Music2Dance: как мы пытались научиться танцевать
Всем привет! Меня зовут Владислав Мосин, я учусь на 4-м курсе бакалаврской программы «Прикладная математика и информатика» в Питерской Вышке. Прошлым летом вместе с Алиной Плешковой, магистранткой нашего факультета, я проходил стажировку в JetBrains Research. Мы работали над проектом Music2Dance, цель которого — научиться генерировать танцевальные движения, подходящие под заданную музыку. Это может быть использовано, например, при самостоятельном обучении танцам: услышал музыку, запустил приложение, и оно показало движения, которые гармонично с этой музыкой сочетаются.
Забегая вперед скажу, что наши результаты, к сожалению, оказались далеки от лучших моделей генерации движений, которые сейчас существуют. Но если вам тоже интересно поразбираться в этой задаче, приглашаю под кат.
 Из к/ф «Криминальное чтиво»
Из к/ф «Криминальное чтиво»Существующие подходы
Идея генерации танца по музыке довольно стара. Наверное, самый яркий пример — это танцевальные симуляторы типа Dance Dance Revolution, где игрок должен наступать на светящиеся в такт музыке панели на полу, и таким образом создается некоторое подобие танца. Также красивый результат в этой области — это создание танцующих геометрических фигур или 2D-человечков.
Cуществуют и более серьезные работы — генерация 3D-движений для людей. Большинство таких подходов основываются исключительно на глубоком обучении. Лучшие результаты на лето 2020 года показывала архитектура DanceNet, и мы решили взять именно её в качестве бейзлайна. Дальше мы обсудим их подход подробнее.
Предобработка данных
В задаче генерации танца по музыке присутствуют два типа данных: музыка и видео, и оба нужно предобрабатывать, так как модели не умеют работать с сырыми данными. Поговорим про обработку каждого типа немного подробнее.
Музыка: onset, beats, chroma
Наверное, самый распространенный способ извлечение фичей из аудио — это подсчет спектрограммы или мелграммы — преобразование звука из амплитудного домена в частотный при помощи преобразования Фурье. Однако, в нашей задаче мы работаем с музыкой, а не произвольным аудиосигналом, и низкоуровневый анализ в данном случае не подходит. Нас интересуют ритм и мелодия, поэтому мы будем извлекать onset, beats и chroma (начало ноты, ритм и настроение мелодии).
Видео: извлечение позы человека
Тут все намного интереснее. Примитивный подход — по видео с танцующими людьми попытаться предсказать следующий кадр — обречен на провал. Например, один и тот же танец, снятый с разных дистанций, будет интерпретироваться по-разному. К тому же, размерность кадра даже маленького разрешения (например, 240×240) превышает несколько десятков тысяч пикселей.
Чтобы обойти эти проблемы, используют извлечение позы человека из видео. Поза задается некоторым количеством физиологически ключевых точек тела, по которым можно восстановить ее целиком. К таким точкам относятся, например, голова и таз, локти и колени, ступни и кисти.
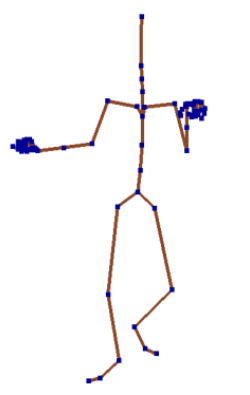 Синим отмечены ключевые точки
Синим отмечены ключевые точкиЭтот метод позволяет уменьшить размерность входных данных (ведь теперь вместо кадра с несколькими десятками тысяч параметров входом выступает низкоразмерный вектор), а также позволяет больше сконцентрироваться на движениях.
Важной особенностью этого метода является способ хранения положений ключевых точек. Например, если хранить просто абсолютные положения в 3D-пространстве, то возникает проблема нефиксированной длины костей: расстояние между голенью и коленом или плечом и локтем может изменяться от кадра к кадру, что не является ожидаемым поведением. Для избежания таких проблем фиксируется положение одной точки человека, а именно середины таза, а положение всех остальных задается через длину кости и угол поворота относительно предыдущей точки. Поясню на примере: положение кисти задается через длину лучевой кости, а также поворот относительно локтя.
Архитектура DanceNet
 Архитектура DanceNet. Источник: https://arxiv.org/abs/2002.03761
Архитектура DanceNet. Источник: https://arxiv.org/abs/2002.03761Архитектура DanceNet cocтоит из нескольких основных частей:
Кодирование музыки;
Классификация музыки по стилю;
Кодирование кадров видео;
Предсказание следующего кадра по предыдущим и музыке;
Декодирование полученного кадра.
Рассмотрим немного подробнее каждую из частей:
Кодирование музыки. Предобратанный аудиосигнал кодируется при помощи сверточной нейросети с Bi-LSTM слоем.
Классификация музыки по стилю. Аналогично предыдущему пункту, сверточная нейросеть с Bi-LSTM слоем.
Кодирование-декодирование кадра. Маленькая двухслойная сверточная сеть.
Предсказание следующего кадра. Самая содержательная часть архитектуры, которая собственно и предсказывает следующую позу по предыдущим и музыке. Состоит из блоков из dilated (расширенных) сверток со скип-соединениями.
На вход DanceNet принимает музыку и набор поз, а вот выдает не просто позу, а параметризацию нормального распределения — математическое ожидание и дисперсию, из которого и сэмплируется ответ, а качестве функции потерь используется минус вероятность правильного положения.
Наше решение
У существующих решений, основанных на глубоком обучении, есть одна серьезная проблема. Чтобы выглядеть реалистично, необходимо вручную реализовывать различного рода ограничения. Например, локти и колени не могут выгибаться в обратную сторону, при статичном положении тела центр тяжести должен находиться между ступнями, и много других ограничений. Для решения этой проблемы автоматически мы предлагаем использовать обучение с подкреплением. Основной частью такого подхода является наличие среды, которая не позволит агенту принимать некорректные положения.
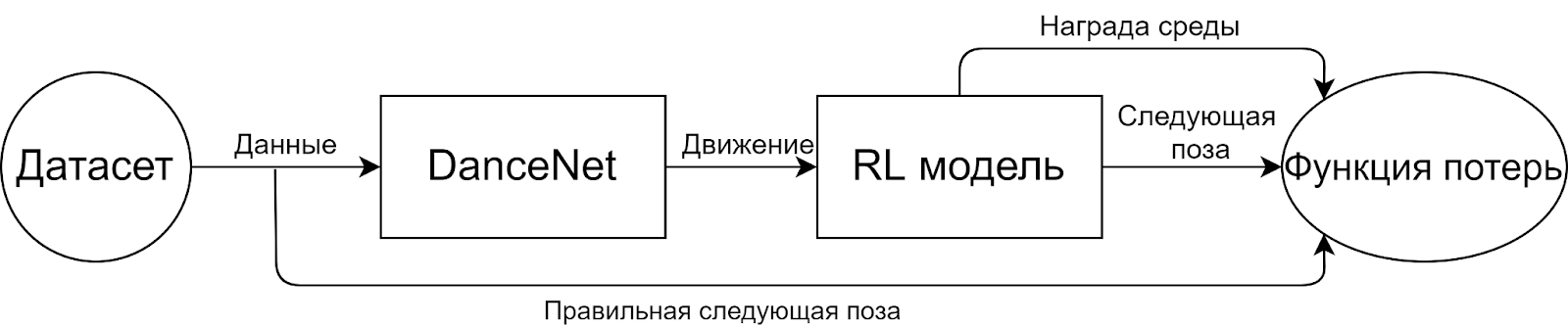 Архитектура решения. Эпоха тренировки
Архитектура решения. Эпоха тренировкиНаше решение состоит из четырех основных частей:
Датасет
Модель для предсказания следующего положения (DanceNet)
Модель для исправления следующего положения положения (RL модель)
Функция потерь
Датасет
Одним из главных вопросов при решении задач машинного обучения является выбор датасета. Для задачи генерации танца на лето 2020 года не было открытых датасетов хорошего качества, и авторы существующих решений собирали их самостоятельно. В статье, взятой нами за бейзлайн, серьезно подошли к вопросу данных и отсняли несколько часов танцев профессионалов. К сожалению, на просьбы поделиться датасетом исключительно на благо науки они ответили отказом. Так как без датасета жить совсем грустно, пришлось что-то придумывать. В итоге мы решили создать датасет из того, что нашлось под рукой: видео с YouTube и библиотеки для детектирования положения человека VIBE.
DanceNet
В своем решении мы использовали оригинальную модель из статьи с одним небольшим изменением — мы убрали классификацию музыки, так как во-первых, нашей целью была генерация танца по любой музыке, а во-вторых, собранные данные не содержали разметки и были весьма разнообразны в музыкальном плане.
RL модель
Задача RL модели — исправить положение тела так, чтобы оно выглядело более реалистичным. На вход модель принимает движение (для каждой точки разность между новым и старым положениями) и старое положение тела, на выход выдает исправленное новое положение.
Рассмотрим модель в деталях. Обучение с подкреплением состоит из двух основных частей: алгоритм обучения и среда.
 Структура алгоритмов обучения с подкреплением
Структура алгоритмов обучения с подкреплениемВ качестве алгоритмов обучения с подкреплением мы решили выбрать один алгоритм, использующий Q-Learning (наш выбор пал на TD3, как на наиболее стабильный и выразительный) и один не использующий (мы остановились на PPO).
Со средой всё оказалось не так просто, как с алгоритмами. По-хорошему, для этой задачи не существует идеально подходящей готовой среды, и ее нужно реализовывать самостоятельно. Однако писать среду, которая будет полностью корректна с точки зрения физики, довольно сложное и долгое занятие, требующее дополнительных знаний. В связи с этим мы решили воспользоваться готовой средой Humanoid, которая предназначена для того, чтобы научить агента передвигаться как можно быстрее и не падать.
Функция потерь
Главной задачей функции потерь является учитывание как награды среды, которая не позволяет принимать нереалистичные положения, так и соответствие положению из датасета.

где S — положение, Sreal — правильное положение, R — награда среды.
Модель на фазе тестирования
 Архитектура решения. Эпоха тестирования
Архитектура решения. Эпоха тестированияНа фазе обучения модель предсказывала следующее положение тела по предыдущим и музыке, однако, на фазе тестирования на вход модели поступает только музыка, а предыдущих положений нет. Чтобы это не стало проблемой, мы ко всем танцам добавили несколько секунд устойчивого неподвижного положения в начале. Теперь на эпохе тестирования мы можем инициализировать предыдущие положения этим самым неподвижным устойчивым равновесием и предсказывать следующее уже на основе музыки.
Результаты
К сожалению, у нас не получилось впечатляющих результатов, таких как у авторов DanceNet. Наш агент научился генерировать некоторые танцевальные движения, например, вращение вокруг своей оси и плавные движения руками, однако, в полноценный танец они не складываются. Мы связываем это в первую очередь с разницей в качествах датасетов. К сожалению, нам не удалось собрать действительно качественные данные — автоматическое извлечение положения из видео с YouTube существенно отличается по качеству в худшую сторону от ручной съемки профессиональных танцоров, и компенсировать это RL алгоритм не сумел.
Наш грустный танец. Спасибо за ваш интерес!
Другие материалы из нашего блога о стажировках:
