Мощный мониторинг за пять минут с помощью Glances
Допустим, что у нас не очень обширная инфраструктура: несколько небольших VPSок, подкроватник, NAS и два ноутбука, торчащих в сеть. Тем не менее, за ней всё равно надо приглядывать, и заниматься этим вручную раздражает всё больше с каждой новой машиной. Я стал искать систему мониторинга, которая могла бы не съедая лишних ресурсов агрегировать информацию отовсюду в единый дашборд, желательно без геморроя с настройкой. В итоге, как только десятки мелких консольных утилит были отброшены вместе с чрезмерно усложнёнными корпоративными хреновинами вроде Prometheus и RabbitMQ, поиск быстро привёл меня к Glances — утилите, берущей лучшее от обоих миров.
Glances — довольно старый консольный инструмент мониторинга на Python, который на Хабре незаслуженно обошли вниманием. Первые релизы вышли в 2014 году, а самый свежий появился 23 января. У проекта почти 18к звёзд на Github, больше сотни контрибьюторов и тысячи форков.
Список отслеживаемых данных:
- Нагрузка на CPU, информация и температура
- Загруженность памяти (RAM, swap)
- Средняя загруженность
- Список и количество процессов
- Использование сетевых интерфейсов
- Операции с диском
- Состояние IRQ и RAID
- Большинство доступных датчиков
- Свободное место на диске и распределение по разделам/папкам
- Список контейнеров, их потребление и процессы
- Аптайм, алёрты и другие мелочи
Кстати, Glances умеет работать и на мобильных устройствах (но, очевидно, только на рутованном андроиде, что сильно сужает круг применения).
Вся нужная информация доступна буквально по одной команде:
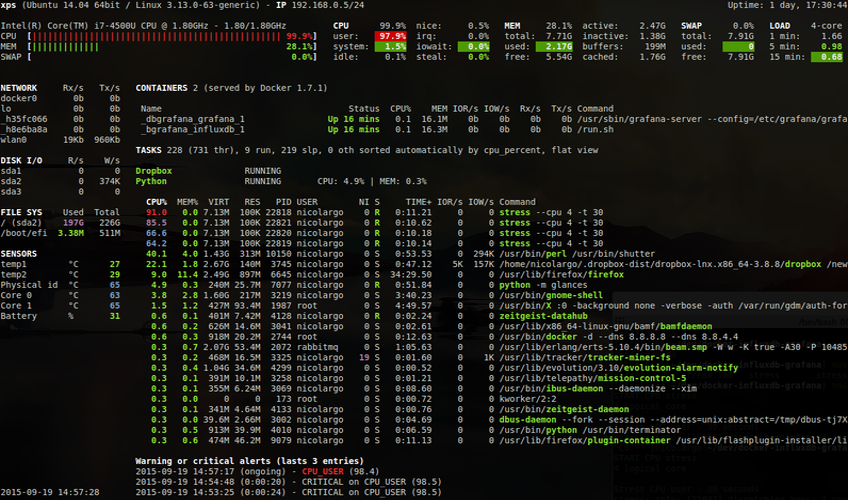
Но пока это лишь консольная утилита, а нам нужно гораздо больше. Вся мощь Glances раскрывается в его огромном количестве интеграций и выходных форматов. Во-первых, из коробки он умеет выводить информацию в веб-версию и XML-RPC/RESTful API. То есть поставив его на все машины и скинув вывод из всех эндпойнтов на один сервер, можно уже добиться желаемого. Но консольный вывод с десятка устройств читать неудобно ни в каком виде, а уж тем более пытаться уместить его на одном экране, поэтому смотрим интеграции:
- Cassandra/Scylla
- CouchDB
- Elasticsearch
- InfluxDB
- Kafka
- MQTT
- OpenTSDB
- Prometheus
- Riemann
- StatsD
- ZeroMQ
Нас, конечно, интересует InfluxDB и последующий вывод из неё в графану. Тем более что у Glances уже есть готовый дашборд, бери да пользуйся.
Вариантов установки много, но стабильнее всего работает установка через PyPI:
pip install glances
Можно сразу доустановить дополнительные модули:
pip install 'glances[action,browser,cloud,cpuinfo,docker,export,folders,gpu,graph,ip,raid,snmp,web,wifi]'
Полный список установок InfluxDB здесь, стандартный вариант для Ubuntu/Debian x64:
wget https://dl.influxdata.com/influxdb/releases/influxdb2-2.0.4-amd64.deb
sudo dpkg -i influxdb2-2.0.4-amd64.deb
Создаём базу glances с любым пользователем и передаём данные в конфиг Glances следующего вида:
# glances.conf
[influxdb]
host=localhost
port=8086
protocol=http
user=admin
password=foobar
db=glances
prefix=localhost
Затем запускаем утилиту с экпортом данных в InfluxDB и использованием конфига, где к ней указан доступ:
glances --export influxdb -С glances.conf
Почти готово, осталось открыть InfluxDB для доступа извне:
# /etc/influxdb/influxdb.conf
[http]
enabled = true
bind-address = ":8086"
auth-enabled = true
log-enabled = true
write-tracing = false
pprof-enabled = true
pprof-auth-enabled = true
debug-pprof-enabled = false
ping-auth-enabled = true
# по хорошему нужно включить https, но я не заморачивался :)
# https-enabled = true
# https-certificate = "/etc/ssl/influxdb.pem"
Все операции выше повторяем на отслеживаемых машинах, затем на агрегирующем сервере ставим графану:
wget -q -O - https://packages.grafana.com/gpg.key | sudo apt-key add -
echo "deb https://packages.grafana.com/oss/deb stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
sudo apt-get update
sudo apt-get install grafana
sudo systemctl daemon-reload
sudo systemctl start grafana-server
sudo systemctl status grafana-server
Открываем интерфейс на 3000 порту, логинимся и добавляем наши удалённые источники данных (Configuration > Data sources > Add data source > InfluxDB):
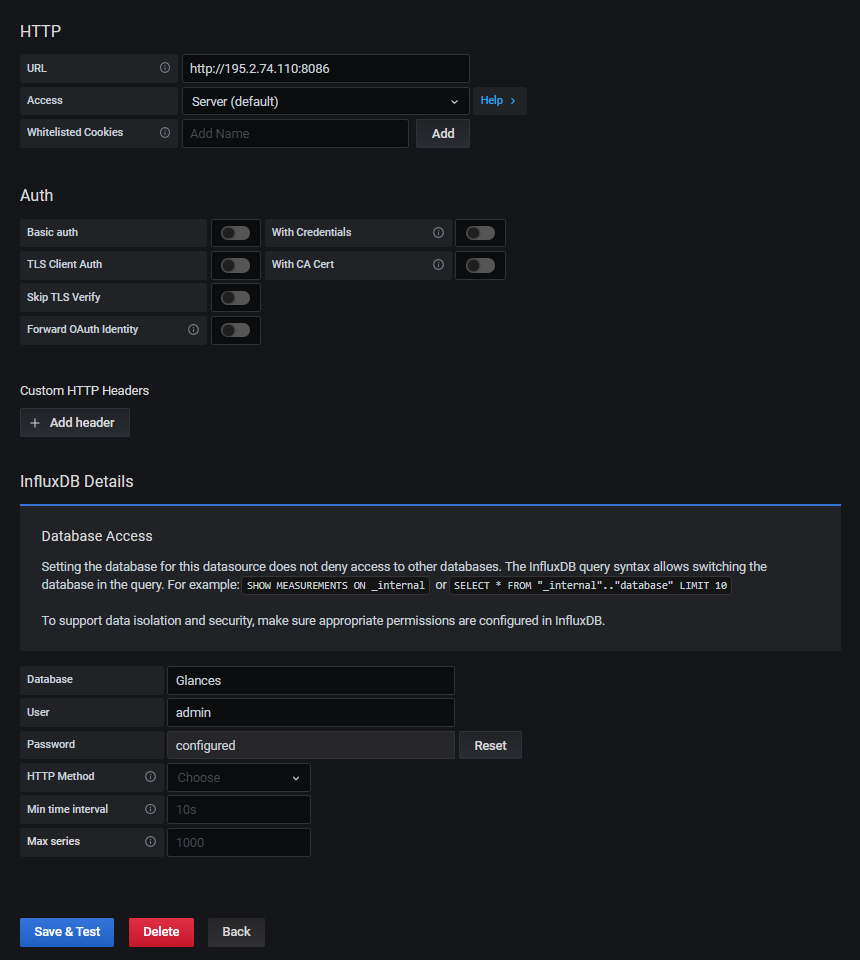
Затем берем настроенный дашборд из репозитория Glances: https://github.com/nicolargo/glances/blob/master/conf/glances-grafana.json
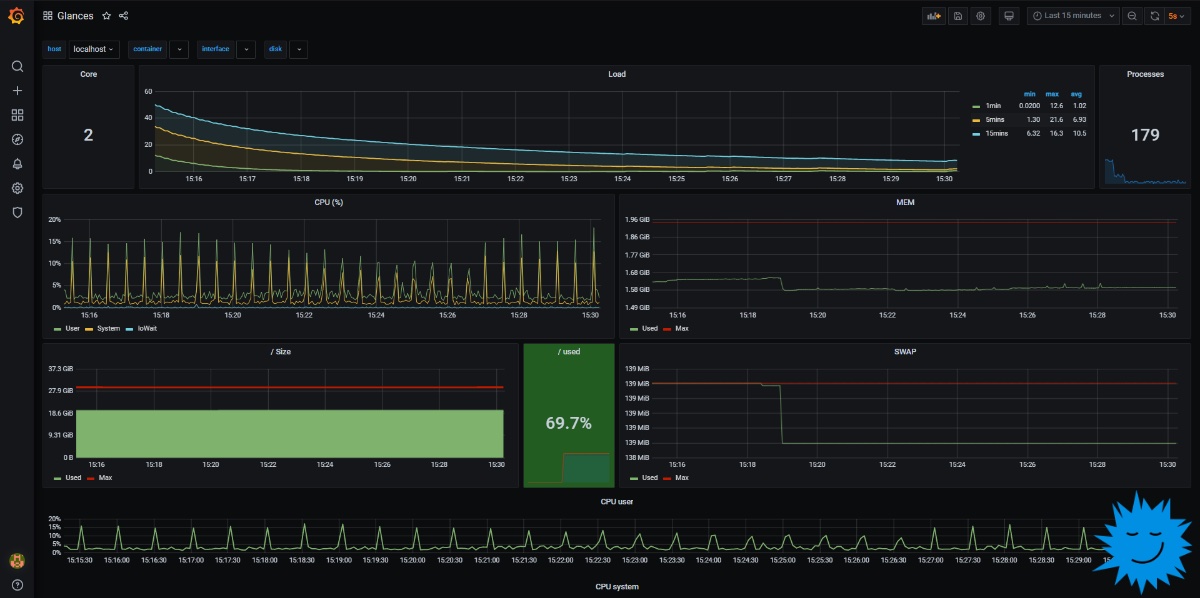
Импортируем его в графану (+ > Import) и настраиваем под себя, повторяем для всех машин. Готово! Теперь в одном интерфейсе мы можем подробно рассмотреть все метрики (как на КДПВ), а ключевые, вроде нагрузки на CPU, можно собрать на одном общем дашборде.
Раньше я думал, что настраивать удалённый мониторинг на несколько машин это жуткий геморрой (или можно отдать всю работу готовым сервисам, но с большей нагрузкой и без гибкой подстройки), а оказывается нужно было просто найти подходящий инструмент. Конечно, при желании можно забить на графики и смотреть консольный вывод или обрабатывать API по-своему. Мне нравится такая вариативность.
На правах рекламы
Эпично! Виртуальные серверы на базе новейших процессоров AMD EPYC, которые подойдут не только для мониторинга, но и для размещения проектов любой сложности, от корпоративных сетей и игровых проектов до лендингов и VPN.

