MLOps-инструменты, обзоры рынка и тренды потоковой обработки данных

Привет, Хабр! В сегодняшнем дайджесте продолжаю делиться материалами, которые помогут вам лучше разобраться в темах ML, искусственного интеллекта и дата-аналитики. Какие перспективы у LLM и BI? Куда Amazon и Google инвестировали более $4 млрд? Как организовать работу аналитических команд? Интересно узнать? Тогда читайте нашу статью. Еще больше полезных материалов по DataOps и MLOps — в Telegram-сообществе «MLечный путь».
Используйте навигацию, если хотите выбрать интересующий блок:
→ Теория
→ Практика
→ Обзор рынка
→ Инфраструктура
→ Инструменты
→ Видео
Теория
All You Need to Know about Vector Databases for Your LLM Apps
Объемная статья о векторных базах данных в контексте LLM. Автор так основательно подошел к статье, что я посмотрел другие его публикации. Подход во всех оказался одинаковый: схемы, пояснения, структура. Уважаю таких.
Рекомендую эту статью всем, кто начинает разбираться в языковых моделях. Вся основная механика завязана на векторных преобразованиях, без понимания которых серьезно разрабатывать LLM не получится. А тут нам по подробно разложили:
- Почему нельзя просто загрузить наши данные в модель?
- Как происходит преобразование данных в векторы?
- Как осуществить поиск «ответа» на наш запрос?
- Как выбрать и развернуть векторное хранилище?
- Как ускорить поиск?
Понравилось, что в статье много примеров кода, которые можно переиспользовать.
How To Set Up Your Data Analytics Team For Success — Centralized vs Decentralized vs Federated Data Teams
Обзорный материал о способах организации аналитических команд. Всего существует три вида: централизованная, децентрализованная и федеративная. С первыми двумя понятно и без дополнительных комментариев. С последним наоборот: появляется единая технологическая платформа, а также команда для ее обслуживания и развития. У каждого есть свои плюсы и минусы, поэтому в статье сможете подобрать подходящий вариант.

Федеративные команды.
The Data Maturity Pyramid: From Reporting to a Proactive Intelligent Data Platform
Автор рассказывает о The Data Maturity Pyramid (модели зрелости аналитики) в компаниях. Она основана на уровне сложности используемых инструментов и методов: от простой отчетности до платформ данных для AI.
Всего в модели пять уровней:
- отчетность,
- Data Governance,
- дата-продукты,
- ML и AI,
- PIDP (Proactive Intelligent Data Platform).
Складывается ощущение, что «проактивная интеллектуальная платформа данных» — это переизобретенная предписательная аналитика из других моделей зрелости аналитических систем.
Migrating From ClickHouse to Apache Doris: What Happened?
Автор статьи перешел на Apache Doris и рассказал о своем процессе миграции с одного аналитического стека на другой. Помимо ClickHouse в «старой» схеме были Apache Kylin и Druid. В итоге производительность улучшилась на 10 из 16 типовых SQL-запросов, используемых автором.
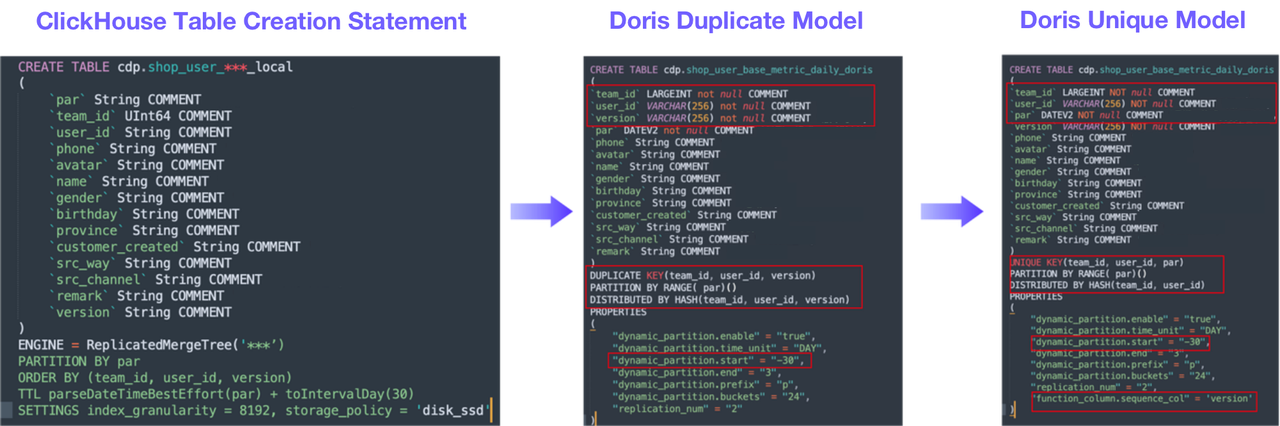
Создание таблиц в трех СУБД.
Практика
Сам себе BI-аналитик или как навести порядок в отчетности компании
Коллеги из Кошелька выпустили статью о структурировании процесса работы с корпоративными дашбордами. И это без BI-аналитиков в команде. В тексте поделились, с чего начали изменение отчетности и с какими проблемами столкнулись. Дополнительно сопроводили тотальным документированием, общими шаблонами и проработкой требований по Dashboard Canvas от Романа Бунина.

Шаблон «Карточка метрики».
LLM and BI System Synergy — First results and Mid-Term Perspectives
Статья про перспективы использования больших языковых моделей (LLM) вместе с BI. При этом автор не пытается «уволить» аналитиков и предсказать восстание машин.
В качестве первых шагов для интеграции двух инструментов предлагают:
- бота для консультаций по формулировкам, используемых в дашбордах,
- бота-путеводителя по имеющимся сертифицированным дашбордам.
Выглядит практически применимым, в отличие от того, что можно прочитать в типовых статьях на данную тему.
Как мы в Just AI создавали и тестировали собственную LLM
Третья языковая модель из России. Создатели сопоставляют ее по качеству с известными русскоязычным LLM — например, GigaChat. Было интересно ознакомиться с их процессом работы над моделью, обучением и тестированием. Надеюсь, у них еще будут статьи с большим количеством деталей.
Платформа для анализа данных за вечер
На Хабре вышла наша статья с описанием, как использовать продукт Data Analytics Virtual Machine. В состав ее образа входят Prefect, Jupyter Lab, Superset. После прочтения можете сразу загрузить данные и начать работу с ними.

Обзор рынка
Amazon to invest up to $4 billion in AI startup Anthropic
Anthropic нужны GPU для обучения своей следующей модели Claude-Next. На рынке AI многие называют его главным конкурентом ChatGPT. Судя по всему, Amazon планирует инвестировать в компанию сначала $1.25 млрд, но с планами увеличения вложений до $4 млрд. При этом Google не стоит в стороне и тоже хочет включиться в процесс. В общем, крупные игроки планируют сократить отставание от OpenAI за чужой счет. Если получится, то успех новой модели будет монетизироваться спонсорами по полной.
Operationalizing Machine Learning at any scale
ClearML выпустил на своем сайте брошюру с описанием четырех клиентских кейсов:
- Как Photomath перешел от отслеживания экспериментов в Google Sheets к увеличению его объема на 1200%.
- Как Philips сэкономила сотни часов по всем направлениям: от управления экспериментами до прозрачности данных.
- Как Agroscout сократил время производства на более 50% и повысил объема данных в 100 раз — без увеличения команды аналитиков.
- Как команда из двух специалистов по анализу данных в Daupler перешла от ручной организации миллионов образцов данных к автоматизации всего жизненного цикла разработки.
Результаты меня впечатлили. Хотя для кого-то рост от нескольких экспериментов в день до десятков уже не вызывает удивления.
The State of Data Streaming for Digital Natives (Born in the Cloud)
В статье — исследование рынка потоковой обработки данных и его трендов на 2023 год. По мнению Кайя Венера, технологического евангелиста в Confluent, на рынок доступных решений влияют:
- децентрализация за счет Data Mesh,
- Kappa-архитектура, заменяющая Lambda,
- передача данных в глобальных масштабах,
- AI/ML в реальном времени.
Если говорить про технологический стек, то все крутится вокруг Kafka. Впрочем, ничего удивительного.
Инфраструктура
Networking for Data Centers and the Era of AI
Nvidia приводит свои решения для организации сетевого взаимодействия нод с большим количеством GPU внутри датацентров. Теперь у нас есть два новых названия: AI-фабрика (AI factory) и AI-облако (AI cloud). Фабрики подходят для кластеров из тысяч GPU, для обучения LLM и организации core-компонентов AI-систем. Тогда как облака подразумевают адаптацию генеративных сервисов для тысячей пользователей.
Обычно о таком задумываются, когда одного сервера с несколькими GPU уже не хватает. Немногие до такого дошли, поэтому эти решения могут показаться необоснованно дорогими, но альтернатив пока не просматривается.
Data engineering at Meta: High-Level Overview of the internal tech stack
Интересная статья о техническим стеке для аналитики в одной крупной компании. Из необычного для себя выделил:
- Data WareHouse на базе СУБД Hive и ORC,
- Presto и Apache Spark для запросов,
- собственные разработки для дата-каталога (iData), реалтайм-аналитики (Scuba), а также работы с ноутбуками (Daiquery & Bento) и BI (Unidash).
Одним словом, красиво жить не запретишь.
Инструменты
Introducing the LLM Mesh
Мы еще не пережили Data Mesh, как нам предлагают LLM Mesh. Выглядит как маркетплейс универсальный интерфейс для доступа к партнерским моделям и сервисам. Среди них — Azure OpenAI Service, Google Vertex AI, AWS Bedrock, OpenAI, Anthropic, Cohere, MosaicML и Hugging Face.
Dataiku решили нести инструмент в «массы» и рассказали в статье, как помогают компаниям создавать и развертывать AI-приложения корпоративного уровня через LLM Mesh.

Runway Platform
Недавно с коллегами проводил исследование, где наткнулся на новую MLOps-платформу от Runway. Особо понравилось, как они показывают свои фичи на сайте — вкладки с интерактивными примерами интерфейсов. Выглядит впечатляюще. Вот бы так делали все…

Data Orchestration Tools: Ultimate Review
Еще одно сравнение инструментов для оркестрации аналитических и ML-нагрузок. Помимо очевидных лидеров рынка есть более интересные варианты: например, DAGWorks, Shipyard, Kestra, Datorios и MLtwist. Однако не все инструменты открытые и одинаково удобные.
Superset 3.0 Release Notes
Вышла третья версия BI-инструмента Apache Superset. Среди основных изменений в релизе — технические доработки. Например, избавление от старого кода и рефакторинг. Дополнительно добавили новые типы графиков, долгожданную функцию drill-by и пофиксили много багов. Сами планируем обновиться в ближайшее время.
Top 10 growing data visualization libraries in Python in 2023
Автор собрал статистику по звездочкам на GitHub в категории Python-библиотек для визуализации данных и выкатил свой топ-10. Удивительно, но на первом месте оказался PyGWalker. При этом способ оценки рейтинга доверия не внушает — выбраны только звездочки за 2023 год. Но можно подсмотреть пару интересных библиотек вроде plotnine, Holoviews, vispy и другие.

Погружаемся в базы данных и SQL: полезные материалы и инструменты
Собрали с коллегами подборку полезных ресурсов для изучения и упрощения работы с базами данных и SQL. Получилось очень познавательно: мы намеренно не добавляли совсем очевидные материалы. Ждем в комментариях ваши варианты, интересно почитать!
Видео
Winning with MLOps Best Practices for a Scalable Enterprise ML Foundation
Винсент Дэвид из Capital One рассказал об их опыте реализации MLOps. В докладе сконцентрировался на практиках интеграции ML в единую среду, где разработчик может провести модель через весь ее жизненный цикл. Сразу чувствуется специфика крупной компании, но в этом и фишка.
Понравились материалы из дайджеста? Делитесь своими в комментариях!
Интересные материалы по теме
→ Как упростить анализ данных? Запуск и сценарии использования DAVM
→ Как мы оптимизировали работу BI-аналитиков? Пошаговая инструкция
→ Как развернуть нейросеть в облаке за 5 минут? Обзор библиотеки Diffusers
