Мониторинг ETL-процессов в хранилище данных
Многие используют специализированные инструменты для создания процедур извлечения, трансформации и загрузки данных в реляционные базы данных. Процесс работы инструментов логируется, ошибки фиксируются.
В случае ошибки в логе содержится информация о том, что инструменту не удалось выполнить задачу и какие модули (часто это java) где остановились. В последних строках можно найти ошибку базы данных, например, нарушение уникального ключа таблицы.
Чтобы ответить на вопрос, какую роль играет информация об ошибках ETL, я классифицировал все проблемы, произошедшие за последние два года в немаленьком хранилище.

К ошибкам базы данных относятся такие, как не хватило места, оборвалось соединение, зависла сессия и т.п.
К логическим ошибкам относятся такие, как нарушение ключей таблицы, не валидные объекты, отсутствие доступа к объектам и т.п.
Планировщик может быть запущен не вовремя, может зависнуть и т.п.
Простые ошибки не требуют много времени на исправление. С большей их частью хороший ETL умеет справляться самостоятельно.
Сложные ошибки вызывают необходимость открывать и проверять процедуры работы с данными, исследовать источники данных. Часто приводят к необходимости тестирования изменений и деплоймента.
Итак, половина всех проблем связана с базой данных. 48% всех ошибок — это простые ошибки.
Третья часть всех проблем связана с изменением логики или модели хранилища, больше половины этих ошибок являются сложными.
И меньше четверти всех проблем связана с планировщиком задач, 18% которых — это простые ошибки.
В целом, 22% всех случившихся ошибок являются сложными, их исправление требует наибольшего внимания и времени. Происходят они примерно раз в неделю. В то время, как простые ошибки случаются почти каждый день.
Очевидно, что мониторинг ETL-процессов будет тогда эффективным, когда в логе максимально точно указано место ошибки и требуется минимальное время на поиск источника проблемы.
Эффективный мониторинг
Что мне хотелось видеть в процессе мониторинга ETL?
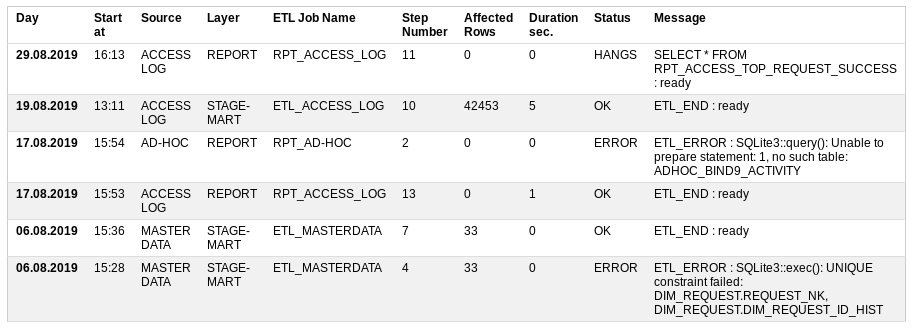
Start at — когда начал работу,
Source — источник данных,
Layer — какой уровень хранилища загружается,
ETL Job Name — поцедура загрузки, которая состоит из множества мелких шагов,
Step Number — номер выполняемого шага,
Affected Rows — сколько данных уже обработалось,
Duration sec — как долго выполняется,
Status — всё ли хорошо или нет: OK, ERROR, RUNNING, HANGS
Message — последнее успешное сообщение или описание ошибки.
На основании статуса записей можно отправить эл. письмо другим участникам. Если ошибок нет, то и письмо не обязательно.
Таким образом, в случае ошибки чётко указано место происшествия.
Иногда случается, что сам инструмент мониторинга не работает. В таком случае есть возможность прямо в базе данных вызвать представление (вьюшку), на основании которой построен отчёт.
Таблица мониторинга ETL
Чтобы реализовать мониторинг ETL-процессов достаточно одной таблицы и одного представления.
Для этого можно вернуться в своё маленькое хранилище и создать прототип в базе данных sqlite.
CREATE TABLE UTL_JOB_STATUS (
/* Table for logging of job execution log. Important that the job has the steps ETL_START and ETL_END or ETL_ERROR */
UTL_JOB_STATUS_ID INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
SID INTEGER NOT NULL DEFAULT -1, /* Session Identificator. Unique for every Run of job */
LOG_DT INTEGER NOT NULL DEFAULT 0, /* Date time */
LOG_D INTEGER NOT NULL DEFAULT 0, /* Date */
JOB_NAME TEXT NOT NULL DEFAULT 'N/A', /* Job name like JOB_STG2DM_GEO */
STEP_NAME TEXT NOT NULL DEFAULT 'N/A', /* ETL_START, ... , ETL_END/ETL_ERROR */
STEP_DESCR TEXT, /* Description of task or error message */
UNIQUE (SID, JOB_NAME, STEP_NAME)
);
INSERT INTO UTL_JOB_STATUS (UTL_JOB_STATUS_ID) VALUES (-1);CREATE VIEW IF NOT EXISTS UTL_JOB_STATUS_V
AS /* Content: Package Execution Log for last 3 Months. */
WITH SRC AS (
SELECT LOG_D,
LOG_DT,
UTL_JOB_STATUS_ID,
SID,
CASE WHEN INSTR(JOB_NAME, 'FTP') THEN 'TRANSFER' /* file transfer */
WHEN INSTR(JOB_NAME, 'STG') THEN 'STAGE' /* stage */
WHEN INSTR(JOB_NAME, 'CLS') THEN 'CLEANSING' /* cleansing */
WHEN INSTR(JOB_NAME, 'DIM') THEN 'DIMENSION' /* dimension */
WHEN INSTR(JOB_NAME, 'FCT') THEN 'FACT' /* fact */
WHEN INSTR(JOB_NAME, 'ETL') THEN 'STAGE-MART' /* data mart */
WHEN INSTR(JOB_NAME, 'RPT') THEN 'REPORT' /* report */
ELSE 'N/A' END AS LAYER,
CASE WHEN INSTR(JOB_NAME, 'ACCESS') THEN 'ACCESS LOG' /* source */
WHEN INSTR(JOB_NAME, 'MASTER') THEN 'MASTER DATA' /* source */
WHEN INSTR(JOB_NAME, 'AD-HOC') THEN 'AD-HOC' /* source */
ELSE 'N/A' END AS SOURCE,
JOB_NAME,
STEP_NAME,
CASE WHEN STEP_NAME='ETL_START' THEN 1 ELSE 0 END AS START_FLAG,
CASE WHEN STEP_NAME='ETL_END' THEN 1 ELSE 0 END AS END_FLAG,
CASE WHEN STEP_NAME='ETL_ERROR' THEN 1 ELSE 0 END AS ERROR_FLAG,
STEP_NAME || ' : ' || STEP_DESCR AS STEP_LOG,
SUBSTR( SUBSTR(STEP_DESCR, INSTR(STEP_DESCR, '***')+4), 1, INSTR(SUBSTR(STEP_DESCR, INSTR(STEP_DESCR, '***')+4), '***')-2 ) AS AFFECTED_ROWS
FROM UTL_JOB_STATUS
WHERE datetime(LOG_D, 'unixepoch') >= date('now', 'start of month', '-3 month')
)
SELECT JB.SID,
JB.MIN_LOG_DT AS START_DT,
strftime('%d.%m.%Y %H:%M', datetime(JB.MIN_LOG_DT, 'unixepoch')) AS LOG_DT,
JB.SOURCE,
JB.LAYER,
JB.JOB_NAME,
CASE
WHEN JB.ERROR_FLAG = 1 THEN 'ERROR'
WHEN JB.ERROR_FLAG = 0 AND JB.END_FLAG = 0 AND strftime('%s','now') - JB.MIN_LOG_DT > 0.5*60*60 THEN 'HANGS' /* half an hour */
WHEN JB.ERROR_FLAG = 0 AND JB.END_FLAG = 0 THEN 'RUNNING'
ELSE 'OK'
END AS STATUS,
ERR.STEP_LOG AS STEP_LOG,
JB.CNT AS STEP_CNT,
JB.AFFECTED_ROWS AS AFFECTED_ROWS,
strftime('%d.%m.%Y %H:%M', datetime(JB.MIN_LOG_DT, 'unixepoch')) AS JOB_START_DT,
strftime('%d.%m.%Y %H:%M', datetime(JB.MAX_LOG_DT, 'unixepoch')) AS JOB_END_DT,
JB.MAX_LOG_DT - JB.MIN_LOG_DT AS JOB_DURATION_SEC
FROM
( SELECT SID, SOURCE, LAYER, JOB_NAME,
MAX(UTL_JOB_STATUS_ID) AS UTL_JOB_STATUS_ID,
MAX(START_FLAG) AS START_FLAG,
MAX(END_FLAG) AS END_FLAG,
MAX(ERROR_FLAG) AS ERROR_FLAG,
MIN(LOG_DT) AS MIN_LOG_DT,
MAX(LOG_DT) AS MAX_LOG_DT,
SUM(1) AS CNT,
SUM(IFNULL(AFFECTED_ROWS, 0)) AS AFFECTED_ROWS
FROM SRC
GROUP BY SID, SOURCE, LAYER, JOB_NAME
) JB,
( SELECT UTL_JOB_STATUS_ID, SID, JOB_NAME, STEP_LOG
FROM SRC
WHERE 1 = 1
) ERR
WHERE 1 = 1
AND JB.SID = ERR.SID
AND JB.JOB_NAME = ERR.JOB_NAME
AND JB.UTL_JOB_STATUS_ID = ERR.UTL_JOB_STATUS_ID
ORDER BY JB.MIN_LOG_DT DESC, JB.SID DESC, JB.SOURCE;SELECT SUM (
CASE WHEN start_job.JOB_NAME IS NOT NULL AND end_job.JOB_NAME IS NULL /* existed job finished */
AND NOT ( 'y' = 'n' ) /* force restart PARAMETER */
THEN 1 ELSE 0
END ) AS IS_RUNNING
FROM
( SELECT 1 AS dummy FROM UTL_JOB_STATUS WHERE sid = -1) d_job
LEFT OUTER JOIN
( SELECT JOB_NAME, SID, 1 AS dummy
FROM UTL_JOB_STATUS
WHERE JOB_NAME = 'RPT_ACCESS_LOG' /* job name PARAMETER */
AND STEP_NAME = 'ETL_START'
GROUP BY JOB_NAME, SID
) start_job /* starts */
ON d_job.dummy = start_job.dummy
LEFT OUTER JOIN
( SELECT JOB_NAME, SID
FROM UTL_JOB_STATUS
WHERE JOB_NAME = 'RPT_ACCESS_LOG' /* job name PARAMETER */
AND STEP_NAME in ('ETL_END', 'ETL_ERROR') /* stop status */
GROUP BY JOB_NAME, SID
) end_job /* ends */
ON start_job.JOB_NAME = end_job.JOB_NAME
AND start_job.SID = end_job.SID
Особенности таблицы:
- начало и конец процедуры обработки данных должен сопровождаться шагами ETL_START и ETL_END
- в случае ошибки должен создаваться шаг ETL_ERROR с её описанием
- количество обработанных данных нужно выделить, например, звёздочками
- одновременно одну и туже процедуру можно запустить с параметром force_restart=y, без него номер сессии выдаётся только завершённой процедуре
- в обычном режиме нельзя запустить параллельно одну и туже процедуру обработки данных
Вывод
Таким образом, сообщения об ошибках в инструментах обработки данных играют мега-важную роль. Но оптимальными для быстрого поиска причины проблемы их сложно назвать. Когда количество процедур приближается к сотне, то мониторинг процессов превращается в сложный проект.
В статье приведён пример возможного решения проблемы в виде прототипа. Весь прототип маленького хранилища доступен в gitlab SQLite PHP ETL Utilities.
