Мониторинг ИИ-систем. Часть 2
В жизни ИИ-системы, медицинской или любой другой, случаются неудачные моменты.
Часть таких ситуаций — непредвиденные ошибки. Да, все разработчики понимают, что рано или поздно что-то пойдёт не так, но случается это всегда по-разному и иногда в самые неподходящие моменты.
К примеру, неправильно заполненный тег части тела в DICOM-файле и некорректная работа модели по фильтрации снимков может привести к возникновению пневмоторакса в стопе:
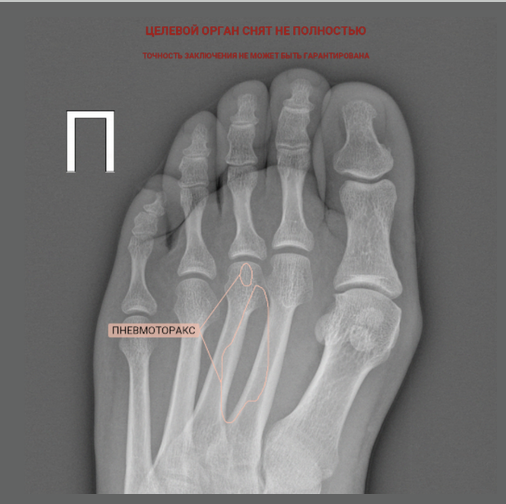
Лёгкая поступь
Если вы хотите узнать ещё больше об организации процессов ML-разработки, подписывайтесь на наш Телеграм-канал Варим ML
Часть ошибок — вполне себе ожидаемые. Не зря в регистрационном удостоверении любого ИИ-медизделия указаны какие-то характеристики (точность, чувствительность, специфичность), и они не равны единице. Более того, ошибки обычно хорошо кластеризуются по категориям. К примеру, одна из первых версий систем по ишемии часто давала ложноположительные срабатывания на кистозно-глиозных изменениях.
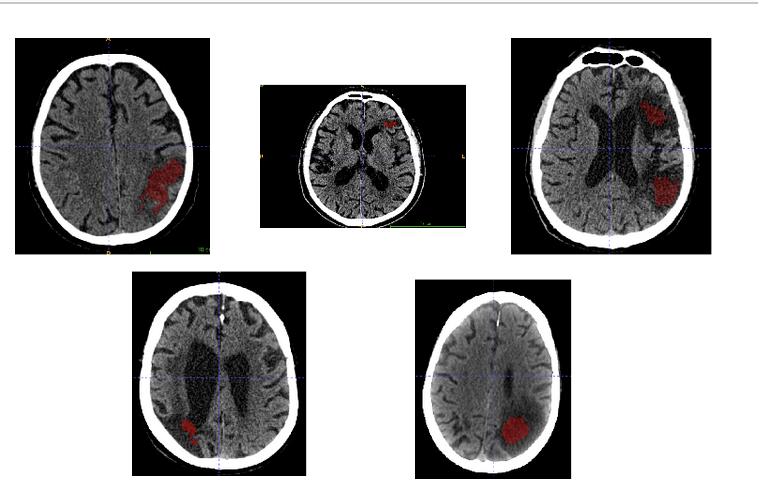
Ложная тревога
А иногда проблемы возникают не из-за самой ИИ-системы, а из-за изменения свойств входных данных. Распространённый случай — подключение нового оборудования к той же модели.
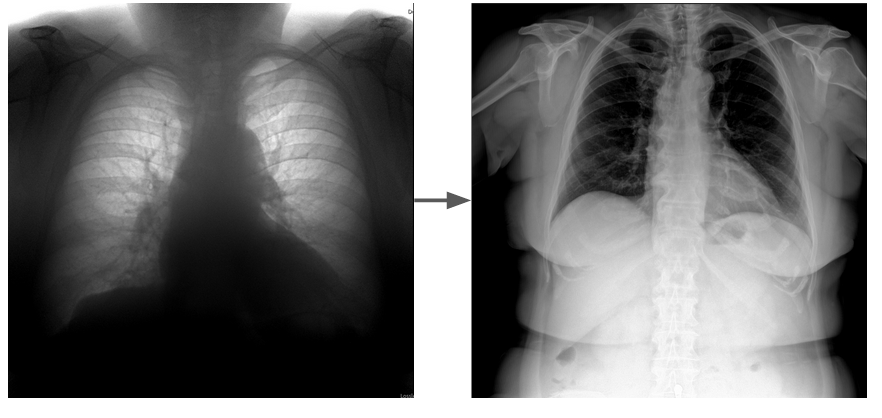
Слева — типичный вход модели ФЛГ, справа — новичок
Помочь в таких ситуациях может мониторинг работы ML-системы на стороне производителя. Грамотно организованный мониторинг позволяет быстрее реагировать на инциденты, получать информацию о неожиданных бизнес-событиях (например, нам забыли сообщить о подключении новой больницы), генерировать новые гипотезы по улучшению и выбирать данные для доразметки.
Давай разбираться, где конкретно могут возникнуть проблемы, какой вид мониторинга может помочь в каждом случае, и какие инструменты можно применять.

Технический мониторинг

В первую очередь любая ML-система — это программное обеспечение. Соответственно ей свойственны все проблемы, которые могут возникать в работе ПО:
Ошибки при выполнении кода — они же баги.
Проблемы с железом — сгорела видюха, уборщица вырвала провод.
Увеличилась нагрузка на систему, выросло среднее или пиковое количество запросов — соответственно, просела скорость работы системы (latency и/или throughput).
То есть, нам нужны инструменты, которые позволят получать алерты о багах, отслеживать время обработки, утилизацию разных железных ресурсов и получать статистику о количестве разных ошибок при обработке запросов по их видам. Классические ошибки — значит и инструменты можно использовать классические.
Инструменты в вакууме могут сделать только хуже — нужен понятный процесс, кто и как их использует. Например:
Автоматические алерты — должны появляться только в том случае, если с какой-то вероятностью нужна реакция.
Регулярный мониторинг — с какой-то периодичностью определённый человек или команды осуществляют мониторинг.
Ситуационный мониторинг — в этом случае инструменты используются для анализа и поиска причин проблем, о которых сообщили внешние или внутренние клиенты сервиса.
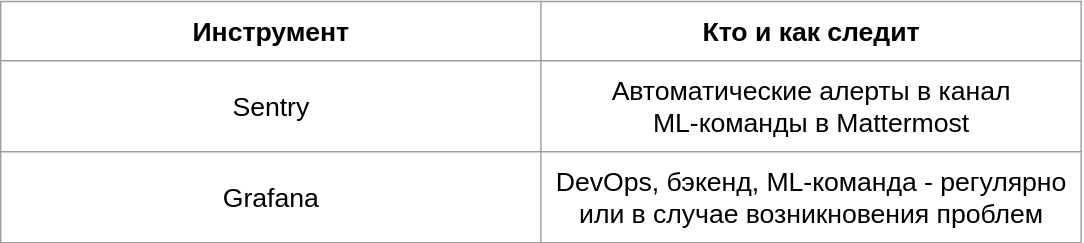
Примеры инструментов для технического мониторинга
Sentry — мой любимый инструмент ещё с 2014 года, особенно в паре с интеграцией в мессенджер. У каждой команды есть свой канал для алертов в Маттермосте, и прям там можно обсудить ошибку и какие действия нужно предпринять. Отдельно отмечу раздел Performance, который позволяет анализировать время работы разных компонентов системы.
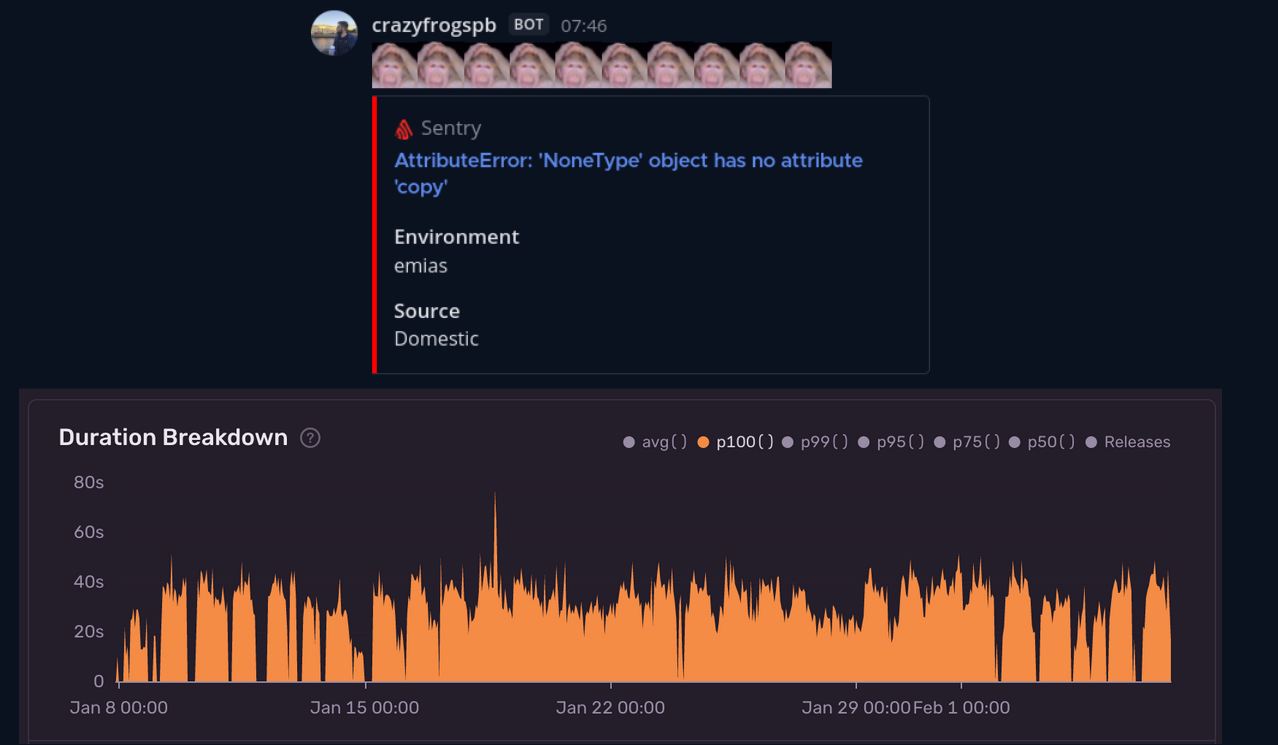
Sentry
Ещё одна классика — Grafana, которая может кушать информацию из самых разных источников — например, из Prometheus и ElasticSearch. Подходит как для железного мониторинга, так и для сбора статистики о предсказаниях.
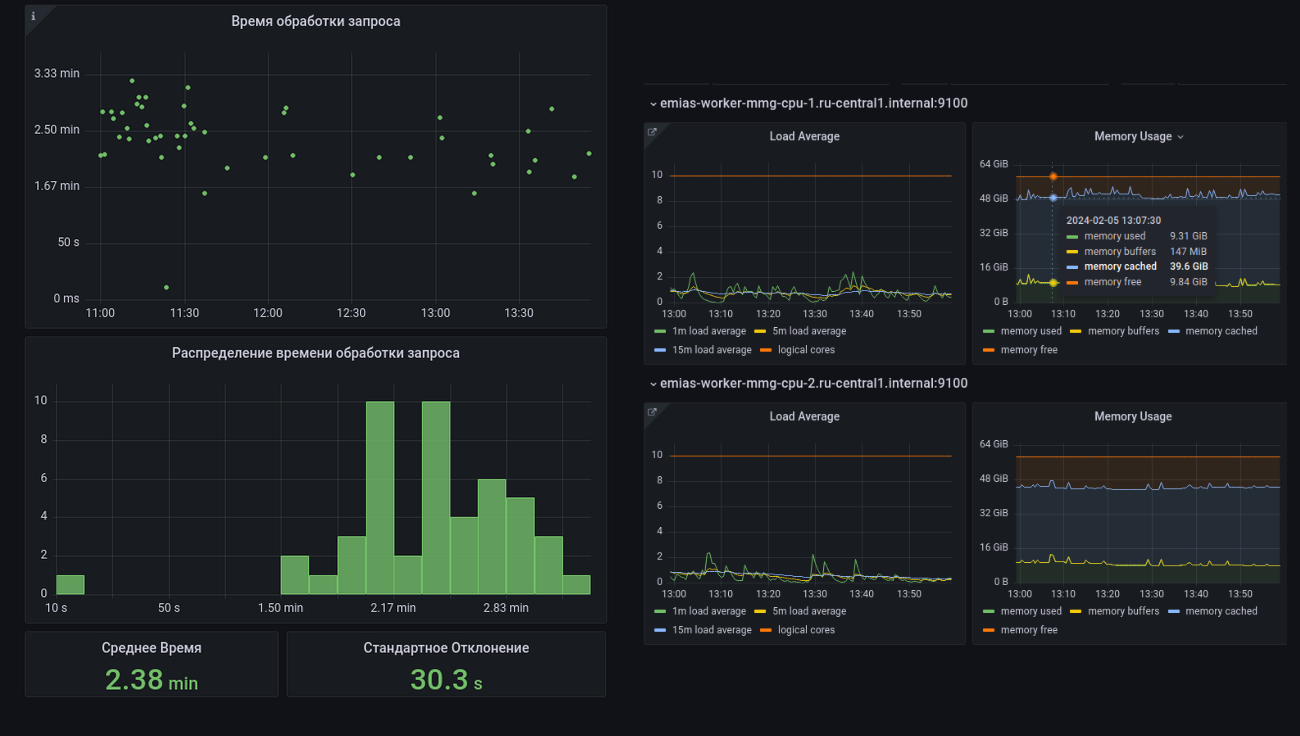
Grafana
Мониторинг выбросов и качества данных

Следующее тонкое место и время — это оборудование и его работа в момент проведения исследования. Термины тут можно использовать разные — выбросы, OoD-сэмплы, но суть не меняется — иногда в нашу систему попадают данные, которые мы не ожидаем увидеть, и на которых система не обучалась или почти не обучалась. Такие данные могут появиться по самым разным причинам:
Работа оборудования — дефекты, артефакты, неправильные настройки.
Работа лаборанта — некорректная укладка пациента, неверно заполненные теги.
Сам пациент — невыполнение указаний лаборанта, особенности анатомии, наличие инородных тел.
Есть два основных способа обнаружения таких сэмплов данных:
Uncertainty estimation — оценка уверенности модели в своём предсказании. Тут есть куча способов — от простейших (расчёт дисперсии по предсказанным вероятностям классов) до сложных, требующих изменения архитектуры модели или нескольких прогонов исследования через сетку.
Логирование и детекция аномалий — логируем различные значения, которые появляются в ходе работы нашей системы, например, DICOM-теги, промежуточные значения (объёмы сегментированных целевых органов, яркость изображения) и предсказания системы. И сверху навешиваем какую-нибудь детекцию аномалий — да хоть алерты по порогам значений.

Здесь помимо команд разработки очень велика роль медицинского консультанта, прикреплённого к команде. Во многих случаях только врач может помочь понять, что такое вообще изображено на картинке.
С точки зрения инструментов тут отлично справляется всё тот же Sentry — если при обработке исследования сработало одно из правил, посылаем алерт. В зависимости от ситуации при этом обработка либо продолжается, либо клиенту сразу отдаётся ошибка.
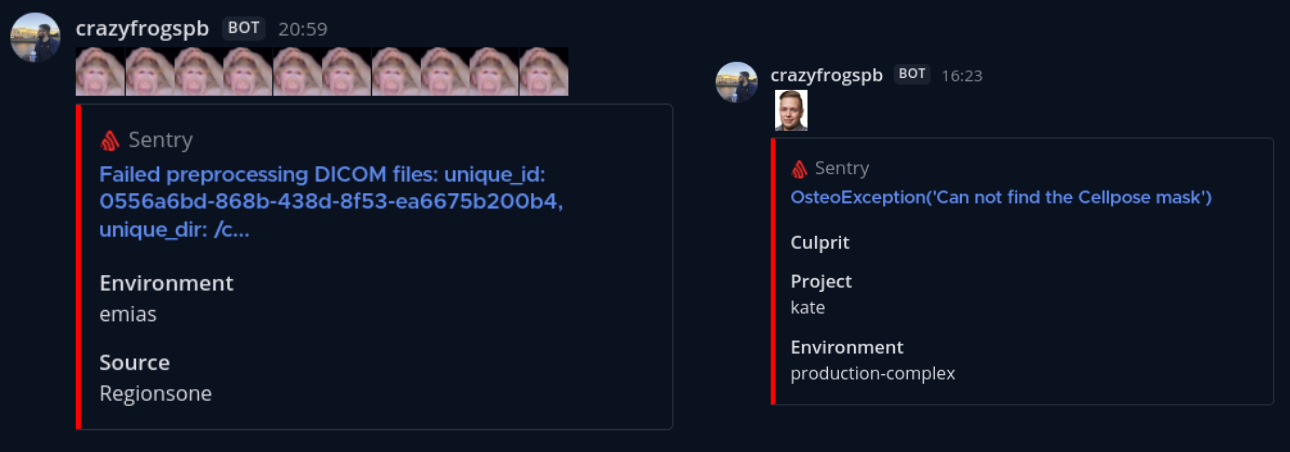
Кликнув на такой алерт, можно провалиться в Сентри и узнать айдишник исследования, который в свою очередь можно ввести на нашей платформе, сделанной на Streamlit. Он найдёт это исследование среди всех БД и даст ссылку на веб-вьюер.

Примеры выбросов, связанные с пациентом и с дефектами оборудования
Иногда исследование не является дефективным или редким, но модель при обучении не сталкивалась с такими картинками.
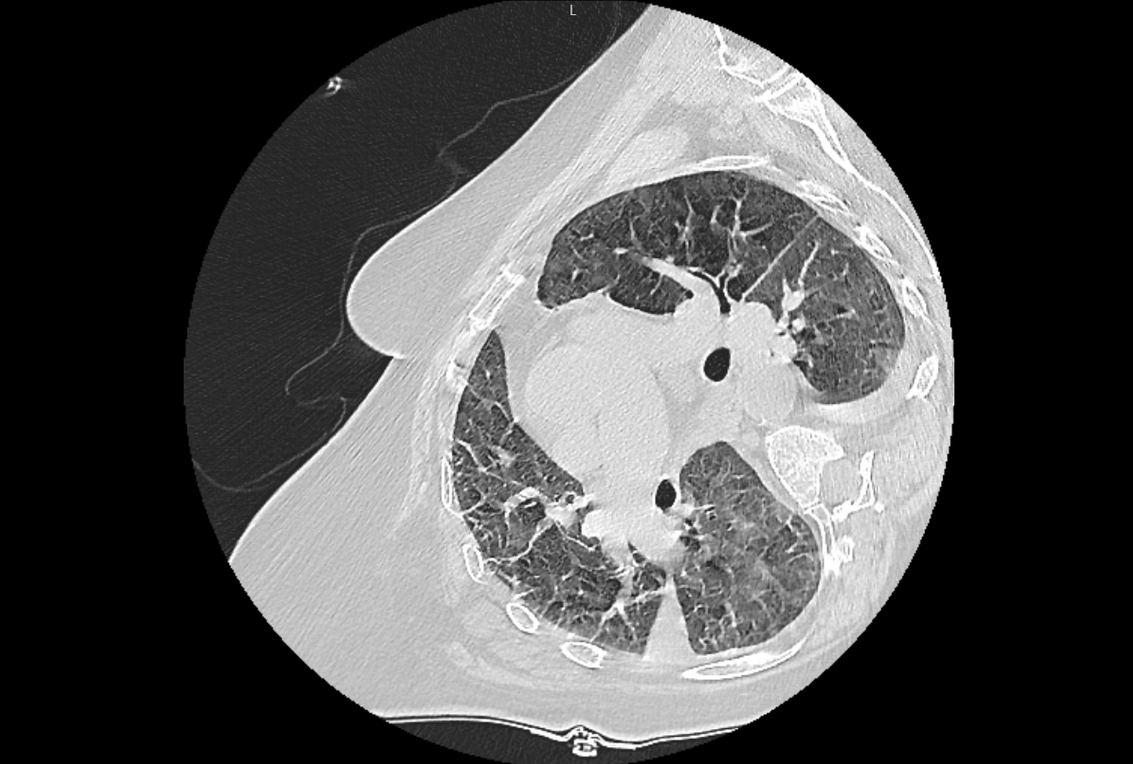
КТ на боку приводило к ошибкам в некоторых патологиях
Наша платформа, которую упоминал выше, также позволяет фильтровать и сортировать исследования по разным условиям — например, анализировать исследования с определённой патологией или с наибольшей неуверенностью модели.

Мониторинг дрифтов

Само распределение данных на уровне медицинского учреждения или целого региона, естественно, не статично. В больнице могут поставить новое оборудование, к нашей системе могут подключить новое учреждение или целый регион, в клинике могут внезапно начать делать рентгены детей. В идеале об этих бизнес-событиях ML-команда должна узнавать заранее, но так, увы, происходит далеко не всегда, так что обязательно нужно иметь в своём арсенале технические способы обнаружения изменений.

В ходе усиленного мониторинга после подключения новых клиентов часто выявляются всякие нестандартные кейсы, которые нужно разбирать отдельно.
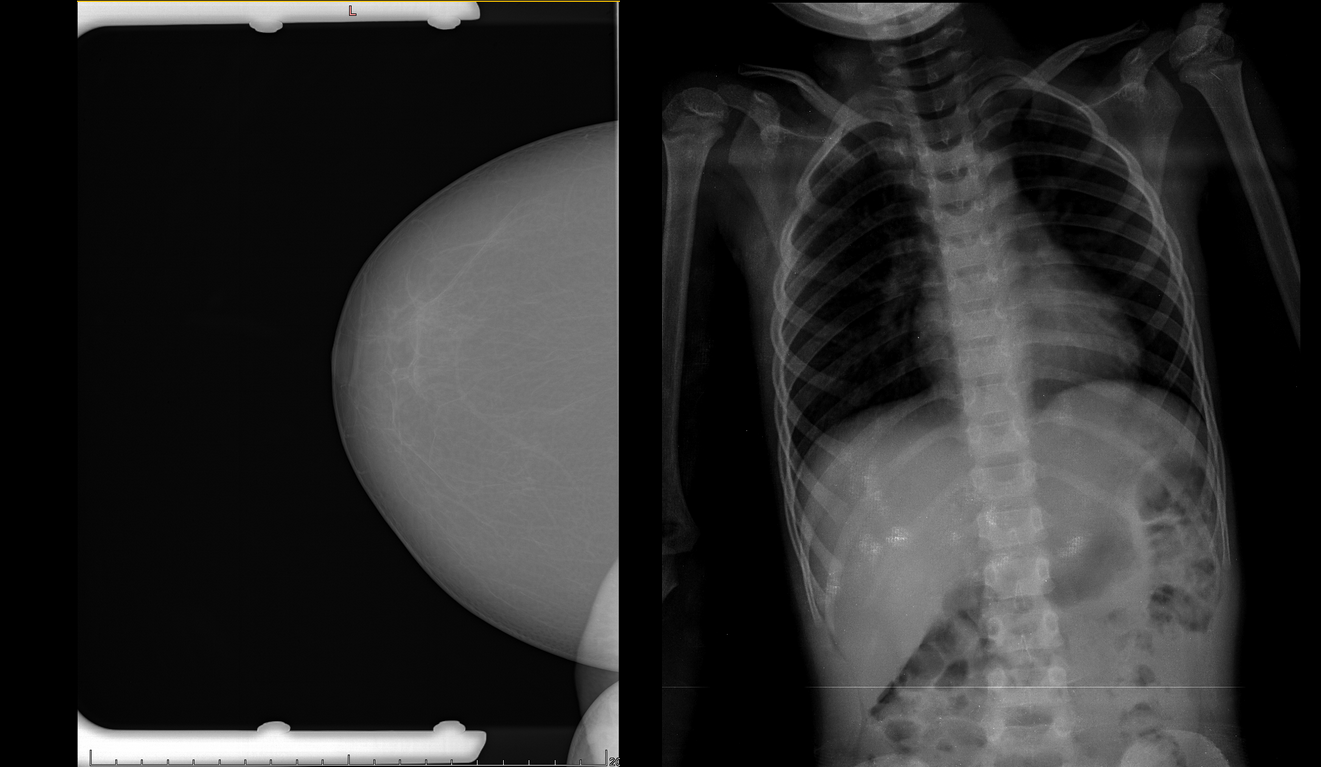
Слева — на исследовании видны рамки, которые в некоторых случаях ещё и залезают на область молочной железы. Справа — рентген ребёнка, на которых наша система работать не предназначена
Простейший автоматический инструмент — алерты о важных бизнес-событиях, например, подключение нового клиента к приложению.

Более глубокий мониторинг включает в себя, например, отслеживание появления нового оборудования или изменение доли того или иного оборудования в потоке исследований.
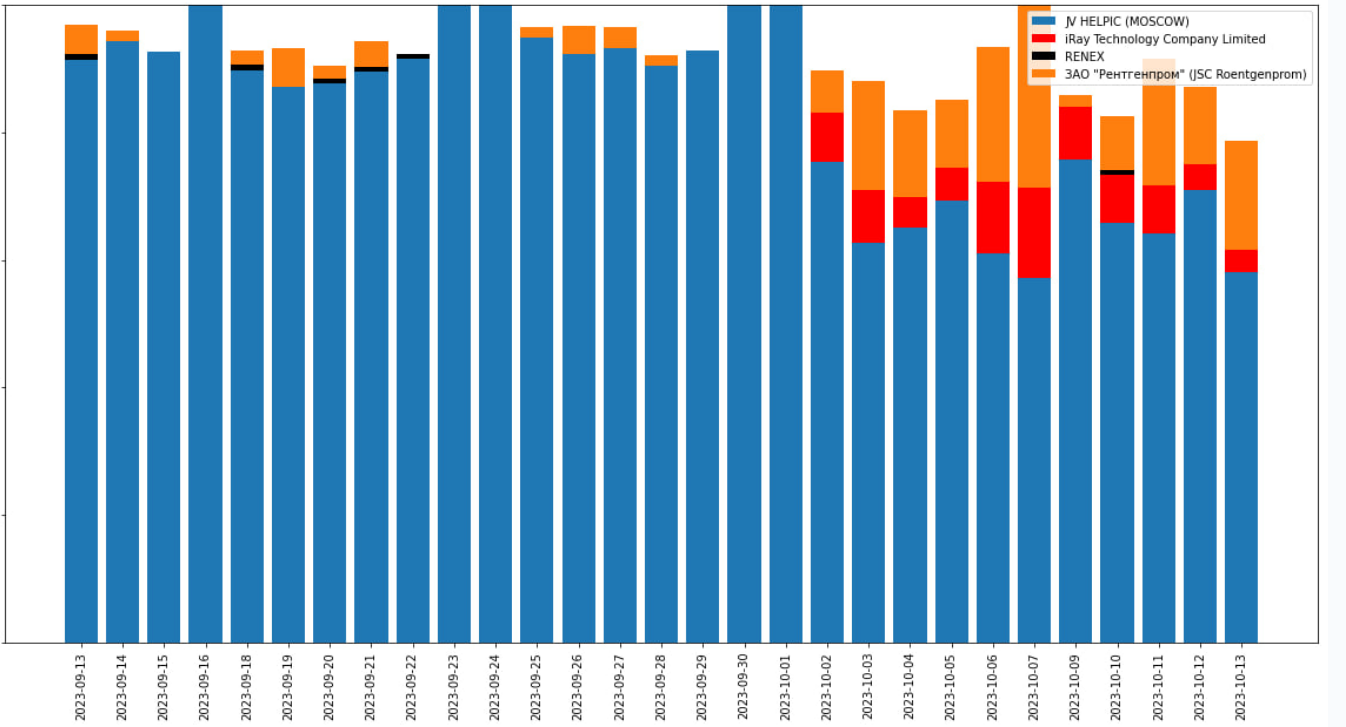
В октябре появляется новый производитель рентгеновских аппаратов + сильно вырастает доля другого
Мониторинг качества работы ML-модели

Так сказать, last but not least — сама модель (модели) или какие-то компоненты системы (препроцессинг, постпроцессинг) могут работать неправильно и это приводит к ошибкам — ложноположительным и ложноотрицательным срабатываниям. Конечно, мы получаем обратную связь от клиентов — от кого-то чаще, от кого-то очень редко, но очень желательно и самим иметь представление об онлайн-качестве работы системы. Особенно критично это в периоды после новых релизов.
Естественно, на этом этапе центральное место занимает врач-консультант, который может отсматривать результаты работы на случайной выборке или по определённому фильтру.

Инструменты здесь используются плюс-минус те же самые, разве что дополнительно это всё ещё оборачивается в какой-нибудь красивый отчёт.

Работа с инцидентами
Не лишним будет напомнить основные этапы работы с инцидентами. К сожалению, медицинские ИИ-системы здесь до сих пор здорово ограничены — чтоб зарелизить полноценный апдейт системы, нужно пройти процедуру обновления регистрационного удостоверения. В данный момент идут дискуссии об облегчении этой процедуры для сертифицированных разработчиков. Вот весьма разумное предложение от FDA.

Текущие проблемы
Основные проблемы с мониторингом сейчас связаны с деплоем в регионах.
Во-первых, большая часть регионов настаивает на локальном развёртывании в закрытом контуре. На таких машинах чаще всего нет доступа в интернет, да и самим нам туда часто зайти не так просто. Это очень сильно ограничивает возможность своевременного мониторинга и по сути превращает систему в чёрный ящик даже для самих разработчиков.
Во-вторых, в регионах сильно выше процент сложных исследований — с неправильной укладкой, дефектами оборудования, неправильно заполненными тегами. Это здорово увеличивает нагрузку на разработчиков и ведёт к некорректной работе ИИ-систем.
При этом выражу респект — в некоторых регионах очень активно идут на встречу, слышат фидбек, исправляют ошибки. Ну и в любом случае у нас всё сильно лучше, чем в Индии =)
Если вы хотите узнать ещё больше об организации процессов ML-разработки, подписывайтесь на наш Телеграм-канал Варим ML
