Многопоточные вычисления на Javascript, или как телефон выиграл гонку у ноутбука
Привет, Хабр!
Продолжаем битву за производительность Javascript на примере построения сводных таблиц. В прошлый раз мы реализовали несколько оптимизаций, и оставалась последняя реальная возможность ускорить расчет — перейти на многопоточные вычисления. В Javascript уже давно существуют воркеры, реализация которых не лишена недостатков, но заявлено, что они используют реальные потоки операционной системы — так почему бы не попробовать? Неожиданно оказалось, что для распараллеливания простого, в сущности, алгоритма пришлось переписать синтакис агрегатных формул, так как старые не обладали свойстом аддитивности (подробнее под катом), но, в конечном итоге, все получилось.
Тестировалась обработка 1 миллиона фактов на двух устройствах:
- Нетбук Linux 4.15, 2 x Intel Celeron CPU N2830 @ 2.16 GHz
- Телефон Android 7.0, 4 x ARM Cortex-A53 @ 1.44 GHz
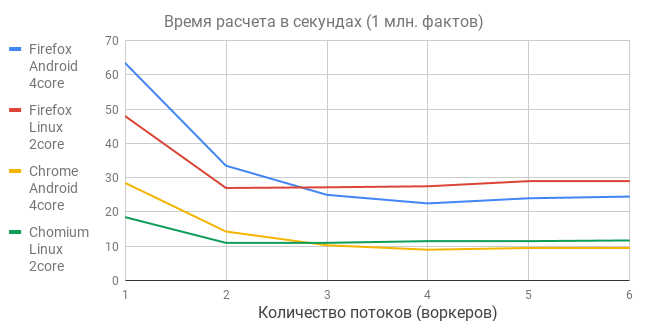
Из графиков следует несколько выводов.
- Выигрыш от многопоточности получился весьма скромным, намного меньше ожидаемого, ибо чудес не бывает — программная многопоточность требует аппаратной многопроцессорности, а в наших устройствах мало ядер.
- Оптимальный размер пула воркеров совпадает с количеством ядер. Именно поэтому телефон, стабильно проигрывавший все однопоточные тесты, внезапно вырвался вперед, показав лучший результат — миллион фактов за 9 секунд.
- Однопроходный алгоритм масштабируется линейно — при увеличении объема исходных данных на порядок — на этот же порядок увеличивается время расчета. Проверил на телефоне — 10 миллионов фактов рассчитались за 80 секунд, 100 миллионов фактов — за 1000 секунд. Ничего не повисло и не упало. Лет 15 назад для таблиц такого размера обычно покупали Oracle.
- Поскольку бизнес-приложения активно переходят в WEB и мобильники — многоядерность персональных устройств абсолютно оправдана, а многопоточное программирование — это просто must have, даже для фронтенда.
Поиграться с тестами можно самостоятельно — приложение тут, генератор тестовых данных в комплекте, время расчета выводится.
Особенности алгоритма
Напомню, что представляет собой наш алгоритм. В качестве исходных данных используется неструктурированное хранилище фактов, схема данных не создается. На вход подается JSON, содержащий вперемешку операции и справочники. Мы определяем вычисления на 2-х уровнях — формула на уровне отдельного факта (по сути вычисляемый атрибут), и агрегатная формула на уровне строки сводной таблицы. Затем накладываем фильтр, и строим сводную таблицу одним проходом по массиву фактов. В этом единственном цикле осуществляется группировка, рассчитываются агрегаты, извлекаются данные справочников, и определяется ширина колонок.
Данные хранятся в IndexedDB блоками, каждому воркеру выделяется свой диапазон блоков, главный поток запускает воркеры, периодически принимает от них статус (количество обработанных записей), и, дождавшись останова всех — сводит результат. На контрольном примере время сведения результата пренебрежимо мало, но на других данных, конечно, могут быть варианты. Чтобы результат сводился правильно — все агрегатные формулы должны обладать аддитивностью, то есть их можно было бы применить как к одиночным фактам, так и к уже посчитанным блокам.
Агрегатные формулы
Я раньше не понимал, почему Excel, взрослые OLAP системы и РСУБД не позволяют написать собственную агрегатную функцию на скриптовом языке, а содержат лишь набор заранее предопределенных типа sum (), avg () и проч. Например, достаточно долгое время в Excel не было даже функции count_distinct, да и сейчас не во всех СУБД она есть. Оказывается, если дать возможность пользователю определять свои агрегатные функции — не все из них будут аддитивными, а значит, расчет не может быть распараллелен, что убийственно для промышленной системы. Покажем это на примере 3-х функций агрегирования массива:
console.log([1, 2, 3, 4].reduce(
(accumulator, currentValue) => accumulator + currentValue
));
console.log([1, 2, 3, 4].reduce(
(accumulator, currentValue) => (accumulator + currentValue) ** 2
));
console.log([1, 2, 3, 4].reduce(
(accumulator, currentValue) => accumulator + currentValue ** 2
));
Первая функция аддитивна, так как может быть применена сама к себе, то есть:
accumulator + (accumulator + currentValue).
Вторая функция вообще не может быть распараллелена, с третьей нужно поработать, ибо применение ее в лоб к блоку:
accumulator + (accumulator + currentValue ** 2) ** 2 — даст некорректный результат, но если распарсить выражение, и понять, что это всего-лишь сумма квадратов — аддитивность достигается. В нашем же алгоритме accumulator — не просто скаляр, а массив, представляющий текущую строку сводной таблицы, а currentValue — соответственно массив значений атрибутов текущего факта (в том числе и вычисляемых), в результате чего риск поломки аддитивности возрастает.
Напомню, что в первом варианте приложения в агрегатных формулах использовались функции fact (colname) и row (colname) (первая возвращает атрибут текущего факта, вторая — промежуточное рассчитанное значение колонки сводной таблицы), и уже из них составлялись выражения суммирования, подсчета количества, и т.д. Однако для пользователя велик сооблазн в одной агрегатной формуле использовать, например, несколько атрибутов факта, что недопустимо, если мы хотим многопоточности. Заниматься парсингом формул мне было лень — мало ли чего пользователь может придумать — и я принял самое простое решение — запретить в агрегатной формуле использовать атрибуты факта напрямую, а только оборачивая их в предопределенные агрегатные примитивы, таким образом наша сводная таблица будет описываться такими формулами:
"quantity-sum": "sum('quantity')",
"amount-sum": "round(sum('amount'), 2)",
"price-max": "max('price')",
"price-min": "min('price')",
"price-last": "last('price')",
"price-avg": "round(sum('price') / count(), 2)",
"price-weight": "round(sum('amount') / sum('quantity'), 2)",
"EAN-code": "selectlast('EAN-code', \"fact('product') == row('product')\")"
Повторных вычислений не происходит — результаты вычисления агрегатных примитивов кэшируются. Доступны примитивы sum (), count (), mul (), min (), max (), last (), first (). Последняя функция selectlast () подтягивает реквизит справочника из другого факта, то есть, по сути, реализует join хранилища самого к себе, но вычисляется в общем цикле, то есть без потери производительности. Что касается функций mode (), median (), count_distinct () — они не аддитивны, не масштабируются линейно, до окончания расчета потребуют хранить все значения в отдельной структуре (расход памяти), и поэтому будут реализованы позднее.
Резюме
Наверное, на этом можно закончить попытки разгона Javascript, мы все-таки не вполне догнали Excel, хотя и вплотную приблизились.Теоретически, можно еще посмотреть в сторону gpu.js, для чего придется переписать алгоритм на чистые функции, но, в принципе, и так получилось неплохо. Желаю приятного программирования и свежих идей!
