Мониторинг с Grafana. Best practices

Сборная солянка из существующих best practices по работе с Grafana и немного с Prometheus, проверенных мной лично. Можно просто положить в закладки — когда-нибудь да пригодится.
 Александр Груздев
Александр ГруздевHead of Core Development, Karuna
Всем привет. Меня зовут Александр, и я работаю руководителем отдела разработки в компании Каруна.
Также в прошлом я инжиниринг менеджер, тим лид и java разработчик. Так что если говорить про мониторинг, то приходилось и инциденты в проде на ощупь чинить (без каких-либо метрик), и внедрять разные практики по observability на уровне всего продукта. Ну, и за это время данная тема настолько закралась мне в душу, что захотелось «излить свои мысли на бумагу».
Интро про мониторинг
Для тех, кто не первый год пилит сервисы — можно спокойно листать до пункта Best practices.
Но я всё же постараюсь сделать статью максимально универсальной и добавлю чуток деталей.
Когда мы говорим о мониторинге, скорее всего, каждый из нас представляет себе совершенно разные вещи. Кто-то представляет красивые графики, меняющиеся в реалтайме и показывающие, сколько профита приносят ваши сервисы, а кто-то видит в этом основную помощь при попытке разобраться, почему его сервис ведет себя, не как остальные на прод. окружении, и максимально обкладывается данными типа JVM Heap Size, времени ожидания получения соединений к БД и количества попаданий в кэш.
Основной посыл — каждому нужен свой собственный мониторинг. Не бывает универсальных метрик, которые будут покрывать все случаи жизни. А если вы такой дашборд сделали, спросите кого-нибудь ещё, понимает ли он, что у вас на этой борде происходит. Скорее всего, вы — единственный, кому понятно, как это использовать.

Универсальный алгоритм, как сделать хороший дашборд
Ответь на вопросы:
Кто будет смотреть на него?
В каком случае?
С какой целью?
Эти вопросы должны помочь определиться с форматом метрик, сложностью и универсальностью дашборда.
Изучи инструмент:
Какие метрики бывают (vector, instant и т. д.)?
Какой DSL у датасорса (promQL, influx)?
Какие есть готовые шаблоны (надо же с чего-то начать)?
Ничего сложного в DSL нет, но всё же каждый датасорс имеет некоторые особенности.
По типам метрик в Grafana/Prometheus опять же всё уже миллион раз написано, да и сам официальный гайд тоже неплох — тык сюда.
Just do it:
Сначала сделай хоть что-то.
Попробуй в работе.
Дорабатывай и автоматизируй.
Не стоит сразу опираться на опыт Google и компаний, которые предлагают писать и поддерживать Grafana дашборды через jsonnet и прочие «as Code» решения. Это — дикое усложнение, которое требует совершенно иного уровня зрелости команд.
Теперь немного пробежимся по стратегиям мониторинга.
Стратегии мониторинга
Все перечисленные ниже концепты на слуху, поэтому не буду раскрывать в деталях, но дам полезные ссылки, где и что почитать.
USE
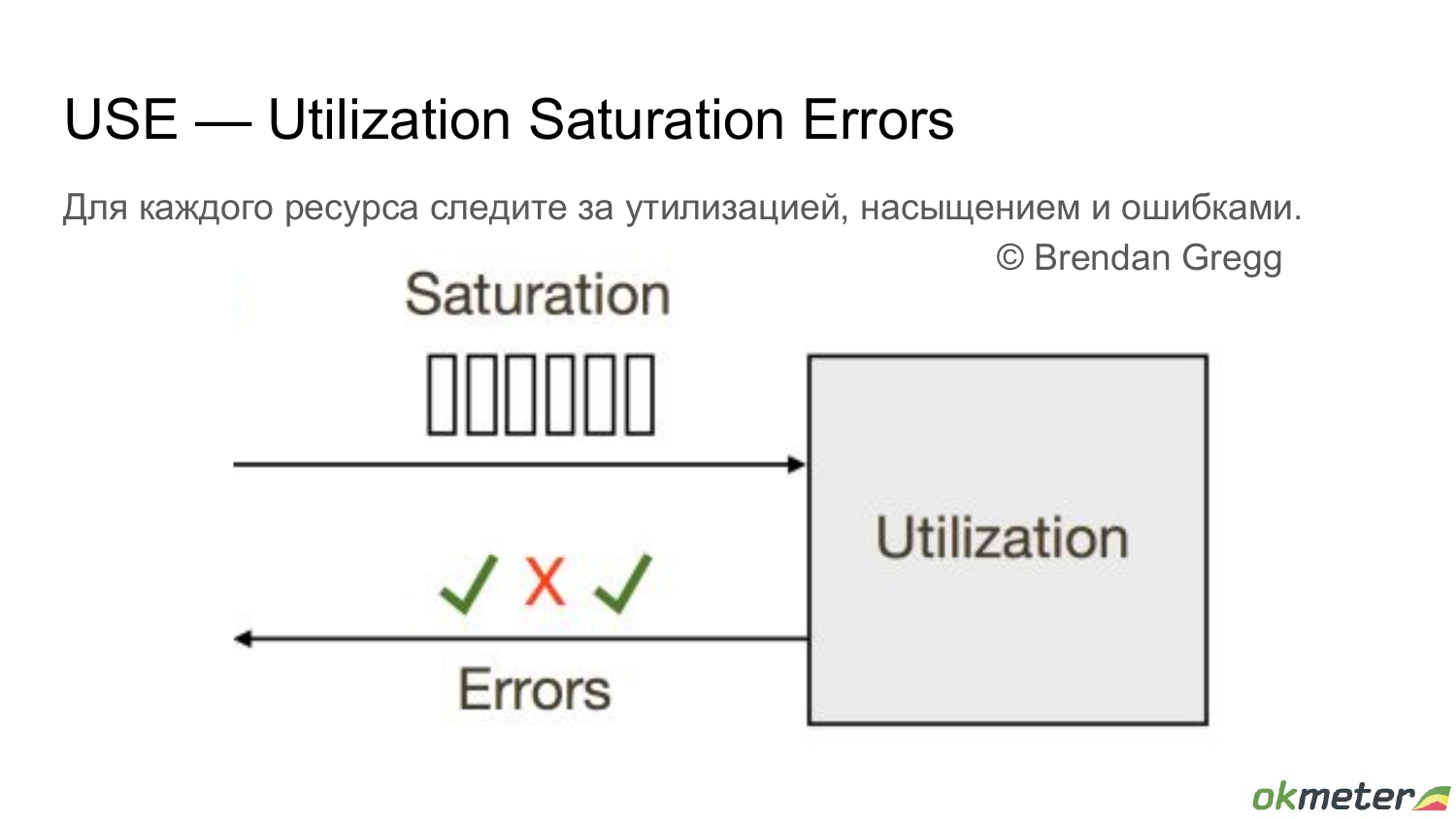
Предлагается отслеживать утилизацию, сатурацию и ошибки для мониторинга железа, сетевых интерфейсов, ну и прочего низкоуровневого:
CPUs: sockets, cores, hardware threads (virtual CPUs)
Memory: capacity
Network interfaces
Storage devices: I/O, capacity
Controllers: storage, network cards
Interconnects: CPUs, memory, I/O
Как видите, ничего сложного и мудреного. Единственное скользкое место — это разница между утилизацией и сатурацией, и их влияние друг на друга.
Вот тут можно почитать подробнее (https://www.brendangregg.com/usemethod.html)
RED

Это вариант для приложений. Берёте метрики по запросам в секунду, ошибки и время выполнения, и вуаля.
Можете считать, что следуете практикам мирового масштаба.

4 Golden Signals
Наверно, самый распиаренный концепт, ну просто потому, что Google так говорит.
На самом деле ничего нового не придумали. Взяли и образно скрестили RED и USE. А почему бы и нет?

Данный вариант предлагает отслеживать задержки (latency), объем трафика (traffic), ошибки (errors) и насыщение (saturation). В целом подойдет как к мониторингу железа, так и приложений.
Вот тут можно дочитать:
Моё уважение тем, кто дочитал до этого момента.

Впереди будет пободрее и без лишнего скептицизма.
Best practices
Самая ценная часть данной статьи.
Дальше будут просто советы, которые вы можете спокойно взять и начать применять, либо накидать критики в комментариях.
Это будет значить, что в любом случае я своей цели добился, и либо получу ваш плюсик в карму, либо ещё один, два, а может и больше советов, как с этим мониторингом жить и не тужить.
Лучшие советы из комментов обещаю добавить в статью!
Важно: пришлось затереть часть информации на скринах, чтобы СБ не пришли за мной ночью… ну их. Ну и часть скринов может быть не самого лучшего качества, как говорится, «фоткал на тапок».
Часть 1. Базовая настройка
UTC timezone everywhere
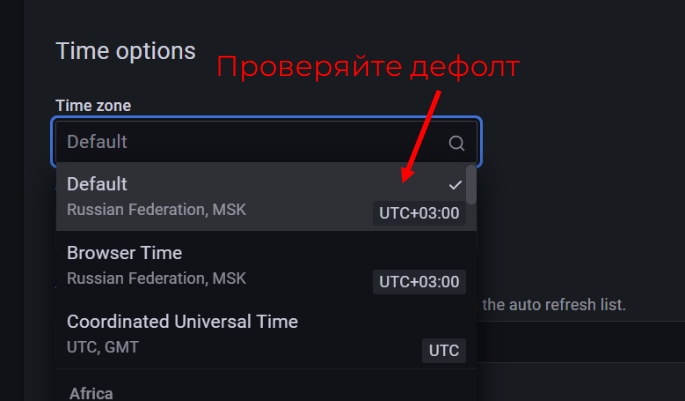
Все в равных условиях: и Москва, и Филиппины. Позволяет ускорить поиск проблем, когда работаешь сразу с несколькими дашбордами разных команд. Иначе постоянно приходится в голове конвертировать и приводить к одному формату.
Не ставьте (по возможности) автоапдейт

Не мучайте Prometheus или другой datasource. Плюсом, ваш браузер не начнет загибаться, пытаясь постоянно отрисовать последние апдейты.
Важно: этот совет применим к статическим дашбордам (каких обычно большинство). Для реалтайм отображения, конечно, это не применимо.
Небольшой time range при открытии

Опять же вопрос скорости отрисовки и потребляемых ресурсов. Чем меньше интервал, тем быстрее отрисуются все графики, и тем быстрее вы сможете сменить дефолтные настройки на нужные в конкретный момент.
Фиксированный start time
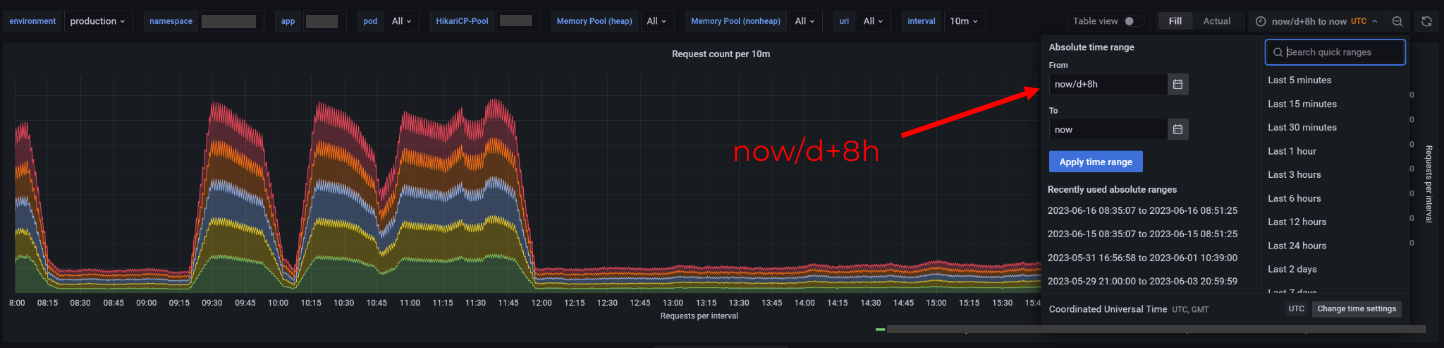
Если вам нужны метрики за фиксированный регулярный интервал (например, рабочий день с 8 до 17), используйте дефолт в формате now/d+8h.
Используйте панели для скрытия
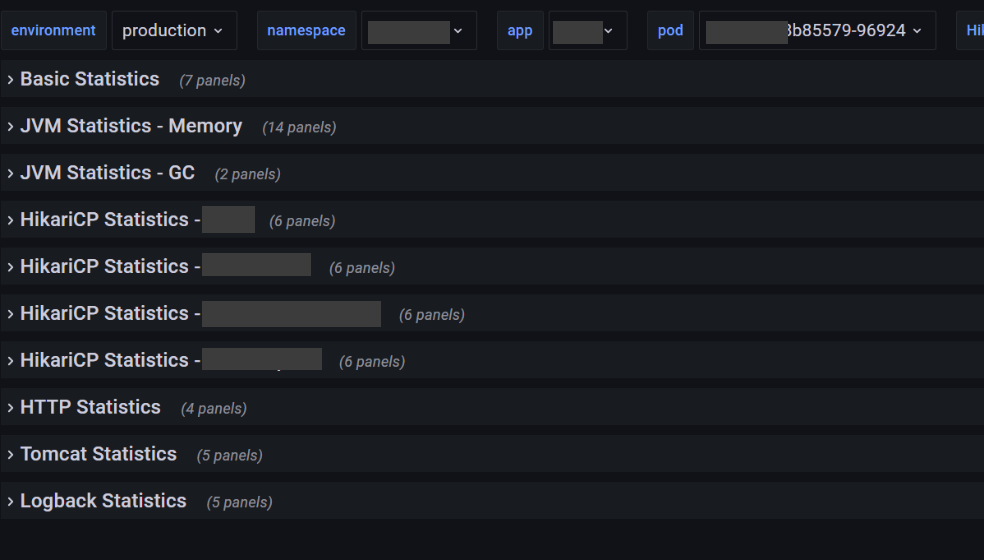
Если метрик становится больше, панели помогут организовать пространство, а также сэкономят ресурсы на загрузке страницы (если вам эти метрики нужны чаще всего по отдельности).
Используйте переменные (с умом)

Можно использовать переменные, чтобы:
отфильтровать конкретные инстансы приложений на графиках;
отфильтровать окружения (prod/stage);
кастомизировать интервалы агрегации.
Одно НО: не превращайте дашборд в суперуниверсальный с помощью этих переменных. Скорее всего, проще разделить дашборды по сервисам, если у них разные технические особенности (CRUD API vs async ETL).
Datasource в переменной
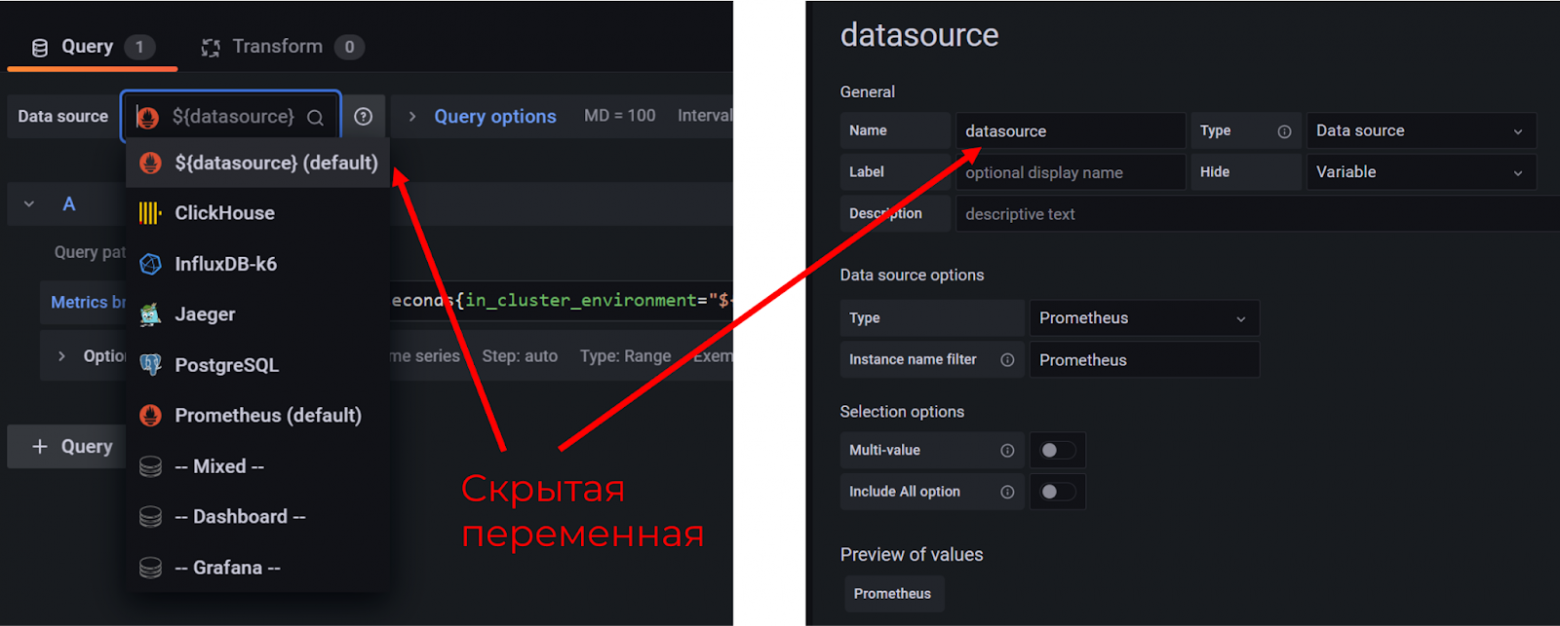
Часто в компании есть несколько датасорсов, откуда подтягиваются метрики для визуализации. Причём даже в рамках одного Prometheus или Influx может быть несколько отдельных инстансов (например, разделение dev vs prod).
Как-то раз мне пришлось переделывать все дашборды (менять имена датасорсов), когда мы переезжали с Prometheus на Victoria Metrics, хотя DSL запросов остался тем же. Мне не особо понравилось, поэтому советую сразу вынести в переменную.
Часть 2. Работа с панелями
Repeat по переменным

В данном примере я разнёс метрики по разным программным пулам (HikariCP) к БД, так как отображать на едином графике не имело никакого смысла — слишком разная бизнес-значимость. Почему по панелям? Потому что внутри каждой панели — около 10 графиков, и в данном случае в каждой панели они автоматически будут показывать данные по конкретному пулу, без необходимости фильтровать информацию по названию.

В случае с API, которых в сервисе может быть 10+ я решил использовать вертикальный repeat. И также через переменную можно выбрать, какие конкретно вы хотите отобразить. Почему не вариант с панелями? Потому что тут всего был нужен 1 график на каждую API. В другом случае можно разделить и иначе.
Горизонтальный repeat аналогичен вертикальному, только позволяет графики располагать друг за другом в одной строке, или — в нескольких, если не влезет в одну. Удобно, когда это показатели в виде отдельных чисел (загрузка памяти, время работы приложения и т. д.) и занимают четверть строки.
Переменные для интервалов агрегации
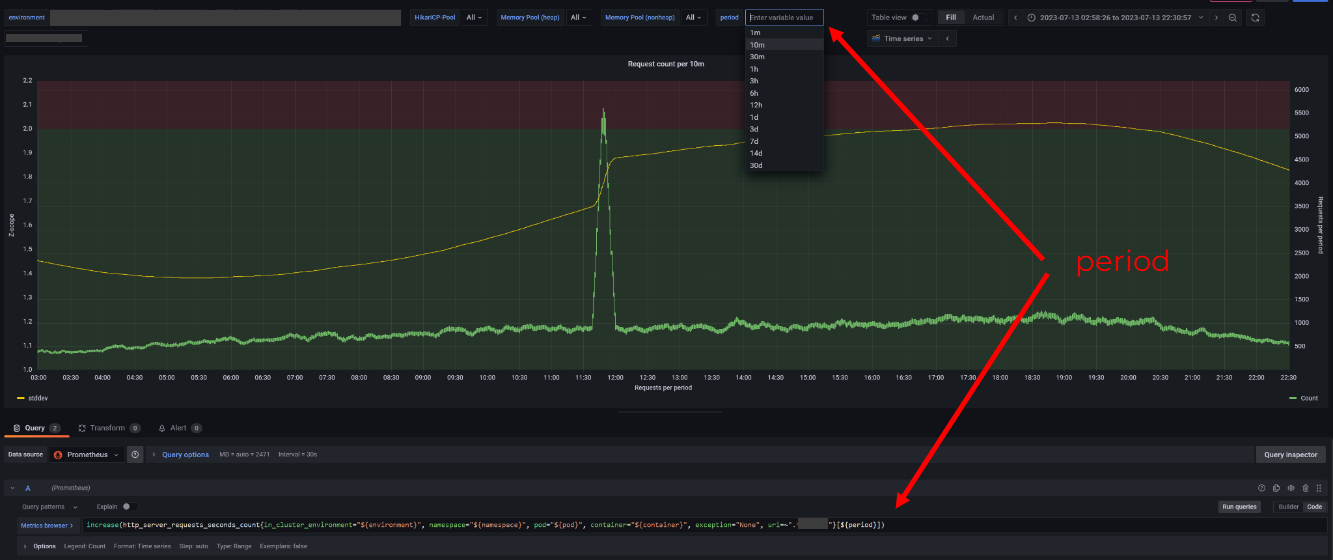
Встроенная переменная $__rate_interval даёт возможность агрегировать сразу по интервалу, который сейчас открыт. Это покрывает только один вариант отображения. Если мы, например, хотим видеть количество запросов за минуту/час/день на недельном графике — вариант с кастомным интервалом даст больше гибкости.
Период агрегации в названии графика
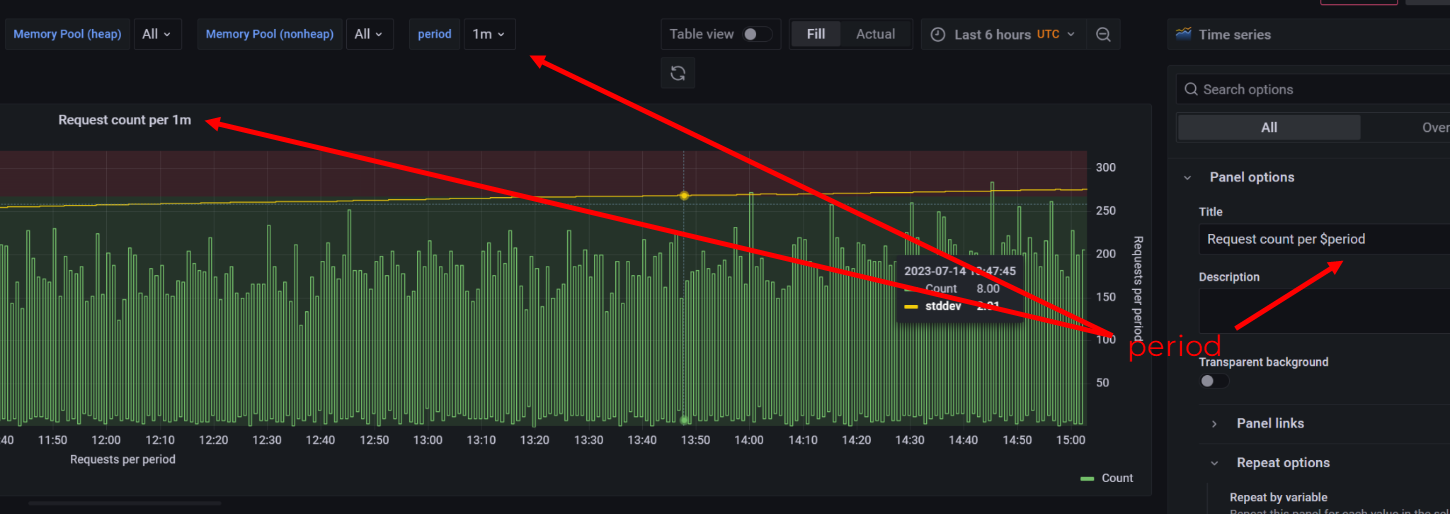
Если вывести период агрегации в название графика, то вы приоткоете завесу тайны без необходимости заходить в Edit (а это ещё и недоступно на read-only дашбордах). Если вы думаете, что в случае RPS метрик это не нужно — то задумайте о том, что RPS вычисляется тоже по среднему за конкретным интервал: минута, час, день, и т. д.
Не заставляйте пользователей графика гадать, что вы имели в виду.
Небольшой интервал для агрегации
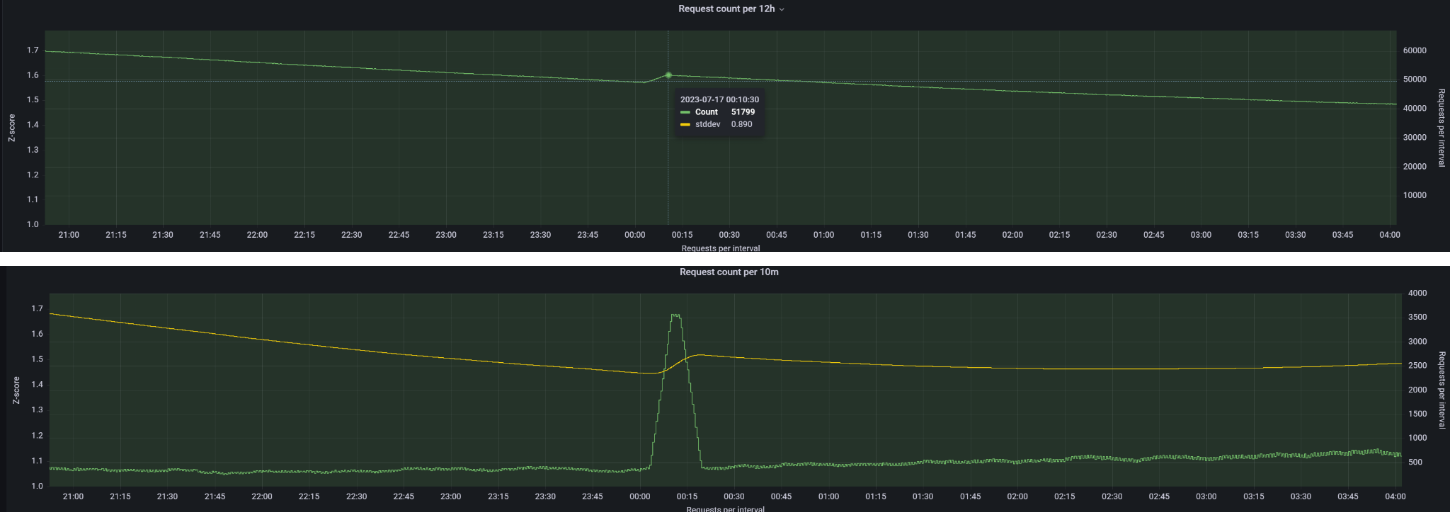
Использование интервала в 12 часов (верхний график) будет сглаживать резкие всплески, и наоборот интервал в десятки минут (как на нижнем графике) будет явно показывать, что идёт некоторое отклонение от стандартной нагрузки.
Лучше, если на такие изменения будут навешены алерты в обоих случаях, чтобы сообщить как о единичных спайках, так и о приросте нагрузки относительно прошлых недель или месяцев.
Часть 3: отображение
Используйте весь набор метрик
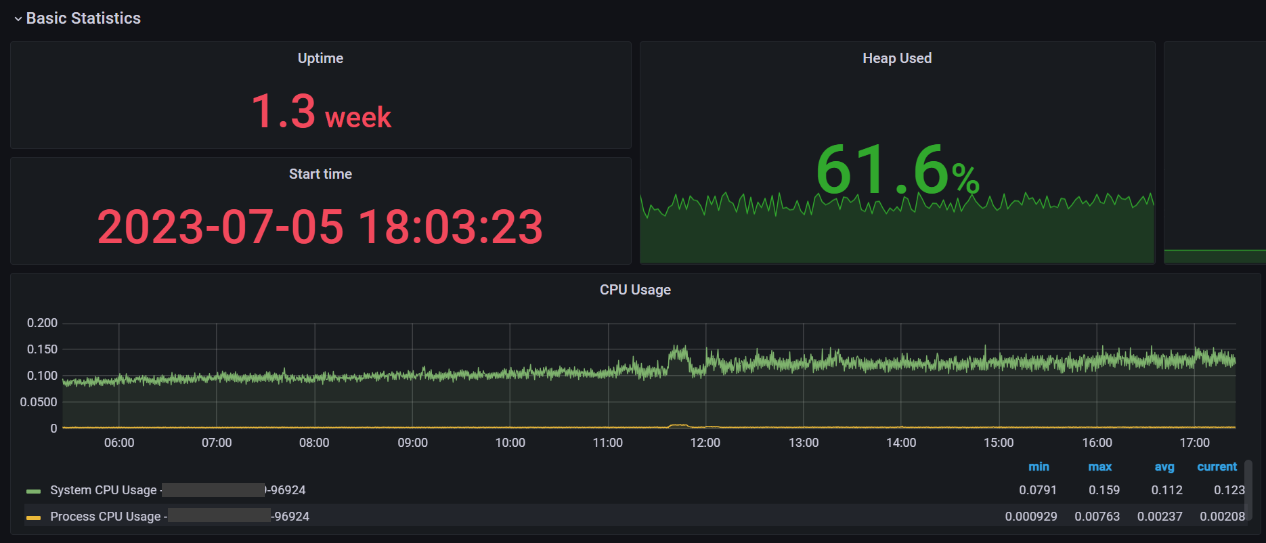
Не стоит всё отрисовывать через Time Series (как CPU Usage на скрине выше). Иногда вам должно быть достаточно актуального/максимального значения или распределения в виде Pie Chart.
Учитывайте порядок значений

Разделяйте графики, если значения сильно отличаются: например, чтение и запись.
Иначе меньшие значения на большом масштабе станут совсем неразличимы.
Устанавливайте абсолютные границы вертикальной оси
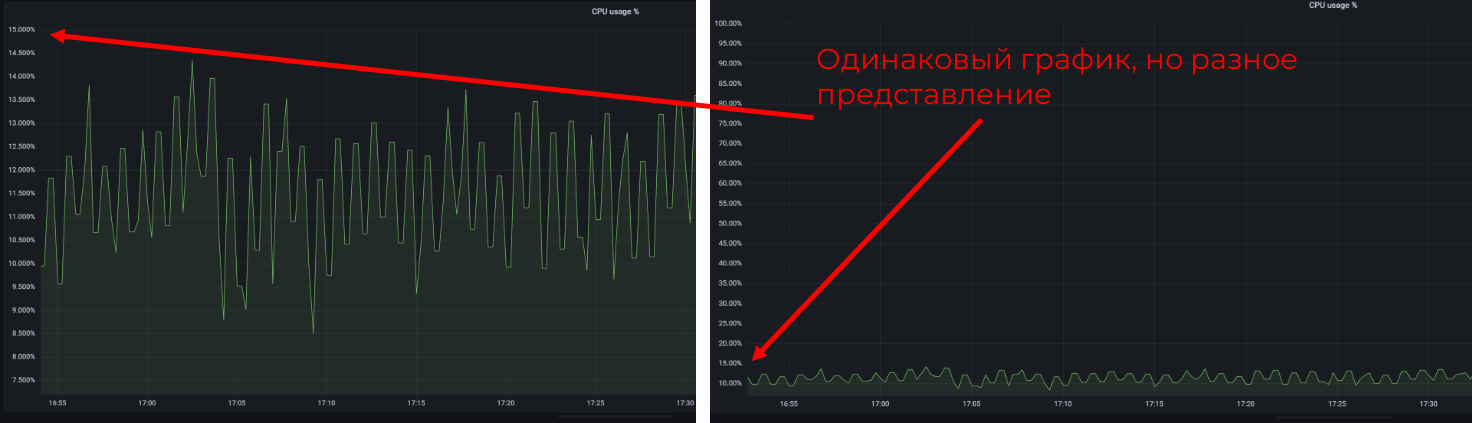
Особенно при работе с процентами вас могут удивить такие перепады на графике. Но, если присмотреться, а ещё лучше — если установить явные границы от 0 до 100, будет явно видно, что всё — в пределах нормы. А если подсветить на правом графике ещё и зону для алертинга, будет вообще пушка.
Stacked time series
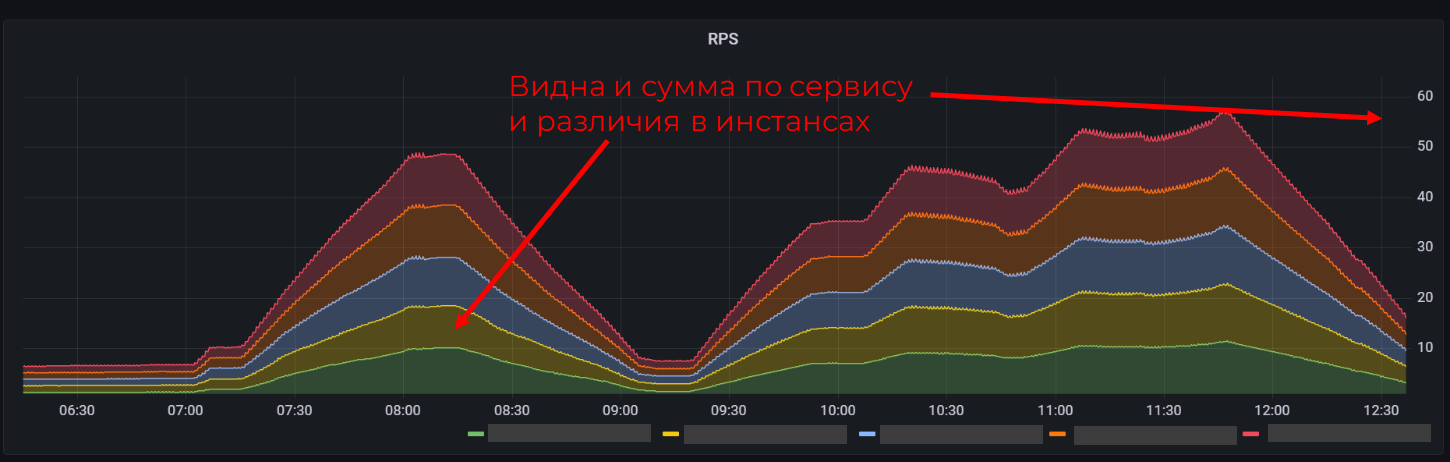
Настройка Stacked позволяет сложить значения всех подов/пулов/серверов и видеть суммарную величину. Удобно видеть общую нагрузку на все инстансы приложения, но не очень удобно проводить сравнение в случае отклонений поведения конкретного объекта (придётся сменить отображение).
Shared Crosshair / Shared Tooltip
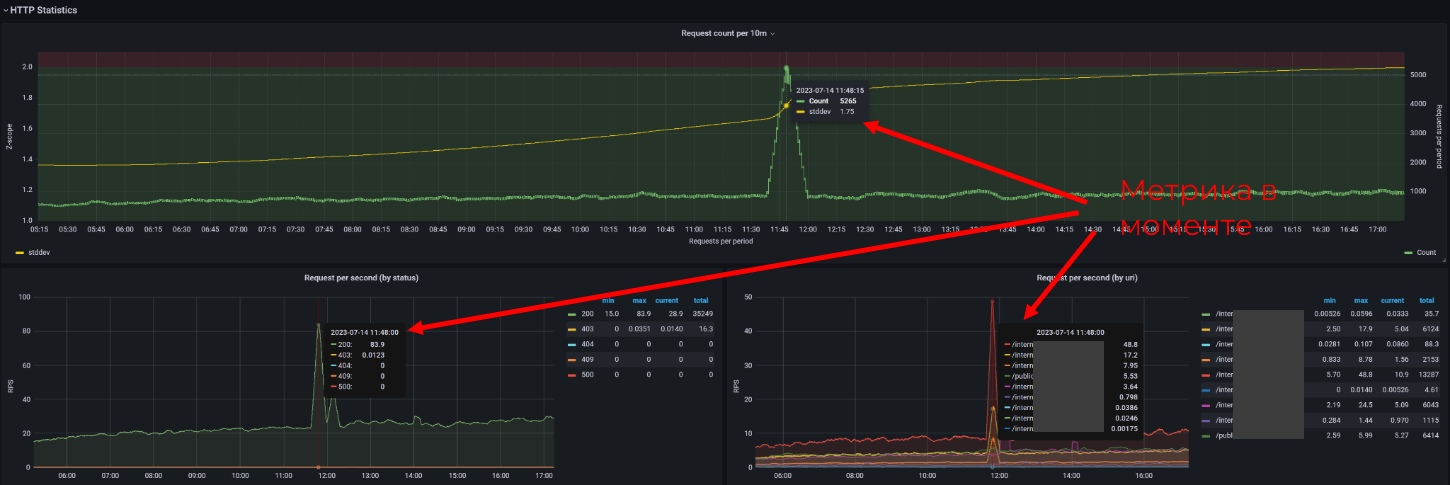
Shared Crosshair настройка тултипа позволяет вам водить курсором на одном графике и видеть сразу значения на других графиках в тот же самый момент времени. Shared Tooltip отображает линию среза, но уже без значений во всплывающем окне.
Очень удобная фича для поиска корреляции между разными показателями.
Нет нужды явно включать на графике Shared Crosshair tooltip, потому что можно использовать hot key (Ctrl+O) и сменить отображение на всём дашборде разом.
Tooltip sort order: Decreasing

Слева на графике включена сортировка значений, справа — нет. При наличии на графике трёх и более серий сортировка становится просто необходима, иначе придётся выискивать значение по цвету на графике. И в целом нет возможности сравнить разброс значений между минимумом и максимумом.
Добавляйте avg/max/pct на один график

Вам будет проще анализировать данные, когда сразу несколько ключевых значений представлены вместе. Например, сравнить конкретный перцентиль с медианой.
Также вместо графика можно вывести это в таблицу с актуальными значениями.
Гистограммы по бакетам не всегда точны
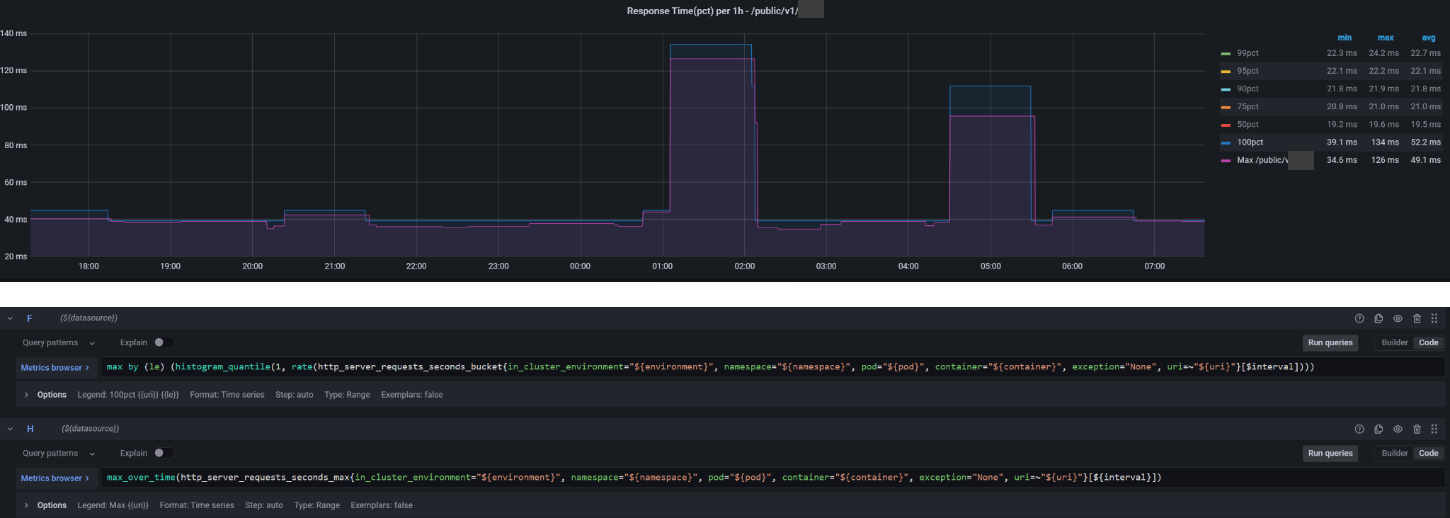
Сравнивая 100-ый перцентиль с максимумом вы сможете найти интересные отклонения, которые могут быть вызваны конфигурацией бакетов в вашем приложении. Если у вас максимальный размер бакета выставлен в 10 секунд, а тайм аут выставлен в 30 секунд, то очень вероятно, что ваш 100-ый перцентиль будет намного ниже ваших максимальных метрик. Поэтому старайтесь вывести бакеты для распределения запросов, исходя из настроек вашего пула.
На графике выше — обратная ситуация, когда максимальное значение ниже, чем 100pct. Опять же — связано это с тем, что значения перцентилей аппроксимируются, так как хранятся не сами значения каждого запроса, а количество запросов, попавших в интервал. Например, от 0 мс до 10 мс, от 10 мс до 30 мс, и т. д. А вот максимальное значение хранится конкретное и не вычисляется.
Для поиска аномалий можно использовать отклонения

Небольшие спайки на графиках не всегда следует рассматривать как что-то плохое и срочно реагировать. Если ваша система довольно волатильна по нагрузке, лучше обратить внимание на формулу поиска отклонения от среднего. Это поможет среагировать, если нагрузка накапливается на протяжении достаточно большого периода, либо скакнула в небо в моменте. Вывести конкретное значение для алерта придётся самостоятельно.
Чуть больше деталей про z-score тут.
Часть 4. Остальное
Чёткий и простой нейминг метрик
Это уже не столько про Grafana сколько про Prometheus.
Не старайтесь запихнуть в имя метрики всё подряд, а лучше договоритесь в команде или командах о формате. Можно, конечно, взять за основу советы из официального гайда от Prometheus.
Вот, что умные люди говорят:
A metric name…
…must comply with the data model for valid characters.
…should have a (single-word) application prefix relevant to the domain the metric belongs to. The prefix is sometimes referred to as namespace by client libraries. For metrics specific to an application, the prefix is usually the application name itself. Sometimes, however, metrics are more generic, like standardized metrics exported by client libraries. Examples:
prometheus_notifications_total (specific to the Prometheus server)
process_cpu_seconds_total (exported by many client libraries)
http_request_duration_seconds (for all HTTP requests)
…must have a single unit (i.e. do not mix seconds with milliseconds, or seconds with bytes).
…should use base units (e.g. seconds, bytes, meters — not milliseconds, megabytes, kilometers). See below for a list of base units.
…should have a suffix describing the unit, in plural form. Note that an accumulating count has total as a suffix, in addition to the unit if applicable.
http_request_duration_seconds
node_memory_usage_bytes
http_requests_total (for a unit-less accumulating count)
process_cpu_seconds_total (for an accumulating count with unit)
foobar_build_info (for a pseudo-metric that provides metadata about the running binary)
data_pipeline_last_record_processed_timestamp_seconds (for a timestamp that tracks the time of the latest record processed in a data processing pipeline)
…should represent the same logical thing-being-measured across all label dimensions.
А если вы используете в разработке инструменты типа Spring Boot Actuator/Micrometer (Java), то и метрики старайтесь именовать в соответствии с форматом уже предоставляемым.
Высокая кардиналити — плохо
Трижды подумайте прежде, чем добавлять какой-нибудь id/name в качестве лейбла для метрики. Если это ограниченный набор значений до 10 элементов, например, названия HTTP методов, или названия БД пулов в приложении — то ок. Но если вы хотите разложить метрики по id юзеров в системе и уже пульнули такой код в прод — советую сразу купить пиво команде, поддерживающей Prometheus, и покаяться. С этих пор ваш сервис будет под бдительным контролем.
По сути каждое уникальное сочетание всех значений лейблов даёт новую серию (аналогия отдельной таблице в БД).
Небольшой пример расчёта — ниже на скрине. Если коротко, то 100 000 — это рекомендуемое максимальное значение. Но на слабеньких окружениях оно может быть ещё меньше. Также не забывайте, что это влияет и на скорость вычисления различных функций. Вы же не хотите ловить таймауты при попытке открыть страницу с дашбордом?

Меняйте через json

Если надо массово внести изменения во все графики на дашборде, используйте редактор json и делайте replace. Сэкономите пару минут, а, может, и часов, пытаясь добавить сортировку ко всем графикам или поменять цветовую схему.
Аннотации для отслеживания деплоев
Просто первая картинка из интернета…
В Grafana можно создавать аннотации на конкретные события. Лучше, конечно, интегрировать установку этих аннотаций в ваш CI/CD. Это позволит не только видеть на конкретных дашбордах релизы сервисов, но и поможет сделать единый дашборд с релизами.
Также можно аннотировать время запуска перфтестов, и так далее. Чтобы потом не вспоминать, почему в это время метрики сильно скакали.
Добавляйте ссылки на детальные дашборды, логи

Можно организовать пространство команды и перечислить все используемые дашборды, ссылки на отображение логов, и др.
Просто, удобно и в одном месте.
Напоследок
И пара советов уже в целом про мониторинг:
Проводите командное ревью дашбордов для мониторинга. Любой мониторинг должен быть прозрачным и понятным для того, кто им будет пользоваться.
Не изобретайте велосипед, пытаясь отправить в хранилище метрик инфу из логов (graylog/kibana дают возможность построить свои дашборды). Пользуйтесь всем ассортиментом инструментов, который для этого создавался: логи, трейсы.
Собирайте дашборды под конкретные цели. Нужно состояние всей платформы, конкретного сервиса, или вы разбираетесь с инцидентом на проде? Это три совершенно разных сценария, которые в идеале должны покрываться тремя разными дашбордами.
Делитесь информацией о ваших командных мониторингах и фиксируйте описания на командных страницах. У соседних команд могут быть полезные данные, которые вам помогут увидеть всю картину целиком. Например, команды OPS/DBA могут поделиться с командами разработки данными о состоянии БД, кафки и прочих инфраструктурных инструментов, что критически важно.
Ну, и приложу список ссылок из статьи для дополнительного ознакомления:
