 | сложение операндов |
| VCMP.F32 | сравнение двух операндов или операнда и нуля |
| VCMPE.F32 | сравнение двух операндов или операнда и нуля с проверкой на некорректный операнд (NaN) |
| VCVT.S32.F32 | преобразование между типами данных (с плавающей точкой / целые) |
| VCVT.S16.F32 | преобразование между типами данных (с плавающей точкой / с фиксированной точкой) |
| VCVTR.S32.F32 | преобразование между типами данных (с плавающей точкой / целые) с округлением |
| VCVT |
преобразование между типами данных (полуслово с плавающей точкой — оно же «число с половинной точностью» / с плавающей точкой) |
| VCVTT |
преобразование между типами данных (с плавающей точкой / полуслово с плавающей точкой) |
| VDIV.F32 | деление операндов |
| VFMA.F32 | перемножение двух переменных, прибавление результата умножения к содержимому указанного регистра |
| VFNMA.F32 | инвертирование первого опренда, умножение результата на второй операнд, сложение произведения и инвертированного значения из указанного регистра |
| VFMS.F32 | инвертирование первого опренда, умножение результата на второй операнд, сложение произведения и значения из указанного регистра |
| VFNMS.F32 | умножение двух операндов, сложение произведения и инвертированного значения из указанного регистра |
| VLDM.F<32|64> | извлечение содержимого нескольких указанных регистров из памяти программ |
| VLDR.F<32|64> | извлечение содержимого указанного регистра из памяти программ |
| VLMA.F32 | умножение с накоплением |
| VLMS.F32 | вычитание произведения двух операндов из указанного регистра |
| VMOV | пересылки данных между «стандартными» регистрами ARM и регистрами FPSCR (Floating-Point Status and Control Register), пересылки данных между регистрами хранящими формата с плавающей точкой (регистры FPU), запись констант в регистры FPU и т.п. |
| VMOV, VMRS, VMSR | пересылки данных между «стандартными» регистрами ARM и регистрами FPSCR (Floating-Point Status and Control Register) |
| VMUL.F32 | умножение операндов |
| VNEG.F32 | инвертирование |
| VNMLA.F32 | умножение двух операндов, инвентирование результата, сложение инвертированого произведения и инвертированного значения из указанного регистра |
| VNMLS.F32 | умножение двух операндов, произведения и инвертированного значения из указанного регистра |
| VNMUL | умножение двух операндов, инвентирование результата |
| VPOP | таки pop |
| VPUSH | таки push |
| VSQRT.F32 | извлечение квадратного корня |
| VSTM | сохранение содержимого нескольких указанных регистров в память программ |
| VSTR.F<32|64> | сохранение содержимого указанного регистра в память программ |
| VSUB.F<32|64> | вычитание операндов |
Впрочем, на практике сами инструкции ядра используются не часто. Обычно при разработке достаточно разобраться с документацией на контроллер и сишными библиотеками от производителей ядра и кристалла. В частности, для ядер Cortex существует ARM-овский набор библиотек CMSIS, который используется для процессоров Cortex-M от разных производителей. В состав CMSIS входит и библиотека CMSIS-DSP, она включает в себя:
- базовые математические функции, операции над векторами
- быстрые тригонометрические и трансцендентные функции (sin, cos, sqrt и т.д.)
- линейную и билинейную интерполяции
- комплексную арифметику
- статистические функции
- алгоритмы фильтрации — БИХ-, КИХ- фильтры, алгоритм минимальной среднеквадратичной ошибки
- алгоритмы преобразования сигналов (БПФ и др.)
- матричную арифметику
- ПИД-регулятор
- функции для работы с массивами
Часть практическая
Как правило, сравнение ядер Cortex-M3 и Cortex-M4(F) заканчивается красивыми графиками — гистограммами, на которых показано значительное ускорение работы контроллера на базе -M4 при выполнении типовых для ЦОС операций (КИХ-фильтр, БПФ, матричные вычисления, ПИД-регулятор и т.п). Без указаний используемых контроллеров, методики вычислений и измерений.
Но мы не будем сравнивать Тайд и Обычный стиральный порошок, а возьмем реальную аппаратную и программную платформу.
На этом месте есть смысл отвлечься и немного поразмышлять задачах, для которых актуален описанный математический аппарат Cortex-M4F. Понятно, что на работу с потоковыми данными и разным мультимедиа производительности не хватит, речь идет скорее о системах управления и обработки данных.
Например, идет сбор каких-то телеметрических данных. Узел опроса датчиков может либо просто управлять датчиками и передавать массивы данных на некий центральный вычислительный узел, либо самостоятельно обрабатывать и фильтровать результаты измерений, передавая «центру» только полезные данные. Второй подход имеет ряд очевидных преимуществ — уменьшаются затраты на коммуникации, за счет распределенных вычислений повышается надежность системы и упрощается её масштабирование.
Я не имею в виду только большие и сложные распределенные системы. Представьте себе какой-нибудь модный фитнес-браслет. Будет он передавать всё что намерил на вашем пульсе через bluetooth смартфону? Конечно, нет. Браслет сам проанализирует данные и отправит только одну маленькую посылочку с результатом.
И вот мы подошли к главному. Что чаще всего важно контроллера, который осуществляет вычисления «на месте»? Энергопотребление! Чем меньше варемени занимает обработка данных, тем больше времени микроконтроллер проводит в режиме сна и тем дольше устройство работает без подзарядки.
Так мы вполне логично дошли до того чтобы рассмотреть микроконтроллеры серии EFM32 Wonder Gecko от SiLabs. Они классные и вы можете купить их в ЭФО по отличным ценам оптом и в розницу. Кхе-кхе.
EFM32WG — серия микроконтроллеров на базе ядра Cortex-M4F. Как и другие EFM32, они ориентированы на малопотребляющие устройства и предоставляют разные программные и аппаратные средства для контроля над энергопотреблением. Эти средства мы будем использовать для сравнения ядер Cortex-M3 и Cortex-M4F.
Аппаратная часть:
Плата EFM32WG-STK3800 — кит для работы с микроконтроллером на базе ядра Cortex-M4F
Плата EFM32GG-STK3700 — кит для работы с микроконтроллером на базе ядра Cortex-M3
Платы отличатся между собой только целевым микроконтроллером.
Программная часть
В описываемом эксперимента использовалась платформа Simplicity Studio. Это SiLabs-овская оболочка, которая объединяет все программы, утилиты, примеры и документы, доступные для микроконтроллеров от Silabs. Сейчас понадобятся несколько её компонентов — IDE, утилита для контроля энергопотребления energy profiler, а также готовый проект из набора примеров и user guide на используемые платы.
Суть эксперимента
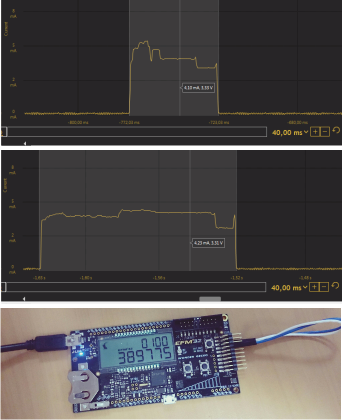
Одна из программ из набора готовых примеров использует Быстрое Преобразование Фурье для измерения частоты мерцания внешнего источника света. Если вкратце, то сигнал с датчика освещенности поступает на АЦП, результаты измерений буферизируются, и раз в 0,5 сек производятся вычисления: по выборке из 512 результатов измерений с использованием БПФ выделяется частота основной гармоники. На ЖКИ выводится результат вычислений и количество машинных циклов за которые была исполнена функция ProcessFFT ().
Ресурсоемкой является только часть алгоритма, связанная с анализом измерений. Запустим одну и ту же программу на двух платах и сравним длительность вычислений и уровень энергопотребления.
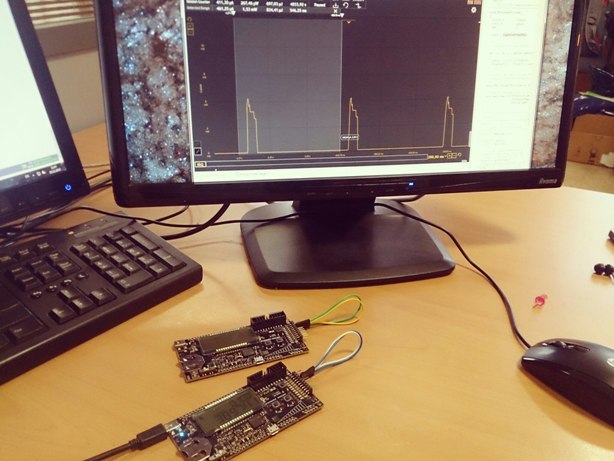
Открываем Simplicity Studio, включаем Simplicity IDE, компилируем проект.
/***************************************************************************//**
* @file lightsensefft.c
* @brief FFT transform example
* @details
* Use ADC in order to capture and analyse input from the
* light sensor on the STK. Runs floating point FFT algorithm from the CMSIS
* DSP Library, and estimate the frequency of the most luminous light source
* using sinc interpolation. The main point with this example is to show the
* use of the CMSIS DSP library and the floating point capability of the CPU.
*
* @par Usage
* Connect the light sensor output to the ADC input by shorting pins
* 15 and 14 on the EXP_HEADER of the STK.
* Direct various light sources to the light sensor. Expect no specific
* frequency from daylight or from a flashlight. Mains powered incandescent
* bulbs should give twice the mains frequency. Using another STK running the
* "blink" example modified to various blink rates is an excellent signal
* source. The frequency bandwidth is approximately 10-500 Hz.
* The frequency shows in the 4 digit numerical display upper right on
* the LCD. The LCD also displays the number of CPU cycles used to do
* the FFT transform.
*
* @author Silicon Labs
* @version 1.04
*******************************************************************************
* @section License
* (C) Copyright 2014 Silicon Labs, http://www.silabs.com
*******************************************************************************
*
* Permission is granted to anyone to use this software for any purpose,
* including commercial applications, and to alter it and redistribute it
* freely, subject to the following restrictions:
*
* 1. The origin of this software must not be misrepresented; you must not
* claim that you wrote the original software.
* 2. Altered source versions must be plainly marked as such, and must not be
* misrepresented as being the original software.
* 3. This notice may not be removed or altered from any source distribution.
*
* DISCLAIMER OF WARRANTY/LIMITATION OF REMEDIES: Silicon Labs has no
* obligation to support this Software. Silicon Labs is providing the
* Software "AS IS", with no express or implied warranties of any kind,
* including, but not limited to, any implied warranties of merchantability
* or fitness for any particular purpose or warranties against infringement
* of any proprietary rights of a third party.
*
* Silicon Labs will not be liable for any consequential, incidental, or
* special damages, or any other relief, or for any claim by any third party,
* arising from your use of this Software.
*
******************************************************************************/
#include "em_common.h"
#include "em_emu.h"
#include "em_cmu.h"
#include "em_chip.h"
#include "em_adc.h"
#include "em_gpio.h"
#include "em_rtc.h"
#include "em_acmp.h"
#include "em_lesense.h"
#include "segmentlcd.h"
#include "arm_math.h"
#include "math.h"
/**
* Number of samples processed at a time. This number has to be equal to one
* of the accepted input sizes of the rfft transform of the CMSIS DSP library.
* Increasing it gives better resolution in the frequency, but also a longer
* sampling time.
*/
#define BUFFER_SAMPLES 512
/** (Approximate) sample rate used for sampling data. */
#define SAMPLE_RATE (1024)
/** The GPIO pin used to power the light sensor. */
#define EXCITE_PIN gpioPortD,6
/* Default configuration for alternate excitation channel. */
#define LESENSE_LIGHTSENSE_ALTEX_DIS_CH_CONF \
{ \
false, /* Alternate excitation enabled.*/ \
lesenseAltExPinIdleDis, /* Alternate excitation pin is disabled in idle. */ \
false /* Excite only for corresponding channel. */ \
}
/* ACMP */
#define ACMP_NEG_REF acmpChannelVDD
#define ACMP_THRESHOLD 0x38 /* Reference value for the lightsensor.
* Value works well in office light
* conditions. Might need adjustment
* for other conditions. */
/* LESENSE Pin config */
#define LIGHTSENSE_CH 6
#define LIGHTSENSE_EXCITE_PORT gpioPortD
#define LIGHTSENSE_EXCITE_PIN 6
#define LIGHTSENSE_SENSOR_PORT gpioPortC
#define LIGHTSENSE_SENSOR_PIN 6
#define LCSENSE_SCAN_FREQ 5
#define LIGHTSENSE_INTERRUPT LESENSE_IF_CH6
/** Buffer of uint16_t sample values ready to be FFT-ed. */
static uint16_t lightToFFTBuffer[BUFFER_SAMPLES];
/** Buffer of float samples ready for FFT. */
static float32_t floatBuf[BUFFER_SAMPLES];
/** Complex (interleaved) output from FFT. */
static float32_t fftOutputComplex[BUFFER_SAMPLES * 2];
/** Magnitude of complex numbers in FFT output. */
static float32_t fftOutputMag[BUFFER_SAMPLES];
/** Flag used to indicate whether data is ready for processing */
static volatile bool dataReadyForFFT;
/** Indicate whether we are currently processing data through FFT */
static volatile bool processingFFT;
/** Instance structures for float32_t RFFT */
static arm_rfft_instance_f32 rfft_instance;
/** Instance structure for float32_t CFFT used by the RFFT */
static arm_cfft_radix4_instance_f32 cfft_instance;
/**************************************************************************//**
* Interrupt handlers prototypes
*****************************************************************************/
void LESENSE_IRQHandler(void);
/**************************************************************************//**
* Functions prototypes
*****************************************************************************/
void setupCMU(void);
void setupACMP(void);
void setupLESENSE(void);
/**************************************************************************//**
* @brief LESENSE_IRQHandler
* Interrupt Service Routine for LESENSE Interrupt Line
*****************************************************************************/
void LESENSE_IRQHandler(void)
{
/* Clear interrupt flag */
LESENSE_IntClear(LIGHTSENSE_INTERRUPT);
}
/***************************************************************************//**
* @brief Enables LFACLK and selects osc as clock source for RTC
******************************************************************************/
void RTC_Setup(CMU_Select_TypeDef osc)
{
RTC_Init_TypeDef init;
/* Ensure LE modules are accessible */
CMU_ClockEnable(cmuClock_CORELE, true);
/* Enable osc as LFACLK in CMU (will also enable oscillator if not enabled) */
CMU_ClockSelectSet(cmuClock_LFA, osc);
/* Division prescaler to decrease consumption. */
CMU_ClockDivSet(cmuClock_RTC, cmuClkDiv_32);
/* Enable clock to RTC module */
CMU_ClockEnable(cmuClock_RTC, true);
init.enable = false;
init.debugRun = false;
init.comp0Top = true; /* Count only to top before wrapping */
RTC_Init(&init);
/* RTC clock divider is 32 which gives 1024 ticks per second. */
RTC_CompareSet(0, ((1024 * SAMPLE_RATE) / 1000000)-1);
/* Enable interrupt generation from RTC0, needed for WFE (wait for event). */
/* Notice that enabling the interrupt in the NVIC is not needed. */
RTC_IntEnable(RTC_IF_COMP0);
}
/**************************************************************************//**
* @brief Enable clocks for all the peripherals to be used
*****************************************************************************/
void setupCMU(void)
{
/* Ensure core frequency has been updated */
SystemCoreClockUpdate();
/* Set the clock frequency to 11MHz so the ADC can run on the undivided HFCLK */
CMU_HFRCOBandSet(cmuHFRCOBand_11MHz);
/* ACMP */
CMU_ClockEnable(cmuClock_ACMP0, true);
/* GPIO */
CMU_ClockEnable(cmuClock_GPIO, true);
/* ADC */
CMU_ClockEnable(cmuClock_ADC0, true);
/* Low energy peripherals
* LESENSE
* LFRCO clock must be enables prior to enabling
* clock for the low energy peripherals */
CMU_ClockSelectSet(cmuClock_LFA, cmuSelect_LFRCO);
CMU_ClockEnable(cmuClock_CORELE, true);
CMU_ClockEnable(cmuClock_LESENSE, true);
/* RTC */
CMU_ClockEnable(cmuClock_RTC, true);
/* Disable clock source for LFB clock. */
CMU_ClockSelectSet(cmuClock_LFB, cmuSelect_Disabled);
}
/**************************************************************************//**
* @brief Sets up the ACMP
*****************************************************************************/
void setupACMP(void)
{
/* Configuration structure for ACMP */
static const ACMP_Init_TypeDef acmpInit =
{
.fullBias = false, /* The lightsensor is slow acting, */
.halfBias
