MTA против MTO. Кто кого? Никто никого. Работу работаем
В прошлой своей заметке я рассказал о том, как мы пытаемся приводить в порядок производственные потоки методами теории ограничений. В этот раз опишу, как мы внедряем MTA (производство для обеспечения наличия).
Менеджер, смотрел сколько продукции на складе, и исходя из этого размещал в производственный план заказ на склад. Но принцип, что-то поделать, пока есть свободное время, изжил себя. Допустим на складе 10 шт некого продукта. Менеджер решает, что этого мало и говорит производству: «Надо сделать 50 шт». Пока делали 50 шт успели отгрузить половину. Снова заказ на склад. И так по кругу. Минус такой схемы работы очевиден. Все данные из «справочника Фонарёва». Мы решили, что цех, хоть и живой организм, должен работать по легко управляемым алгоритмам.
Менеджер выбирает позицию, за которой должна следить система. Заносит исходные данные. Достаточно только размера начального буфера и это последнее, что делает человек. Дальше автопилот. Начальный буфер (определение см. в интернете) — это то, от чего оттолкнется система для входа в автоматический режим. Примем решение о размере начального буфера на примере, представленного на скрине ниже. Период 12 месяцев. Средний запас 13 750 шт. Период оборачиваемости ~17 дней. Т.е за 17 дней мы продадим примерно 14 000 шт. Стоит отметить, что эти данные берутся из активной базы данных и на каждый момент времени они свежие. Из практики, для комфортной работы, нам нужно иметь запас примерно на 1–1,5 месяца (зависит от продукции). Получается, что нам нужно держать на складе примерно 20 000 шт. Это и есть размер начального буфера. Здесь не важна точность. Можно установить и 25 000 шт. Система через определённый промежуток времени сама откорректирует буфер исходя из текущих отгрузок и приходов на склад.
Небольшие вводные данные:
1. Проект закрытый. Разрабатывается для себя.
2. Среда разработки не имеет значения. Алгоритмы теории ограничений — простая математика, а значит, реализуются любым доступным языком программирования.
3. Все заметки — это попытка поделиться нашей практикой с миром. Теорию ищите в интернете.
Было
Менеджер, смотрел сколько продукции на складе, и исходя из этого размещал в производственный план заказ на склад. Но принцип, что-то поделать, пока есть свободное время, изжил себя. Допустим на складе 10 шт некого продукта. Менеджер решает, что этого мало и говорит производству: «Надо сделать 50 шт». Пока делали 50 шт успели отгрузить половину. Снова заказ на склад. И так по кругу. Минус такой схемы работы очевиден. Все данные из «справочника Фонарёва». Мы решили, что цех, хоть и живой организм, должен работать по легко управляемым алгоритмам.
Стало
Менеджер выбирает позицию, за которой должна следить система. Заносит исходные данные. Достаточно только размера начального буфера и это последнее, что делает человек. Дальше автопилот. Начальный буфер (определение см. в интернете) — это то, от чего оттолкнется система для входа в автоматический режим. Примем решение о размере начального буфера на примере, представленного на скрине ниже. Период 12 месяцев. Средний запас 13 750 шт. Период оборачиваемости ~17 дней. Т.е за 17 дней мы продадим примерно 14 000 шт. Стоит отметить, что эти данные берутся из активной базы данных и на каждый момент времени они свежие. Из практики, для комфортной работы, нам нужно иметь запас примерно на 1–1,5 месяца (зависит от продукции). Получается, что нам нужно держать на складе примерно 20 000 шт. Это и есть размер начального буфера. Здесь не важна точность. Можно установить и 25 000 шт. Система через определённый промежуток времени сама откорректирует буфер исходя из текущих отгрузок и приходов на склад.

Всё. Далее система начинает отслеживать выбранные нами позиции и уведомляет, что нужно разместить в план, при достижении критических точек (красная зона).
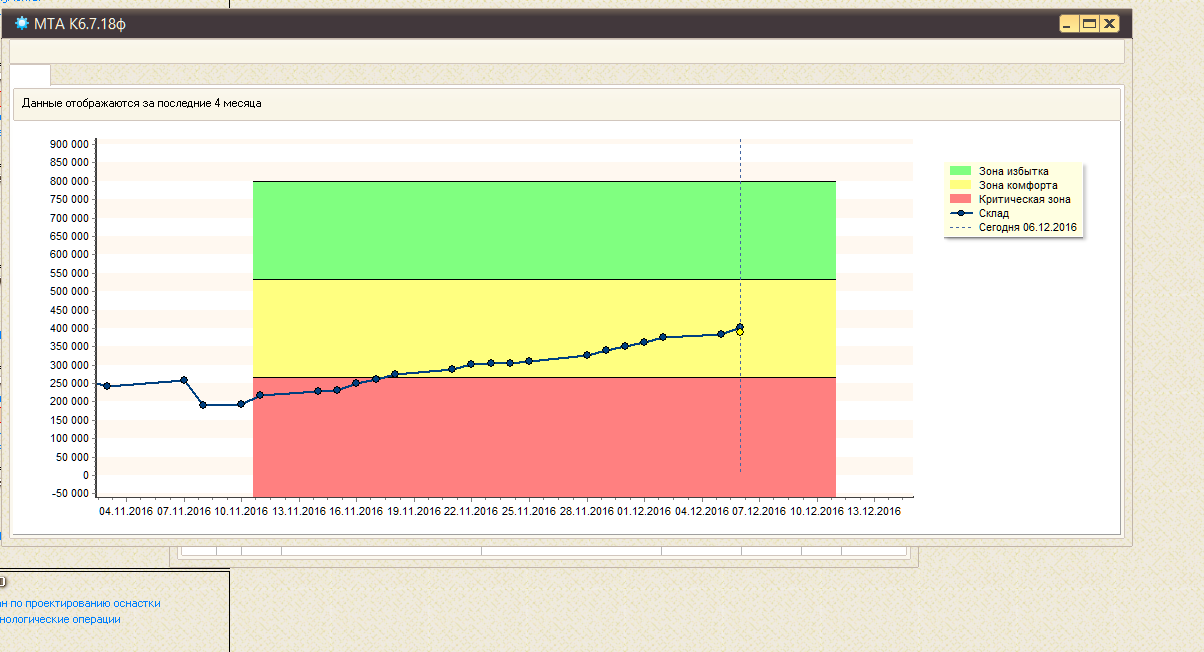
Синяя — перепроизводство. Зелёная — избыток. Желтая — комфорт. Красная — опасность. Черная — дыра.

В следующий раз расскажу про наш динамический буфер.
