ML,VR & Robots (и немного облака)
Всем привет!
Хочу рассказать об очень не скучном проекте, где пересеклись робототехника, Machine Learning (а вместе это уже Robot Learning), виртуальная реальность и немного облачных технологий. И все это на самом деле имеет смысл. Ведь это и правда удобно — вселяться в робота, показывать, что ему делать, а затем обучать веса на ML сервере по сохраненным данным.
Под катом мы расскажем, как оно сейчас работает, и немного деталей про каждый из аспектов, который пришлось разрабатывать.

Зачем
Для начала стоит немного раскрыть проблему.
Кажется, роботы, вооруженные Deep Learning, вот-вот повсеместно вытеснят людей с их рабочих мест. На самом деле все не так гладко. Там, где действия строго повторяются, процессы уже действительно неплохо автоматизируется. Если речь идет о «умных роботах», то есть применения, где компьютерного зрения и алгоритмов уже достаточно. Но так же остается много крайне сложных историй. Роботы с трудом справляются с разнообразием объектов, с которыми приходится иметь дело, и разнообразием окружающей обстановки.
Ключевые моменты
Есть 3 ключевые вещи с точки зрения реализации, которые еще не везде встречаются:
- Возможность прямого обучения из управления роботом (data-driven learning). Т.е. по мере того, как оператор управляет роботом, запоминаются все данные с камер, датчиков и сигналы управления. Затем, эти данные используются для обучения.
- Вынесение вычислительной задачи (мозгов) из механического тела робота
- Следование принципу робото-человеческой взаимопомощи (Human-machine collaboration)
Второе важно еще и потому, что прямо сейчас мы будем наблюдать изменение в подходах к обучению, алгоритмов, за ними и вычислительных средств. Алгоритмы восприятия и управления станут более гибкими. А модернизация робота стоит денег. Да и вычислитель можно эффективнее использовать, если он будет обслуживать сразу несколько роботов. Эта концепция называется «cloud robotics».
С последним все просто — AI прямо сейчас развит недостаточно, чтобы обеспечивать 100% надежности и точности во всех ситуациях, которые требуются бизнесу. Поэтому не помешает супервайзер-оператор, который сможет иногда помогать подопечным роботам.
Схема
Для начала о программной/сетевой платформе, которая обеспечивает всю описанную функциональность:
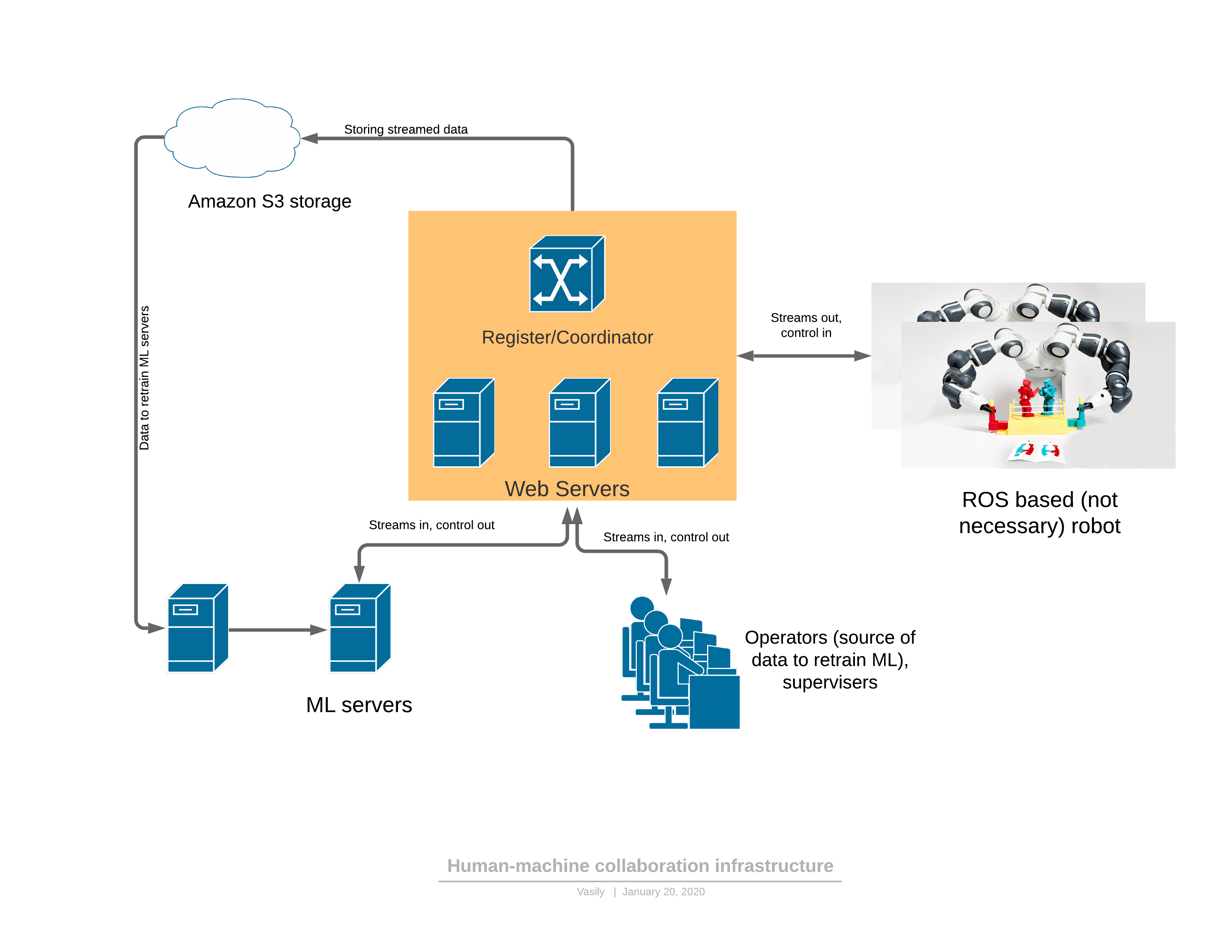
Составные части:
- Робот отправляет 3D видео-поток на сервер, в ответ получает управление.
- Облачная часть включает в себя: сервера приема-передачи стримов, сервис регистратора сущностей в системе (роботов, операторов, администраторов, серверов)
- Отдельно вынесена ML часть (машинное обучение), в ее составе есть сервера для переобучения моделей, а также сервера, управляющие роботом. Они функционируют полностью аналогично операторам — получают 3D стрим на вход, на выходе формируют управляющие сигналы.
- Есть клиент-приложение для оператора, отрисовывающее 3D поток с робота в шлем виртуальной реальности, предоставляющее достаточный UI для управления роботом. На выход — управление.
Порядок автоматизации
Есть 2 режима функционирования робота: автоматический и ручной.
В ручном режиме робот работает, если ML сервис еще не обучен. Затем из автоматического робот переходит в ручной либо по запросу оператора (увидел странности в поведении, следя за роботом), либо при детектировании аномалии самим ML сервисов. О детекции аномалиях будет позже — это очень важная часть, без которой невозможно применять предложенный подход.
Эволюция управления получается следующая:
- Формируется задание для робота в понятных человеку терминах и описываются показатели производительности
- Оператор подключается к роботу в VR и выполняет поставленную задачу в рамках существующего рабочего процесса некоторое время
- ML часть обучается на полученных данных
- Робот начинает работать автономно под присмотром оператора, в случае выявление аномалий ML сервисом управления или самим оператором робот снова переключается в ручной режим и дообучается
- Формируется еженедельный отчет по заданным показателям производительности и проценту времени выполнения работы в автоматическом режиме
Интеграция с роботом и немного о компрессии 3D
Очень часто для роботов используется среда ROS (robot operating system), которая по факту является фреймворком для управления «node-ами» (узлами), каждый из которых обеспечивает часть функциональности робота. В целом, это относительно удобный способ программирования роботов, который в чем-то напоминает микросервисную архитектуру веб приложений по своей сути. Основное достоинство ROS — это стандарт в отрасли и уже есть огромное количество модулей, необходимых для создания робота. Даже промышленные робо-руки могут иметь модуль сопряжения с ROS.
Самое простое — сделать модель сопряжения (bridge) между нашей серверной частью и ROS. Например, такой. Сейчас в нашем проекте используется более развитая версия ROS «ноды», которая логинится и опрашивает микросервис регистра, к какому ретрансляционному серверу может подключиться конкретный робот. Исходный код приведен лишь как пример инструкции по установки ROS модуля. Поначалу, когда осваиваешь этот фреймворк (ROS), все выглядит довольно недружелюбно, но документация сделано довольно неплохо, и через пару недель разработчики начинают довольно уверенно использовать его функционал.
Из интересного — проблема компрессии 3D потока данных, которую нужно производить непосредственно на роботе.
Не так и просто сжать карту глубин. Даже при небольшой степени сжатия RGB потока допускается очень серьезное локальное искажение яркости от истинного в пикселях на границах или при движении объектов. Глаз этого почти не замечает, но как только такие же искажения допускаются в карте глубин, при отрисовке 3D все становится очень плохо:

(из статьи)
Эти дефекты на краях сильно портят 3D сцену, т.к. появляется просто много мусора в воздухе.
Мы стали использовать покадровое сжатие — JPEG для RGB и PNG для карты глубины с небольшими хаками. Такой способ жмет поток 30FPS для 3D сканера разрешения 640×480 в 25Мбит/с. Можно обеспечить и лучшее сжатие, если трафик критичен для приложения. Существуют коммерческие кодеки 3D потока, которые также могут использоваться для сжатия этого потока.
Управление в виртуальной реальности
После того, как мы провели калибровку систему отсчета камеры и робота (и мы уже писали статью про калибровку), роборукой можно управлять в виртуальной реальности. Контроллер задает и позицию в 3D XYZ и ориентацию. Для некоторых роборук будет достаточно только 3х координат, но с бОльшим количеством степеней свободы нужно передавать и ориентацию инструмента, заданного контроллером. Кроме того, элементов управления на контроллерах хватает и для исполнения команд робота вроде включения/отключения насоса, управления захватом и других.
Изначально, было решено использовать JavaScript framework для виртуальной реальности A-frame, основанный на движке WebVR. И первые результаты (видео демонстрации в конце статьи для 4х координатной руки) были получены именно на A-frame.
На деле оказалось, что WebVR (или A-frame) было неудачным решением по ряду причин:
- совместимость в основном с FireFox, при этом именно в FireFox фреймворк A-frame не освобождал ресурсы текстур (остальные браузеры справлялись), пока потребление оперативной памяти не достигало 16Гб
- ограниченность взаимодействия с VR контроллерами и шлемом. Так, например, не получилось добавить дополнительные метки, которыми можно задавать положение, например, локтей оператора.
- приложение требовало многопоточности или нескольких процессов. В одном потоке/процессе нужно было распаковывать видео-кадры, в другом — отрисовывать. В итоге все было организовано через worker-ы, но время распаковки достигало 30 мс, а отрисовку в VR нужно делать с частотой 90FPS.
Все эти недостатки выливались в то, что отрисовка кадра не успевала в отведенные ей 10 мс и были очень неприятные подергивания в VR. Вероятно, все можно было побороть, но самобытность каждого браузера немного напрягала.
Сейчас мы решили уйти в C#, OpenTK и C# порт библиотеки OpenVR. Есть еще альтернатива — Unity. Пишут, что Unity для новичков…, но сложно.
Самое главное, что нужно было найти и познать для обретения свободы:
VRTextureBounds_t bounds = new VRTextureBounds_t() { uMin = 0, vMin = 0, uMax = 1f, vMax = 1f };
OpenVR.Compositor.Submit(EVREye.Eye_Left, ref leftTexture, ref bounds, EVRSubmitFlags.Submit_Default);
OpenVR.Compositor.Submit(EVREye.Eye_Right, ref rightTexture, ref bounds, EVRSubmitFlags.Submit_Default);
(это код отправки двух текстур в левый и правый глаза шлема)
Т.е. отрисовать в OpenGL в текстуры то, что видят разные глаза, и отправить в очки. Радости не было предела, когда получилось залить левый глаз красным, а правый — синим. Еще пару дней и вот карта глубин и RGB, приходящая по webSocket, переводились в полигональную модель за 10 мс вместо 30 на JS. А дальше просто опрашивать координаты и кнопки контроллеров, ввести систему событий для кнопок, обработать нажатия пользователя, ввести State Machine для UI и вот уже можно хватать стаканчик из под эспрессо:
Сейчас несколько удручает качество Realsense D435, но это пройдет, как только поставим хотя бы вот такой интересный 3D сканер от Microsoft, облако точек которого намного точнее.
Сторона сервера
Сервер ретрансляции
Основным функциональным элементов является сервер ретрансляции (server in the middle), который получает от робота видео-поток с 3D снимками и показаниями датчиков и состояния робота и распределяет между потребителями. Входные данные — упакованные кадры и показания датчиков, приходящие по TCP/IP. Раздача потребителям осуществляется web-socket-ами (очень удобный механизм для стриминга нескольким потребителям, в том числе и в браузер).
Кроме того, промежуточный сервер сохраняет поток данных в облачное хранилище S3, чтобы впоследствии их можно было использовать для обучения.
Каждый сервер ретрансляции поддерживает http API, которое позволяет выяснить его текущее состояние, что удобно для контроля текущих подключений.
Задача ретрансляции достаточно тяжелая, как с точки зрения вычислительной, так и с точки зрения трафика. Поэтому здесь мы следовали логике, что сервера ретрансляции разворачиваются на множестве облачных серверов. А, значит, нужно вести учет кто куда подключается (особенно, если роботы и операторы в разных регионах)
Регистр
Самым надежным сейчас будет жестко задать для каждого робота, к каким серверам он может подключаться (резервирование не помешает). ML сервис управления ассоциируется с роботом, опрашивает сервера ретрансляции, чтобы определить к какому из них сейчас подключен робот и подключается к соответствующему, если, конечно, у него для этого достаточно прав. Аналогично действует и приложение оператора.
Самое приятное! В силу того, что обучение роботов представляет из себя услугу, сервис виден только нам внутри. Значит, его front-end может быть максимально удобным, собственно нам! Т.е. это консоль в браузере (есть прекрасная своей простотой библиотека TerminalJS, которую очень легко дорабатывать, если хочется дополнительных функций, вроде автодополнения по клавише TAB или воспроизведения истории вызовов) и выглядит вот так:
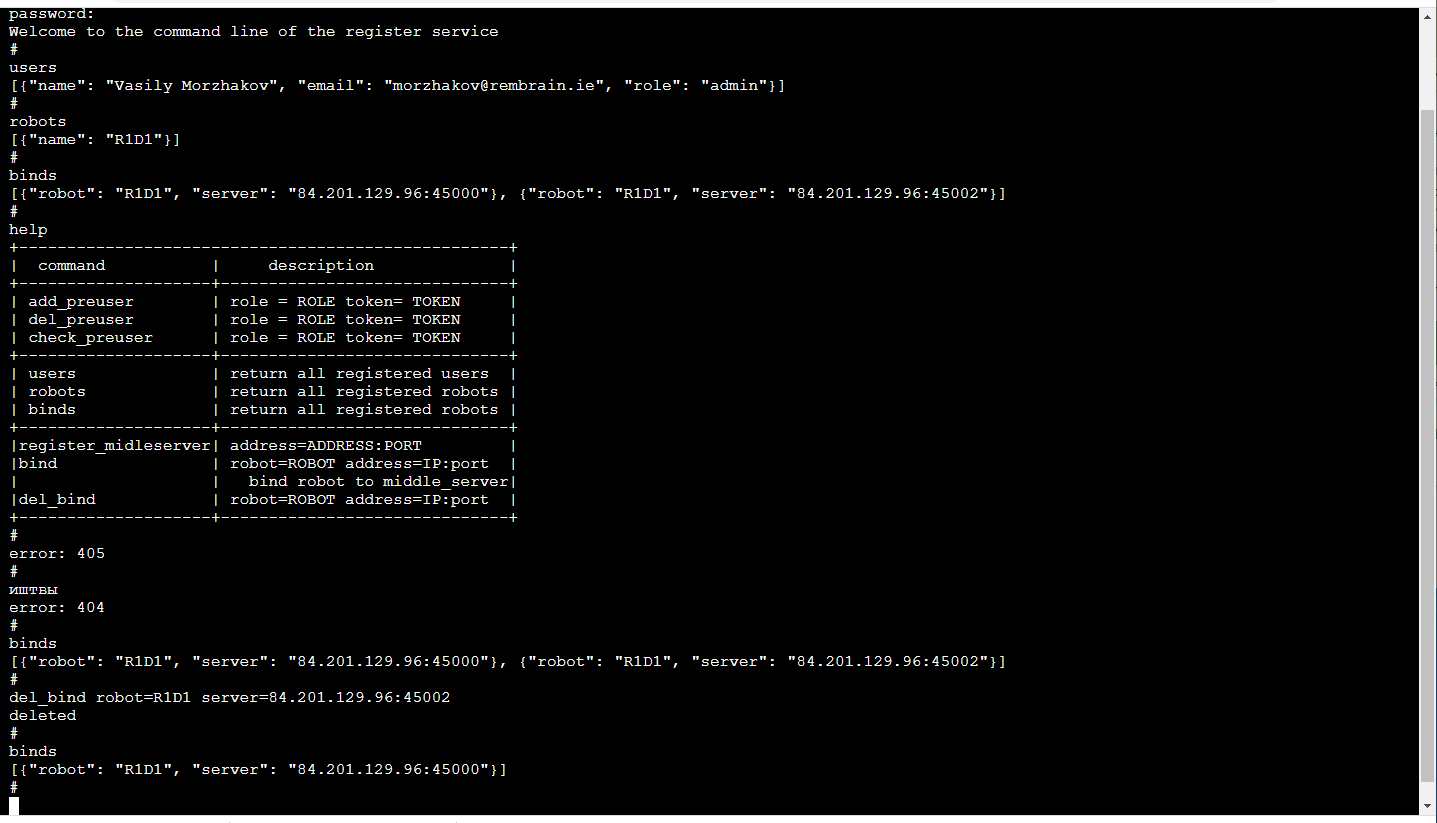
Это, конечно, отдельная тема для обсуждения, почему же командная строка так удобна. Кстати, особенно удобно делать unit-тестирование такого frontend-а.
Помимо http API в этом сервисе реализован механизм регистрации пользователей с временными token-ами, login/logout операторов, администраторов и роботов, поддержка сессии, сессионных ключей шифрования трафика между сервером ретрансляции и роботом.
Все это сделано на Python с Flask-ом — очень близкий стек для ML разработчиков (т.е. нам). Да, к тому же, существующая инфраструктура CI/CD для микросервисов отлично дружит с Flask.
Проблема задержки
Если мы хотим управлять манипуляторами в реальном времени, то минимальная задержка крайне полезна. Если задержка становится слишком большой (более 300 мс), то очень сложно, опираясь на изображение в виртуальном шлеме, управлять манипуляторами. В нашем решении за счет покадрового сжатия (т.е. отсутствует буфферизация) и не использования стандартных средств, как GStreamer, задержка даже с учетом промежуточного сервера получается около 150–200 мс. Время на передачу по сети из них составляет около 80 мс. Остальная задержка вызвана камерой Realsense D435 и ограниченностью частоты захвата.
Конечно, это проблема в полный рост встает в режиме «слежения», когда манипулятор в своей реальности постоянно следует за контроллером оператора в виртуальной реальности. В режиме перемещения в заданную точку XYZ задержка не вызывает каких-либо проблем у оператора.
ML часть
Здесь 2 типа сервисов: управление и обучение.
Сервис для обучения забирает данные, сохраненные в хранилище S3, и запускает перетренировку весов модели. В конце обучения веса отправляются сервису управления.
Сервис управления ничем не отличается по входным-выходным данным от приложения оператора. Точно также на входе RGBD (RGB+Depth) стрим, показания датчиков и состояния робота, на выходе — команды управления. За счет этой идентичности и появляется возможно обучать в рамках концепции «data-driven training».
Состояние робота (и показания датчиков) — это ключевая история для ML. Оно определяет контекст. Например, у робота будет характерная для его работы машина состояний, которая во многом определяет какое управление необходимо. Эти 2 значения и передаются вместе с каждым кадром: режим работы и вектор состояния робота.
И немного про обучение:
В демонстрации в конце статьи стояла задача поиска объекта (детского кубика) на 3D сцене. Это базовая задача для pick&place применений.
Обучение строилось по паре кадров «до и после» и целеуказания, полученного при ручном управлении:

За счет наличия двух карт глубин легко было вычислить маску перемещенного в кадре объекта:
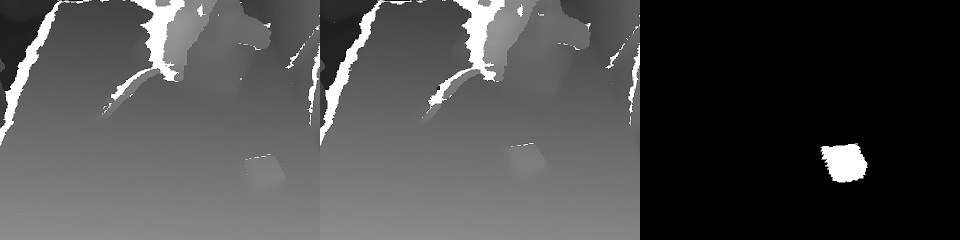
Кроме того, xyz проецируются на плоскость камеры и можно выбрать окрестность хватаемого объекта:

Собственно с этой окрестностью и будет работать.
Первично XY получим, обучив Unet сверточную сеть на сегментацию кубика.
Затем, нам нужно определить глубину и понять, не аномальное ли перед нами изображение. Это делается с помощью автоэнкодера в RGB и условного автоэнкодера в depth.
Архитектура модели для обучения автоэнкодера:
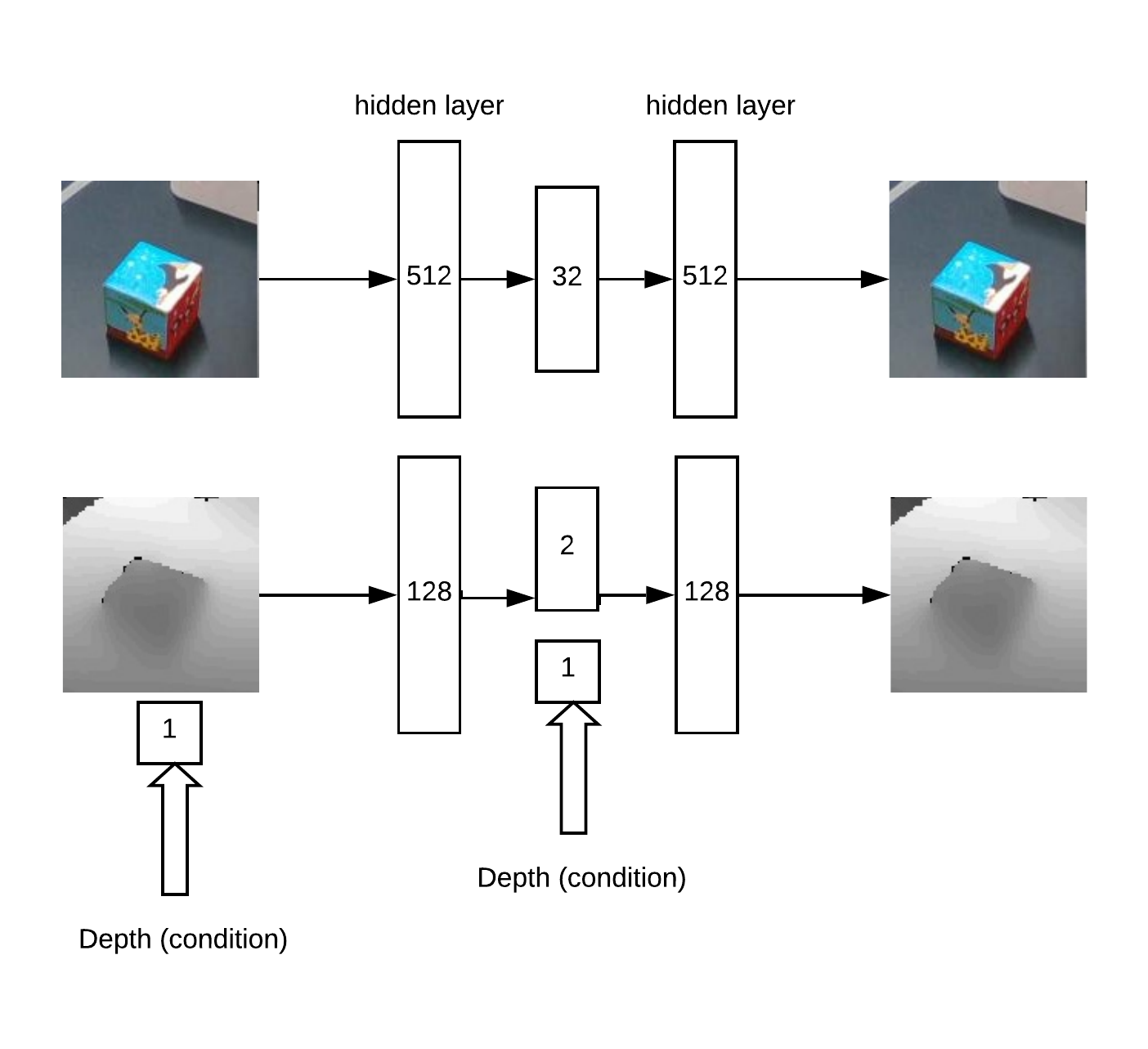
В итоге логика работы:
- поиск максимума на «тепловой карте» (определяют угловые u=x/z v=y/z координаты объекта), превышающего порог
- затем автоэнкодер реконструирует окрестности найденной точки для всех гипотез по глубине (с заданным шагом от min_depth до max_depth) и выбирается глубина, на которой невязка реконструкции и входа минимальна
- Имея угловые координаты u, v и depth можно получить координаты x, y, z
Пример реконструкции автоэнкодером карты глубин кубика при правильно определенной глубине:

Отчасти, идея метода поиска глубины построена на статье про наборы автоэнкодеров.
Этот подход хорошо работает для объектов разнообразной формы.
Но, в целом, есть множество разнообразных подходов для поиска XYZ объекта по RGBD снимку. Конечно, надо на практике и на большом объеме данных выбирать наиболее точный метод.
Также стояла задача детекции аномалий, для этого нам понадобится сегментационная сверточная сеть, чтобы обучаться по имеющимся маскам. Затем согласно этой маске можно оценить точность реконструкцию автоэнкодера в карте глубин и RGB. По этой невязке и можно принять решение о присутствии аномалии.
За счет этого метода можно детектировать появление ранее не виданных объектов в кадре, которые тем не менее детектируются первичным алгоритмом поиска.
Демонстрация
Проверка и отладка всей созданной программной платформы проводилась на стенде:
- 3D камера Realsense D435
- 4х координатная роборука Dobot Magician
- VR шлем HTC Vive
- Сервера на Yandex Cloud (уменьшает задержку в сравнении с AWS облаком)
На видео мы учим находить кубик на 3D сцене, выполняя в VR pick&place задачу. Для обучения на кубике было достаточно около 50 примеров. Затем меняется объект и показывается еще около 30 примеров. После переобучения, робот может находить и новый объект.
На весь процесс затрачено около 15 минут, из которых около половины — обучение весов модели.
А на этом видео управление YuMi в VR. Для обучения манипуляции объектов тут нужно оценить ориентации и места захвата инструмента. Математика построена на аналогичном принципе, но сейчас находится на стадии тестирования и отработки.
Заключение
Большие данные и Deep learning — это еще не все.
Мы меняем подход к обучению, движемся к тому, как люди учатся новому — через повторение увиденного.
Математический аппарат «под капотом», который мы будем развивать на реальных применениях, нацелен на проблему контекстно-зависимой трактовки и управления. Контекстом здесь выступает естественная информация, доступная с датчиков робота или внешняя информация о текущем технологическом процессе.
И, чем больше технологических процессов мы освоим, тем больше будет развита структура «мозга в облаках», и натренированы отдельные его части.
Сильные стороны этого подхода:
- возможность обучения манипуляции вариативными объектами
- обучение при изменяющемся окружение (например у мобильных роботов)
- плохо структурируемые задачи
- короткое время достижения рынка, т.к. можно выполнять целевую задачу даже в ручном режиме с помощью операторов
Ограничение:
- потребность в надежном и неплохом интернете
- необходимы дополнительные методы достижения высокой точности, например, камеры в самом манипуляторе
Сейчас мы работаем над применением нашего подход в стандартной задаче pick&place разнообразных объектов. Но нам (естественно!) кажется, что он способен на большее. Есть идеи, где еще попробовать силы?
Благодарю за внимание!
