Мои маленькие реле: Brainfuck компьютер это магия
Введение
Давным давно, когда вокруг все было большим, а я маленьким, читал я книгу Войцеховского «Радиоэлектронные игрушки», горя желанием воплотить в жизнь те или иные описанные в ней устройства. Так, в уже тоже далеком 2008-м году, из нескольких десятков электромагнитных реле было собрано 4-разрядное АЛУ (РЦВМ1 — Релейная Цифровая Вычислительная Машина — версия 1) способное складывать и вычитать. И задумал я тогда —, а что если собрать существенно большее количество реле и построить полноценный релейный компьютер? На неспешную сборку реле то здесь то там до требуемого количества ушло всего 8 лет, и я начал творить.
Разрешите представить Вам свой проект по созданию второй версии релейной цифровой вычислительной машины, с кодовым названием «BrainfuckPC» — 16-разрядной компьютер с Фон-Неймановской архитектурой и набором инструкций для языка Brainfuck. Работы по проектированию завершены, и я в процессе изготовления сего монстра.
1 Технические характеристики
- Разрядность шины адреса: 16 бит
- Адресация: пословная, 16 бит/слово
- Емкость памяти: 64 килослова (128Кбайт)
- Разрядность шины данных: 16 бит
- Единое адресное пространство кода и данных (Архитектура Фон-Неймана)
- Тактовая частота (проектная): 100 Гц, 1 инструкция/такт
- Набор инструкций: Brainfuck++
- Количество реле (проектное): 792
- Используемые реле: герконовые, РЭС55(1п), РЭС64(1з)
Подробности подкатом
Общий принцип работы
Рассмотрим обобщенную структуру компьютера:
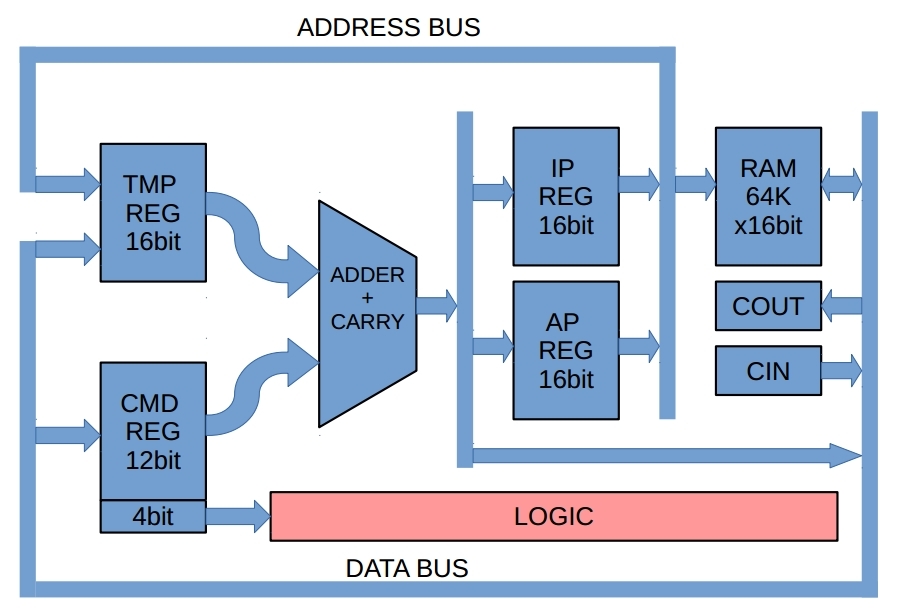
Рисунок 1: Обобщенная структура компьютера
Центральным элементом является Сумматор, причем не простой, а с параллельным переносом. Зачем это нужно — расскажу чуть ниже.
Программа и данные хранятся в блоке памяти. Доступ к ним осуществляется по адресу, записанному в регистре инструкций IP, либо в регистре адреса AP, исходя из того, что мы сейчас хотим прочитать — данные по адресу, указанному в AP, либо инструкцию, записанную по адресу IP.
Чтобы оперировать этой лентой Тьюринга (а Brainfuck язык программирования отождествляет именно её), нам надо иметь возможность совершить одно из трех действий:
- Изменять значение в текущей ячейке данных, то бишь делать операции Add/Sub. В Brainfuck значение в ячейке можно изменить только на единицу, т.е. +1 либо -1. Но имея полноценный сумматор грешно не схлопнуть длинные цепочки ++++++++++++(------------) в одну операцию AP+=N (AP-=N) существенно ускорив процесс вычисления. (также не забудем превратить [-](или [+]) в *AP=0);
- Изменять номер текущей выбранной ячейки данных. То бишь гулять по памяти данных (AP++, AP--);
- Изменять номер текущей инструкции. Во-первых, нам нужно после выполнения каждой инструкции увеличивать значение в регистре IP на единицу. Во-вторых, изменять это значение при наличии ветвлений в коде (по умолчанию для организации циклов). Контрольный флаг всего один — Z. Соответственно есть команды JumpIfZero и JumpIfNotZero.
Итого нам надо иметь возможность подавать на один вход сумматора значение любого из следующих трех блоков — AP-регистра, IP-регистра, DATA-шины. Делать это будем через временный регистр, в котором будем сохранять одно из требуемых значений, подключая нужный с помощью 16-разрядных ключей.
На второй вход сумматора будем подавать число, на которое одно из этих значений должно изменяться в плюс или минус. В виду ограниченной ширины инструкции, изменять можно только на ±12 битное число. Впрочем для Brainfuck это более чем достаточно («хватит всем», ага).
Брать эти 12 бит мы будем с регистра команд, при наличии таких команд естественно, ибо часть команд не использует сумматор вовсе. Не забудем что отрицательные числа будут подаваться в дополненном коде, с подачей на доп. вход переноса единицы (т.е. будет A+ invB + 1)
Результат вычисления сразу загружаем туда, откуда мы его взяли. Из-за временного регистра делать это мы можем безболезненно.
Более подробно (я бы даже сказал — занудно) об архитектуре можно узнать из этого видео:
Набор инструкций
Нарисовав общую принципиальную схему, способную реализовать 8 основных Brainfuck-инструкций, я понял, что у нее гораздо больший потенциал. Поэтому я разработал более широкий набор инструкций, совместимый с Brainfuck, однако требующий компиляции каждой исходной Brainfuck-инструкции в 16-разрядную инструкцию компьютера.
Все инструкции 16-разрядные. Формируются из нескольких частей.
- Биты 15, 14, 13 — определяют класс инструкции
- Бит 12 — Знаковый бит для знаковых инструкций
- Биты 11–0 — содержат младшие 12 бит знакового int-a. Старшие 4 бита формируются согласно значению 12-го бита.
| Инструкция | Опкод | Операция | Эквивалент из Brainfuck | Описание |
|---|---|---|---|---|
| add m16 | 0X XX | AP ← AP + m16 | '+' (Повторить m16 раз) | Прибавляет базу к текущему значению выбранной ячейки |
| sub m16 | 1X XX | AP ← AP — m16 | '-' (Повторить m16 раз) | Соответственно вычитает базу из числа |
| ada m16 | 2X XX | AP ← AP + m16 | '>' (Повторить m16 раз) | Увеличивает значение адреса |
| ads m16 | 3X XX | AP ← AP — m16 | '<' (Повторить m16 раз) | Уменьшает значение адреса |
| jz m16 | 4X XX | (*AP == 0)? IP ← IP + m16: IP ← IP | '[' | Идти на IP + m16 если значение текущей ячейки равно нулю |
| jz m16 | 5X XX | (*AP == 0)? IP ← IP — m16: IP ← IP | Нет | Идти на IP — m16 если значение текущей ячейки равно нулю |
| jnz m16 | 6X XX | (*AP!= 0)? IP ← IP + m16: IP ← IP | Нет | Идти на IP + m16 если значение текущей ячейки не равно нулю |
| jnz m16 | 7X XX | (*AP!= 0)? IP ← IP — m16: IP ← IP | ']' | Идти на IP — m16 если значение текущей ячейки не равно нулю |
| and m16 | 8X XX | AP ← AP AND m16 | Нет | Логическое AND с положительным числом |
| and m16 | 9X XX | AP ← AP AND m16 | Нет | Логическое AND с отрицательным числом (кто-то же должен сформировать старшие 4 бита) |
| or m16 | aX XX | AP ← AP OR m16 | Нет | Логическое OR с положительной константой |
| or m16 | bX XX | AP ← AP OR m16 | Нет | Логическое OR с отрицательной константой |
| in | c0 00 | *AP ← CIN | ',' | Прочитать один m8 символ из консоли. Если входной буфер пуст — подождать его |
| out | c0 01 | COUT ← *AP | '.' | Вывести m8 символ в консоль |
| clr.ap | d0 01 | AP ← 0 | Нет | Очистить AP регистр. Команда допускает комбинирование |
| clr.ip | d0 02 | IP ← 0 | Нет | Очистить IP регистр. Команда допускает комбинирование |
| clr.dp | d0 04 | *AP ← 0 | '[+]' or '[-]' | Очистить ячейку памяти. Команда допускает комбинирование |
| set.ap | d0 10 | AP ← *AP | Нет | Записать текущее значение в AP регистр |
| set.ip | d0 20 | IP ← *AP | Нет | Записать текущее значение в IP регистр |
| get.ap | d1 00 | *AP ← AP | Нет | Считать текущее значение из AP регистра |
| get.ip | d2 00 | *AP ← IP | Нет | Считать текущее значение из IP регистра |
| mode.b8 | e1 00 | Нет | Активация 8-разрядного режима (1) | |
| mode.b16 | e2 00 | Нет | Активация 16-разрядного режима | |
| halt | f0 00 | Нет | Стоп машина |
- AP — Регистр адреса
- IP — Регистр Инструкций
- *AP — Текущая ячейка памяти
- CIN — Консольный ввод
- COUT — Консольный вывод
- При активации 8-разрядного режима, сумматор продолжает работать в 16-разрядном режиме. Однако условные команды (а именно тест значения текущей ячейки памяти на равенство нулю) становится 8-разрядным. (AP & 0×00FF == 0)? и (AP & 0×00FF!= 0)? Консольный ввод и вывод пока решено оставить всегда 8-разрядным. Не в юникоде же печатать в конце то концов?
В этом видео я подробно (но мало понятно) рассказал о том, что делает каждая инструкция и какой brainfuck-инструкции она соответствует:
Параллельный сумматор
Релейная ЭВМ должна быть не только релейной, но еще и быстрой. Как и любая другая ЭВМ, моя тоже будет синхронной машиной, оснащенной тактовым генератором. Естественно мне хочется не растрачивать впустую циклы тактирования и постараться каждую операцию уместить в один цикл — т. е. за нарастающий и спадающий фронты синхронного генератора успеть загрузить новую команду и исполнить ее. Желательно при этом чтобы все команды выполнялись за одинаковый период времени.
Каждое реле имеет некоторую задержку срабатывания и отпускания, которое мы примем за 1 условную единицу времени (у.е.в.) Если будем использовать реле РЭС22, 1 у.е.в. будет равен 12–15 мс (справочное), РЭС64 — 1.3 мс (справочное). Самой дорогой (и наиболее частой) операцией в моей машине является сумматор.
Сам по себе он довольно простой и быстрый, но «есть один нюанс», который заключается в способе вычисления и передачи сигнала переноса.
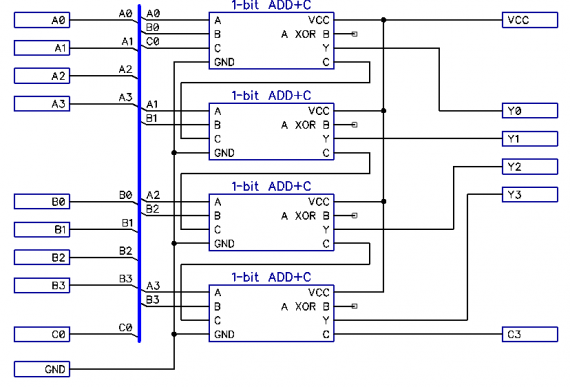
Рисунок 2: Сумматор с последовательным переносом.
Изначально я планировал использовать сумматор с последовательным переносом. В таком сумматоре каждый последующий разряд зависит от состояния сигнала переноса разряда текущего. В итоге длительность операции вычисления будет колебаться между 2 у.е.в. — N*2 у.е.в., где N — число разрядов. В итоге, 16-разрядный сумматор с последовательным переносом будет иметь максимальную задержку 32 у.е.в.
Сумматоры с параллельным переносом имеют максимальное быстродействие. В них отсутствуют процессы распространения переносов от разряда к разряду. В каждом разряде одновременно вырабатываются выходные величины:

Рисунок 3: Сумматор с параллельным переносом
Возможность построения сумматора с указанными свойствами основана на воспроизведении функций суммы и переноса, зависящих только от значений слагаемых независимо от местоположения разряда в разрядной сетке. Подвох в том, что сама схема параллельного переноса с каждым последующим разрядом усложняется. Вот, смотрите что получается:
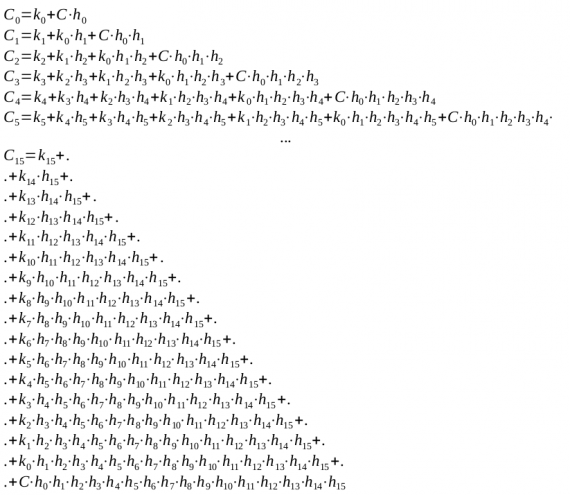
Рисунок 4: (Который должен был быть в виде LaTeX формулы, но нет) уравнение вычисления сигнала переноса для разрядов. Где  — побитовое И,
— побитовое И,  — побитовое ИЛИ
— побитовое ИЛИ
Как итог — реализовать параллельный перенос довольно накладно. Однако можно заметить, что последующий разряд содержит в себе уравнение вычисления предыдущего (тут должен быть мем «да ладно?» с Николасом Кейджем), поэтому в принципе достаточно будет сделать схему расчета переноса только для старшего разряда, а остальные собрать из него, предусмотрев вывод промежуточных результатов.

Рисунок 5: Полная схема 16-разрядного сумматора с параллельным переносом
На рисунке 5 — первые два столбца это собственно сами сумматоры. Потом идут блоки 2AND и 2OR, которые формируют промежуточные значения h и k, фигурирующие в рисунке 4. Их наличие подтолкнуло меня на мысль расширить список команд логическими операциями сложения и умножения, для чего мне необходимо добавить лишь пару защелок и соответствующий микрокод.
Все остальное — блоки 5AND на базе 4-х реле РЭС64, которые можно запаять так, чтобы один модуль использовать как, например 2AND + 3AND. У этих блоков каждый шаг логического И выведен через диод, что позволяет собирать промежуточные сигналы переноса.
Расчетное время распространения сигнала: сумматоры справляются за 1 у.е.в., еще одна у.е.в. уходит на 2AND/2OR, еще одна — на умножение в блоках 5AND, логическое сложение на диодах, задержки не вносит. Ну и последняя одна у.е.в. тратится на досчет сумматора.
Итого 4 у.е.в. супротив 32-х, или не более 6 мс на работу сумматора.
Регистры
В машине четыре 16-разрядных специализированных регистра. Никаких РОН-ов. Только жесткая привязка, только хардкор! Состоит из D-триггеров, каждый D-триггер — это отдельный модуль на 4-х реле РЭС55 со следующей схемой:

Рисунок 6: Принципиальная схема модуля D-триггера. Где-то там есть еще разъем, но здесь он не важен, ибо все подписано.
Данные приходят на вход Data, реле которого определяет, куда пойдет сигнал синхронизации — на сброс триггера, или его установку (за что отвечают еще два реле, одно с самоблокировкой). Четвертому реле достается коммутация выхода Q. Очень полезная фишка.
Плата памяти

Рисунок 7: Плата памяти. Размеры платы 315×200 мм
Очень сложный и важный элемент, хотя сама схема памяти составляет малую часть общей начинки блока. Задача этой платы — во-первых, нести на себе 64 Килослова общей памяти программ и данных. Собрана она на базе двух 64 Кбайт микросхем кэша. Адресный вход через схемы защиты и коммутатор подключается к шине адреса компьютера, а со стороны шины данных сложная система из входного буффера и выходного драйвера, также с коммутатором. За чтение и запись в память отвечают две линии W/R и Sync. Первая выбирает что будем делать, вторая — собственно будет это делать.
И пока этого самого Sync нет, плата памяти натурально живет своей жизнью. На рендере можно видеть две светодиодные матрицы 16×16. Этот дисплей выводит некоторую область памяти. Эдакая VideoRAM, определяется программно, кстати. Опрашивает микросхему памяти и управляет выводом микроконтроллер Atmega1280.
За сим задачи микроконтроллера не заканчиваются. На нем висит консольный ввод и вывод. Куда он будет выводить — я еще не решил, посему на плате разведен USB-Serial преобразователь для обычной консоли и ESp8266 для Wi-Fi. По последнему в наиболее актуальных планах иметь веб-страничку с возможностью загрузки программ для компьютера в память и собственно сама консоль. Да, В задачи МК также входит первоначальная загрузка программы в ОЗУ, для чего у него есть полный доступ к ОЗУ, а также небольшая EEPROM-ина на 1Мбит, для хранения программ.
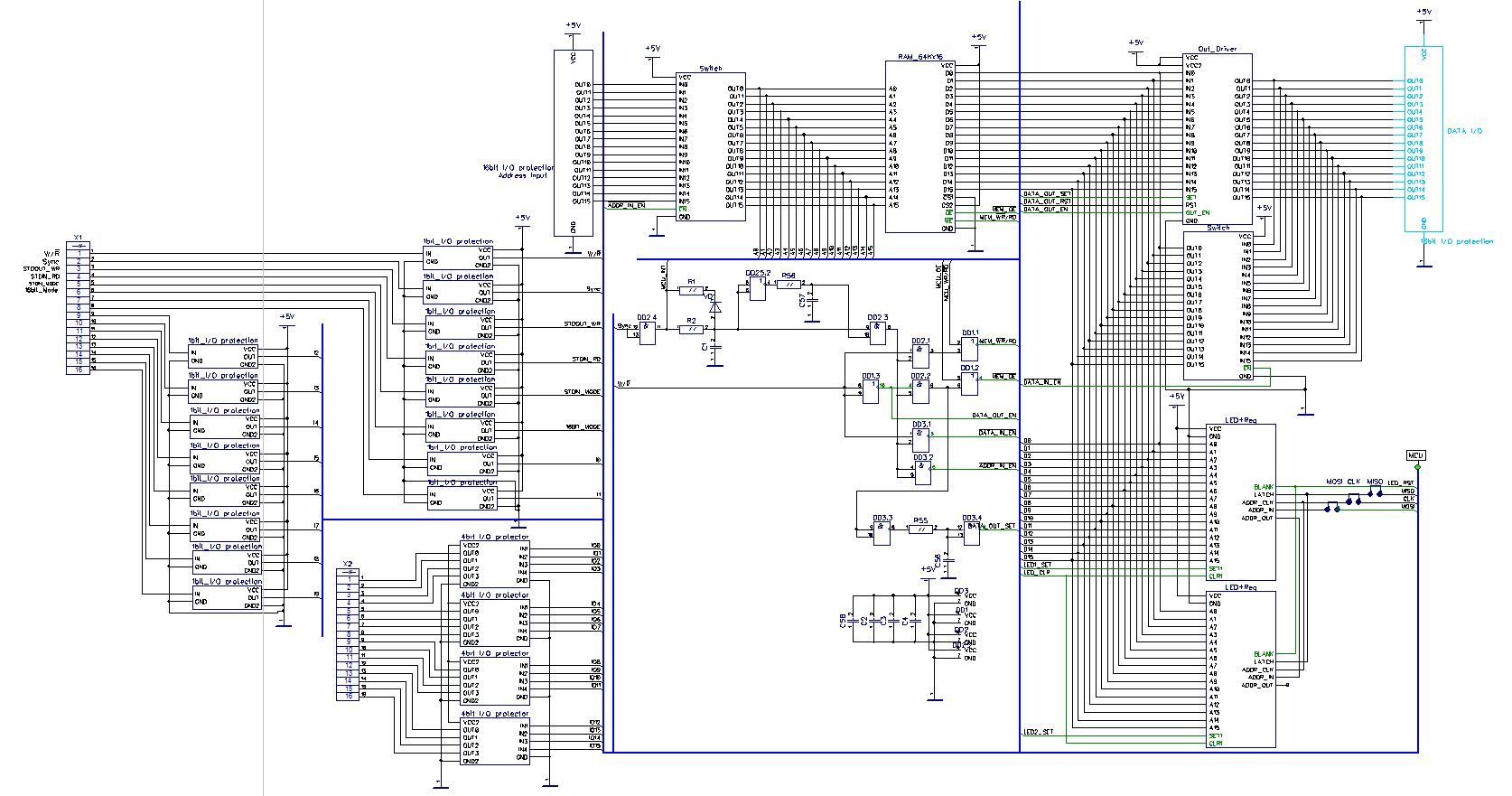
Рисунок 8: Принципиальная схема платы памяти. Микроконтроллер и схемы блоков не показаны
Блок логики
Я понятия не имею, как он в итоге будет выглядеть. Последняя версия присутствует на общей схеме компьютера, но мне она не нравится. Скорее всего я сделаю 12-стадийный секвенсор и с помощью ключей буду подавать сигналы на отдельные блоки.
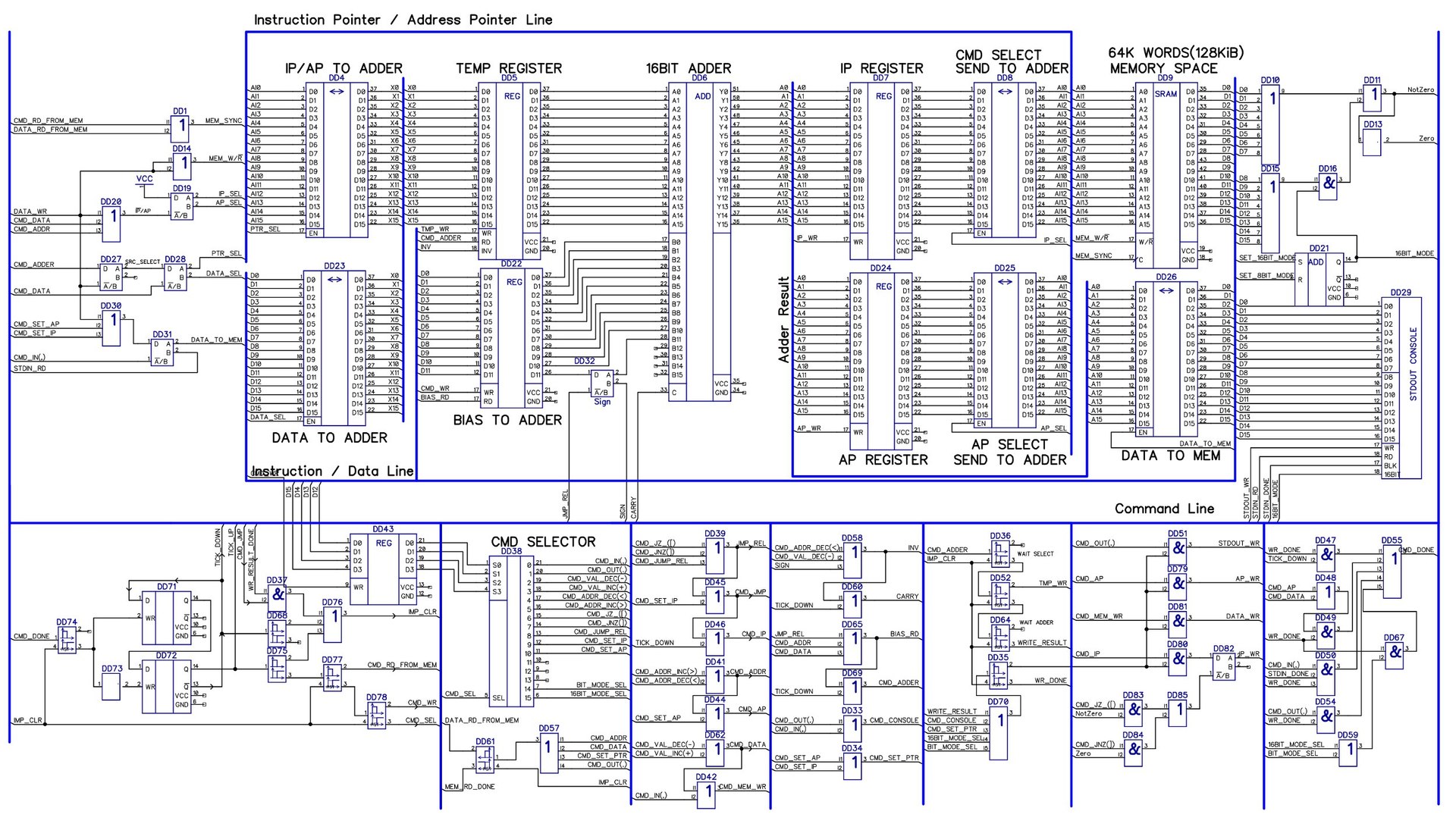
Рисунок 9: Все что вокруг 16-разрядных блоков и есть блок логики
Конструкция
Конструкция машины модульная, поблочная рамная. На КДПВ наглядно показано как будет располагаться начинка машины. Но обо всем по порядку:
Базовый элемент компьютера — модуль 60×44 мм, с 16-контактным разъемом, несущий на себе 4 реле, их обвязку, и 4 светодиода для индикации:

Рисунок 10: 3D-модель модуля
Модули различных типов:
- 1-разрядный сумматор с переносом — 16 шт;
- Модуль 5AND для схемы параллельного переноса — 32 шт;
- Модуль D-триггера — 64 шт на регистры, плюс немного на логике;
- Модуль 4×2AND_SW, для организации защелок. Тут просто 4 замыкающих реле;
- Модуль 4×2AND, для организации защелок. Здесь 3 реле из 4-х с переключающим контактом. На 4 реле не хватило вывода разъема;
- Модуль диодный, 8 диодов Д226Д. Для организации многовходового OR
- Модуль универсальный 2AND/2OR, позволяет создать 2AND-NOT, 2OR-NOT, 4AND, 4AND-NOT, 4OR, 4OR-NOT и любые комбинации. На базе 4 реле с переключающими контактами и общими точками;
Так как блок управляющей логики я, хоть и придумал, уже забраковал, точное число модулей каждого типа мне не ведомо. Разберусь по дороге. Расчетное число модулей — 192 штуки.
Берем плату 150×200 мм, запаиваем на нее 32 разъема на 16 пинов, да не простые, а для монтажа накруткой и устанавливаем на нее в матрицу 8×4 наши модули, получая такой вот блок:

Рисунок 11: Блок
В моей машине таких блоков будет 6 штук — два блока на сумматор, два на регистры и два на логику. Чешу репу насчет еще пары блоков защелок, но если они и будут, то плоскими и распаянными
Монтаж накруткой был выбран потому, что: во-первых, схемотехника каждой базовой платы заранее хоть и известна, но может изменяться и подвержена ошибкам. Во-вторых, блок логики в принципе невозможно с первого раза развести корректно, и если для блока регистров все в целом понятно и можно разок ошибиться со, скажем, линией синхронизации, то логику придется переделывать тысячу и один раз. Будет намного лучше, если собирать каждую составляющую блока логики постепенно. В-третьих, чисто механический фактор — на двухслойной плате физически невозможно развести эти блоки :) Во все стороны расходятся 16-разрядные шины, которые многократно пересекаются друг с другом.
Итого каждый блок содержит 32 модуля, с общим числом реле 128 штук. Питание каждого блока — 5В 2А.
На большой раме, размерами 640×480 мм (по факту немногим больше, но число красивое) размещаются шесть релейных блоков и плата памяти:
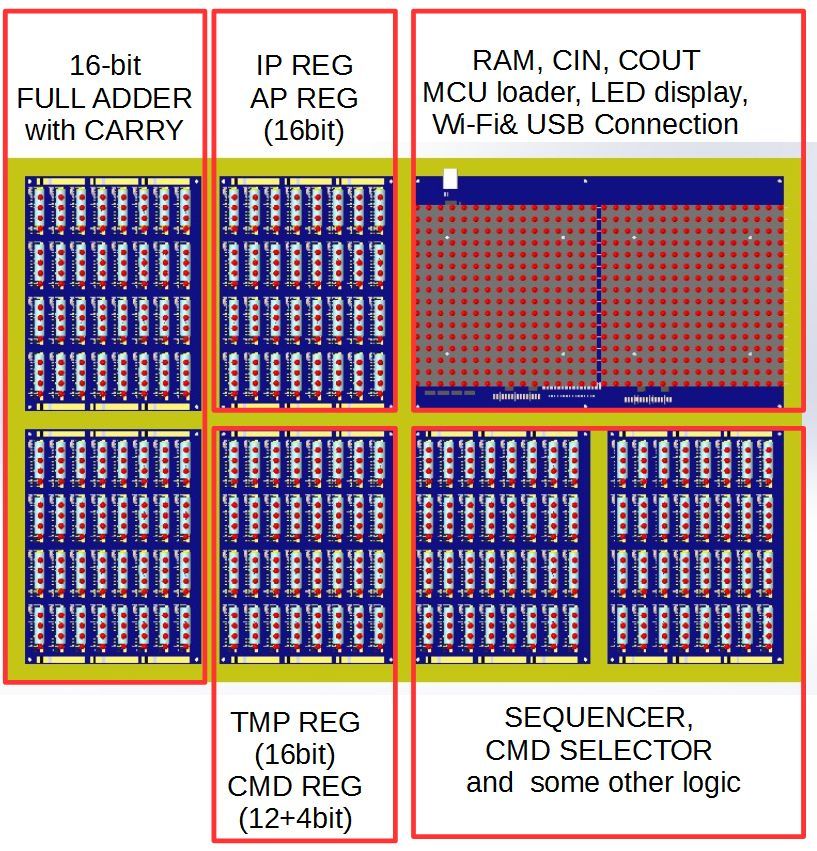
Рисунок 12: расположение блоков машины
Весь компьютер вставляется в деревянную раму из ценных пород дерева, со стеклом спереди и сзади.
Изготовление
Не смотря на сегодняшнюю дату, проект на самом деле существует :-) И находится в не самой активной, но все же стадии изготовления.
Их есть у меня. В большом количестве, но проблема в том, что из более килоштучного запаса три сотни — реле на 27 Вольт и 5-вольтовых РЭС55 мне может не хватить. Масштаб бедствия окончательно оценить не смогу, но думаю за последующее время что я буду собирать эту адскую машину проблема исчезнет за счет пополнения запасов извне.

Рисунок 13: Запасы реле. 800 штук реле — новые, удачно ухваченные на митинском радиорынке за копейки
Одним из источников пополнения запасов являются релейные платы ЦАП от лабораторных блоков питания. Вот такие вот:

Рисунок 14: Платы из блоков питания типа БП, приобретенные на радиорынке (нет, сам я БПшники не дербаню)
Все печатные платы я решил делать сам. Зажал 300 баксов китайцам и уже 4 месяц занимаюсь тем, что покрываю заготовки фоторезистом, просвечиваю, травлю, покрываю паяльной маской, проявляю, сверлю фрезерую.

Рисунок 15: Протравленные панели различных видов
Платы я изготавливаю пластинами, по 9 модулей на пластине 200×150 мм. Протравил 30 пластин и застрял на нанесении паяльной маски. Все никак не начну. Паяльная маска у меня FSR-8000 синего цвета, двухкомпонентная и я с ней ранее уже имел дело.
Пластины 200×150 мм выбраны не случайно — у нас на радиорынке, в одном секретном месте такие стабильно продаются многие годы и вся моя приспособа заточена именно под этот формат.
В слову фоторезист (МПФ-ВЩ от Диазоний) я стал наносить с помощью ламинатора и это просто чудеса. Качество приклеивания выросло в разы.
Потом надо будет эти платы еще нарезать и насверлить, для чего у меня даже 3Д-фрезер имеется.

Рисунок 16: 3D-фрезерный китайский станок DIY 2020CNC
Взял я его за скромные 175 долларов исключительно за электронику. Платы сверлить и фрезеровать хватит, а я уже поглядываю на комплекты ШВП+рельсы для 3Д-станков. Готовые такие покупать дороговато, а собрать самому когда он начнет требоваться — самое то.
Вот в этом обзоре можно получше узнать о моем станочке:
Программы
Программы загружаются в компьютер с помощью микроконтроллера, а значит он должен знать что и куда грузить. Для сего есть специальный формат (в состоянии драфта конечно же) бинарного файла, а ля Elf. В заголовке файла прописывается число, размер и адреса секций кода и данных (а также где содержимое этих секций лежит в файле). //TODO Не забыть добавить секцию видеопамяти — у нас же есть светодиодная панель, надо сказать микроконтроллеру с какого по какое выводить на экран.
Наличие микроконтроллера позволяет мне: а. контролировать корректность выполнения программы, б. обеспечивать защищенный режим работы с памятью. Можно ловить Segmentation Fault!
В общем, нужен компилятор. Я испробовал десятки различных популярных интерпретаторов — все исполняют одну и ту же программу по разному. Стабильнее всех оказался leBrainfuck, он делает трансляцию программы в свой формат и корректно ее исполняет.
Я написал свой компилятор, на данный момент его код ужасен, но он позволяет транслировать обычный Brainfuck в бинарь формата моей машины. Поддерживает сворачивание команд ±<>, но не реализовано преобразование последовательности [-] в сброс ячейки. Ну и куча других фич, в том числе поддержка доп. инструкций, тоже не сделаны.
Есть и простенький эмулятор. Эмулятор в момент написания статьи также поддерживает только основные 8 инструкций. Вот что он творит с программой факториала:

Время выполнения — чуть меньше 10 секунд. Найденная на полях адекватная LLVM версия справляется за 0,9 секунд. О том как я с помощью Intel Vtune Amplifier оптимизировал свой эмулятор и разгонял с 120 секунд до 10 заслуживает отдельной статьи.
Но важно не это. Чтобы вывести этот фрактал, потребовалось 3 миллиарда оптимизированных brainfuck-инструкций. С учетом проектной частоты в 100Гц и 50 строк текста мы получаем 347 машинных дней — т.е. почти ГОД на одну программу, или строчка вывода в неделю! По факту первую строчку мы дождемся к концу первых суток, но чем дальше, тем медленнее. С другой стороны это самый быстрый релейный компьютер из всех существующих и проектируемых.
За сим, информация по существу закончилась, поэтому предлагаю посмотреть небольшой видеообзор других релейных компьютеров, существующих в природе
Вот здесь находится наиболее полный на мой взгляд список всех релейных машин на данный момент.
Мыслишки
Хочу заиспользовать часть запасов вакуумных индикаторов ИВ-6 в виде длинного табло в верхней части машины, выводящего в реальном времени значения всех регистров, а также общее число исполненных инструкций и общее время работы компьютера. Но здесь я никак не могу определиться с источником этих данных — МК в плате памяти забит под завязку, да и часть значений он способен лишь эмулировать. Лучший вариант — считывать значения напрямую. По схеме управления самими ИВ-шками тоже не могу прийти к единому мнению — делать динамическую индикацию на 30–40 ИВ-шек проблематичнее чем для 6 штук настольных часов.
ЗАЧЕЕЕЕМ???777

Ссылки
Весь проект в openSource. Посему вот основные ссылки по проекту:
- https://github.com/radiolok/RelayComputer2 — репозиторий с принципиальными схемами и разводками печатных плат. Ссылочку на репозиторий прошивки платы памяти я добавлю позднее
- https://github.com/radiolok/RelayComputer2/blob/master/roadmap.md Отдельно отмечу эту страницу с дорожной картой проекта, на которой фиксируются ключевые изменения.
- https://hackaday.io/project/18599-brainfuck-relay-computer на этой страничке я публикую подробные отчеты о том что было сделано. По набору критической массы они будут превращаться в статью на GT.
- https://github.com/radiolok/bfutils компилятор и эмулятор.
