Мониторинг Postgresql: запросы
 В 2008 году в списке рассылки pgsql-hackers началось обсуждение расширения по сбору статистики по запросам. Начиная с версии 8.4 расширение pg_stat_statements входит в состав постгреса и позволяет получать различную статистику о запросах, которые обрабатывает сервер.
В 2008 году в списке рассылки pgsql-hackers началось обсуждение расширения по сбору статистики по запросам. Начиная с версии 8.4 расширение pg_stat_statements входит в состав постгреса и позволяет получать различную статистику о запросах, которые обрабатывает сервер.
Обычно это расширение используется администраторами баз данных в качестве источника данных для отчетов (эти данные на самом деле являются суммой показателей с момента сброса счетчиков). Но на основе этой статистики можно сделать мониторинг запросов — посмотреть на статистику во времени. Это оказывается крайне полезно для поиска причин различных проблем и в целом для понимания, что происходит на сервере БД.
Я расскажу, какие метрики по запросам собирает наш агент, как мы их группируем, визуализируем, так же расскажу о некоторых граблях, по которым мы прошли.
pg_stat_statements
Итак, что же у нас есть во view pg_stat_statements (мой пример из 9.4):
postgres=# \d pg_stat_statements;
View "public.pg_stat_statements"
Column | Type | Modifiers
---------------------+------------------+-----------
userid | oid |
dbid | oid |
queryid | bigint |
query | text |
calls | bigint |
total_time | double precision |
rows | bigint |
shared_blks_hit | bigint |
shared_blks_read | bigint |
shared_blks_dirtied | bigint |
shared_blks_written | bigint |
local_blks_hit | bigint |
local_blks_read | bigint |
local_blks_dirtied | bigint |
local_blks_written | bigint |
temp_blks_read | bigint |
temp_blks_written | bigint |
blk_read_time | double precision |
blk_write_time | double precision |Здесь все запросы сгруппированы, то есть статистику мы получаем не по каждому запросу, а по группе одинаковых с точки зрения pg запросов (я расскажу про это подробнее). Все счетчики растут с момента старта или с момент сброса счетчиков (pg_stat_statements_reset).
- query — текст запроса
- calls — количество вызовов запроса
- total_time — сумма времен выполнения запроса в миллисекундах
- rows — количество строк возвращенных (select) или модифицированных в ходе запроса (update)
- shared_blks_hit — количество блоков разделяемой памяти, полученное из кэша
shared_blks_read — количество блоков разделяемой памяти, прочитанное не из кэша
В документации не очевидно, это суммарное количество прочитанных блоков или только то, что не нашлось в кэше, проверяем по коду/* * lookup the buffer. IO_IN_PROGRESS is set if the requested block is * not currently in memory. */ bufHdr = BufferAlloc(smgr, relpersistence, forkNum, blockNum, strategy, &found); if (found) pgBufferUsage.shared_blks_hit++; else pgBufferUsage.shared_blks_read++;- shared_blks_dirtied — количество блоков разделяемой памяти, промаркированных как «грязные» в ходе запроса (запрос изменил хотя бы один кортеж в блоке и данный блок необходимо записать на диск, это делает или checkpointer или bgwriter)
- shared_blks_written — количество блоков разделяемой памяти записанное на диск синхронно в процессе обработки запроса. Постгрес пытается синхронно записать блок, если он уже вернулся «грязным».
- local_blks — аналогичные счетчики для локальных с точки зрения backend блоков, используются для временных таблиц
- temp_blks_read — количество блоков временных файлов считанных с диска.
Временные файлы используются для обработки запроса когда не хватает памяти, ограниченной настройкой work_mem - temp_blks_written — количество блоков временных файлов записанных на диск
- blk_read_time — сумма времени ожидания чтения блоков миллисекундах
- blk_write_time — сумма времени ожидания записи блоков на диск в миллисекундах (учитывается только синхронная запись, время затраченное checkpointer/bgwriter здесь не учитывается)
blk_read_time и blk_write_time собираются только при включенной настройке track_io_timing.
Отдельно стоит отметить, что в pg_stat_statements попадают только завершенные запросы. То есть, если у вас какой-то запрос уже час делает что-то тяжелое и до сих пор не закончился, его будет видно только в pg_stat_activity.
Как группируются запросы
Я долгое время считал, что запросы группируются по реальному плану выполнения. Смущало только то, что запросы с разным количеством аргументов в IN отображаются отдельно, план то у них должен быть одинаковый.
В коде видно, что на самом деле берется хэш от «значимых» частей запроса после синтаксического разбора. Начиная с 9.4 он выводится в колонке queryid.
На практике нам приходится дополнительно нормализовывать и группировать запросы уже в агенте. Например, разное количество аргументов в IN мы схлопываем в один плейсхолдер »(?)». Или аргументы, которые прилетели в pg заинлайнеными в запрос мы сами заменяем на плейсхолдеры. Задача усложняется еще и тем, что текст запроса может быть не полным.
До 9.4 текст запроса обрезается до track_activity_query_size, c 9.4 текст запроса хранится вне разделяемой памяти и ограничение убрали, но мы в любом случае обрезаем запрос до 8Кб, так как если в query лежат очень увесистые строки, запросы от агента ощутимо нагружают постгрес.
Из-за этого мы не можем разобрать запрос парсером SQL для дополнительной нормализации, вместо этого пришлось написать набор регулярных выражений для дополнительной зачистки запросов. Это не очень удачное решение, так как постоянно приходится добавлять новые сценарии, но ничего лучше пока придумать не удалось.
Еще одна проблема в том, что в поле query постгрес записывает первый пришедший запрос в группе до нормализации с сохранением исходного форматирования, и если счетчики сбросить, запрос может быть другим для той же группы. Ещё очень часто разработчики используют комментарии в запросах, например для указания названия функции, которая дергает этот запрос или ID пользовательского запроса), они в query тоже сохраняются.
Для того, чтобы не плодить каждый раз новые метрики для одних и тех же запросов, мы вырезаем коментарии и лишние whitespace символы.
Постановка задачи
Мониторинг постгреса мы делали с помощью наших друзей из postgresql consulting. Они подсказывали, что самое полезное при поиске проблем с базой, какие метрики не особо полезны и консультировали по внутренностям postgresql.
В итоге мы хотим получать от мониторинга ответы на следующие вопросы:
- как сейчас работает БД в целом по сравнению с другим периодом
- какие запросы нагружают сервер (cpu, диски)
- каких запросов сколько
- какие времена выполнения разных запросов
Собираем метрики
На самом деле лить счетчики по всем запросам в мониторинг достаточно дорого. Мы решили, что нас интересует только TOP-50 запросов, но нельзя просто взять top по total_time, так как если у нас появится новый запрос, его total_time еще долго будет догонять старые запросы.
Мы решили брать top по производной (rate) total_time за минуту. Для этого раз в минуту агент вычитывает pg_stat_statements целиком и хранит предудущие значения счетчиков. По каждому счетчику каждого запроса вычисляется rate, потом мы пытаемся дополнительно объединить одинаковые запросы, которые pg посчитал разными, их статистики суммируются. Дальше берем top, по ним делаем отдельные метрики, остальные запросы суммируем в некий query=»~other».
В итоге мы получаем 11 метрик для каждого запроса из топа. Каждая метрика имеет набор уточняющих параметров (меток):
{"database": "", "user": "", "query": ""} - postgresql.query.time.cpu (мы просто вычли из total_time времена ожидания диска для удобства)
- postgresql.query.time.disk_read
- postgresql.query.time.disk_write
- postgresql.query.calls
- postgresql.query.rows
- postgresql.query.blocks.hit
- postgresql.query.blocks.read
- postgresql.query.blocks.written
- postgresql.query.blocks.dirtied
- postgresql.query.temp_blocks.read
- postgresql.query.temp_blocks.written
Интерпретируем метрики
Очень часто у пользователей появляются вопросы о физическом смысле метрик «postgresql.query.time.*». Действительно, не особо понятно, что показывает сумма времен ответов, но такие метрики обычно хорошо показывают соотношение каких-то процессов между собой.
Но если мы договоримся не брать во внимание блокировки, можно очень грубо предположить, что в течении всего времени обработки запроса постгрес утилизирует какой-то ресурс (процессор или диск). Такие метрики имеют размерность: количество потраченных ресурсных секунд в секунду. Можно еще привести это к процентам утилизации запросом процессорного ядра, если умножить на 100%.
Смотрим, что получилось
Прежде чем полагаться на метрики, нужно проверить, правду ли они показывают. Например попробуем разобраться, что вызывает увеличение количества операций записи на сервере БД:
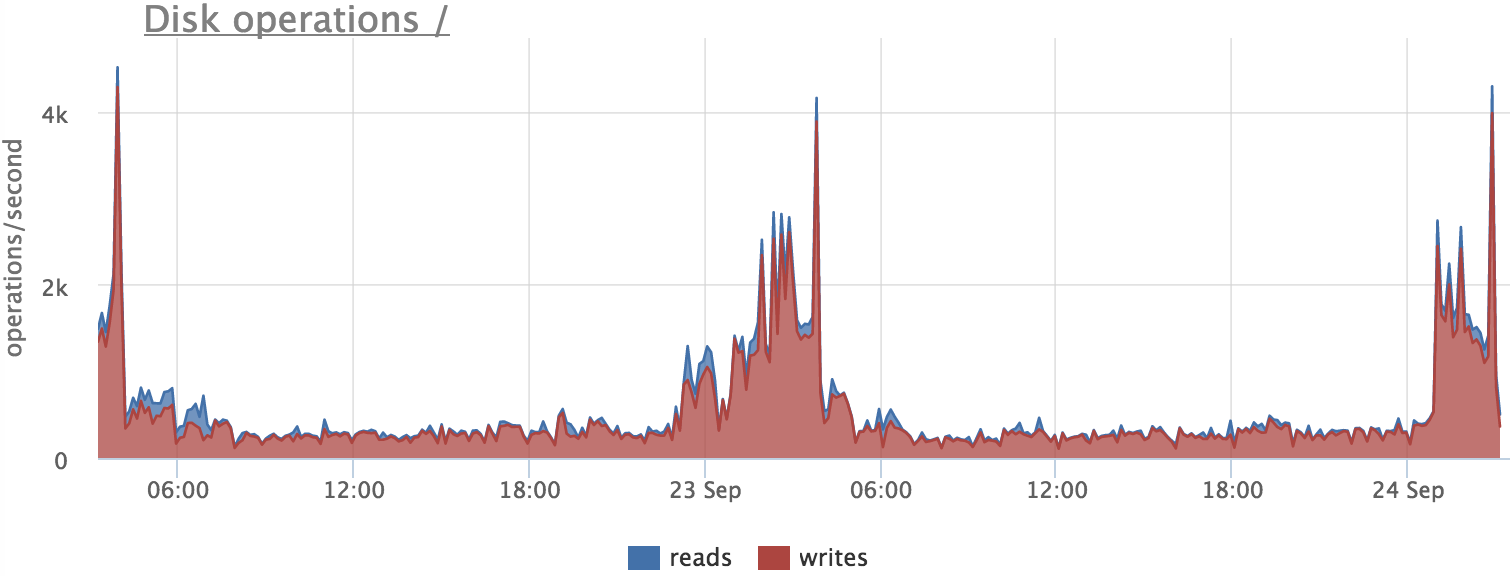
Смотрим, писал ли постгрес на диск в это время:
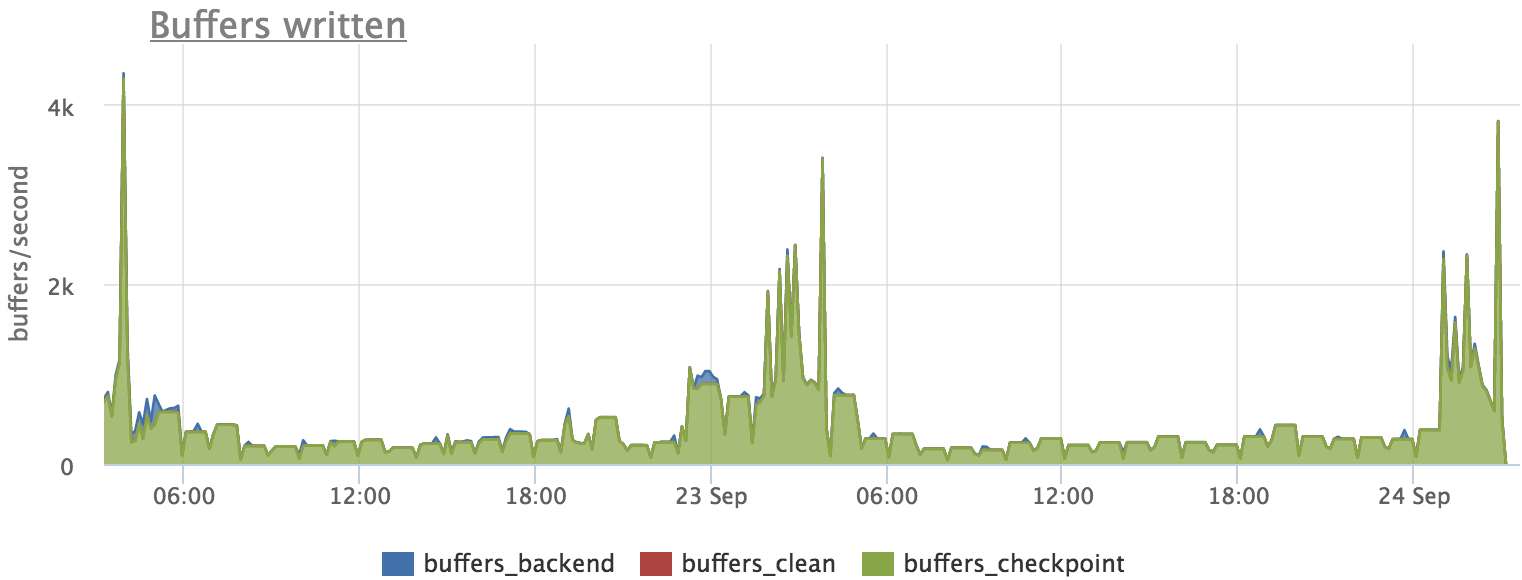
Дальше выясняем, какие запросы «пачкали» страницы:
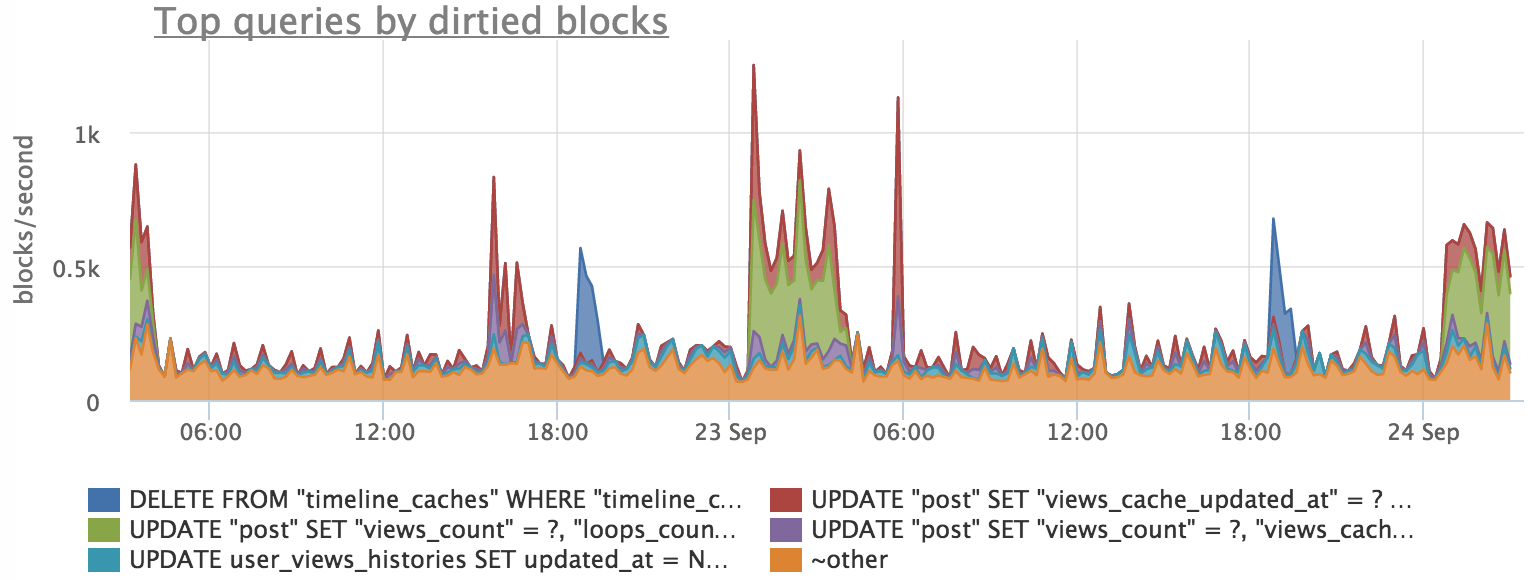
Видим, что есть примерное совпадение, но график по запросам в точности не повторяет график сброса буферов. Это вызвано тем, что процесс записи блоков происходит в фоне и при этом профиль нагрузки на диск немного меняется.
Теперь посмотрим, какая картина у нас получилась с чтением:
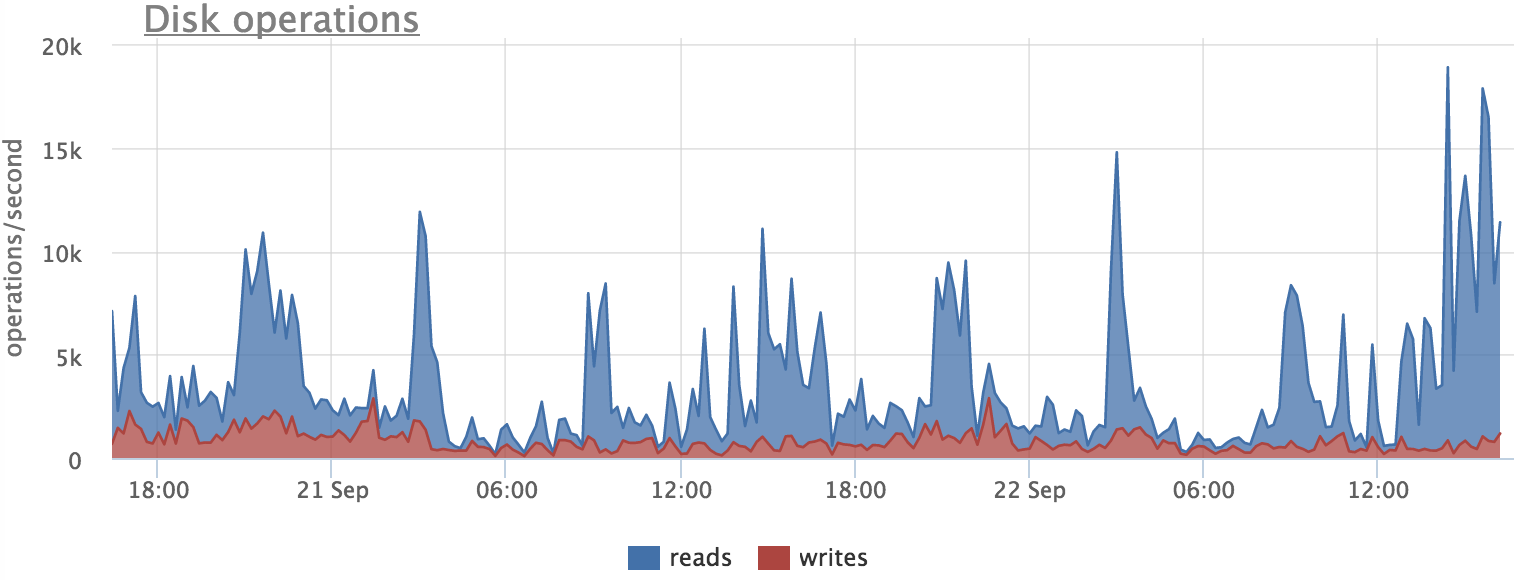
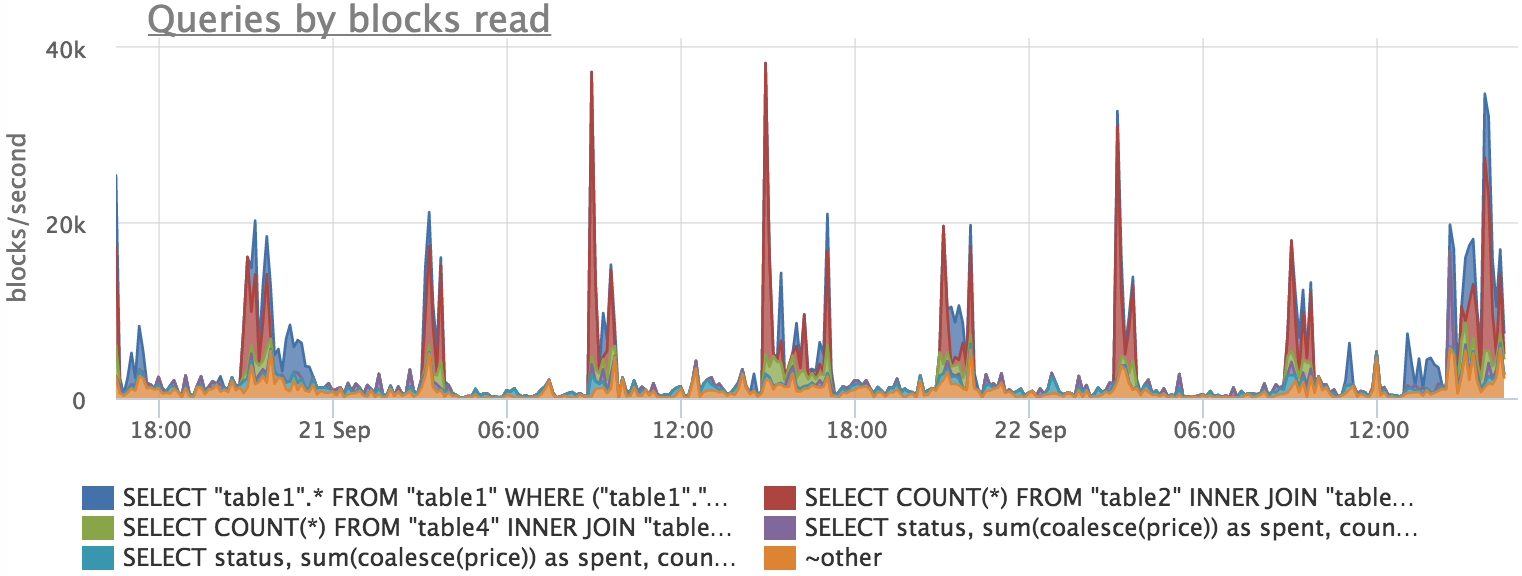
Здесь мы тоже видим, что корреляция есть, но точного совпадения нет. Это можно объяснить тем, что постгрес читает блоки с диска не напрямую, а через кэш файловой системы. Таким образом мы не видим часть нагрузки на диск, так как чаcть блоков читается из кэша.
Утилизацию процессора тоже можно объяснить конкретными запросами, но абсолютной точности ожидать не приходится, так как есть ожидания различных локов итд:
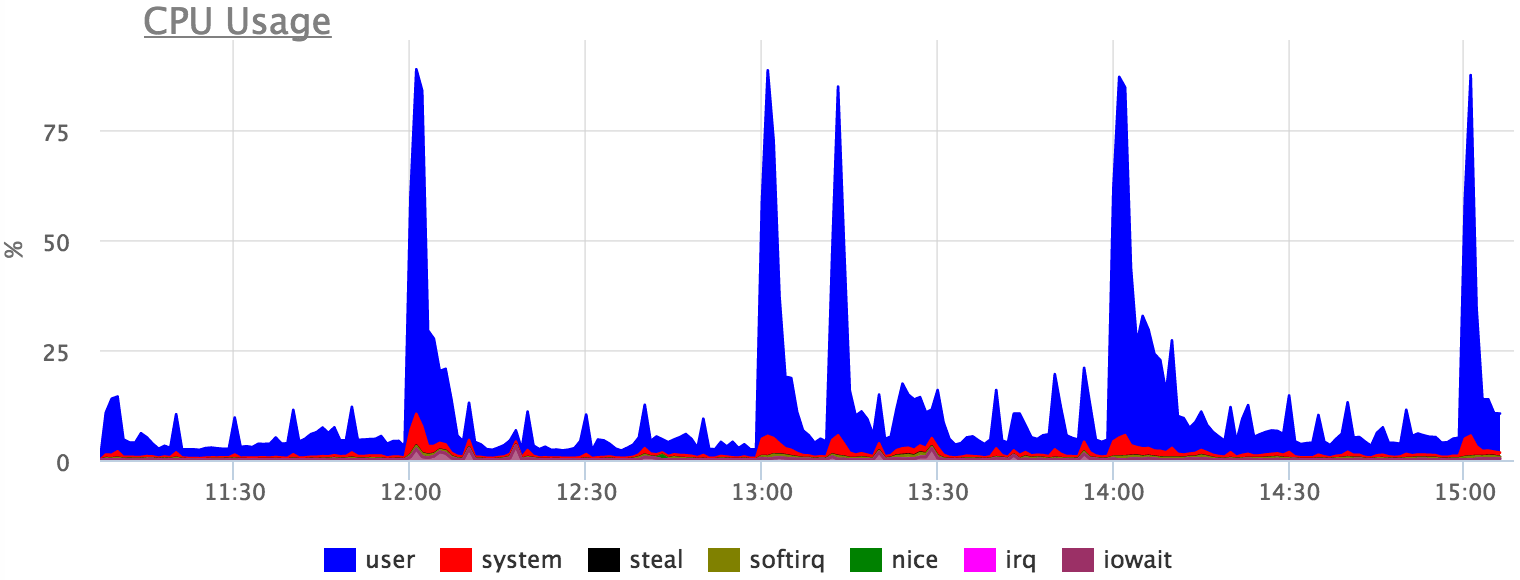
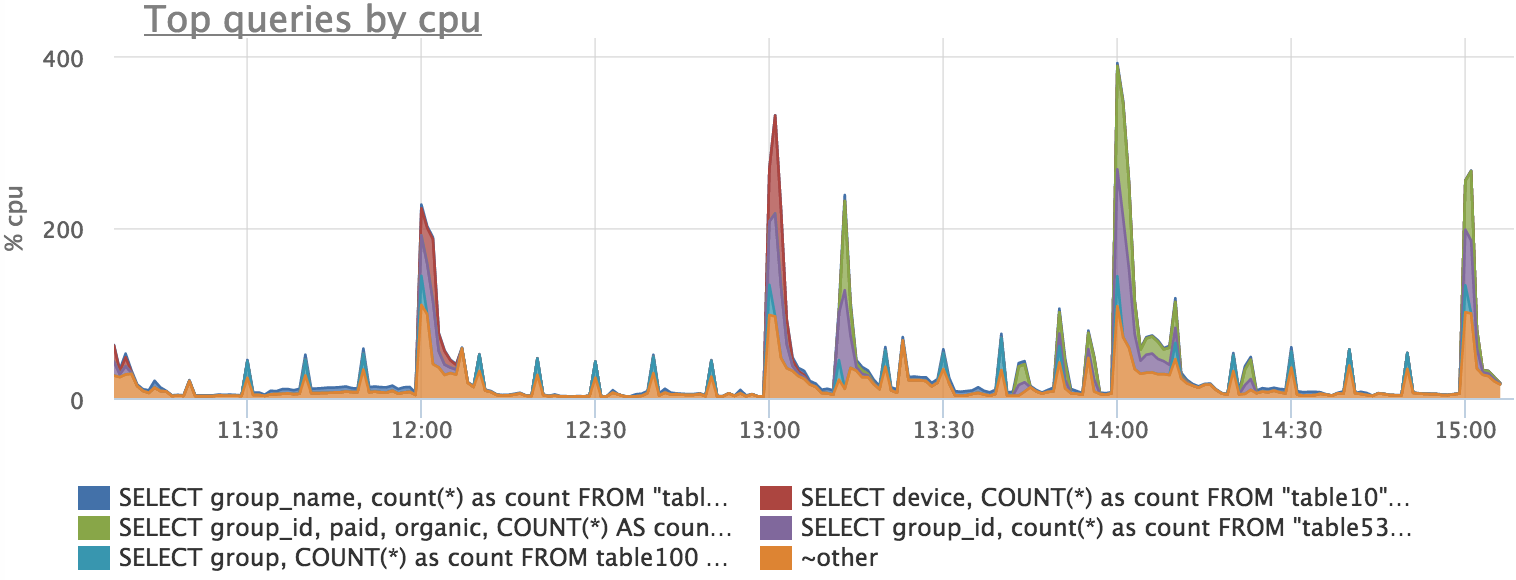
Итого
- pg_stat_statements очень крутая штука, которая дает подробную статистику, но при этом не убивает сервер
- есть ряд допущений и неточностей, их нужно понимать для правильной интерпретации метрик
На нашем демо стенде есть пример метрик по запросам, но нагрузка там не очень интересная и лучше посмотреть это на ваших метриках (у нас есть бесплатный, ни к чему не обязывающий двухнедельный триал)
Комментарии (2)
 Envek
Envek
30 сентября 2016 в 11:56
0↑
↓
Спасибо вам за okmeter — очень помогает при оптимизации работы приложения с БД.
График Top queries by CPU — самый первый багор пожарного DBA (ну или кого там призвали в дружину огнеборцев за неимением оного). NikolaySivko
NikolaySivko
30 сентября 2016 в 12:03
+1↑
↓
Приятно слышать, что мы полезны:) Cпасибо!
