Моделирование базы данных в Neo4j
В этой статье я расскажу о best practices моделирования данных в Neo4j.
Neo4j — пожалуй, самая распространенная графовая БД по состоянию на 2022 год. Полностью ACID-совместима и имеет множество интерфейсов для работы: от REST до нативного адаптера почти для каждого языка программирования. А также нативный GUI с человеческим лицом :) Из небольших минусов — отсутствие поддержки в популярных Database IDE вроде Jetbrains DataGrip.
Однако, графовая БД — не реляционная БД и требует иного подхода к проектированию базы данных. В этой статье я буду использовать примеры из официальной, распространяемой вместе с дистрибутивом, базы данных Movie Graph с фильмами и людьми с ними связанными: актерами, режиссерами и т.д.
Для начала, разберем общие best practices
Прежде, чем начать проектирование БД, необходимо:
Идентифицировать всех стейкхолдеров проекта: кто, как и зачем будет использовать приложение. Это клиенты, администраторы, сотрудники бек-офиса, техподдержка, разработчики и другие. Без этого понимания будет можно продвигаться в проработке проекта, но не туда :) Это тем более важно сделать в самую первую очередь, потому что на данном этапе такая работа самая дешевая. Переделывать многократно дороже.
Поняв, кто ваши стейкхолдеры, с каждым нужно:
Проработать приложение в деталях.
Определить пользователей системы (стейкхолдер не всегда пользователь).
Определить сценарии использования (use cases) системы.
Приоретизировать сценарии использования.
Если бы мы проектировали IMDB, то примеры хороших use cases, на которые должна отвечать система в контексте чтения данных, могут быть такими:
Какие люди играли в этом фильме?
В каких фильмах играл этот актер?
Кто самый юный актер в этом фильме?
Сколько драм срежиссировал этот режиссер?
И так далее.
Таких use cases могут быть сотни и все они имеют значение, если будут использоваться в реальной жизни системы. Один пропущенный, но важный use case может привести к проектированию костылей, которые уберут еще одну букву в вашей реализации CAP-теоремы.
По окончании данного этапа у вас должен получиться некий набор артефактов, рассказывающих о вашей системе. Зачем и для кого она существует, и как ей будут пользоваться. После чего можно приступать к укладыванию этих знаний в ядро — базу данных.
Две главные задачи моделирования — это:
Моделирование графа
В Neo4j всего четыре типа компонентов, которыми можно описать схему данных:
Nodes — сущности
Labels — метки к сущностям
Relationships — однонаправленные отношения между сущностями
Properties — свойства сущностей или отношений

При проектировании необходимо создать два типа моделей: модель данных и модель инстансов (экземпляров данных)
Почему это важно? Потому что модель данных — это теоретическая часть вашей системы. Необходимо смоделировать как реальные данные лягут на эту теорию и спроектировать практическую модель с конкретными экземплярами данных. Это также позволит еще в песочнице посмотреть справляется ли ваша модель со всеми use cases.
Моделирование нод
Грубо говоря, все существительные в ваших use cases — это ноды.
Актер, режиссер, фильм — это все ноды. Однако, небольшой логический тюнинг все-же необходим и мы объединим актера и режиссера в одну ноду с меткой Person. Конкретно в Neo4j иногда этого выгоднее не делать, но об этом позже. Также в Neo4j для специфических задач можно указать до 4 меток на одну ноду, но это скорее исключение.
Фильм поместим в ноду с меткой Movie.
 Для названия нод используется CamelCase
Для названия нод используется CamelCase
Теперь нам нужно обогатить ноды свойствами. Помимо очевидных свойств вроде имени человека и названия фильма, по нашим use cases у нас определяются несколько других свойств, выделим их:
«Кто самый юный актер в этом фильме?» — свойство для хранения возраста человека
«Сколько драм срежиссировал этот режиссер?» — свойство для хранения жанра фильма
 Для названия свойств используется camelCase
Для названия свойств используется camelCase
Теперь на нашу теоретическую модель данных применим реальную модель инстансов:
 Ноды с данными разместили, но между ними пока нет взаимосвязей
Ноды с данными разместили, но между ними пока нет взаимосвязей
Кажется, все хорошо и мы успешно спроектировали ноды. Теперь спроектируем взаимосвязи между ними.
Моделирование взаимосвязей
Вновь обращаясь к нашим use cases, мы можем определить взаимосвязи из глаголов:
«Какие люди играли в этом фильме?» — взаимосвязь ACTED_IN
«В каких фильмах играл этот актер?» — взаимосвязь ACTED_IN
«Сколько драм срежиссировал этот режиссер?» — взаимосвязь DIRECTED
В Neo4j все связи между нодами однонаправлены и это направление должно быть явно указано. Соответственно, выбирая название для связи, необходимо выбрать правильный глагол, который бы отображал как левая часть связи (активная нода) воздействует (глагол) на правую часть (пассивная нода).
Например:
Recipe — USES --> Ingredient
Person — MARRIED --> Person
(да, можно ссылаться на ту же самую ноду)Player — PLAYS --> Game
Book — CONTAINS --> Chapters
Доработаем нашу модель данных:

Важно упомянуть об одной рекомендации по проектированию БД в Neo4j: иногда вынесение свойств в отдельные ноды имеет смысл! Например, можно вынести имя и фамилию актера в разные ноды, если того требуют наши use cases:

Такое разделение может быть полезно, если нам необходимо отвечать на вопросы вроде: «Кто из персон имеет фамилию Kidman?».
В принципе, для такой «денормализации» данных нет предела. Одновременно с ужасной, на первый взгляд, избыточностью и потенциальным появлением супернод с 1000+ связей, она несет в себе огромную пользу в ответе на самые нетипичные вопросы. Я бы сказал, что для исследовательских целей имеет смысл дробить базу настолько глубоко, насколько есть вероятная польза от этого. Для продакшн систем дробить только в пределах use cases.
Во взаимосвязях между нодами также можно указывать дополнительные свойства, которые описывают специфику такого взаимодействия.
Доработаем нашу модель инстансов с взаимосвязями и свойствами к ним:
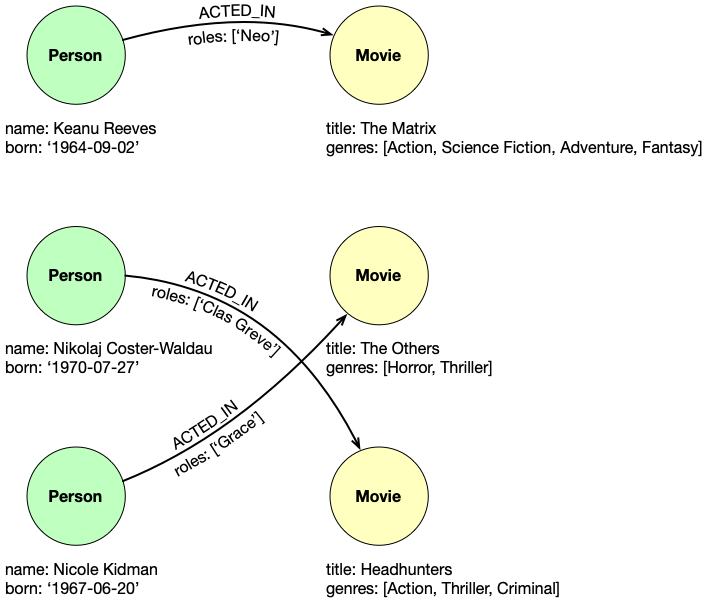
В базовом виде, моделирование нашей БД в Neo4j закончено. Это больше теоретическая статья. В следующих публикациях я постараюсь рассказать о практике с конкретными примерами запросов. Также мы разберем как тестировать модель данных, рефакторить её и другие аспекты.
