MyBatis «на минималках»

кадр из м/ф «Крылья, ноги и хвосты»
Привет, Хабр! Меня зовут Пётр Гусаров, я Java‑программист в CDEK. В этой статье расскажу про не очень распространённый фреймворк MyBatis.
Почему MyBatis? Потому что мы в CDEK используем его в большинстве проектов, и в деле он весьма неплохо себя показал. Немного сложен и непривычен на этапе входа, но все эти минусы перекрываются его гибкостью. «Да есть Hibernate, Jooq, JDBC и еще что‑то», — скажут бывалые. Есть, но в данной статье речь пойдёт о MyBatis.
Статья будет полезна новичкам, которые хотели попробовать данный фреймворк или попробовали, но что‑то не получилось.
Содержание
Что мы сделаем
Посмотрим на плюсы и минусы данного фреймворка
Развернём MyBatis на основе Spring Boot (так шустрее)
Напишем и запустим пару‑тройку запросов
Посмотрим, в каких случаях применять MyBatis лучше, чем другие фреймворки.
Почему MyBatis
У меня две новости: хорошая и плохая. С какой начать? Хорошо, начнём с плохой, точнее — с недостатков:
все запросы придётся писать на нативном SQL в XML-файлах. Стойте, не уходите! Не все так страшно, как звучит :)

А теперь послушай, птичка: ты будешь писать SQL на XML (кадр из м/ф «Крылья, ноги и хвосты»)
Теперь к достоинствам:
полный контроль над запросами к БД;
намного легче накладывать логику на legacy‑схемы БД (просто мапим запросы на сущности, остальное делает «птичка»);
при развитии и усложнении продукта вы потратите меньше времени на оптимизацию запросов, чем в других фреймворках;
скорость обработки данных выше. Но здесь есть нюансы: за формирование запросов отвечает разработчик, и только от него зависит, как быстро будет работать обмен данными между приложением и БД;
не нужны знания о дополнительных состояниях вашего объекта, как в Hibernate‑е.
Итак, начнём. Что многие обычно делают, когда начинают изучать новый фреймворк? Открывают официальную документацию подключают его и начинают «тыкать» с разных сторон. В крайнем случае пробуют найти готовый примерчик в сети. Фреймворк считается успешным, если получается поднять его, добавив зависимость и пару‑тройку аннотаций, и всё работает. С MyBatis немного по‑другому — здесь подходит фраза из мультика: «лучше день потерять, потом за 5 минут долететь».
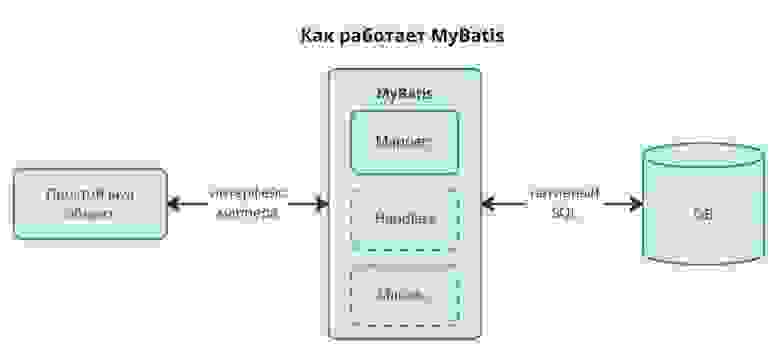
*в рамках данной статьи мы затронем только мапперы
Запустим птичку
Для самых нетерпеливых ссылка на пример лежит здесь.
Создадим проект на основе Spring Boot. Не буду описывать подробности, вы и так знаете, как это делается. Кто не в курсе — вам сюда. Добавьте такие зависимости как mybatis, h2, lombok. Или просто возьмите их из этого pom‑файла:
pom.xml
4.0.0
org.springframework.boot
spring-boot-starter-parent
3.1.3
ru.gpm.example
mybatis-minimum
0.0.1-SNAPSHOT
mybatis-minimum
Demo MyBatis Spring Boot
17
org.mybatis.spring.boot
mybatis-spring-boot-starter
3.0.2
com.h2database
h2
runtime
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
org.mybatis.spring.boot
mybatis-spring-boot-starter-test
3.0.2
test
org.springframework.boot
spring-boot-maven-plugin
org.projectlombok
lombok
Можем уже запустить проект. Он запустится, но делать ничего не будет. Это самая лучшая программа: ничего не делает, ничего не ломает. Но нас не так учили: нам нужен движ, печеньки и зарплата :)
Стартуем на малых оборотах
Мы не будем писать «hello world», а напишем более приближенный к реальности проект, потому что именно такой подход, по моему мнению, покажет этот инструмент в деле. Сделаем сервис по управлению складом и остатками товара на нём.
Настроим MyBatis (здесь будет немного XML). Рядом с application.yml положим файл mybatis‑config.xml следующего содержания:
Здесь мы показали «птичке», где у нас будут лежать объекты, отображающие данные из БД.
Создадим файл schema.sql и положим его в корень ресурсов приложения. Это будет скелет нашей высоконагруженной БД — как мы любим.
schema.sql
set mode MySQL;
CREATE TABLE IF NOT EXISTS product (
id integer NOT NULL auto_increment,
name varchar,
sku varchar,
PRIMARY KEY (id)
);
CREATE TABLE IF NOT EXISTS warehouse (
id integer NOT NULL auto_increment,
name varchar,
PRIMARY KEY (id)
);
CREATE TABLE IF NOT EXISTS stock (
product_id integer,
warehouse_id integer,
qty integer,
PRIMARY KEY (product_id, warehouse_id)
)
mode MySql нужен для поддержки базой H2 некоторых удобных функций при обновлении данных upsert.
Там же создадим папку с названием mappers, в нее мы будем класть наши файлы с запросами к базе. Теперь скажем Spring’у, где у нас этот XML‑файл лежит и откуда брать запросы к БД. Для этого в application.yml напишем следующее:
mybatis:
config-location: classpath:mybatis-config.xml
mapper-locations: classpath*:mappers/*.xml
spring.sql.init.mode: alwaysconfig‑location — показывает, где настройки MyBatis;
mapper‑locations — где «птичка» будет брать запросы;
spring.sql.init.mode — указывает Spring’у, когда инициировать скрипт schema.sql (в нашем случае — каждый раз при запуске).
Закончили с настройками, приступим к написанию кода. Создадим 3 класса в пакете domain: товар, склад и остатки.
@Data
@Accessors(chain = true)
public class Product {
private Integer id;
private String name;
private String sku;
}
@Data
@Accessors(chain = true)
public class Stock {
private Product product;
private Warehouse warehouse;
private int count;
}
@Data
@Accessors(chain = true)
public class Warehouse {
private Integer id;
private String name;
}Далее напишем сами запросы, репозитории и сервисы в привычном нам стиле. Начнём с репозиториев. Точнее, здесь они называются «мапперы».
По‑хорошему, лучше использовать репозитории с DI мапперов в них, так как это создает правильный слой данных и даст возможность управлять форматом данных в репозитории. Но у нас в рамках примера таких сложностей не ожидается.
@Mapper
public interface ProductRepository {
void save(Product product);
List findAll();
}
@Mapper
public interface WarehouseRepository {
void save(Warehouse warehouse);
Warehouse findOne(int id);
}
@Mapper
public interface StockRepository {
List findStockByWarehouse(Warehouse warehouse);
void save(Stock stock);
}
Почти всё готово, осталось написать запросы SQL. Да‑да, запросы на старом добром SQL).
mappers/product-mapper.xml
INSERT INTO product (name, sku)
VALUES (#{name}, #{sku});
mappers/warehouse-mapper.xml
INSERT INTO warehouse (name) values (#{name});
UPDATE warehouse SET name=#{name} where id=#{id};
Обратите внимание: id блоков в XML‑схеме полностью идентичны наименованию методов в интерфейсах репозиториев. Так запросы в XML автоматически линкуются с Java‑интерфейсами репозиториев. Есть и другие варианты, но усложняться не будем.
Здесь мы задействовали такие элементы как insert select и resultMap. Немного остановимся на них:
insert — выполняет вставку в БД.
— id = »…» — это id statement’а для соответствия репозиторию, который будет мапиться на этот запрос;
— useGeneratedKeys=«true» говорит о том, что запрос генерирует значение ключа;
— keyProperty=«id» сообщает «птичке», какое свойство у класса‑модели отвечает за ID и устанавливает его в значение в объекте после сохранения.select — выполняет чтение данных из базы.
— resultMap = «StockMap» используется в блоке и сообщает «птичке», какой маппер использовать для выгрузки данных в объект.resultMap — собственно, сам маппер. Здесь описываются правила маппинга результата запроса (описанного в блоке ) на доменный объект. Вариантов множество. В рамках данной статьи все рассматривать не будем. Остановимся на основных.
— autoMapping=«true» объявляет «птичке»: «Cделай все сама». Но это работает, когда у класса и алиаса в ответе однотипные именования полей, иначе придется описывать правила маппинга.
На следующем маппере (mappers/stock‑mapper.xml) остановимся подробнее.
INSERT INTO stock (product_id, warehouse_id, qty)
VALUES (#{product.id}, #{warehouse.id}, #{count}) ON DUPLICATE KEY
UPDATE qty = #{count}
SELECT
p.id AS p_id,
p.name AS p_name,
p.sku AS p_sku,
w.id AS w_id,
w.name AS w_name,
s.qty
FROM stock s
LEFT JOIN product p ON s.product_id = p.id
LEFT JOIN warehouse w ON s.warehouse_id = w.id
Рассмотрим новые элементы:
sql — шаблонная конструкция запроса, которая может неоднократно использоваться.
— id = »…» — это id шаблона.include refid = »…» — собственно, сама вставка шаблона. Она применяется здесь в двух запросах с разными условиями where.
parameterType=«Warehouse» сообщает «птичке», какой класс объекта передается в параметрах запроса.
resultMap — более развернутый маппер. Здесь видно, как алиасы ответа накладываются на вложенные объекты.
— result property = «count» column = «qty» — настраивает отношение свойств класса и наименования полей ответа;
— association — настраивает отношение вложенных объектов в класс. Таким образом, мы реализуем отношение one‑to‑one. Где property указывает свойство класса вложенного объекта, а columnPrefix — это своеобразный фильтр алиасов в ответе для данного объекта.
Ну, вот. Теперь мы снова олдскульные ребята и девчата! (кадр из м/ф «Крылья, ноги и хвосты»)
И самое сердце нашего приложения — сервисы. Чтобы не грузить логикой этот пример, напишем один сервис для получения остатков товаров на складах. Сохранение сделаем в тестах напрямую через репозитории.
@Service
@RequiredArgsConstructor
public class StockService {
private final StockRepository repository;
public Stock save(Stock stock) {
repository.save(stock);
return stock;
}
public List getAllByWarehouse(Warehouse warehouse) {
return repository.findStockByWarehouse(warehouse);
}
public Stock getBy(Warehouse warehouse, Product product) {
return repository.findStockByWarehouseAndProduct(warehouse.getId(), product.getId());
}
}
Вот и всё — можем запускать наш проект и ловить баги наслаждаться жизнью. Не будем дергать это всё великолепие REST‑контроллерами, а просто напишем тест, который покажет, как это всё работает.
Посмотрим, как это всё работает

кадр из м/ф «Крылья, ноги и хвосты»
@Slf4j
@SpringBootTest
class MyBatisApplicationTest {
@Autowired
private StockService stockService;
@Autowired
private ProductRepository productRepository;
@Autowired
private WarehouseRepository warehouseRepository;
@Test
void init() {
// Добавим товары в БД
productRepository.save(new Product().setName("name-1").setSku("sku-1"));
productRepository.save(new Product().setName("name-2").setSku("sku-2"));
final List all = productRepository.findAll();
Assertions.assertEquals(2, all.size());
// Добавим склад.
final Warehouse warehouse = new Warehouse().setName("склад-1");
warehouseRepository.save(warehouse);
Assertions.assertNotNull(warehouseRepository.findOne(warehouse.getId()));
// Сохраним остатки по товарам на складе
final Stock stock1 = new Stock().setProduct(all.get(0)).setWarehouse(warehouse).setCount(10);
final Stock stock2 = new Stock().setProduct(all.get(1)).setWarehouse(warehouse).setCount(50);
stockService.save(stock1);
stockService.save(stock2);
// Получим текущие остатки на складе
List allByWarehouse = stockService.getAllByWarehouse(warehouse);
Assertions.assertEquals(2, allByWarehouse.size());
log.info("{}", allByWarehouse);
// Поменяем остаток товара
stockService.save(stock1.setCount(20));
allByWarehouse = stockService.getAllByWarehouse(warehouse);
Assertions.assertEquals(2, allByWarehouse.size());
final Stock stockEdit = stockService.getBy(warehouse, stock1.getProduct());
Assertions.assertNotNull(stockEdit);
Assertions.assertEquals(20, stockEdit.getCount());
log.info("{}", allByWarehouse);
}
}
Занавес
Думаю, достаточно для первого знакомства с «птичкой». Подозреваю, многие скажут, что неудобно всё это ручками писать, если есть фреймворки, делающие всё за тебя. Отчасти вы будете правы: они очень удобны, чтобы быстренько написать стандартное приложение. Но когда приходится подключать эти «суперавтоматы» к legacy‑базам или требуется оптимизация запросов в связи с возросшим размером данных, то MyBatis реально выручает.
Возможно, кому‑то данная статья поможет в выборе технологии, а у кого‑то я просто украл время.
Всегда готов к конструктивной критике, так как она поднимает знания и опыт критикуемого :)
Ссылки: GitHub примера, Мультфильм: «Крылья, ноги и хвосты» (скрины и цитаты).
