Мой путь к секционированию в PostgreSQL

Когда мы перестаем контролировать размер таблицы — обслуживание и обеспечение доступности данных становится нетривиальной задачей. Я с такой проблемой столкнулся уже в продакшне, данных с каждым днем становится больше, таблица не влезает в память, сервера отвечают долго, но решение было найдено.
Привет, Хабр! Меня зовут Алмаз и сейчас я хочу поделиться методом, который помог мне реализовать секционирование.
Секционирование в PostgreSql
Секционирование (или как еще называют — партицирование) — процесс разбиение одной большой логической таблицы на несколько меньших физических секций. Это то, что поможет нам управлять нашими данными.
Пример: у нас есть таблица «sales», которая секционирована по интервалу один месяц, а эти секции могут быть разбиты на еще более мелкие подсекции по регионам.
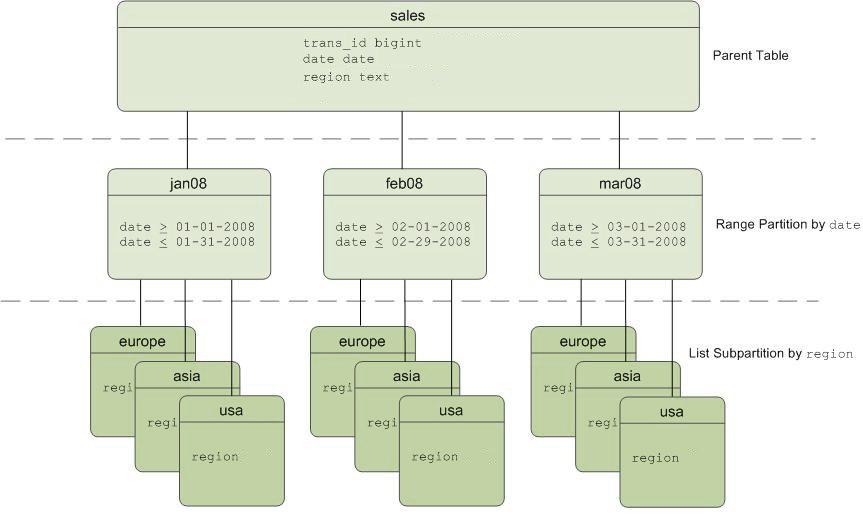
Схема секционированной таблицы «sales»
Минусы этого подхода:
— Усложняется структура базы данных. Каждая секция в определениях базы — это таблица, хоть и является частью одной логической сущности.
— Преобразовать существующую таблицу в секционированную и наоборот нельзя.
— Нет полной поддержки в версии Postgres 11.
Плюсы:
+ Быстродействие. В определенных случаях мы можем работать с ограниченным набором секций, не перебирая всю таблицу, даже поиск по индексу для больших таблиц будет медленнее. Повышается доступность данных.
+ Массовая загрузка и удаление данных командами ATTACH/DETACH. Это избавляет нас от накладных расходов в виде VACUUM-а. что позволяет более эффективно сопровождать базу данных.
+ Возможность указать TABLESPACE для секции. Это дает нам возможность выносить данные в другие разделы, но все же мы работаем в рамках одного инстанса и метаданные главного каталога будут содержать информацию о секциях.(не путать с шардингом)
2 пути к реализации секционирования в PostgreSql:
1. Наследование таблиц (INHERITS)
Когда, создавая таблицу, мы говорим «наследуйся от другой (родительской) таблицы». При этом добавляем ограничения для управления данными в таблице. Этим мы поддерживаем логику разбиения данных, но это логически разные таблицы.
Тут нужно отметить расширение разработанное компанией Postgres Professional pg_pathman, которое реализует секционирование, также через наследование таблиц.
CREATE TABLE orders_y2010 (
CHECK (log_date >= DATE '2010-01-01)
) INHERITS (orders);
2. Декларативный подход (PARTITION)
Таблица определяется как секционированная декларативно. Данное решение появилось в 10 версии PostgreSql.
CREATE TABLE orders (log_date date not null, …)
PARTITION BY RANGE(log_date); Я выбрал декларативный подход. Это дает большое преимущество — нативность, больше фич поддерживается ядром. Рассмотрим развитие PostgreSQL в данном направлении:

Источник
Но PostgreSql продолжает развиваться, и в 12 версии есть поддержка ссылок на секционированную таблицу. Это большой прорыв.
Мой путь
Учитывая вышесказанное, был написан скрипт на PL/pgSQL, который создает секционированную таблицу на основе существующей и «перекидывает» все ссылки на новую таблицу. Тем самым мы получаем секционированную таблицу на основе существующей и продолжаем работать с ней как с обычной таблицей.
Скрипт не требует дополнительных зависимостей и выполняется в отдельной схеме, которую создает сам. Также записывает логи повтора и отмены действий. Данный скрипт решает две основные задачи: создает секционированную таблицу и реализует внешние ссылки на нее через констрейнт триггеры.
Требование к скрипту: PostgreSql v.:11 и выше.
Сейчас пройдемся более детально по скрипту. Интерфейс очень прост:
есть две процедуры, которые делают всю работу.
1. Главный вызов — на этом этапе мы не меняем основную таблицу, но все необходимое для секционирования будет создано в отдельной схеме:
call partition_run(); 2. Вызов отложенных задач, которые были запланированы во время основной работы:
call partition_run_jobs(); Работа может быть запущена в несколько потоков. Оптимальное количество потоков близка к количеству секционируемых таблиц.
Входные параметры для скрипта (_pt record)

Скрипт изнутри, основные действия:
— Создаем секционированную таблицу
perform _partition_create_parent_table(_pt);
— Создаем секции
perform _partition_create_child_tables(_pt);
— Копируем данные в секции
perform _partition_copy_data(_pt);
— Добавим ограничения (job)
perform _partition_add_constraints(_pt);
— Восстановим ссылки на внешние таблицы
perform _partition_restore_referrences(_pt);
— Восстановим триггеры
perform _partition_restore_triggers(_pt);
— Создаем событийный триггер
perform _partition_def_tr_on_delete(_pt);
— Создаем индексы (job)
perform _partition_create_index(_pt);
— Заменяем вьюхи, ссылки на секцию (job)
perform _partition_replace_view(_pt); Время работы скрипта зависит от многих факторов, но основные — это размер целевых таблиц, количества отношений, индексы и характеристики сервера. В моем случае таблица 300Gb секционировалась меньше чем за час.
Результат
Что мы получили? Посмотрим на план запроса:
EXPLAIN ANALYZE
select * from "sales” where dt BETWEEN '01.01.2019'::date and '14.01.2019'::date 
Результат из секционированной таблицы мы получали быстрее и использовали меньше ресурсов нашего сервера по сравнению с запросом к обычной таблице.
В данном примере обычная и секционированные таблицы находятся на одной базе и имеют около 200М записей. Это хороший результат, учитывая то, что мы, не переписывая прикладной код, получили ускорение. Запросы по другим индексам также работают хорошо, но следует помнить: всегда, когда мы можем определить секцию, результат будет в несколько раз быстрее, т.к. PostgreSql умеет отбрасывать лишние секции на этапе планирования запроса (set enable_partition_pruning to on).
Итог
Мне удалось реализовать секционирование на таблицах, которые имеют множество связей и обеспечить целостность базы данных. Скрипт не зависит от конкретных структур данных и может быть переиспользован.
PostgreSQL — самая современная в мире реляционная база данных с открытым исходным кодом!
Всем спасибо!
Ссылка на исходник
